
At the beginning of the 20th century, Wilhelm von Austin, a German horse trainer and mathematician, announced to the world that he had taught a horse to count. For years, von Austin traveled to Germany with a demonstration of this phenomenon. He asked his horse named
Clever Hans (a breed of
Orlov trotter ) to count the results of simple equations. Hans gave the answer, stamping his hoof. Two plus two? Four hits.
But scientists did not believe that Hans was so clever as von Austen declared. Psychologist
Karl Stumpf conducted a thorough investigation, which he dubbed the “Ganzovskom Committee”. He found that Clever Hans does not solve the equations, but reacts to visual signals. Hans tapped his hoof until he got to the correct answer, after which his coach and the enthusiastic crowd erupted in shouts. And then he just stopped. When he did not see these reactions, he continued to knock.
Computer science can learn a lot from Hans. The accelerating pace of development in this area suggests that most of the AI created by us has been trained enough to give the correct answers, but it does not really understand the information. And it's easy to fool him.
Machine learning algorithms quickly became the all-seeing shepherds of a human herd. The software connects us to the Internet, tracks spam and malicious content in our mail, and will soon drive our cars. Their deception shifts the tectonic foundation of the Internet, and threatens our security in the future.
Small research groups - from Pennsylvania State University, from Google, from the US military - are developing plans to protect against potential attacks on AI. Theories put forward in the study say that the attacker can change what the robot sees. Or activate voice recognition on the phone and force it to enter a malicious site with the help of sounds that will only be noise for a person. Or allow the virus to leak through the network firewall.
 On the left - the image of the building, on the right - the modified image, which the deep neural network refers to ostriches. In the middle, all changes applied to the primary image are shown.
On the left - the image of the building, on the right - the modified image, which the deep neural network refers to ostriches. In the middle, all changes applied to the primary image are shown.Instead of intercepting control over the operation of the robotic car, this method shows him something like a hallucination - an image that actually does not exist.
Such attacks use images with a trick [adversarial examples - there is no well-established Russian term, literally something like “examples with opposition” or “rival examples” is obtained - approx. trans.]: images, sounds, text that look normal to people, but are perceived completely differently by machines. Small changes made by the attackers can cause the deep neural network to draw wrong conclusions about what it is showing.
“Any system that uses machine learning to make security-critical decisions is potentially vulnerable to these kinds of attacks,” says Alex Kanchelyan, a researcher at the University of Berkeley, who studies machine learning attacks using fraudulent images.
Knowledge of these nuances in the early stages of developing an AI gives researchers a tool to understand the methods of correcting these shortcomings. Some have already done this, and they say that because of this, their algorithms have become more efficient.
Most of the mainstream of AI research is based on deep neural networks, which in turn are based on a wider area of machine learning. MO technologies use differential and integral calculus and statistics to create software used by most of us, such as spam filters in the mail or searching the Internet. Over the past 20 years, researchers have begun to apply these techniques to a new idea, neural networks - software structures that simulate the operation of the brain. The idea is to decentralize the computations on thousands of small equations (“neurons”), receiving data, processing and transmitting them further, to the next layer of thousands of small equations.
These AI algorithms are trained in the same way as in the case of the MO, which, in turn, copies the process of human learning. They are shown examples of different things and related tags. Show the computer (or child) an image of a cat, say that the cat looks like this, and the algorithm learns to recognize the cats. But for this computer will have to view thousands and millions of images of cats and cats.
The researchers found that these systems can be attacked with specially selected fraudulent data, which they called "adversarial examples".
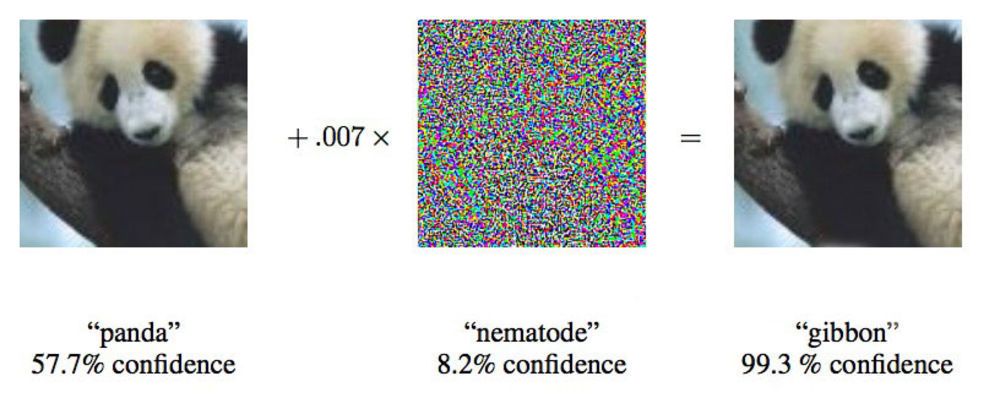 In a paper from 2015, researchers from Google showed that deep-seated neural networks can be made to attribute this image of a panda to gibbons.
In a paper from 2015, researchers from Google showed that deep-seated neural networks can be made to attribute this image of a panda to gibbons.“We show you a photo that clearly shows the school bus, and make you think that it is an ostrich,” says Ian Goodfellow, a Google researcher who is active in the field of similar attacks on neural networks.
By changing the images provided by neural networks by only 4%, the researchers were able to deceive them, forcing them to make a mistake with the classification, in 97% of cases. Even if they did not know exactly how the neural network processes images, they could fool it 85% of the time.
The latest version of deception without data about the network architecture is called “attack on the black box”. This is the first documented case of a functional attack of this kind on a deep neural network, and its importance lies in the fact that approximately in such a scenario attacks can occur in the real world.
In their work, researchers from Pennsylvania State University, Google, and the US Navy Research Laboratory launched an attack on a neural network that classifies images, supported by the MetaMind project, and serves as an online tool for developers. The team built and trained the attacked network, but their attack algorithm worked independently of the architecture. With this algorithm, they were able to trick the neural network- “black box” with an accuracy of up to 84.24%.
 The top row of photos and signs - the correct recognition of signs.
The top row of photos and signs - the correct recognition of signs.
Bottom row - the network was forced to recognize the signs completely wrong.Feeding incorrect data to machines is not a new idea, but Doug Tygar, a professor at the University of Berkeley who has studied machine learning with an opposition of 10 years, says that this attack technology has evolved from simple MO to complex deep neural networks. Malicious hackers have been using this technique on spam filters for years.
Tiger’s research originates from the
work of 2006 on attacks of this kind on the network with the MoD, which he
expanded in 2011 with the help of researchers from the University of California at Berkeley and Microsoft Research. The Google team, the first to start using the deep neural networks, published its
first job in 2014, two years after the discovery of the possibility of such attacks. They wanted to make sure that this was not an anomaly, but a real possibility. In 2015, they published another
work that described a way to protect networks and increase their efficiency, and Ian Goodfello has since advised on other scientific work in this area, including
the black box attack .
Researchers call the more general idea of unreliable information “Byzantine data”, and thanks to the course of research they have come to deep learning. The term comes from the well-known "
task of the Byzantine generals, " a thought experiment in the field of computer science, in which a group of generals must coordinate their actions with the help of messengers, without having confidence in who is the traitor. They cannot trust the information received from their colleagues.
“These algorithms are designed to cope with random noise, but not with Byzantine data,” Taigar says. To understand how such attacks work, Gudfello suggests imaging a neural network in the form of a scatter diagram.
Each dot in the diagram represents one pixel of the image processed by the neural network. Usually the network tries to draw a line through the data that best matches the aggregate of all points. In practice, this is a bit more complicated, since different pixels have different values for the network. In reality, this is a complex multi-dimensional graph processed by a computer.
But in our simple analogy of the scatterplot, the shape of the line through the data determines what the network thinks it sees. For a successful attack on such systems, researchers need to change only a small part of these points, and make the network make a decision, which is not really there. In the example of a bus that looks like an ostrich, a photo of a school bus is dotted with pixels arranged according to a scheme related to the unique characteristics of photos of ostriches familiar to the network. This is a contour invisible to the eye, but when the algorithm
processes and simplifies the data , the extreme data points for the ostrich seem to be a suitable classification option. In the black box version, the researchers checked the work with different input data to determine how the algorithm sees certain objects.
By giving the classifier objects fake input data and studying the decisions made by the machine, the researchers were able to restore the operation of the algorithm so as to deceive the image recognition system. Potentially, such a system in roboMobiles in such a case may instead of the “stop” sign see the sign “give way”. When they understood how the network works, they were able to get the car to see anything.
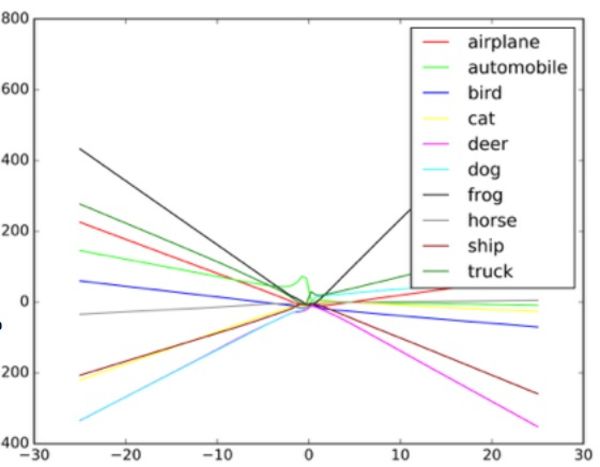 An example of how the image classifier draws different lines depending on various objects in the image. Examples-blende can be considered as extreme values on the graph.
An example of how the image classifier draws different lines depending on various objects in the image. Examples-blende can be considered as extreme values on the graph.Researchers say that such an attack can be entered directly into the image processing system, bypassing the camera, or these manipulations can be carried out with a real sign.
But security expert at Columbia University Alison Bishop says that such a forecast is unrealistic and depends on the system used in the robot. If the attackers already have access to the data stream from the camera, they can already give it any input data.
“If they can get to the entrance of the camera, such difficulties are not needed,” she says. “You can just show her the stop sign.”
Other methods of attack, in addition to bypassing the camera - for example, drawing visual marks on a real sign, seem to Bishop hardly likely. She doubts that low-resolution cameras used on roboMobiles will generally be able to discern small changes on the mark.
 The untouched image on the left is classified as a school bus. Corrected on the right - like an ostrich. In the middle - change the picture.
The untouched image on the left is classified as a school bus. Corrected on the right - like an ostrich. In the middle - change the picture.Two groups, one at the University of Berkeley, the other at Georgetown University, have successfully developed algorithms that can issue speech commands to digital assistants like Siri and Google Now, sounding like an indiscriminate noise. For a person, such commands seem like random noise, but at the same time they can give commands to devices like Alexa, not intended by their owner.
Nicholas Carlini, one of the researchers of the Byzantine audio attacks, says that in their tests they were able to activate recognizing audio programs with open source, Siri and Google Now, with an accuracy of more than 90%.
Noise is like any science fiction alien talk. It is a mixture of white noise and a human voice, but it is not at all like a voice command.
According to Karlini, with such an attack, anyone who heard the noise of the phone (it is necessary to plan attacks on iOS and Android separately) can be made to go to a web page that also plays a noise that will infect nearby phones. Alternatively, this page may silently download a malicious program. There is also the possibility that such noises will be lost by radio, and they will be hidden in white noise or in parallel with other audio information.
Such attacks can occur because the machine is trained on the fact that virtually any data contains important data, and also that one thing is more common than others, as Goodfell explains.
It is easier to deceive the network, forcing it to believe that it sees a widespread object, since it considers that it should see such objects more often. Therefore, Goodfello and another group from the University of Wyoming were able to force the network to classify images that were not there at all - she identified objects in white noise, randomly created black and white pixels.
In the Goodfellow study, random white noise passed through a network was classified by her as a horse. This, by coincidence, brings us back to the story of Smart Hans, a not very mathematically gifted horse.
Goodfellow says that neural networks, like Smart Hans, do not really learn any ideas, but only learn to know when they find the right idea. The difference is small, but important. The lack of fundamental knowledge facilitates malicious attempts to recreate the appearance of finding the "correct" results of the algorithm, which in fact turn out to be false. To understand what something is, a machine also needs to understand what it is not.
Goodfello, having trained the network to sort images on both natural images and processed (fake) images, found that he could not only reduce the effectiveness of such attacks by 90%, but also make the network better cope with the initial task.
“By making it explain really unusual fake images, you can get an even more reliable explanation of the underlying concepts,” says Gudfello.
Two groups of audio researchers used an approach similar to the approach of the Google team, protecting their neural networks from their own attacks by overtraining. They also achieved similar success, more than 90% reducing the effectiveness of the attack.
Not surprisingly, this area of research interested the US military. The Army Research Laboratory even sponsored two of the newest works on this topic, including the attack on the black box. And although the agency finances research, this does not mean that the technology is going to be used in a war. According to the representative of the department, it can take up to 10 years from research to usable technology by a soldier.
Ananthram Swami, a researcher from the US Army laboratory, was involved in the creation of several recent works on the deception of AI. The army is interested in the issue of detecting and stopping fraudulent data in our world, where not all sources of information can be carefully checked. Swami points to a set of data obtained from public sensors located at universities and working on open source projects.
“We do not always control all the data. Our opponent is pretty easy to fool us, says Swami. “In some cases, the consequences of such deception can be frivolous, in some - the opposite.”
He also says that the army is interested in autonomous robots, tanks and other means of transportation, so the purpose of such research is obvious. Studying these questions, the army will be able to win a head start in developing systems that are not subject to attacks of this kind.
But any group using a neural network should have concerns about the potential for attacks with AI cheating. Machine learning and AI are in their infancy, and at this time, security failures can have dire consequences. Many companies trust highly sensitive information to AI systems that have not passed the test of time. Our neural networks are still too young for us to know everything we need about them.
A similar oversight led to the fact that the
bot for Twitter from Microsoft, Tay , quickly turned into a racist with a penchant for genocide. The flow of malicious data and the “repeat after me” function caused Tay to stray far from the intended path. The bot has been deceived by poor-quality input data, and this serves as a convenient example of poor implementation of machine learning.
Kanchelyan says he does not think that the possibility of such attacks has been exhausted after the successful research of the team from Google.
“In the field of computer security, the attackers are always ahead of us,” says Kanchelyan. “It would be rather dangerous to declare that we solved all the problems with the deception of neural networks with the help of their repeated training.”