I started writing this text a long time ago, so it was not planned as politically relevant. But it turned out that it was precisely during these days that the media had an information guide connected with small (minority) languages of Russia. It is possible that the research I am writing about below will clarify something to someone in this sense.
How many languages in Russia?
It is not so easy to realize, but in Russia they speak an impressive number of languages. Moreover, in Russia they speak such languages that are not common anywhere else. For example, millions of Ukrainians and Uzbeks live in Russia, at the same time there are sovereign states Ukraine and Uzbekistan, where the corresponding languages are state languages. But in Russia they speak Bashkir, Tuvinian, Udmurt, and many (indeed many) other languages that have no other state anywhere.
State status is important. In the era of globalization, languages need to be supported in order to survive, which has a positive effect on the press, on the mass media, on art, and ultimately on the desire and ability of people to speak their native language.
And how much have these languages adapted to the new digital realities? Is it true that they are spoken only in remote mountain villages? Or are they a full way to online communication? A few years ago, my colleagues and I decided to find out.
At first it was a study within the framework of the now-defunct NES Internet and Society Center (now it is successfully transformed into the Internet and Society Fans Club ), then we organized a research project in the magistracy of the HSE School of Linguistics , and, in general, we were successful. All the results are presented on the special site Languages of Russia , but I will tell you here about the most interesting, what we did and how (and also what happened).
First of all, it was necessary to establish how many languages there are in Russia at all, and what kind of languages. Linguists did not have any generally accepted list: it is not known about some languages, at least one carrier is still alive, some do not have agreement, is it really a language, or is it actually a dialect of another language. And there are no clear criteria for distinguishing one from the other. There is a comic: "language is a dialect with an army and navy," but with all the wit of this statement Weinreich has enough counterexamples: Brazil has an army and navy, but does not have its own language (Brazilians use Portuguese, the language of their former metropolis), moreover, only a dialect, and the Americans, the owners of the most powerful army in the world, use no language of their own. Iceland does not have an army or a fleet (only coast guard ships), but no one attempts on the peculiarity of their language (although no one argues that he is a relative of modern Norwegian).
In short, the task was not easy. Particularly difficult are the languages of Dagestan. There are so many languages (real languages, not dialects! Their speakers do not understand each other) that you can only figure this out after consulting with experts.
We also decided to move the title languages of other states out of our list. Indeed, if a whole country outside Russia speaks some language, then, most likely, the state resource is also used to support the language. It is possible to consider such a language as the language of Russia, but it would be incorrect to assess its representation on the Internet compared to other languages that are not fed from abroad: Ingush and Kazakh will be in completely different weight categories. So, our study turned out to be Ossetian: despite the fact that in Russia there is a whole titular region where Ossetian is spoken, there exists a separate country recognized by Russia, South Ossetia, for which this language is state language. Strictly speaking, in South and North Ossetia they speak different dialects, Iron and Digor. But automatically, computer, to distinguish them is very difficult. So it is better to consider them as one language that does not belong to the class of languages of Russia.
Another incident is related to Yiddish. In Russia, nominally, too, there is a region in which Yiddish speakers must live - the Jewish Autonomous Region. At the same time, our experts explained to us that there are almost no Yiddish speakers in the JAR, and all the texts on the Internet in this language are written almost exclusively in Israel and in the USA. So analyzing the representation of Yiddish on the Internet as the language of Russia is stupid. This is in addition to the fact that we would face a headache associated with a variety of spelling options. Here are some relevant links about this: [ 1 ], [ 2 ], [ 3 ].
So, we have decided on languages. They turned out 96.
Full list of languagesAbaza
Avar
agulsky
Adyghe
Aleut
Alutor
amuzgi shirinsky
andean
Archinsky
Akhvakh
bagwalinsky
Bashkir
Begta
botlikh
Buryat
Vepsian
Verkhnevurkunsky
Vodsky
Hapshimian
Ginuh
Goduberin
Gorno-Mari
Gunzib
Izhora
Ingush
Itelmen
Kabardino-Circassian
Kadar (possibly Darginian)
kaytag
Kalmyk
karatinsky
Karachay-Balkar
Karelian
Ket
Kola-Saami
Komi-Zyryan
Komi-Permian
Koryak
Kubachi-Ashtinsky
Kumyk
Lak
Lezgin
Forest Nenets
meadow-eastern mari
Mansi
Megebian
moksha-mordovsky
Mauri
Nanai
Nganasan
Negidal
Nivkh
Nogai
Orok
rutul
Sanzhi Itsarinsky
North Altai
Northern Yu-Kagir (tundra, vadul)
North Dargin (including literary Darginsky)
Selkup
Soyot-Tsatan
Tabasaran
Tanta-Sirkhinsky (possibly, one language with Verkhneurkunsky)
Tatar
Tat (endangered)
Tinda
Tofalar
Tubalar
Tuva
Nenets tundra
udin
Udmurt
Udegei
ulchi
ushusha-tsudahar
Khakass
Khanty
Khvarshinsky
Tsakhur
tsez
Gypsy
Chamalinsky
Chechen
Chirag
Chuvash
Chukchi
Chulym
Shor
Evenki
Even
enetsky
Erzya Mordovian
Eskimo
South Altai
South Kyagir (Kolyma, Odulsky)
Yakut
How now to look for them on the web? You can deflate the entire Internet and try to find the necessary texts in the resulting collection ... But wait, because in fact you can not deflate the entire Internet. That is, it is possible if you are a large IT company with an appropriate server park and development team. And if at your disposal a small university team, then there is nothing to think about. On the other hand, there is no need to download anything at this stage, because the entire network has already been bypassed by search robots. It is only necessary to ask the search engines the correct requests. True, search engines dislike automatic downloads. But if you really ask, you can use, for example, Yandex.XML, which has restrictions on the number of requests, but still it is not the same thing as working with search results.
Marker words
But what to ask? Words are needed - this is clear. Search indexes are formed from words, so it is necessary to choose such words for each desired language that would occur in this language and not match the composition of the letters with a single word in any other language. In a sense, the search for Russian languages should be easier, because almost all the languages from our list have Cyrillic script, and this is a relatively rare case for world languages, so the probability of two words coinciding from different languages decreases dramatically: only words from languages from the post-Soviet space, and words from some languages in Oceania will not make noise.
But where to get the words? If you again turn to linguists, they will tell you that there is an old and well-deserved publication - R. S. Gilyarevsky, V. S. Grivnin. The determinant of world languages according to writing (M., 1961 for the second edition). Each of the described languages (about 200) is devoted to one page, where one template contains the name of the language, two short texts on them, the alphabet, its main features, and information about the number of carriers and genetic affiliation.
It seems that the book for our purposes is completely useless, but on page 259 there is an additional section “Characteristic letter combinations and service words of some languages”. It seems that this is what is needed, but unfortunately, the words that are cited there are very short and coincide in letter with the words from the Russian language. For example, for Balkar, this word “bla”, which when searching will produce a monstrous amount of garbage, doesn’t correlate with Balkarian language (not only blah blah, but “ Unmanned aerial vehicle ”), but for mountain Mari - don ( the search will be even worse). Well, and yet the words in this section, rather, a rarity. And on a letter combination in Yandex you will not look.
So would suggest to make linguists. Computer scientists would have another solution. Why not take Wikipedia (after all, there are Wikipedia in the languages of the peoples of Russia), make it a chastotnik, cross dictionaries, find unique tokens in this way, and use them for search queries? Unfortunately, that won't work either. First, Wikipedia is not for all languages of Russia. There are only 22 “real” wikipedia sections, not from the incubator, the incubator adds another 41. But usually this is a maximum of a few dozen very short texts, that is, they will not give statistically significant results. Here is the incubator with the Tabasaran Wikipedia (5 articles). Here is the Nogai Incubator (23 articles). And in some there is no text at all, but the local article about the Bashkirs . And so on.
But the real (not incubation) Wikipedia can not serve as a good source. Because they ... are not written by humans! The biggest wikipedia in the languages of the peoples of Russia suffer from what wikipediyshchik called " arachnophilia ". that is, automatic filling of the section with articles generated by the template, into which any numerical data from an open database or registry is inserted. For example, the Bashkir and Tatar wikipedia for a very small percentage of "human", there are tens of thousands of automatic articles about rivers and lakes. Try to click the link “ random article ” in the Bashkir Wikipedia, how many times out of 10 you will get not to the “water article” (you can search by the keyword “yylғa” “river”)? Now the situation has straightened out a bit, there were more articles about countries and localities, but five years ago the “water” topic was in 8 cases out of 10. I clicked it now, it turned out 7: 3 in favor of the rivers. What about you?
Everything would be fine, but the frequency words in such texts are not at all the frequency words in the language. What does a “normal” frequency dictionary look like, compiled on texts of natural origin? The first couple of dozens of positions there occupy different official words, which are many times more common in speech than any significant ones. Here is the frequency dictionary for the Russian language . The first noun (year) appears there at the end of the third decade. And before that, everything is completely - conjunctions, prepositions, pronouns and particles. But the frequency dictionary of the Tatar Wikipedia for 2013:
| No | Word form | Translation / Value | Incidence |
|---|
| one | Elga | river | 132567 |
| 2 | swimming pools | pool | 75706 |
| 3 | su | water | 54689 |
| four | buencha | by | 48838 |
| five | Russia | Russia | 48722 |
| 6 | urnashkan | situated | 38043 |
| 7 | km | kilometer | 36962 |
| eight | Һәm | and | 27231 |
| 9 | ketch | small | 27203 |
| ten | is not | state | 26888 |
There are only two official words, of which only one - Һәm "and" - is indeed especially often found in real texts. The rest, of course, were included in the list only because of the specifics of the initial sample.
There was only one way out before us: to collect words to set up search queries manually for each language. This is an expert work, you need to look into dictionaries and grammars, then type in candidate words into the search and look at the result and evaluate how much garbage comes out. In addition, each word must satisfy two mandatory criteria. First, it must be frequency for its language. Therefore, the Tatar Һәm "and" would fit. Indeed, this word is in most texts in the Tatar language, and a request that would contain this word would allow us to get into the issue and thus catch the majority of sites that have texts in the Tatar language. Secondly, such a word must be unique, that is, to be in use only in this language, but in no other. From this point of view, Һәm , alas, “flies by”, because exactly the same word is in Bashkir.
There is one more nuance. In the alphabets of national languages there are many “special” characters, that is, letters that are not in the alphabet of the Russian language, with the help of these characters (as linguists say, “grapheme”) special sounds are written (as linguists say, “phonemes”) of these languages. For example, the Komi-Zyryan word tashtöm contains such a symbol, far from the most exotic of those that can be (other examples can be seen in the Tatar list of “water” words above).
The fact is that since all this graphic luxury is not on the standard Russian keyboard, on which everything is mostly typed, real users do not actually enter these letters, replacing them with others that are similar in spelling or sound. The word "tashtöm" is referred to as "tashtem" or "tashtom". In Bashkir, the letter “ә” is transmitted as “e” or “a”, and the letter “ҙ” as “z”. Here on the KDPV just the word “menan” actually should be written “menan”. Following the linguist A. Zaliznyak, we call such a spelling mode the “everyday writing system”. Approximately the same processes (only without keyboards and other software) Zaliznyak described for the Old Novgorod dialect recorded in birch bark letters.
What does this mean in practice? What is ideally needed are not just word markers that are unique to this language and frequency in this language. We also need such words so that they do not contain these "special characters." Because in reality, such characters do not write everything, and if you send a query to a search engine with a word in the “correct” graphic, the answer will be so-so: we won’t get a huge number of texts written in the home system.
In addition, there are more cunning symbols, for example, “I”: “Yakovlev's wand” (in various Caucasian languages, it means either a guttural bow, or the so-called “abruptive” sound). Often in the household system it is replaced by a unit, but it happens that they also write the symbol “|”, a vertical bar, which is used as a search operator “or” (search for pages containing any of the words associated with this operator.).
In short, it is not easy. But we have compiled such lists of word markers for most of the languages we are interested in. And this is the only thing that we do not publish in open access, because such words can still be useful for searching texts, and this list is very easy to vandalize, for example, if someone wants to use them to generate search spam.
Search
So, we have search terms, send them one by one to Yandex.XML and get the output. Here, too, is not so simple. First, Yandex.XML limits our appetites to 10,000 requests per day. Not so little? Yes, but it gives out links per page (10 per page) and going to the next page is considered a separate request ...
In addition, we still get garbage at the exit. Even on "good" markers. What do we have? Mirrors and doubles. Especially a lot of doubles Wikipedia. Why should we consider Wikipedia, if our goal is to collect all the texts in a certain language? After all, Wikipedia can be downloaded with one click! What else? Linguistic scientific articles. Some linguist writes an article in Russian and cites as an example a sentence in some Rutul, and this sentence contains our word marker. This, too, is no good, because before us is actually a text in Russian. Or else it could be a dictionary. There will also be the word we were looking for, but there will be no text. Music sites were a surprise for us. They contain mp3s of numerous folk or author songs in a small language. There are no texts there either, but there are short phrases suitable for a request - the names of musical works. For some languages, these sites are so numerous that they clog the whole issue. We decided that since we are looking for texts, these are not our clients either.
We must somehow cut off the excess. The first filter can be entered at the stage of accessing the search engine. If we have several markers for the language, then having caught some domain under the bed, we can ask the search engine if there are other words from our list on the same site. If so, then there is a possibility that we have reached the site we need. If one marker is there, and the rest are not represented, then we are very likely holding a dummy in our hands. There is, for example, the wonderful Khakass word "pazoh" ("again"). It satisfies all the above criteria for the word marker. But here's the thing. When they write in Russian, sometimes they make mistakes and print instead of “sinuses” (nose) - “tongue”. Our filter will help you to understand if this is a typo in the Russian text, or indeed the Khakass text. The thing is that these are additional requests, which are few.
Not everything is unambiguous with the list of sites where we found the texts we need. If we plan not only to find these sites, but also to pump them out to form a case, then we need to know the depth to which it should be pumped out. We divided all the found domains into three categories (all this can also be found by asking Yandex for the correct requests).
The first were those on which many (presumably the majority) pages contain texts in the language of interest to us.
In the second there were those on which there are several (not too many compared to the total number of pages) documents in the language of interest to us.
By the third, we attributed those huge sites with millions of pages, including the content we are interested in. This is Youtube (in the caption to any video recording there is a text in “our” language) or stihi.ru (Chechen poets, for example, are published there).
In addition, we specifically asked Yandex about where he finds the words of interest to us on the social network VK.com. Only the communities were selected from the resulting pages, because they believed that on average, a bilingual user would rather speak his language in a special place (in this very community), and would rather write Russian in his own wall, respecting the feelings of Russian-speaking friends This, of course, is not always the case. But in general, so.
Language definition
As a result, we received lists of sites and communities in VK.com . Now these lists are already outdated: some sites have disappeared, some have been added, life in vk.com happens much more intensively. But as of the beginning of 2016, this is quite true information about how the Internet is arranged in the small languages of Russia.
The next step was to download all this. We did not fully cope with the task. Pumping up dozens of different sites for major languages like Tatar or Udmurt, we have not been able to put on stream. Scrapy broke, hung. But the communities from VK we downloaded everything completely from the API.
But deflate a little. We still need to determine what we downloaded. Sites that contain content that interests us are almost never mono-language. In order to obtain a corpus of texts that linguists could then use, as well as to understand how a particular language is represented on the Internet, it is necessary to clear the resulting web pages from the binding and from texts in other languages. Usually in computational linguistics, statistics of the distribution of characters (more often - sequences of characters, ngram) in the text are used for this. If we already have some corpus of texts in different languages, we can train a model on it and continue to successfully determine which language is in front of us. But the problem is that we just do not have such a predetermined body. We are just trying to make it.
But if you think about it, then everything is not quite so. We most likely have two languages, the differences between which we must find. One language is a small language (without difference, Yakut or Chuvash), and the second is Russian. We must separate them from each other. In this form, the task is already acquiring feasible outlines. After all, we have a Russian language as a “test subject” in large numbers. That is, we need to say about each, say, a paragraph of text, whether it is written in Russian or not. If not in Russian, then this is our client.
The determiner is not everywhere and did not always work well, but in general, rather, it is satisfactory.
results
So, we have the lyrics. We have data about sites and communities. What can you do with them now?
At a minimum, we can execute the most basic program and give the collected texts to linguists. We already have corps of Buryat , Udmurt , Tatar , Khakass languages. They can be replenished with "real" texts from the wild. Linguists like that.
But you can still try to understand something about the representation of the language on the Web. Are there many texts in this language or few? And if you compare it with how a language lives offline, does its online well-being look the same or not?
Sites
To begin with, we will calculate how many sites (domain names) are obtained for each language.
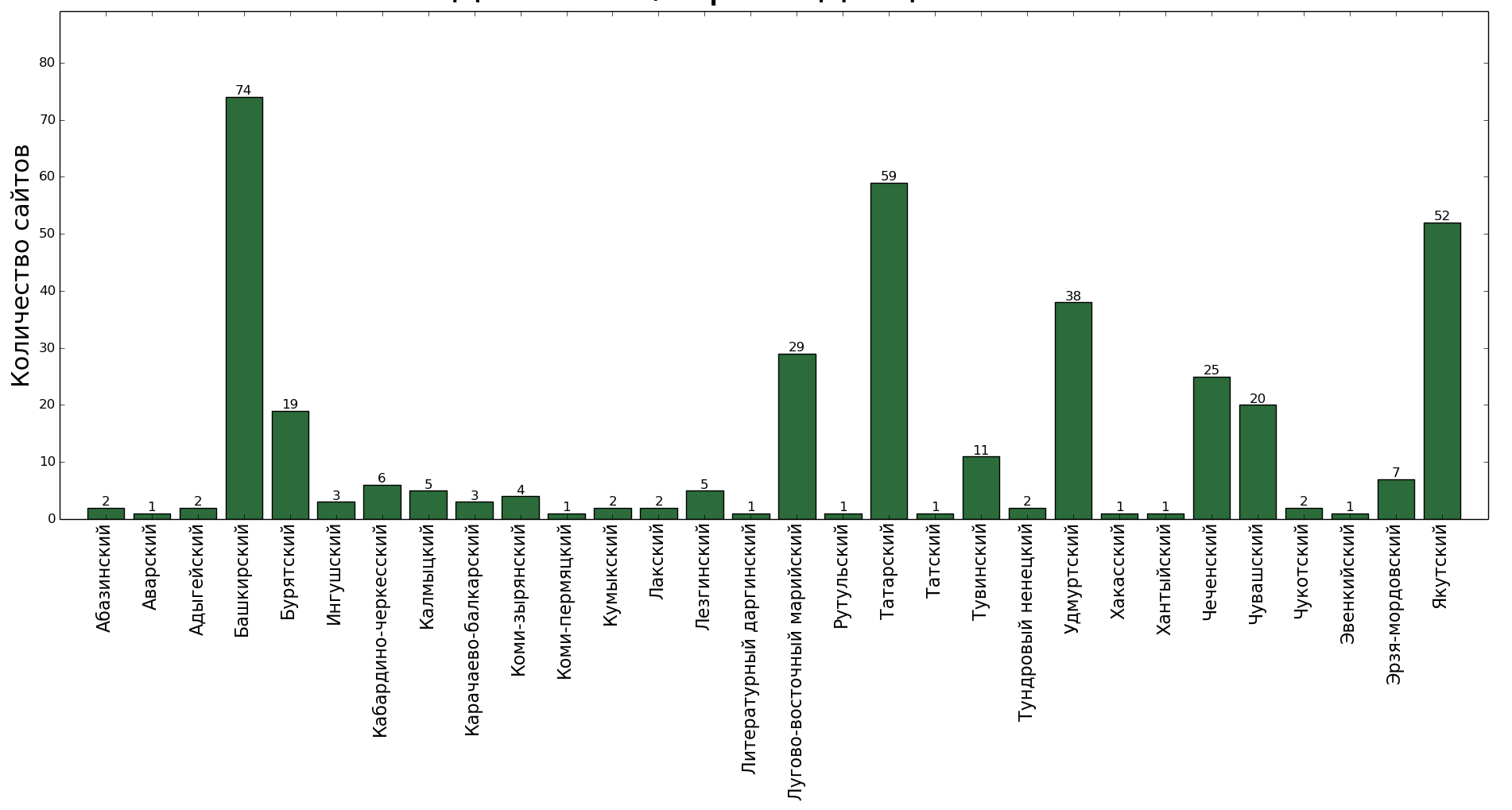
And by whom they are registered? Is it generally all private or public initiative - to lay out texts in small languages on the Internet?
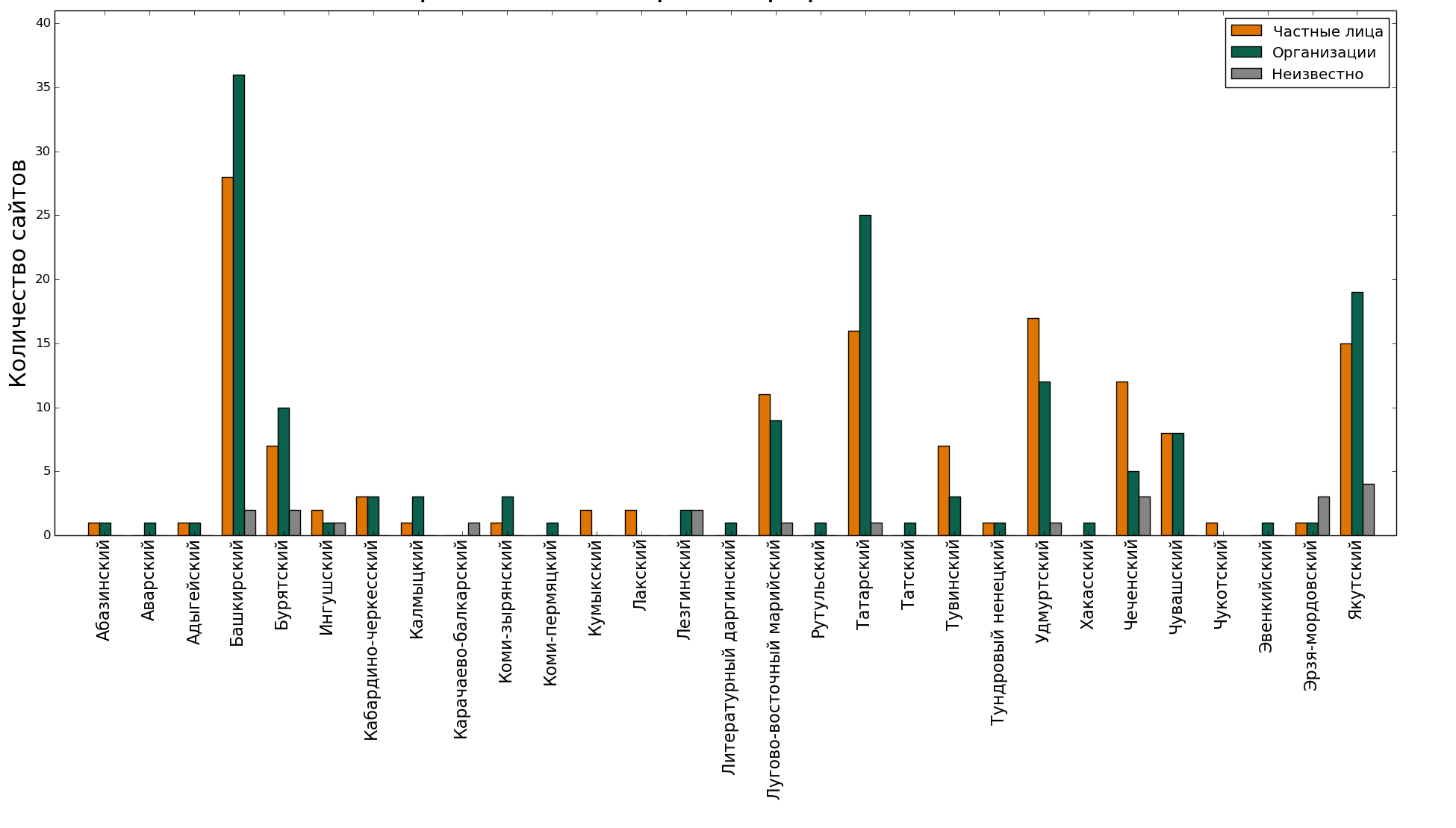
In principle, there are some activists, but for the most part the responsibility is on organizations here.
And when the sites were registered?
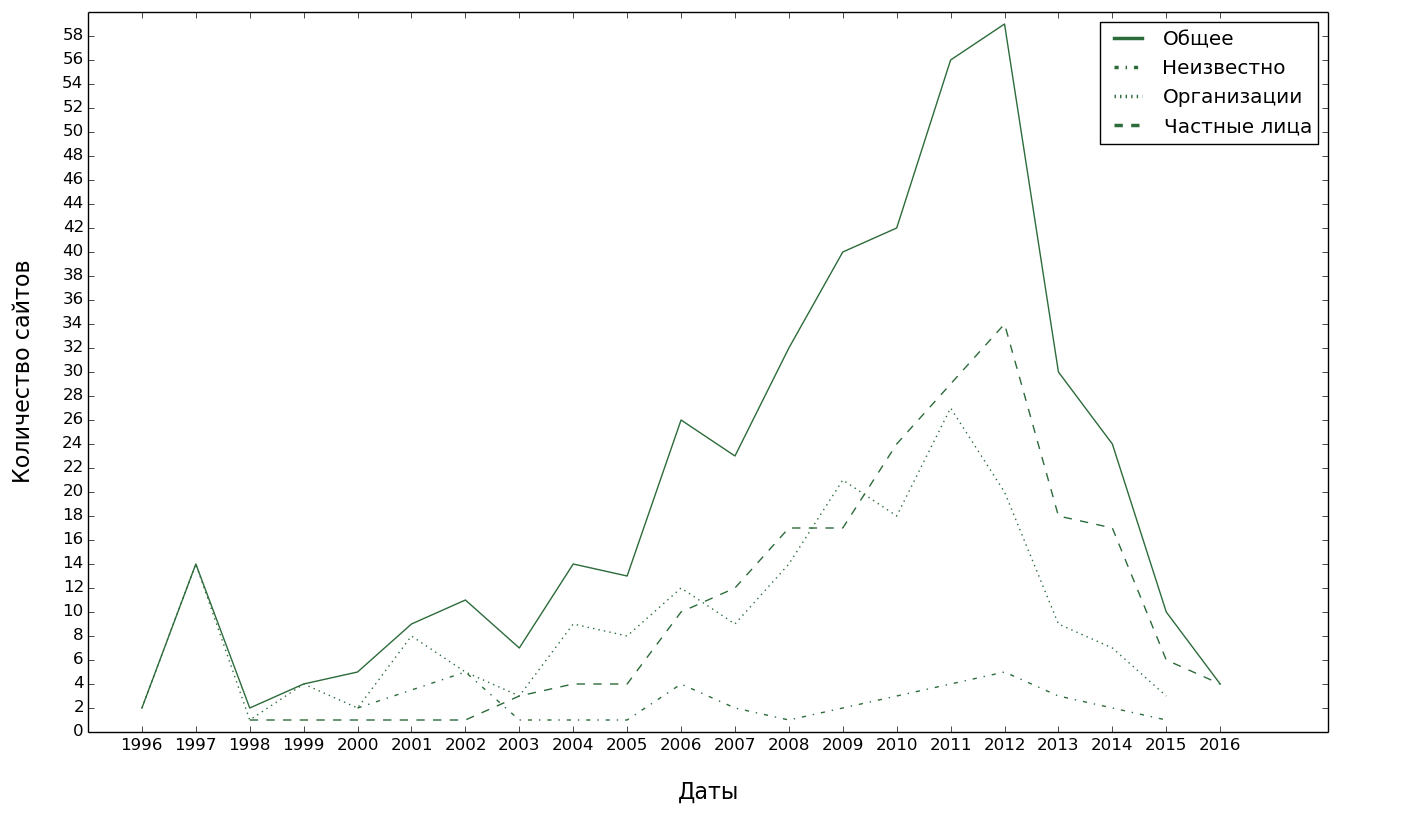
It is evident that the process went on increasing, but after 2012 there was a sharp decline. Why? Probably because all the activity of this kind has flowed into the social networks that have gained credibility. First of all, in vk.com.
Now let's try data analysis. Here we have indicators for language online: the number of articles in Wikipedia, data from Vkontakte (number of communities, volume of texts). And we have indicators for offline language (first of all, the number of speakers, but not only, there are also some economic indicators of the regions where native speakers live for the most part). Is there a correlation between these groups of indicators? Is there a correlation within the group of indicators?
, - ( 0.7), - . , , , . , , , . , , . , , .
, . ? , , , , .
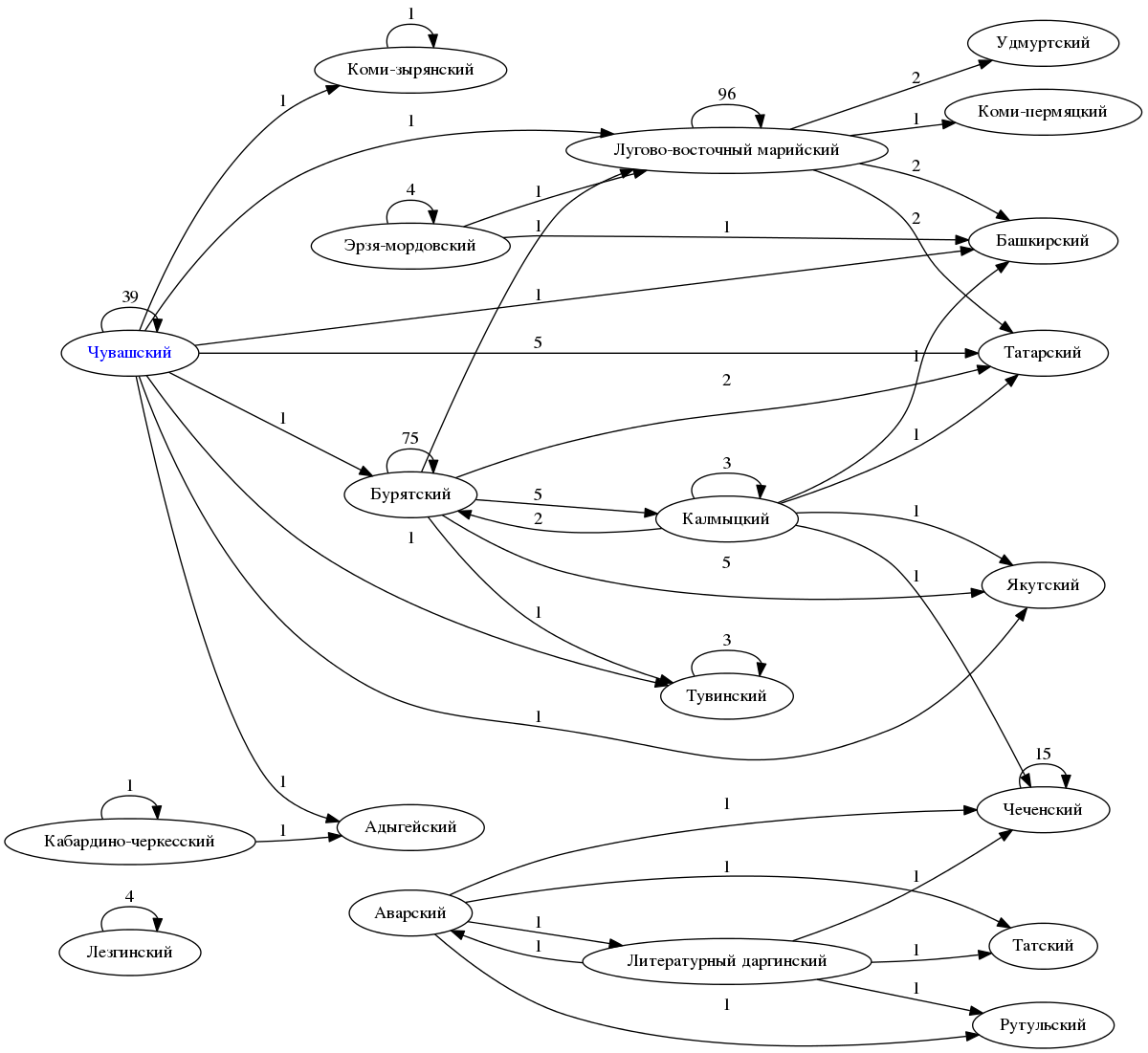
- "", , , . , : , , , . , , , .
, . , , , , , .
, -, ?
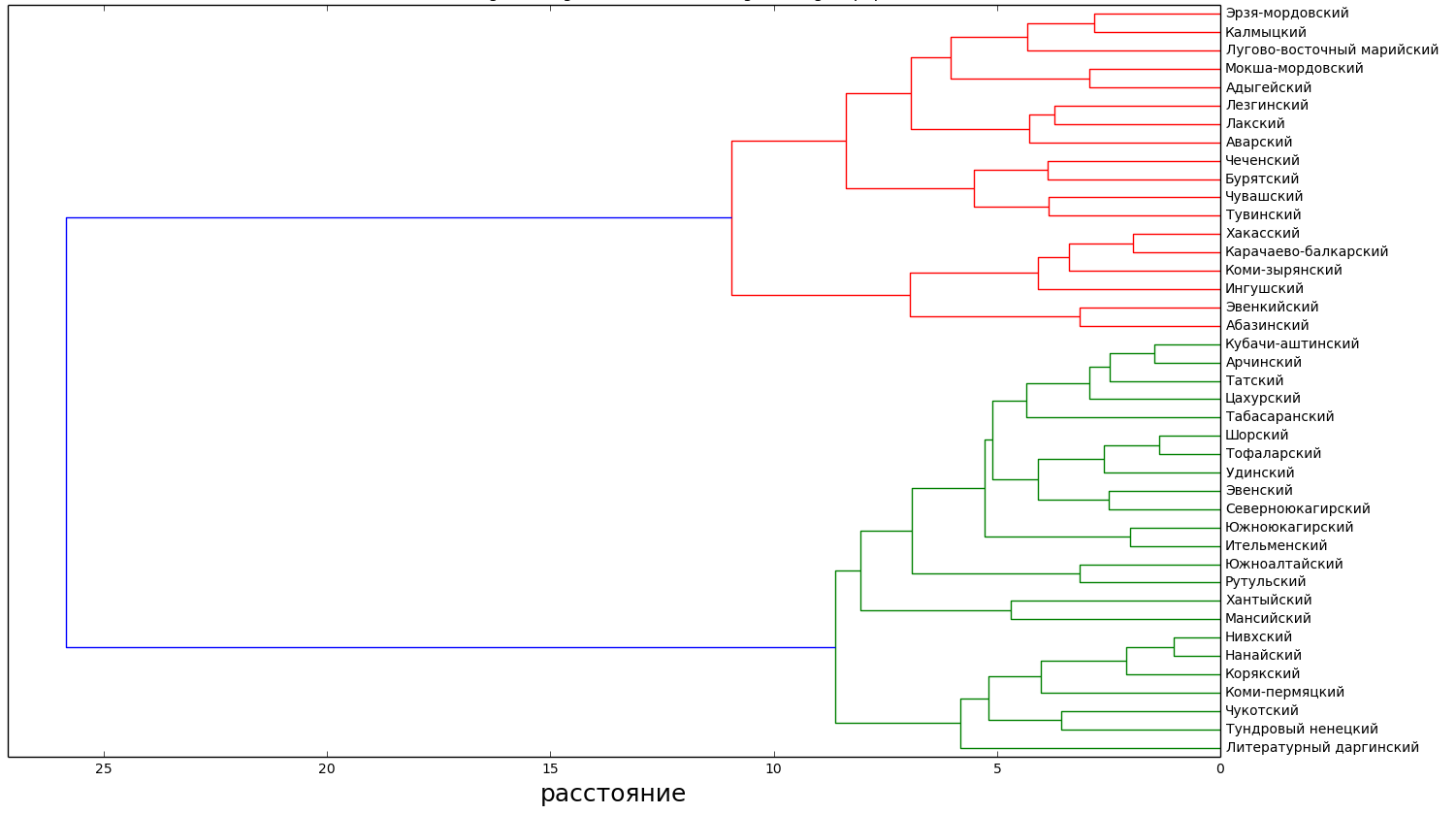
, , : - , , - , , .
Social networks
, vk.com. - , - , : , . . .
:
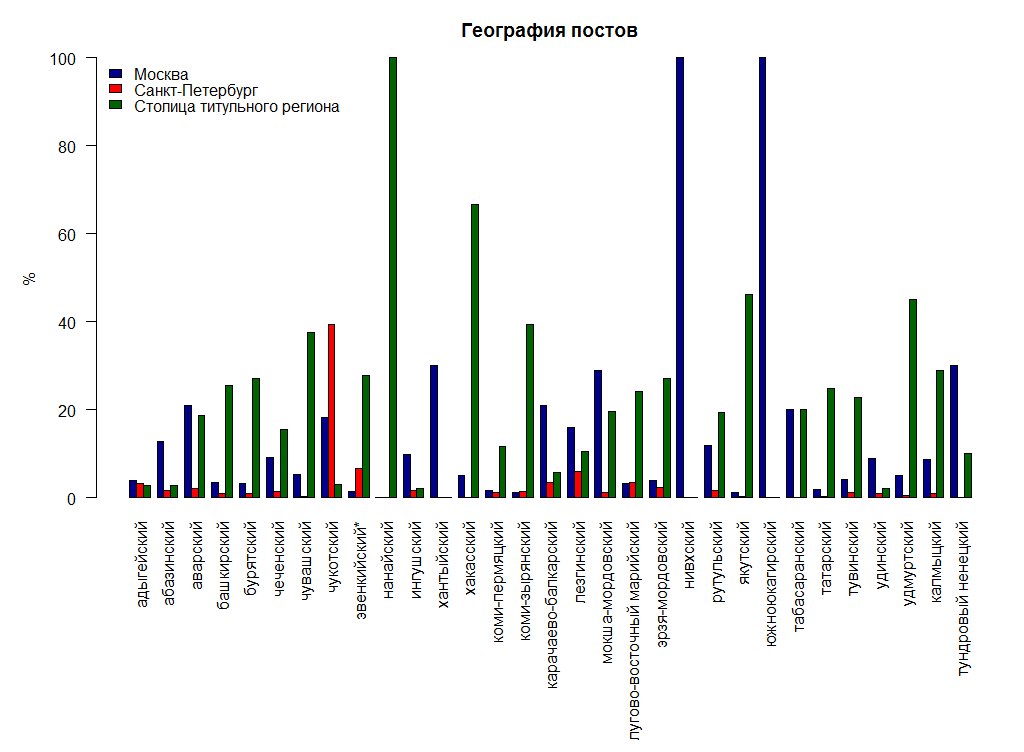
, , , , — . , — . , , . . , .
- ?
, «» :
?
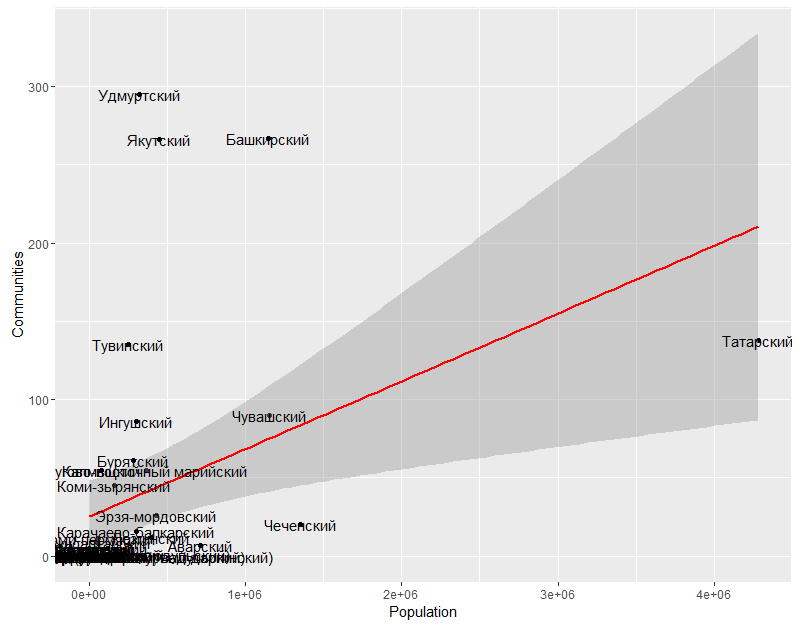
- . , , . , , . , 90- 2000-.
, , . , 2012 . , «» . , « ». , , - (, ). , « », , .
, .
. .
vk.com .