Back in early November 2017, Qualcomm Datacenter Technologies (QDT) completed work on its new brainchild - a processor based on 10-nm technology - Centriq 2400. What future does the industry have in the opinion of the creators of this innovation? What are the benefits of getting servers and why is the Centriq 2400 so unique? About this and not only read further.
On November 8, a press conference of the QDT company was held in San Jose (California), at which the start of supplying the new processor was officially announced. Anand Chandrasecher, senior vice president and general manager of the company, said:
Today's presentation is an important achievement and culmination of more than 4 years of diligent design, development and support of the system ... We have created the most advanced server processor in the world, which provides high performance combined with a high level of energy efficiency, allowing our customers to significantly reduce their costs.
In addition to undisguised pride in their product, company representatives feel free to say that their Centriq 2400 processor significantly outperforms competing products, for example, Intel Xeon Platinum 8180. According to their calculations, for every dollar spent (and the cost of the processor is $ 1995), the user will get 4 times. And at recalculation in productivity on 1 watt - for 45% more. Bold statements, however, many of the representatives of various companies interested in the new product are more than happy to hear them.
Technical data of Qualcomm Centriq 2400
CPU architecture:- up to 48 64-bit cores with a peak frequency of 2.6 GHz;
- Armv8-compatible;
- only AArch64;
- Armv8 FP / SIMD;
- CRC and Armv8 Crypto extension;
CPU cache:- 64 KB cache commands (instructions) L1 and 24 KB single-cycle cache L0;
- 32 KB L1 data cache;
- 512 KB of shared L2 cache for every 2 cores;
- 60 MB of shared L3 cache;
- filtering interprocessor requests L2;
- QoS;
where, L (L1, L2, L3, L0) is the level, i.e. L0 - zero level.Technology:- 10-nm technology FinFET from Samsung;
Memory Bandwidth:- 6 channels for connecting DDR4 memory modules;
- up to 2667 MT / s per connection;
- 128 GB / s - the maximum total bandwidth;
- Built-in bandwidth compression;
Memory:- 768 GB = 128 GB x 6 connections;
Memory Type:- 64-bit DDR4 connectivity with 8-bit ECC;
- RDIMM and LRDIMM;
Supported interface:- GPIO;
- I²C;
- SPI;
- 8-band SATA Gen 3;
- 32 PCIe Gen3 with the ability to connect up to 6 PCIe controllers;
In addition to the above characteristics, it is worth noting that this processor has 18 billion transistors on each chip. And all of its cores are connected by a bidirectional ring bus. At maximum load, the Centriq 2400 consumes only 120 watts.
The main focus of the new processor is still cloud solutions. According to the company, the Centriq 2400 will create a server system that will be characterized by high performance, efficiency and scalability.
This could not fail to attract many companies, cloud technologies for which are almost the basis of their activities. The presentation was attended by Alibaba, LinkedIn, Cloudflare, American Megatrends Inc., Arm, Cadence Design Systems, Canonical, Chelsio Communications, Excelero, Hewlett Packard Enterprise, Illumina, MariaDB, Mellanox, Microsoft Azure, MongoDB, Netronome, Packet, Red Hat, ScyllaDB, 6WIND, Samsung, Solarflare, Smartcore, SUSE, Synopsys, Uber, Xilinx. The list is quite impressive, which indicates increased attention to this product.
At the moment, the Qualcomm Centriq 2400 processor is only gaining momentum, both in prevalence and in popularity. That, of course, will lead to the emergence of something new, similar or even more productive, on the part of QDT competitors.
But not everyone blindly believes in the coolness of the novelty. If those who believe that conducting tests and benchmarking multiple processors will make it possible to see much more revealing results than the words of the promoters of Centriq 2400.
The company Cloudflare conducted a comparative analysis of three platforms: Grantley (Intel), Purley (Intel) and Centriq (Qualcomm).
The graphs of this analysis and the conclusions of their author,
Vlad Krasnov, will be presented below. (
The original of this analysis in the blog of the company Cloudflare )
Public key cryptography
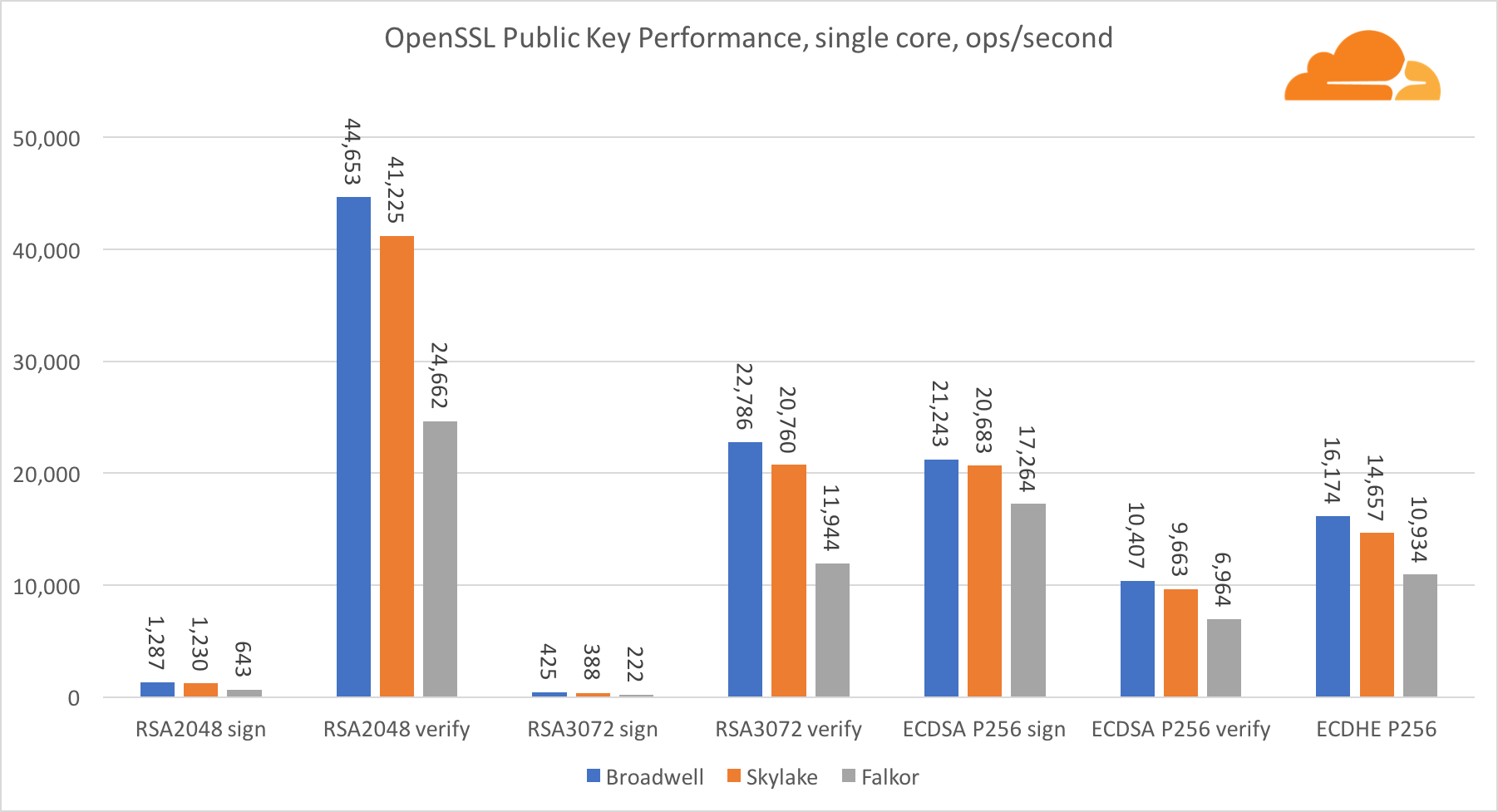
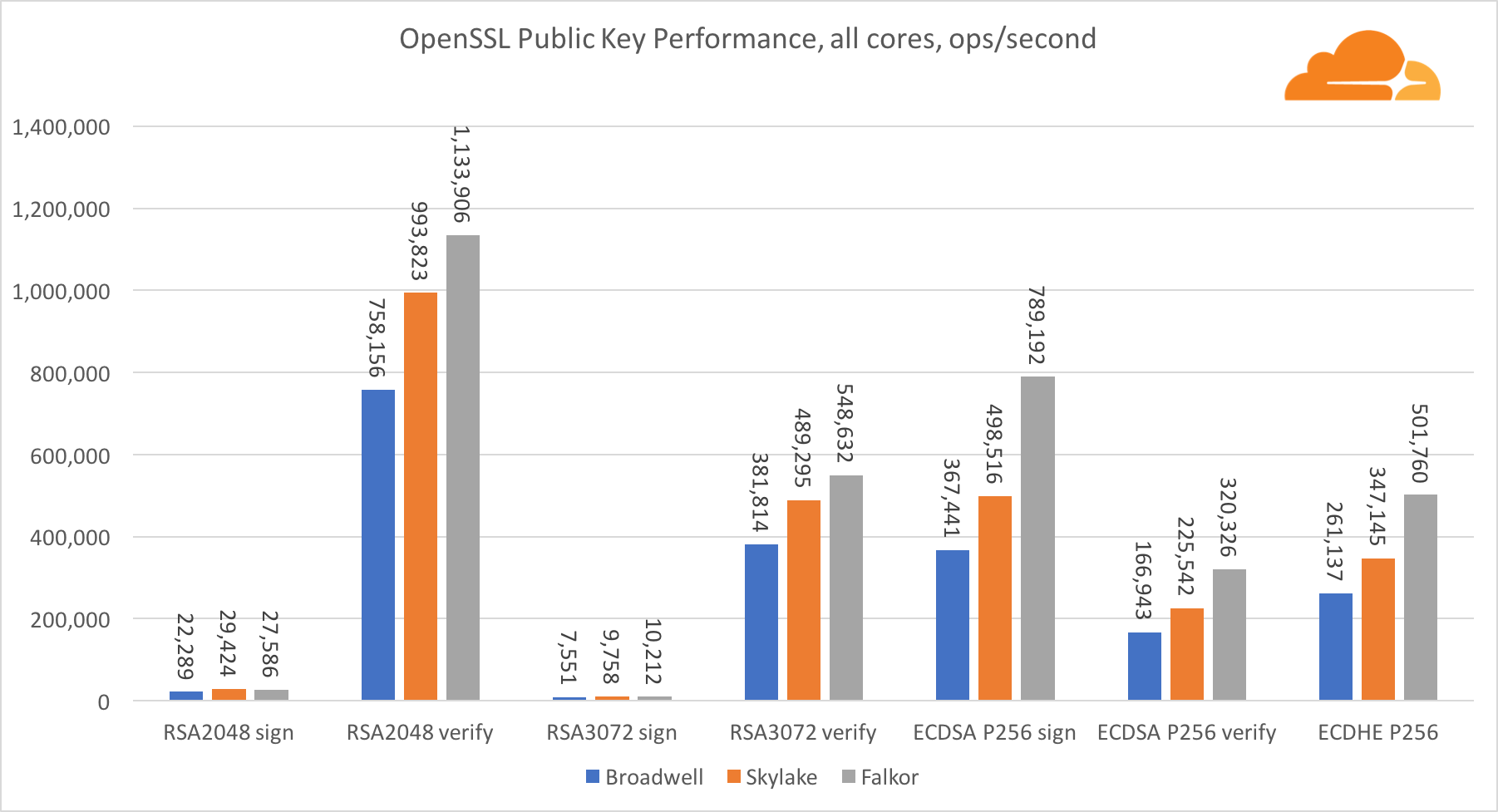
Public key cryptography is pure ALU performance (an arithmetic logic unit). It's interesting, but not surprisingly, that in one base benchmark the Broadwell core is faster than Skylake, and both of them in turn are faster than Falkor. This is because Broadwell operates at a higher frequency, although in architectural terms it is not much inferior to Skylake.
Falkor is inferior to the rest of this test. First, turbo mode was turned on in one of the base benchmarks, meaning that Intel processors run at a higher frequency. In addition, at Broadwell, Intel introduced two special instructions for speeding up the processing of large numbers: ADCX and ADOX. They perform two independent add-with-carry operations per cycle, while ARM can only perform one. Similarly, the ARMv8 instruction set does not have a single command for performing 64-bit multiplication; instead, a pair of instructions MUL and UMULH are used.
However, at the SoC level, Falkor wins. It is slightly slower than Skylake in terms of RSA2048, and only because RSA2048 does not have an optimized implementation for ARM. ECDSA performance is ridiculously high. A single Centriq chip can satisfy the needs of ECDSA for almost any company in the world.
It is also very interesting to see that Skylake surpasses Broadwell by 30%, despite the fact that it yielded one core to the test and has only 20% more cores than Broadwell. This can be explained by a more efficient turbo mode and improved hyperthreading.
Symmetric cryptography
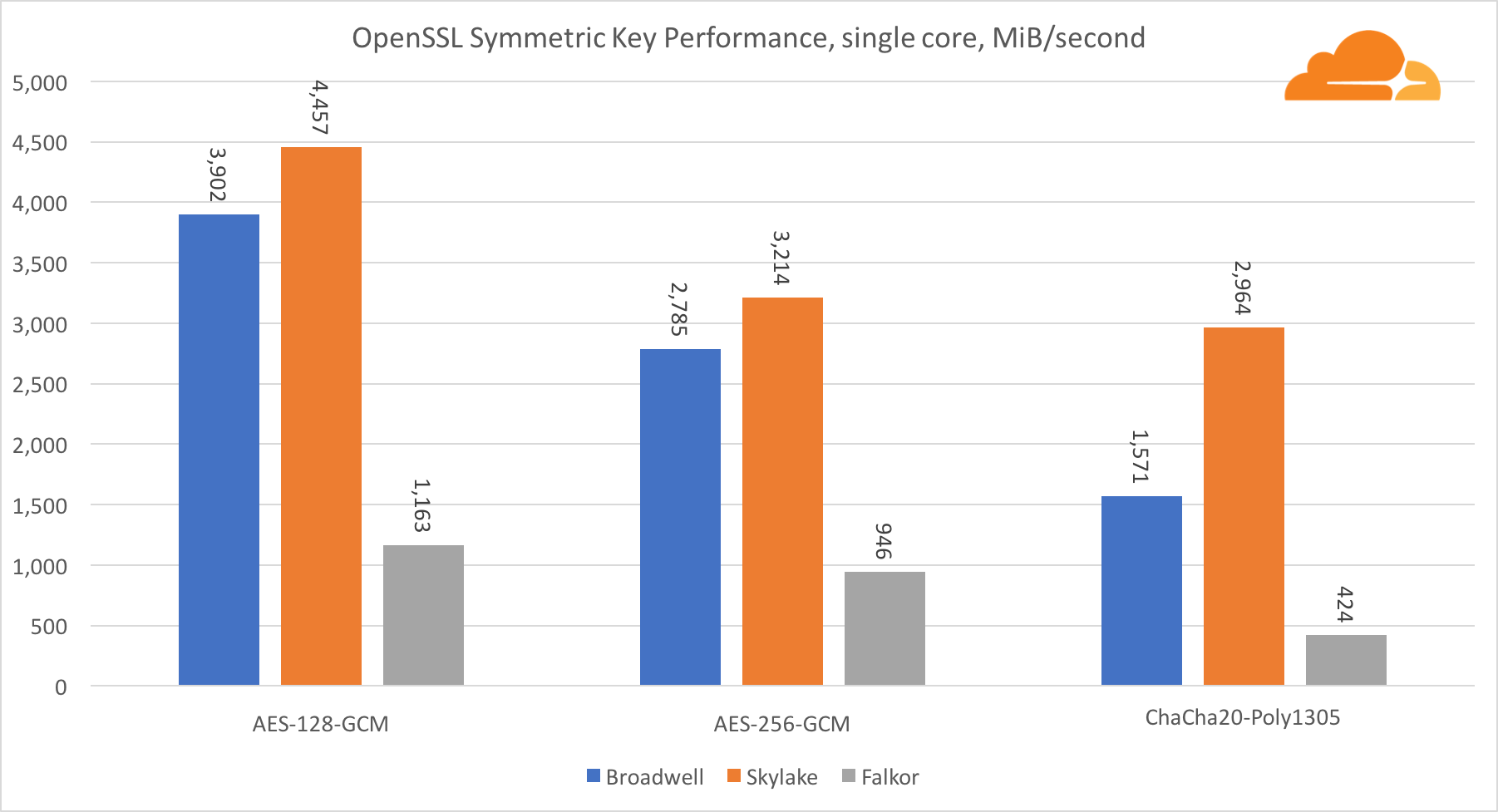
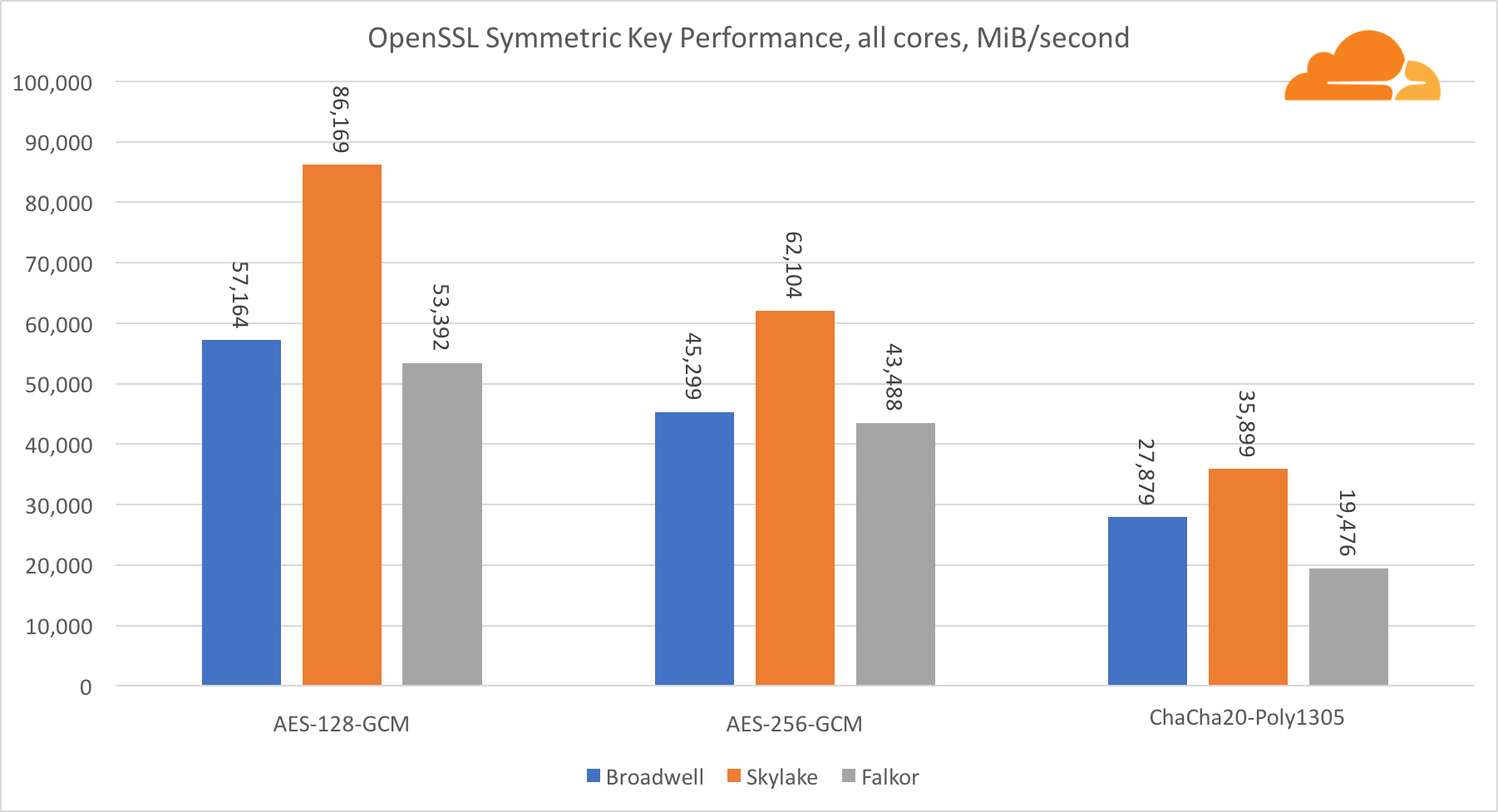
The performance of Intel cores in symmetric cryptography is simply superb.
AES-GCM uses a combination of special hardware instructions to speed up AES and CLMUL. Intel first introduced these instructions back in 2010, with their Westmere processor and with each generation, they improved their performance. Recently, ARM introduced a set of similar instructions with their 64-bit instruction set as an optional addition. Fortunately, every equipment supplier I know implemented them. It is very likely that Qualcomm will improve the performance of cryptographic instructions in future generations.
ChaCha20-Poly1305 is a more general algorithm designed to make better use of wide SIMD modules. The Qualcomm processor has only a 128-bit NEON SIMD, while the Broadwell has a 256-bit AVX2, and the Skylake has a 512-bit AVX-512. This explains why Skylake with such a margin went to the leaders in evaluating the work with one core. In the test of all cores at the same time, Skylake’s separation from the rest was reduced, since it must reduce the clock frequency when executing AVX-512 workloads. When running the AVX-512 on all cores, the base frequency is reduced to 1.4 GHz. Keep this in mind if you mix the AVX-512 and other code.
Conclusion regarding symmetric cryptography is that even though Skylake is in the lead, Broadwell and Falkor showed very good results, having a sufficiently high performance for real cases, given the fact that on our side RSA consumes more processor time than all other cryptoalgorithms combined .
Compression (compression)
The next test I wanted to do is compress. For two reasons. Firstly, this is an important workload, because the better the compression, the less need for capacity passes, and this allows for faster delivery of content to the client. Secondly, this is a very demanding workload with high frequency Branch misprediction.
Obviously, the first test will be the popular zlib library. At Cloudflare, we use an improved version of the library optimized for 64-bit Intel processors, and although it is written primarily in C, it uses some Intel-specific built-in functions. Comparing this optimized version with the original zlib would be unfair. But do not worry, a little effort and I adapted the library so that it worked on the ARMv8 architecture, using the properties of NEON and CRC32. Moreover, its speed is 2 times more than the original, for some files.
The second test is the new brotli library, written in C and allowing equal conditions for all platforms to be used.
All tests are conducted on HTML blog.cloudflare.com, in memory, just as NGINX performs streaming compression. Is a specific version of the HTML file 29329 bytes, which is a good indicator, since it corresponds to the size of most of the files that we compress. The parallel compression test is a parallel compression of several files simultaneously, a single compression of a single file into several streams, in the same way as NGINX works.
gzip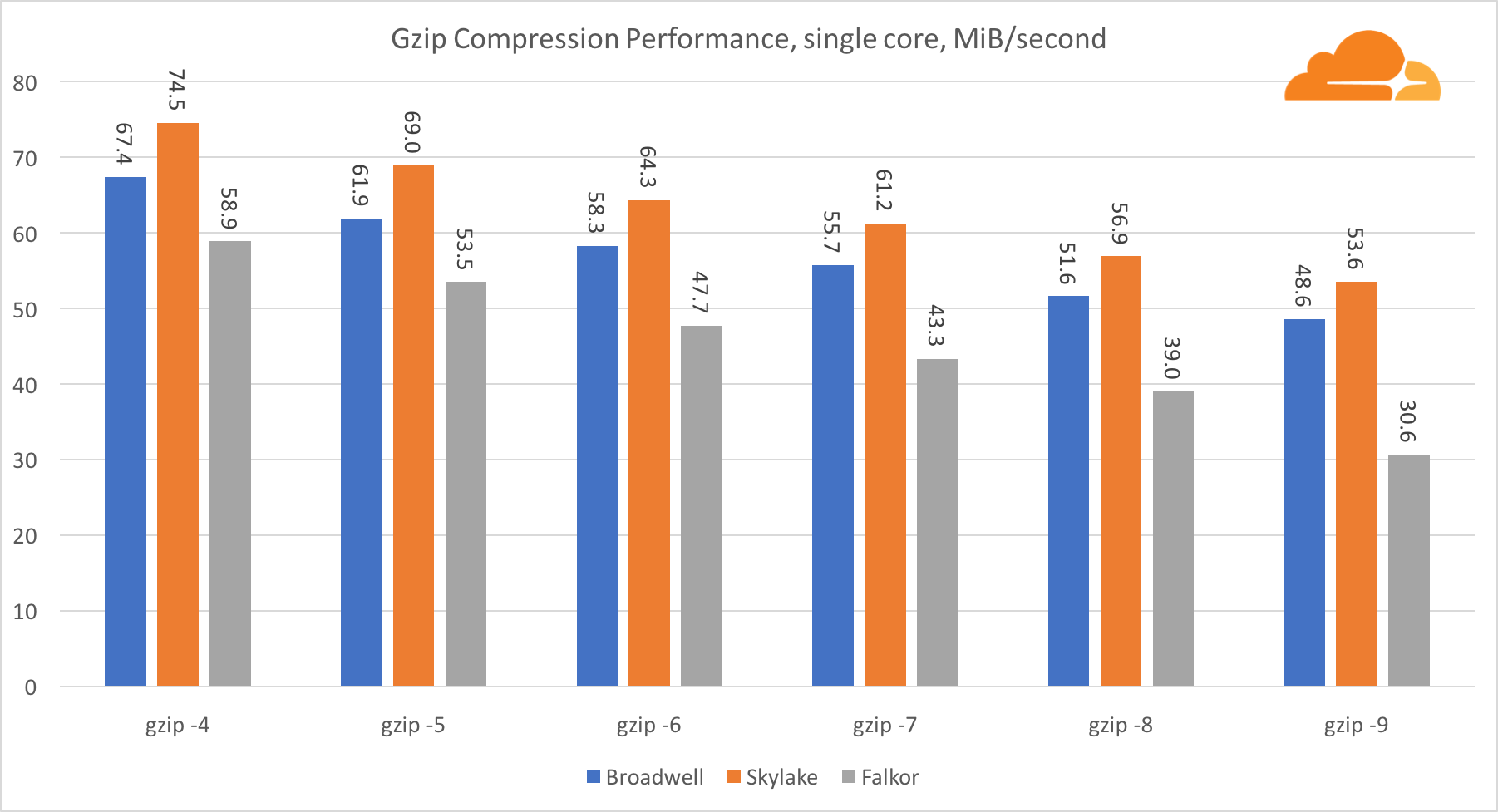
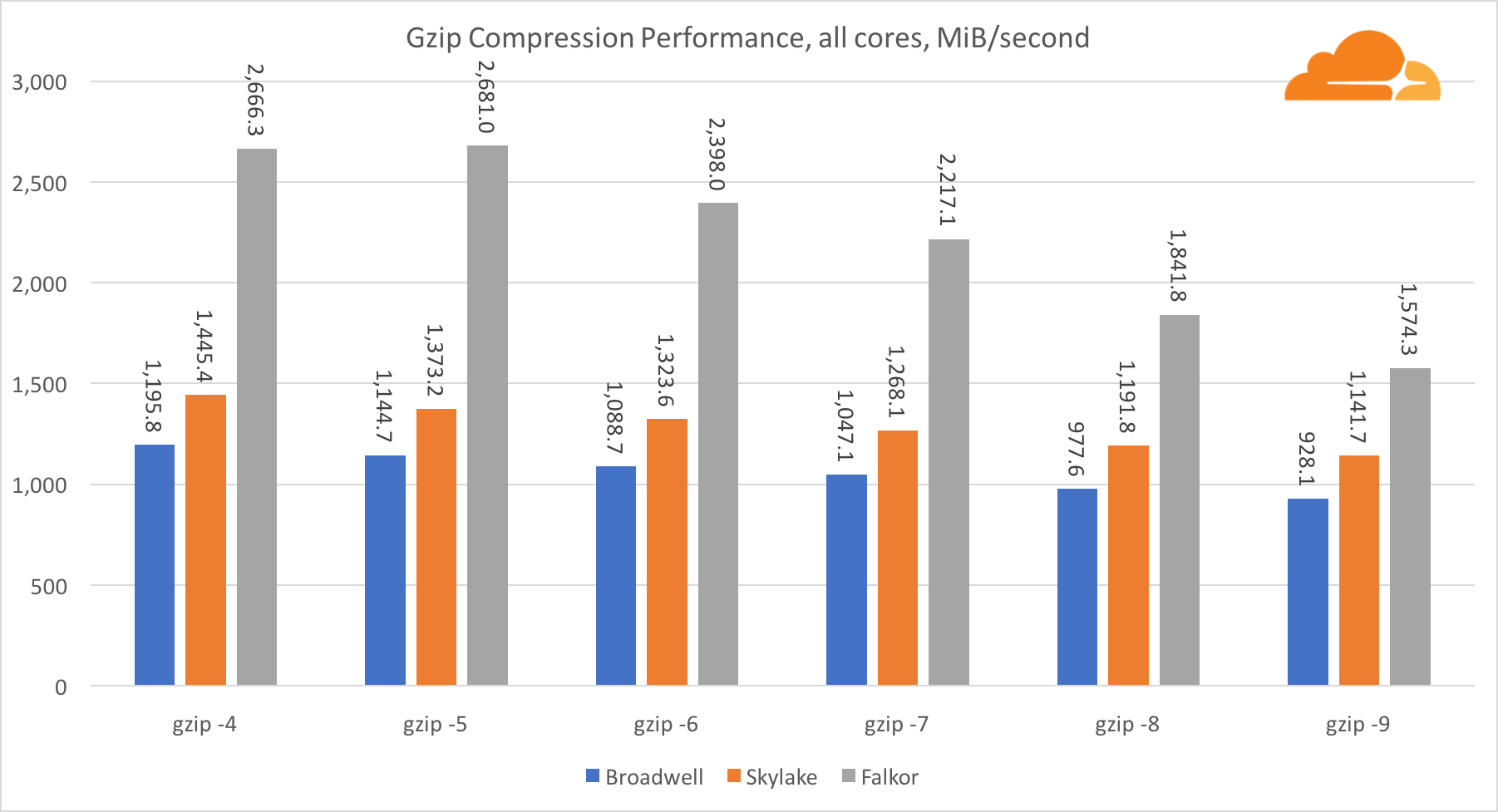
Using gzip at the level of one core, Skylake undoubtedly wins. With a lower frequency than Broadwell, Skylake benefits from lower branch misprediction. The Falkor kernel is not far behind. At the system level, Falkor performs much better, due to the larger number of cores. Notice how gzip scales well on multiple cores.
BrotliWith brotli on one core, the situation is similar to the previous one. Skylake is the fastest, but Falkor is not very far behind. And on standard 9, Falkor is even faster. Brotli with standard 4 is very similar to gzip level 5, while actual compression is still better (8010B vs. 8187B).
Pr compression on multiple cores, the situation becomes a bit confusing. For levels 4, 5 and 6 brotli scales very well. At level 7 and 8, productively, the core begins to fall, dropping to the bottom at level 9, where we get 3 times less performance of all the cores compared to one.
In my opinion, this is due to the fact that with each level brotli begins to consume more memory and destroys the cache. Indicators begin to recover already at level 10 and 11.
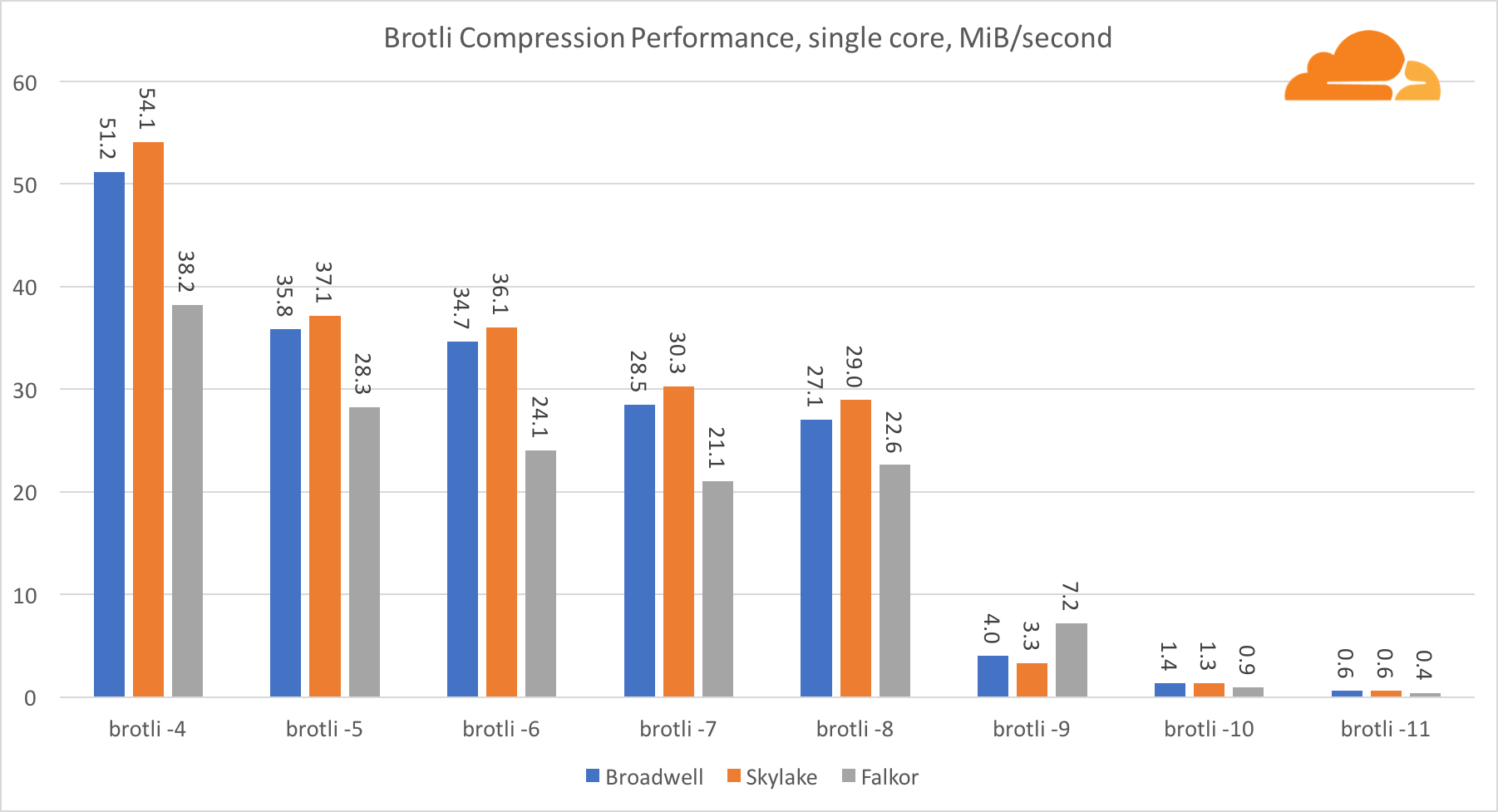
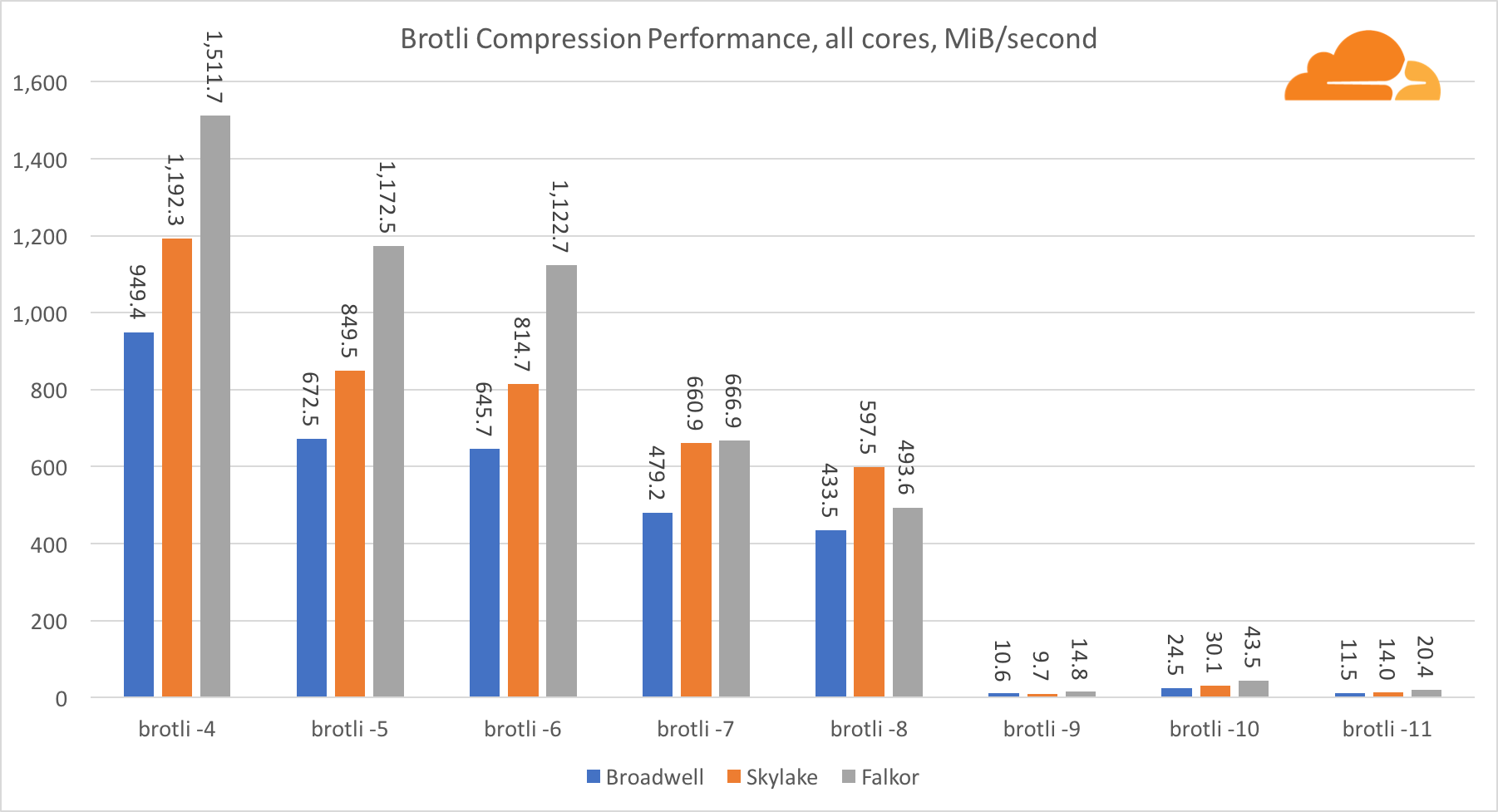
As a conclusion, Falkor won, given that dynamic compression will not go above level 7.
Golang
Golang is another very important language for Cloudflare. It is also one of the first languages to support ARMv8, so you can expect good performance. I used some built-in tests, but modified them for multiple goroutines.
Go cryptoI would like to start with encryption performance tests. Due to OpenSSL, we have excellent source data, and it will be very interesting to see how good the Go library is.
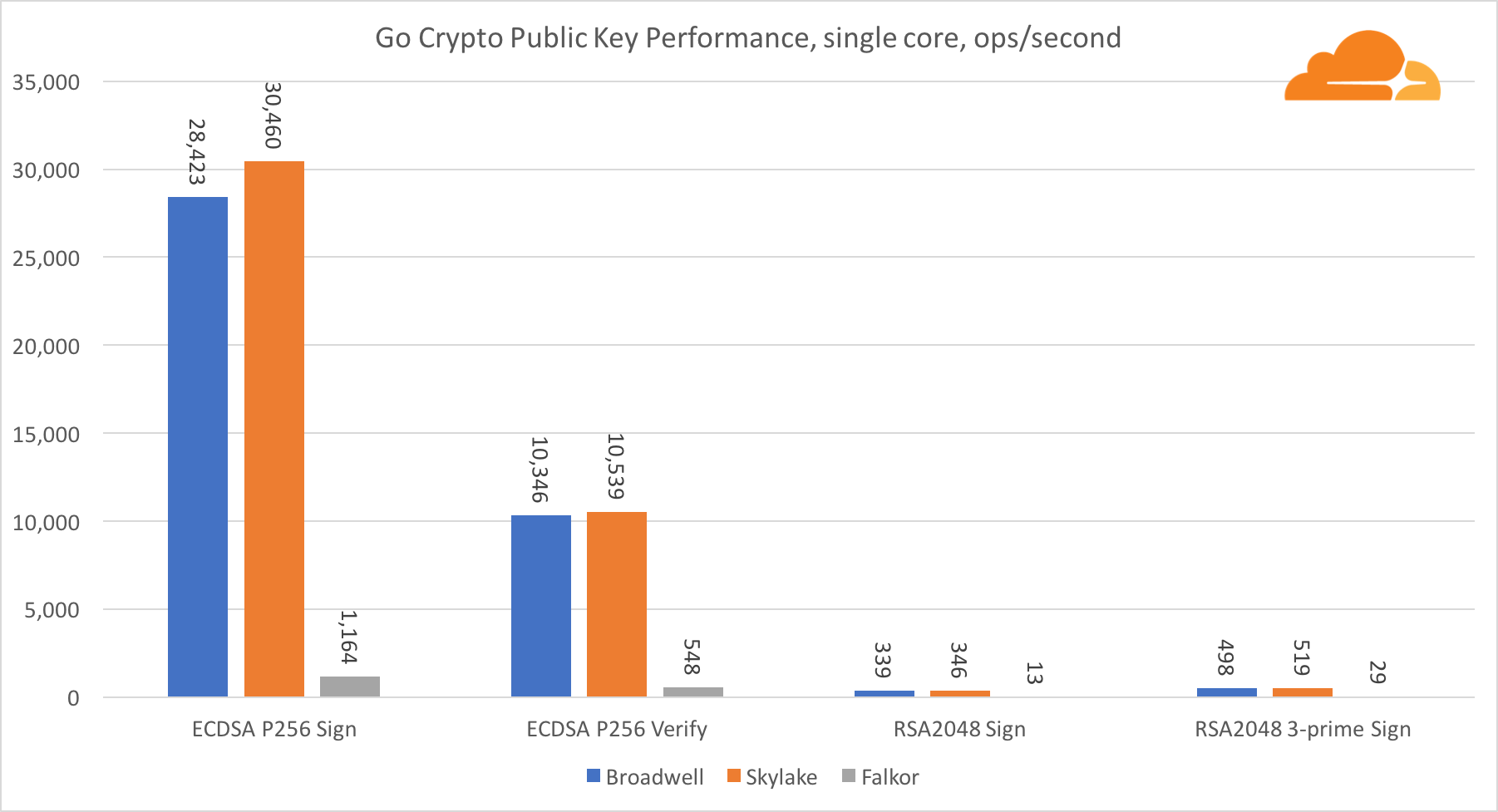
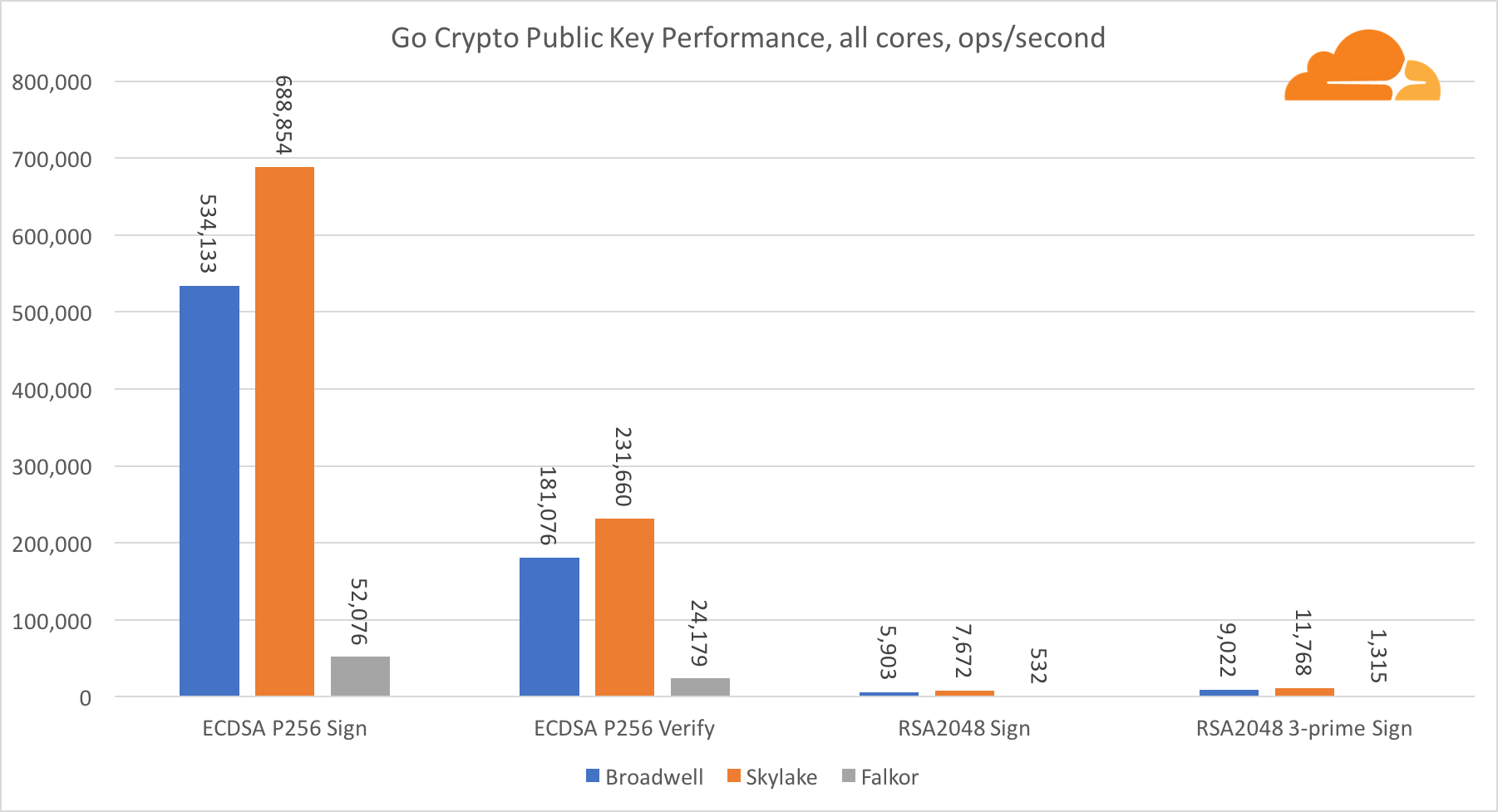
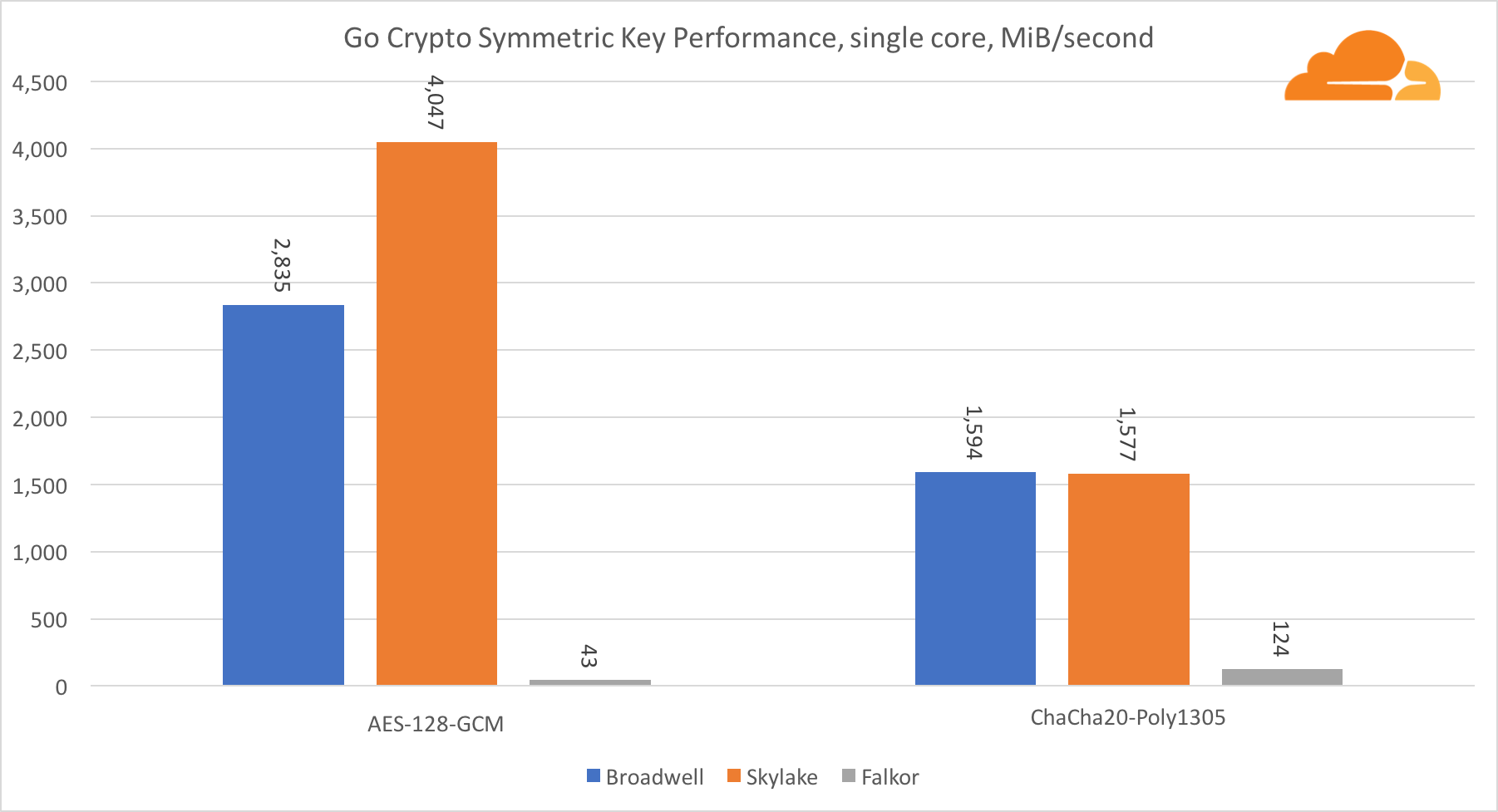
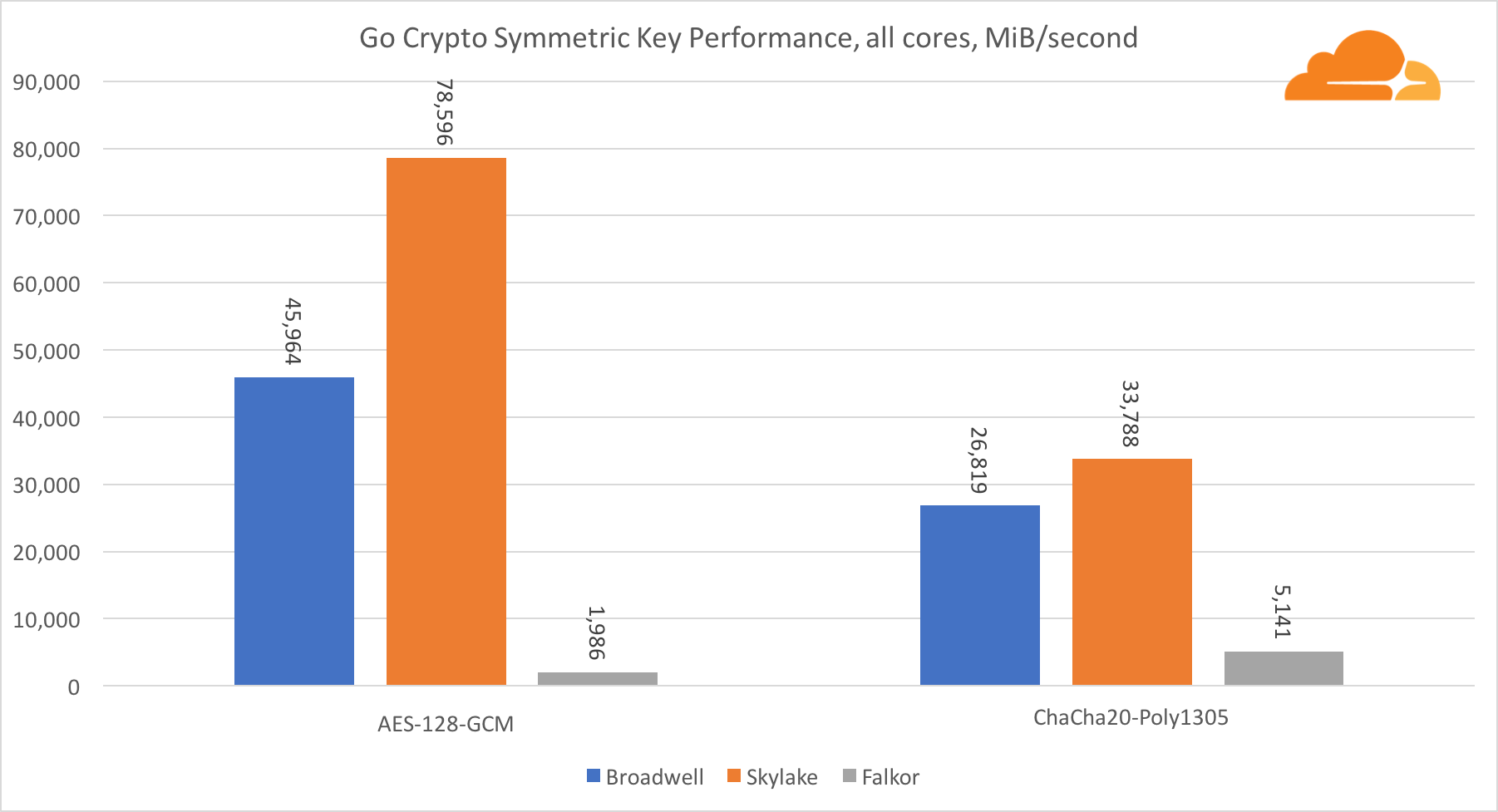
Regarding Go crypto, ARM and Intel are not even in the same weight category. Go has a perfectly optimized assembler code for ECDSA, AES-GCM and Chacha20-Poly1305 on Intel. There are also optimized math functions used in RSA calculations. ARMv8 doesn't have all this, which puts it at a very disadvantage.
However, the gap can be bridged with relatively little effort, and we know that with proper optimization, performance can be on par with OpenSSL. Even very minor changes, such as the implementation of the addMulVVW function in an assembly, lead to a more than tenfold increase in RSA performance, placing Falkor (with an indicator of 8009) above both Broadwell and Skylake.
Another interesting thing to note is that on Skylake, the Go Chacha20-Poly1305 code that uses AVX2 works in much the same way as the OpenSSL AVX512 code. Again, this is due to the fact that the AVX2 operates at higher clock speeds.
Go gzipNow let's take a look at Go performance from gzip. There is also a great reference point for a fairly well-optimized code, and we can compare it with Go. In the case of the gzip library, there are no specific optimizations for Intel.
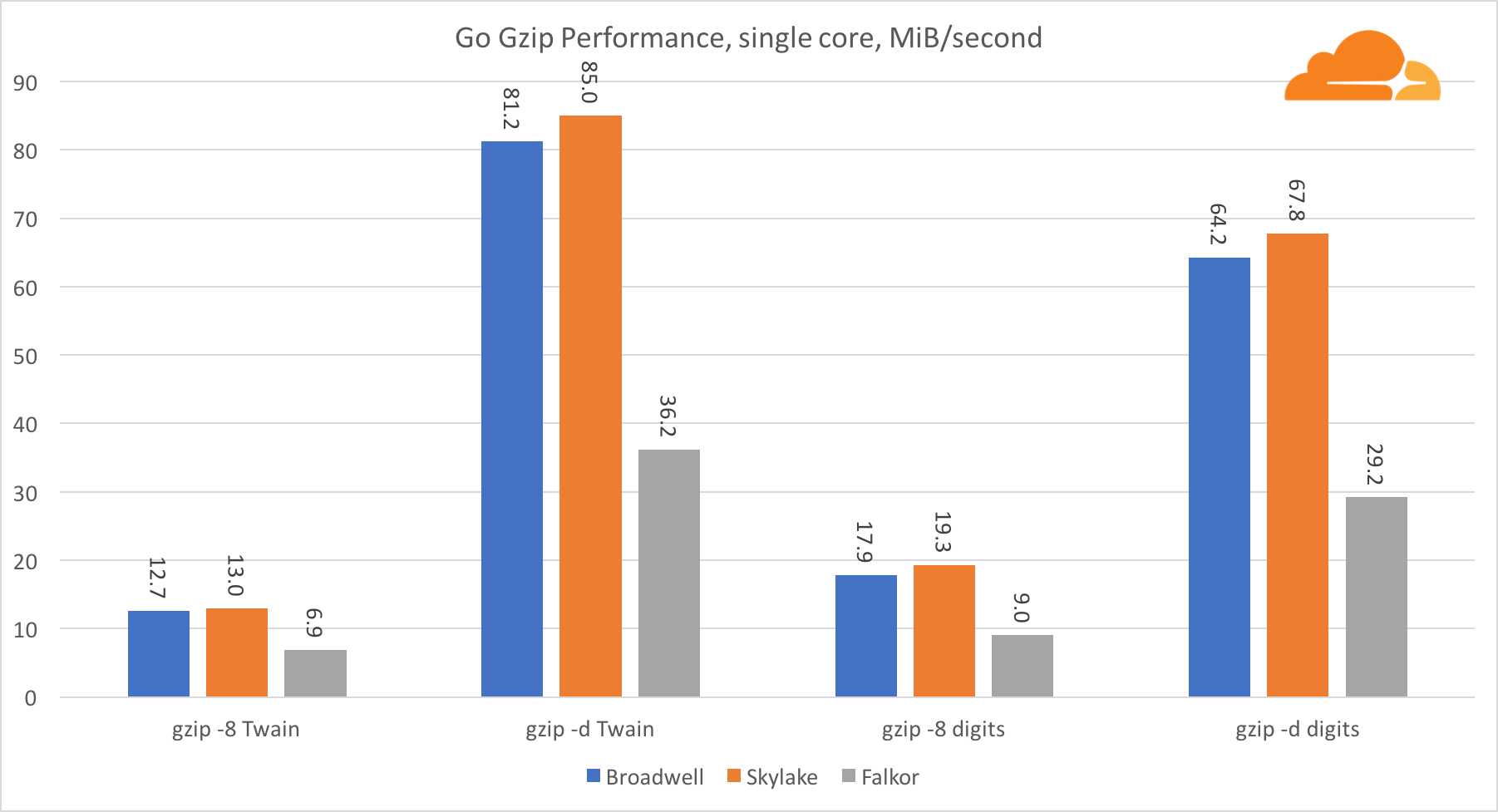

The gzip performance is pretty good. Performance on a single Falkor core lags far behind both Intel processors, but at the system level it managed to outperform Broadwell and position itself below Skylake. Since we already know that Falkor is superior to the other two processors when C is working. This can mean only one thing - the Go back end for ARMv8 is still not refined compared to gcc.
Go regexpRegexp is widely used in a variety of tasks, because its performance is also extremely important. I ran embedded tests on 32 KB threads.
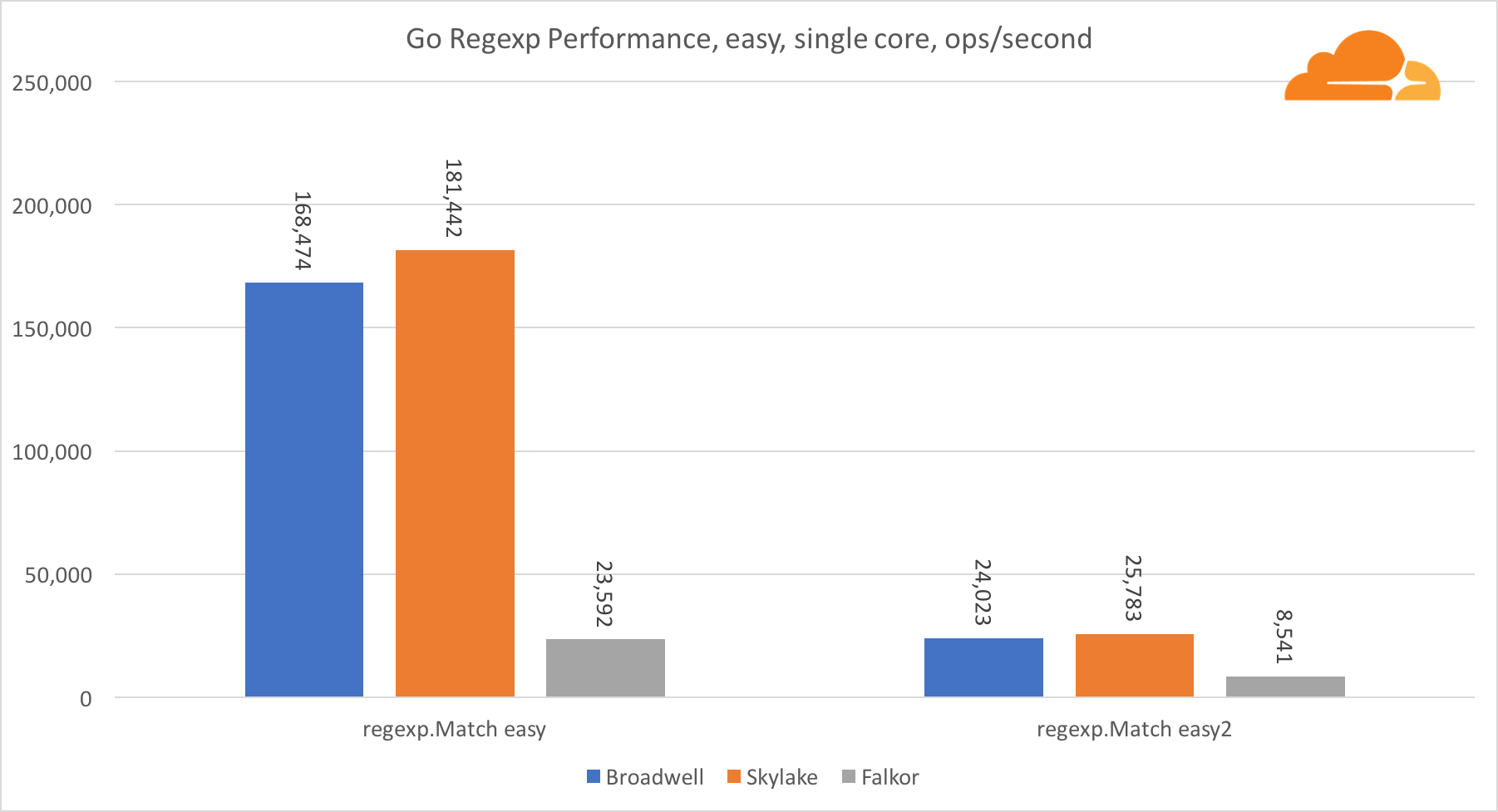
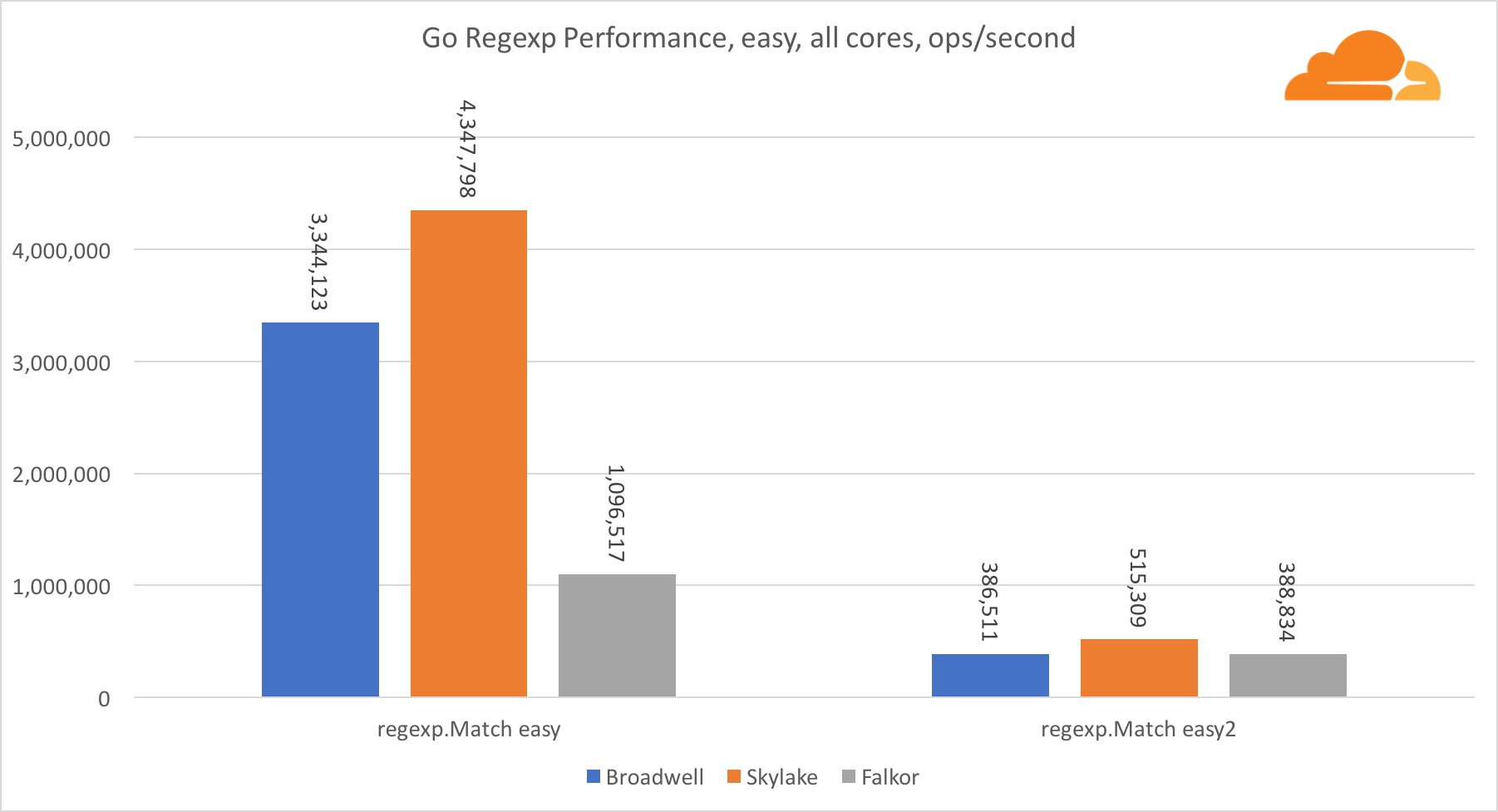
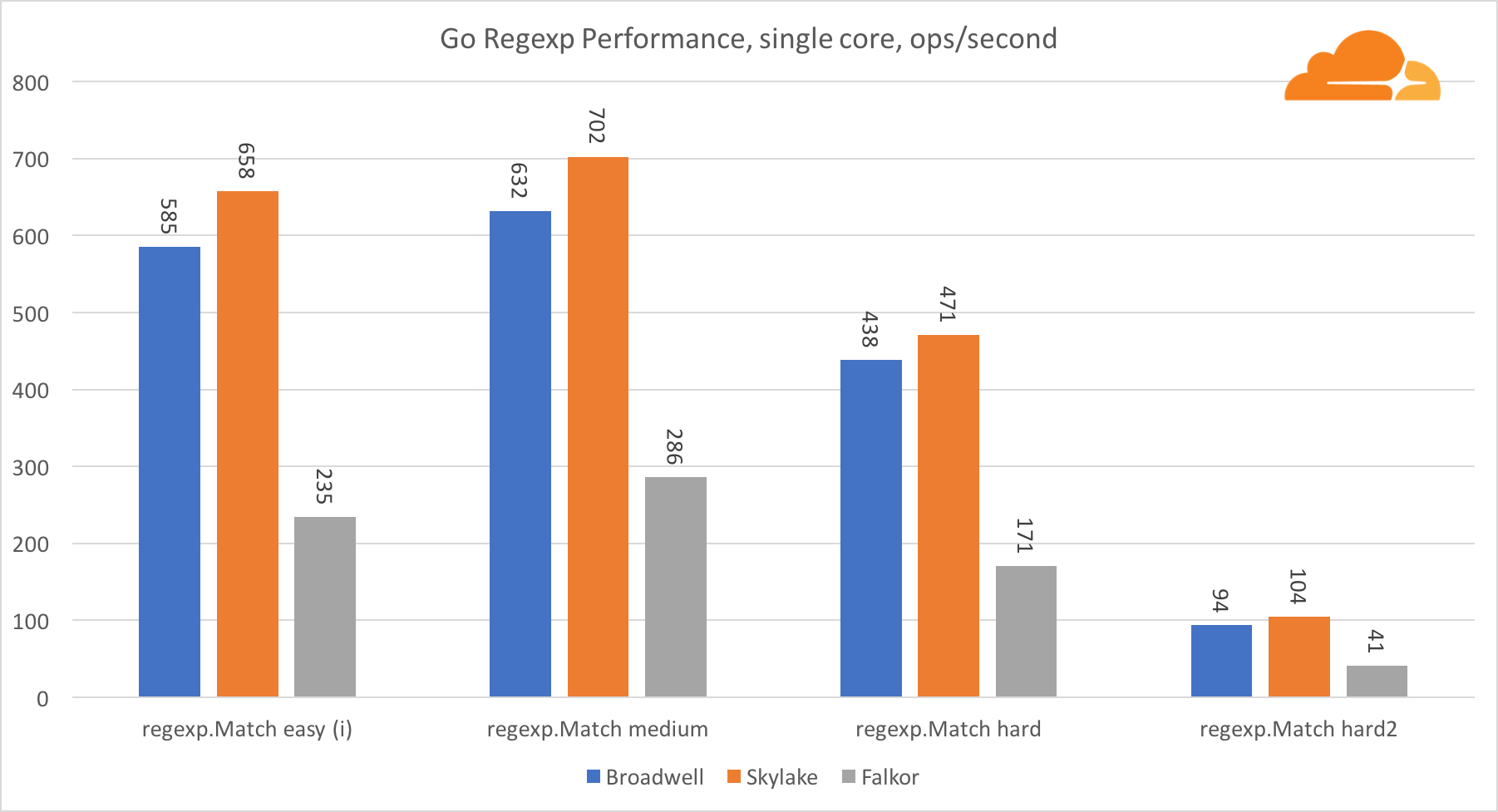
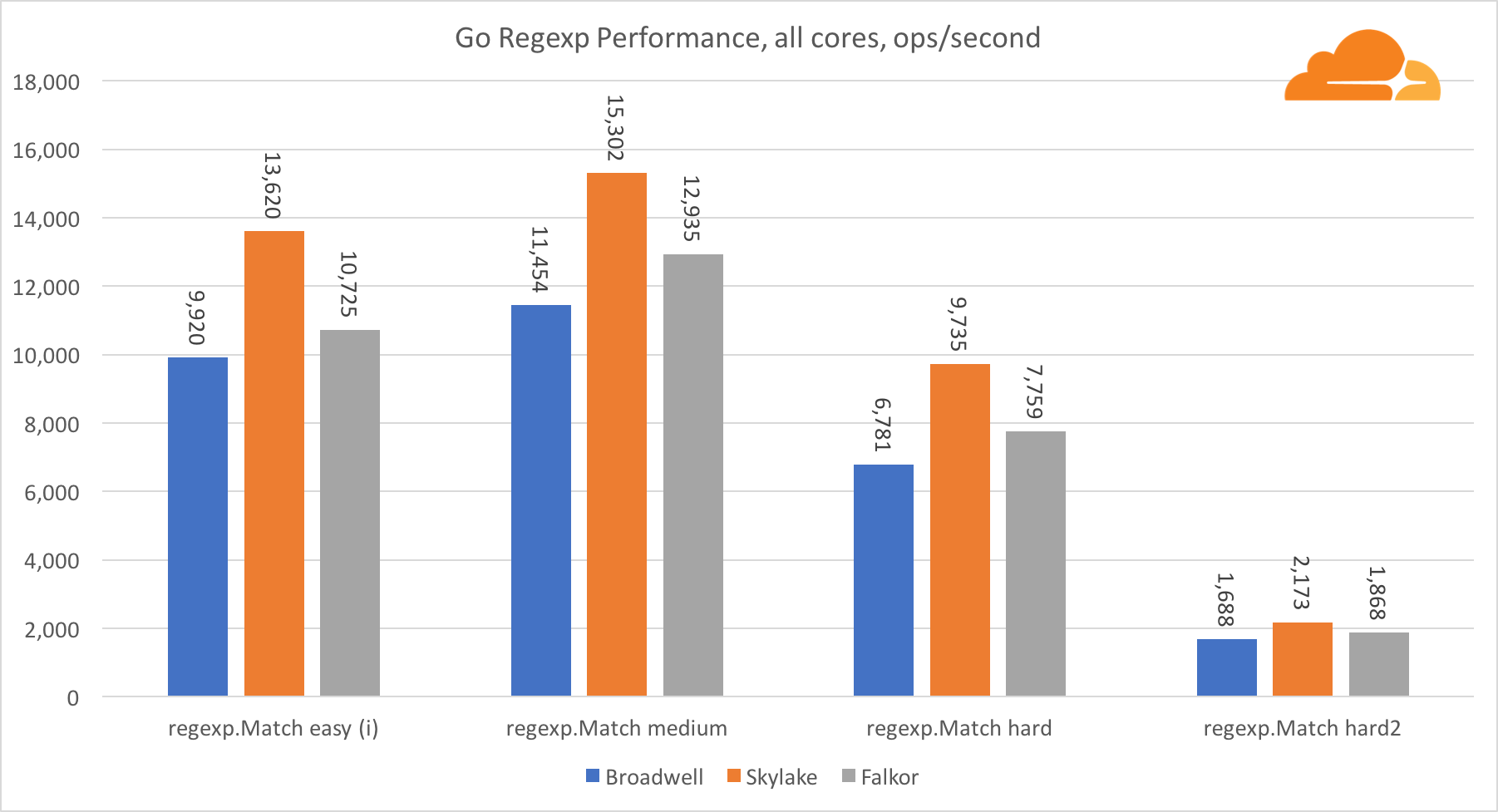
On Falkor, Go regexp performance is not very good. On medium and difficult tests, it ranks second due to a larger number of cores, but, nevertheless, Skylake is much faster.
A more detailed review of the process shows that a lot of time is spent on the bytes.IndexByte function. This function has an assembler implementation for amd64 (runtime.indexbytebody), but the main implementation for Go. During the light tests, regexp spent even more time in this function, which explains an even larger gap.
Go stringsAnother important library for a web server is Go strings. I tested only the main Replacer class.
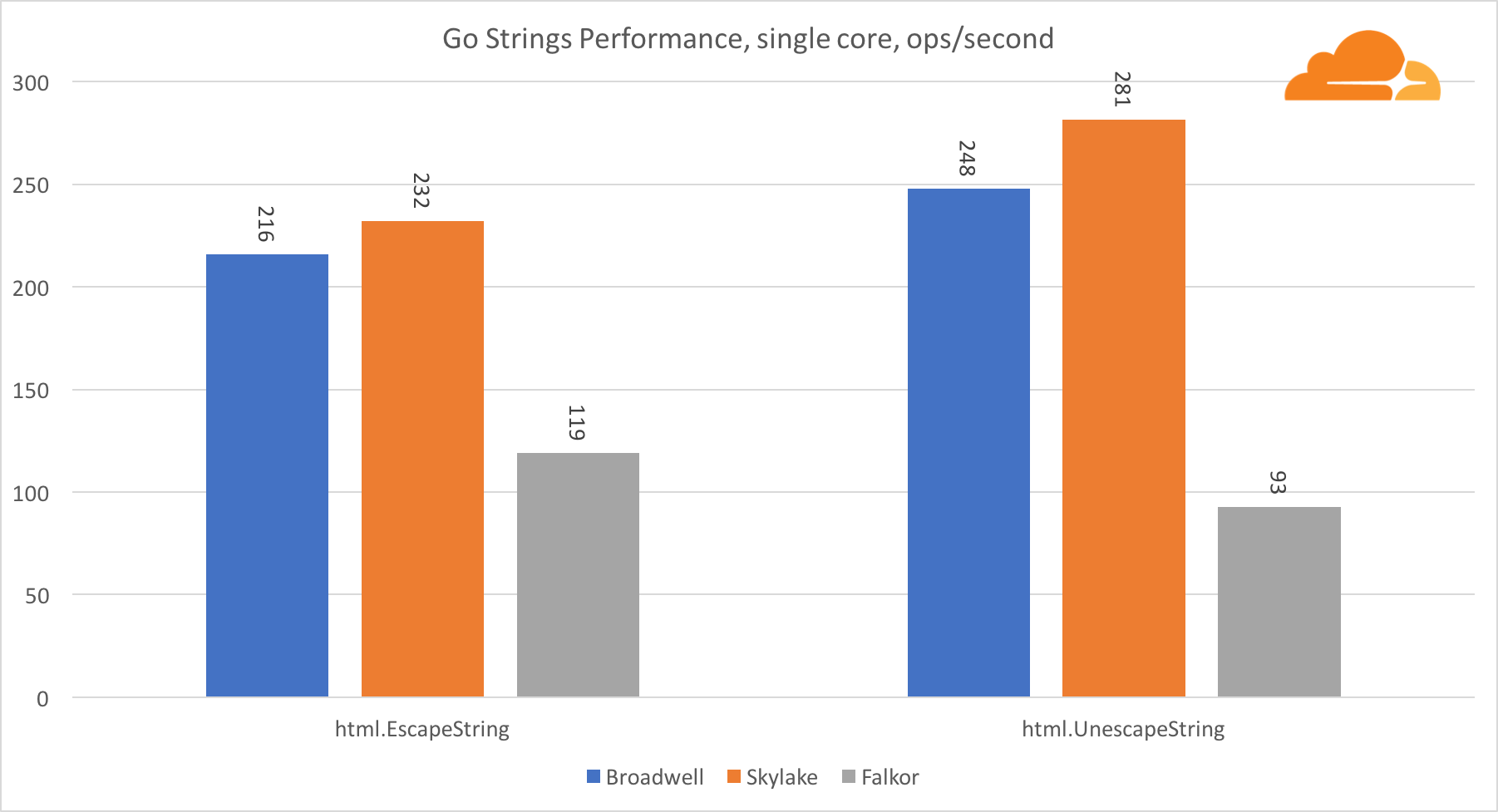
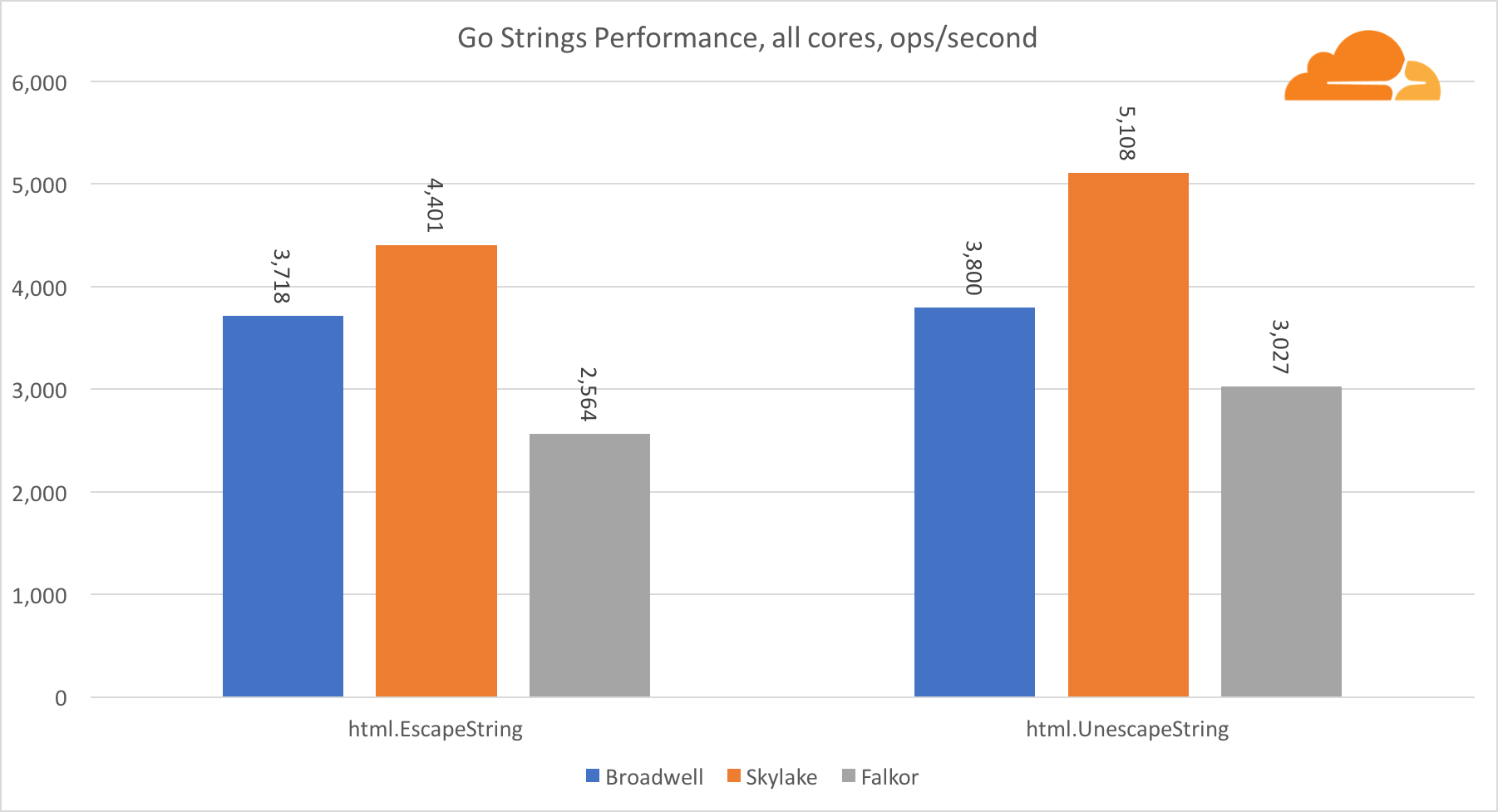
In this test, Falkor again lags behind, yielding even Broadwell. A detailed review shows a long stay in the runtime.memmove function. You know what? It has a perfectly optimized assembler code for amd64, which uses AVX2, but only the simplest assembler, which copies 8 bytes at a time. By changing 3 lines in this code and using the LDP / STP instructions (pair loading / pair storage) you can copy 16 bytes at a time, which increased memmove performance by 30%, which, in turn, speeds up EscapeString and UnescapeString by 20%. And this is just the tip of the iceberg.
Output to goGo support on aarch64 is rather disappointing. I am happy to say that everything compiled and worked perfectly, but from the performance side it could be better. It seems that most of the effort was spent on the compiler backend, and the library was almost intact. There are many low-level optimizations, for example, my addMulVVW fix, which took 20 minutes. Qualcomm and other suppliers of ARMv8 intend to spend significant technical resources to remedy the situation, but anyone, in fact, can contribute to Go. Therefore, if you want to leave your mark on history, now is the time.
LuaJIT
Lua is the glue that holds Cloudflare together.
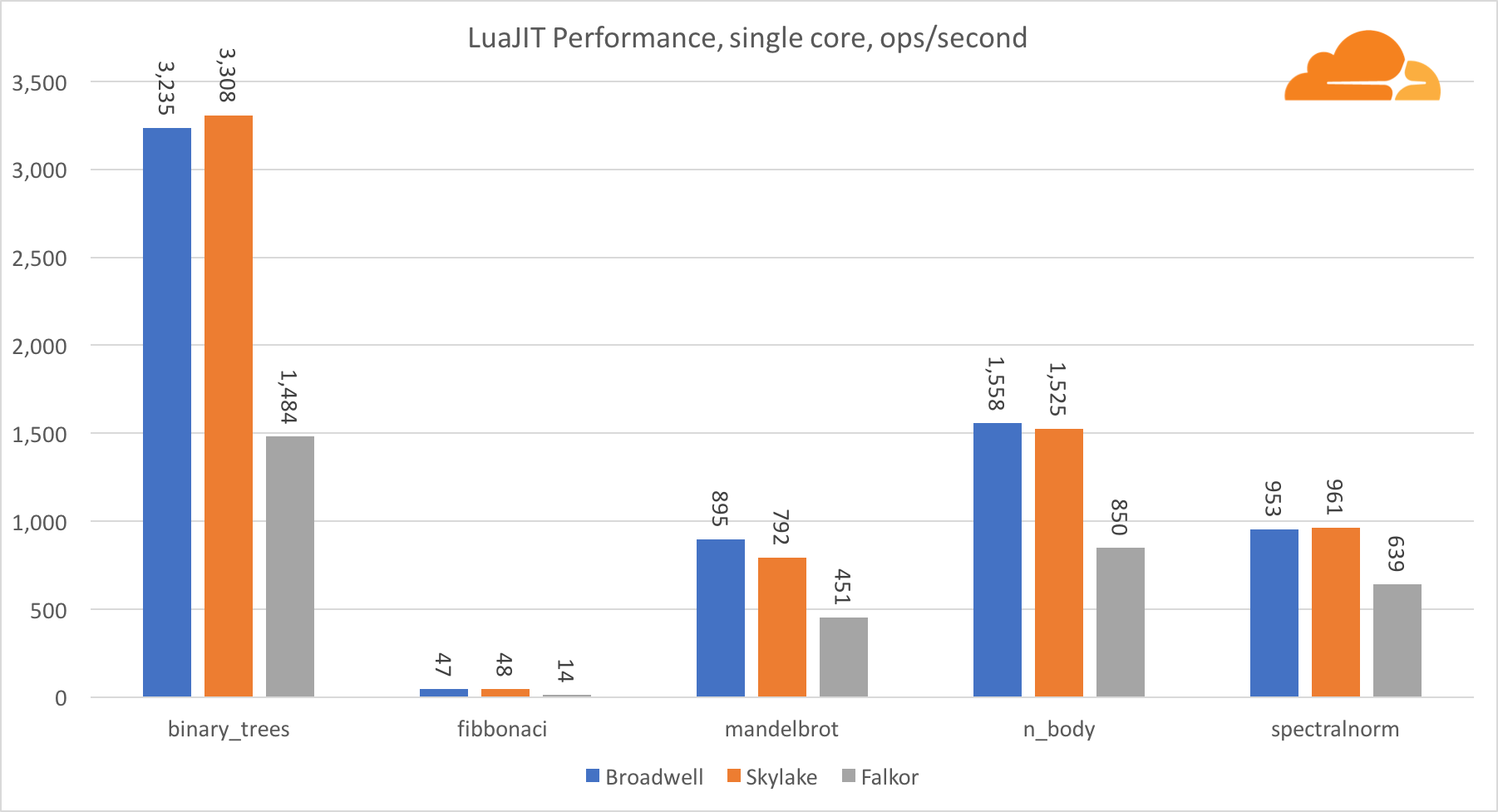
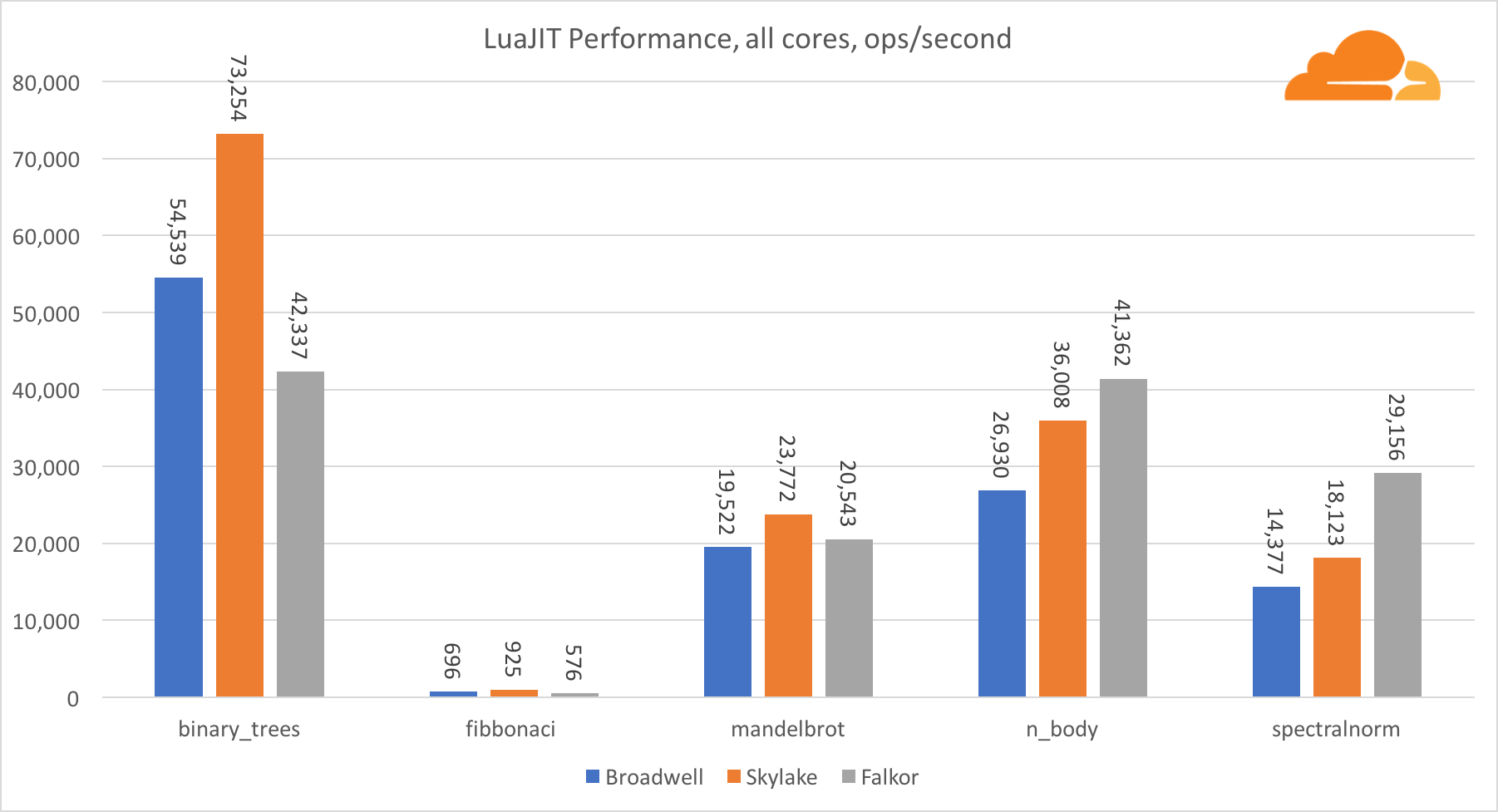
With the exception of the binary_trees test, the performance of LuaJIT at ARM is very competitive. Two tests he wins, and the third is nose to nose with competitors.
It is worth noting that the binary_trees test is extremely important, since it involves many cycles of memory allocation and garbage collection. It requires a more thorough consideration in the future.
Nginx
As a NGINX workload, I decided to create one that would resemble an actual server.
I set up a server that serves the HTML file used in the gzip test, on top of https, using the ECDHE-ECDSA-AES128-GCM-SHA256 cipher suite.
It also uses LuaJIT to redirect the incoming request, remove all line breaks and additional spaces from the HTML file when adding a timestamp. HTML is then compressed using brotli 5.
Each server was configured to work with as many users as virtual processors. 40 for Broadwell, 48 for Skylake and 46 for Falkor.
As a client for this test, I used the hey program, running from 3 Broadwell servers.
Simultaneously with the test, we took the power readings from the corresponding BMC blocks of each server.
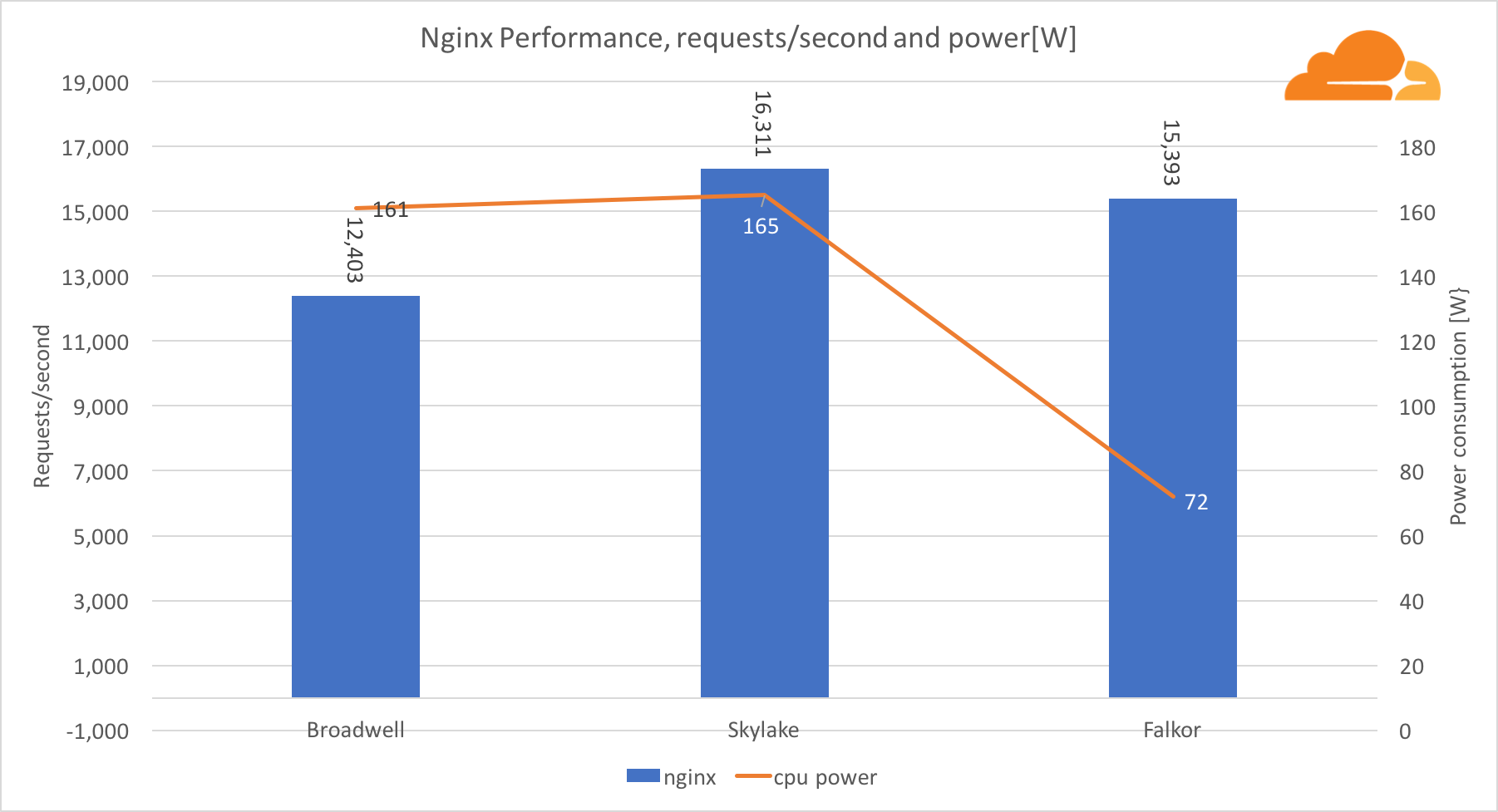
With the NGINX workload, Falkor handled almost the same number of requests as the Skylake server, and both are well ahead of Broadwell. The power readings taken from the BMC show that this happened at a power consumption of half less than other processors. This means that Falkor managed to get 214 requests / W, Skylake - 99 requests / W and Broadwell - 77 requests / W.
I was surprised that Skylake and Broadwell consume approximately the same amount of energy, given that they are produced the same way, and Skylake has more cores.
The low power consumption of Falkor is not surprising, since the processors from Qualcomm are known for their high energy efficiency, which allowed them to occupy a dominant position in the market of processors for mobile devices.
Conclusion
The sample of Falkor that we received really hit me. This is a huge step forward compared to previous attempts in ARM-based servers. Of course, comparing the core with the core, Intel Skylake is much better, but if you look at the system level, the performance becomes very attractive.
The production version of the Centriq SoC will contain 48 Falkor cores operating at a frequency of up to 2.6 GHz, which gives a potential performance increase of 8%.
Obviously, the Skylake we are testing is not a flagship like Platinum with its 28 cores, but these 28 cores cost a lot and consume 200W, while we try to optimize our costs and increase performance by 1 watt.
At the moment, I am most worried about the poor performance of the Go language, but this will change as soon as ARM-based servers find their niche in the market.
Performance C and LuaJIT are very competitive, and in many cases superior to Skylake. In almost all tests, Falkor proved to be a worthy replacement for Broadwell.
The biggest plus for Falkor at the moment is the low level of energy consumption. Although the TDP is 120W, during my tests this indicator never exceeded 89W (for go tests). For comparison, Skylake and Broadwell exceeded 160W, while their TDP is 170W.
As advertising. These are not just virtual servers! This is a VPS (KVM) with dedicated drives, which can be no worse than dedicated servers, and in most cases - better!
We made VPS (KVM) with dedicated drives in the Netherlands and the USA (configurations from VPS (KVM) - E5-2650v4 (6 Cores) / 10GB DDR4 / 240GB SSD or 4TB HDD / 1Gbps 10TB available at a uniquely low price - from $ 29 / month , options are available with RAID1 and RAID10) , do not miss the chance to place an order for a new type of virtual server, where all resources belong to you, as on a dedicated one, and the price is much lower, with a much more productive hardware!
How to build the infrastructure of the building. class c using servers Dell R730xd E5-2650 v4 worth 9000 euros for a penny? Dell R730xd 2 times cheaper? Only we have
2 x Intel Dodeca-Core Xeon E5-2650v4 128GB DDR4 6x480GB SSD 1Gbps 100 TV from $ 249 in the Netherlands and the USA!