 A screenshot of the task and the issue of the pix2code neural network in its own language, which the compiler then translates into code for the desired platform (Android, iOS)
A screenshot of the task and the issue of the pix2code neural network in its own language, which the compiler then translates into code for the desired platform (Android, iOS)The new program
pix2code (
scientific article ) is designed to facilitate the work of programmers who are engaged in a chore case - coding the client GUI.
The designer usually creates interface layouts, and the programmer must write code to implement this design. Such work takes precious time that a developer can spend on more interesting and creative tasks, that is, on the implementation of real functions and program logic, rather than GUI. Soon the code generation can be transferred to the shoulders of the program. The toy demonstration of future machine learning opportunities is the
pix2code project, which has already reached the 1st place in the
list of the hottest repositories on GitHub , although the author has not even posted the source code and data sets for learning the neural network! Such a huge interest in this topic.
Encode GUI is boring. What further aggravates the situation, these are different programming languages on different platforms. That is, you need to write a separate code for Android, separate for iOS, if the program should work natively. It takes even more time and makes you perform the same type of boring tasks. More precisely, it was before. The pix2code program generates GUI code for the three main platforms — Andriod, iOS, and cross-platform HTML / CSS — with an accuracy of 77% (accuracy is determined in the program's embedded language — by comparing the generated code with the target / expected code for each platform).
The author of the program Tony Beltramelli (Danish startup
UIzard Technologies) calls this a demonstration of the concept. He believes that when scaled, the model will improve coding accuracy and potentially have the potential to save people from having to manually encode a GUI.
The pix2code program is built on convolutional and recurrent neural networks. Training on the Nvidia Tesla K80 GPU took a little less than five hours - during this time the system has optimized
parameters for one data set. So if you want to train it for three platforms, it will take about 15 hours.
The model is capable of generating code, taking only pixel values from a single screenshot as input. In other words, a special pipeline is not required for a neural network to extract features and preprocess input data.
The generation of a computer code from a screenshot can be compared with the generation of a text description from a photo. Accordingly, the architecture of the pix2code model consists of three parts: 1) a computer vision module for recognizing pictures, objects represented there, their location, shape and color (buttons, signatures, element containers); 2) a language module for understanding text (in this case, a programming language) and generating syntactically and semantically correct examples; 3) the use of the two previous models for generating text descriptions (code) for recognized objects (GUI elements).
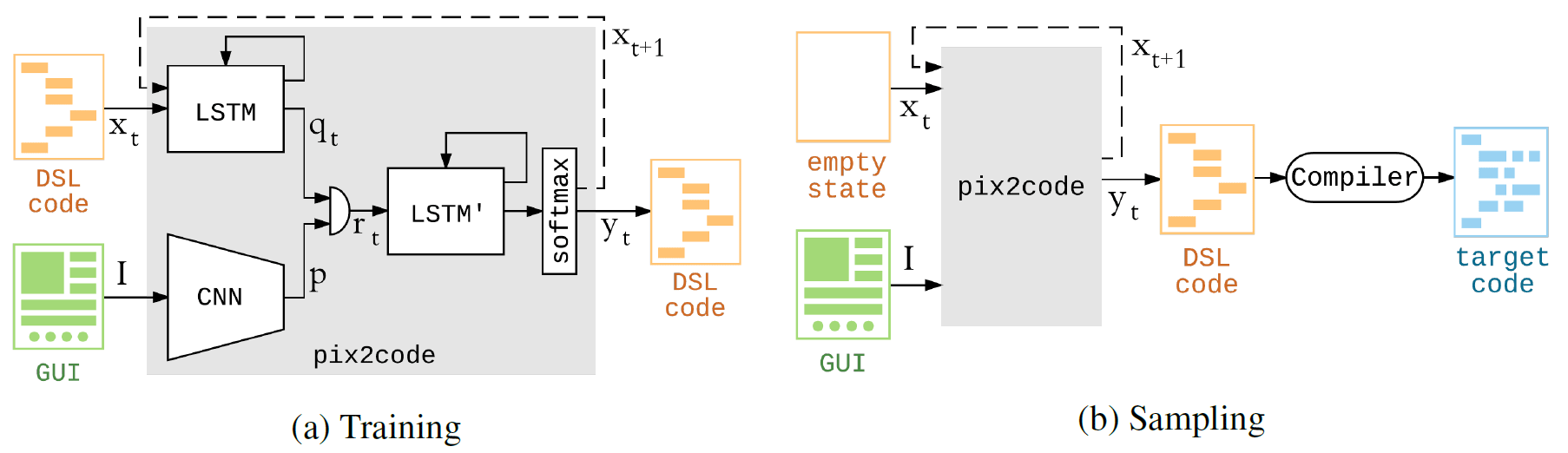
The author notes that the neural network can be trained on a different set of data - and then it will begin to generate code in other languages for other platforms. The author himself does not plan to do this, because he regards pix2code as a kind of toy, which demonstrates some of the technologies his startup is working on. However, anyone can fork the project and create an implementation for other languages / platforms.
In a scientific paper, Tony Beltramelli wrote that he would publish datasets for teaching a neural network in open access to the repository on GitHub. The repository has already been created. There, in the FAQ section, the author clarifies that he will post the data sets after publishing (or refusing to publish) his article at
the NIPS 2017 conference . Notification from conference organizers should arrive in early September, so the data sets will appear in the repository at the same time. There will be screenshots of the GUI, the corresponding code in the language of the program and the issuance of a compiler for the three main platforms.
Regarding the source code of the program - its author did not promise to publish, but given the overwhelming interest in its development, he decided to open it too. This will be done simultaneously with the publication of the data sets.
The scientific article was
published on May 22, 2017 on the site of preprints arXiv.org (arXiv: 1705.07962).