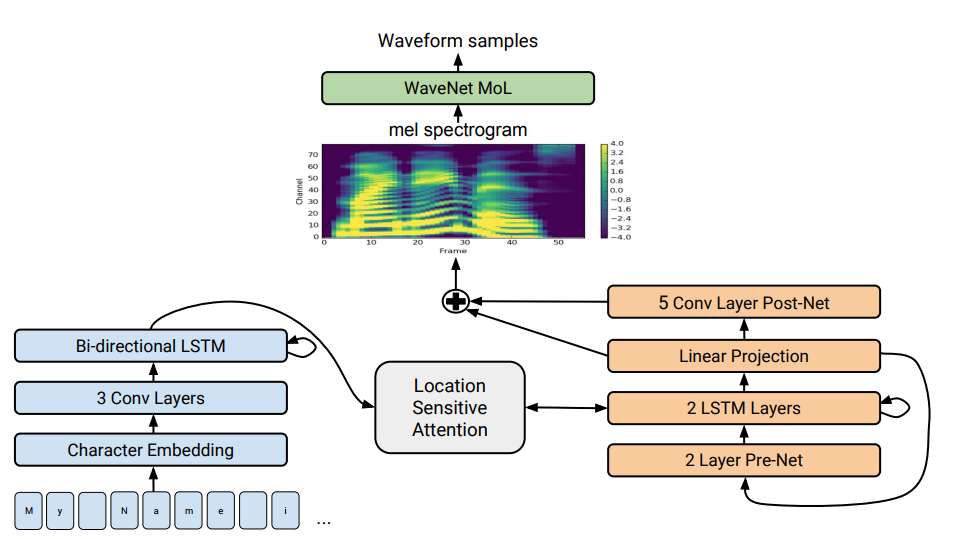
 The Tacotron 2 architecture. The bottom of the illustration shows sentence-to-sentence models that translate a sequence of letters into a sequence of attributes in an 80-dimensional space. Technical description, see scientific article
The Tacotron 2 architecture. The bottom of the illustration shows sentence-to-sentence models that translate a sequence of letters into a sequence of attributes in an 80-dimensional space. Technical description, see scientific articleSpeech synthesis - the artificial reproduction of human speech from text - is traditionally considered to be one of the constituent parts of artificial intelligence. Previously, such systems could only be seen in science fiction films, but now they work literally in every smartphone: these are Siri, Alice and the like. But they do not pronounce very realistic phrases: the voice is still, words are separated from each other.
Google has
developed a new generation of advanced speech synthesizer. It is called Tacotron 2 and is based on a neural network. To demonstrate its capabilities, the company has laid out
examples of synthesis . At the bottom of the page with examples, you can take a test and try to determine where the text speaks the speech synthesizer, and where the person. To determine the difference is almost impossible.
Despite decades of research, speech synthesis is still an urgent task for the scientific community. Over the past years, various techniques have prevailed in this area: concatenative synthesis with the choice of fragments has recently been considered the most advanced - the process of combining together small pre-recorded sound fragments, as well as statistical parametric speech synthesis, in which smooth vocabulary synthesized vocoder. The second method solved many problems of concatenative synthesis with artifacts at the boundaries between fragments. However, in both cases, the synthesized sound sounded unintelligible and unnatural compared to human speech.
Then came the WaveNet sound engine (a generative model of waveforms in the time domain), which for the first time was able to show sound quality comparable to a human one. It is currently used in the
Deep Voice 3 speech synthesis system.
Earlier in 2017, Google introduced the
Tacotron offer-to-offer architecture. It generates spectrogram amplitudes from a sequence of characters. Tacotron simplifies the traditional pipeline of the sound engine. Here the linguistic and acoustic features are generated by a single neural network trained only on data. The phrase "sentence-to-sentence" means that the neural network establishes a correspondence between a sequence of letters and a sequence of attributes for encoding sound. Signs are generated in an 80-dimensional audio pattern with frames of 12.5 milliseconds.
The neural network is trained not only in the pronunciation of words, but also in specific voice characteristics, such as loudness, speed and intonation.
Then directly sound waves are generated using the Griffin-Lima algorithm (for phase estimation) and the inverse short-term Fourier transform. As the authors noted, this was a temporary solution to demonstrate the capabilities of the neural network. In fact, the WaveNet engine and the like create a better sound quality than the Griffin-Lima algorithm, and without artifacts.
In the modified Tacotron 2 system, experts from Google still connected the WaveNet vocoder to the neural network. Thus, the neural network creates spectrograms, and then a modified version of WaveNet generates sound at 24 kHz.
The neural network is self-learning (end-to-end) at the sound of the human voice, which is accompanied by text. A well-trained neural network then reads texts in such a way that it is almost impossible to distinguish from the sound of human speech, as can be seen from
real examples .
The researchers note that the system Deep Voice 3 uses a similar approach, but the quality of its synthesis still can not be compared with human speech. But Tacotron 2 can, see the results of the tests Mean Opinion Score (MOS) in the table.
There is another speech synthesizer that also works on a neural network - this is
Char2Wav , but it has a completely different architecture.
Scientists say that in general, the neural network works fine, but still has difficulty pronouncing some difficult words (such as
decorum or
merlot ). And sometimes it randomly gives out strange noises - the reasons for this are now being investigated. In addition, the system is not able to work in real time, and the authors are still unable to take the engine under control, that is, to ask him the desired intonation, for example, a happy or sad voice. Each of these problems is interesting in itself, they write.
The scientific article was
published on December 16, 2017 on the site of preprints arXiv.org (arXiv: 1712.05884v1).