
Our day begins with the phrase "Good morning!". During the day, we communicate with colleagues, family, friends, and even with strangers passersby who ask for directions to the nearest metro. We speak even when there is no one around us in order to better perceive our own reasoning. All this is our speech - a gift that is truly incomparable with many other possibilities of the human body. Speech allows us to establish social connections, express thoughts and emotions, express ourselves, for example, in songs.
And in the lives of people appeared smart machines. A person, whether from curiosity, or from a thirst for new accomplishments, is trying to teach the machine to speak. But in order to speak, you need to hear and listen. Nowadays, it is difficult to surprise with a program (for example, Siri), which is able to recognize a speech, to find a restaurant on the map, to call your mother, even to tell a joke. She understands a lot, not everything, of course, but a lot. But it was not always, naturally. Decades ago, it was for happiness, when a car could understand at least a dozen words.
Today, we will plunge into the history of how humanity was able to speak with the machine, which breakthroughs over the centuries in this area have served as the impetus for the development of speech recognition technology. Also consider how modern devices perceive and process our voices. Go.
The origins of speech recognition
What is speech? Roughly speaking, it is a sound. So in order to recognize speech, you need to first recognize the sound and record it.
Now we have iPods, MP3 players, we used to have tape recorders, even earlier we had phonographs and gramophones. These are all devices for playing sounds. But who was the progenitor of them all?
 Thomas Edison with his invention. 1878
Thomas Edison with his invention. 1878It was a phonograph. On November 29, 1877, the great inventor Thomas Edison demonstrated his new creation, capable of recording and reproducing sounds. It was a breakthrough that caused the keen interest of society.
The principle of the phonograph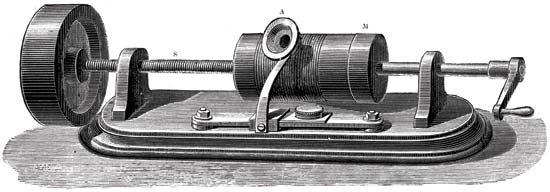
The main parts of the mechanism for recording sound were a cylinder with a coating of foil and a needle-cutter. The needle moved through the cylinder, which rotated. And mechanical vibrations were captured using a membrane microphone. As a result, the needle left marks on the foil. As a result, we received a cylinder with a record. For its reproduction, the same cylinder was originally used as in the recording. But the foil was too fragile and quickly wore out, because the records were short-lived. Then they began to apply wax, which covered the cylinder. In order to prolong the existence of records, they began to copy them using electroforming. Due to the use of harder materials, the copies served much longer.
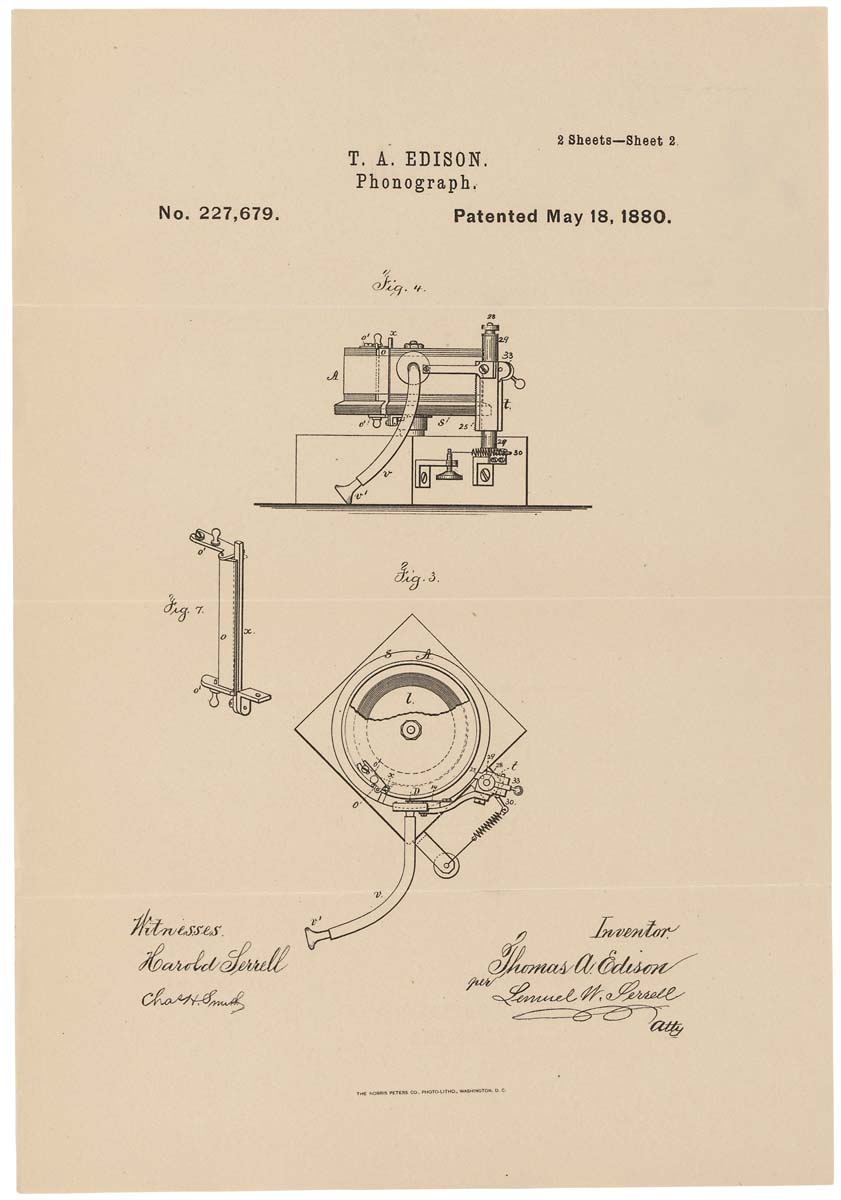 Schematic representation of the phonograph on the patent. 1880, May 18
Schematic representation of the phonograph on the patent. 1880, May 18Given the above disadvantages, the phonograph, although it was an interesting machine, was not swept away from the shelves. Only with the appearance of a disk phonograph - better known as a gramophone - did public recognition come. The novelty allowed for longer recordings (the first phonograph could record just a couple of minutes), which served for a long time. And the gramophone itself was equipped with a speaker, which increased the playback volume.
Thomas Edison initially conceived the phonograph as a device for recording telephone conversations, such as modern dictaphones. However, his work has become very popular in the reproduction of musical works. After serving as the beginning for the development of the recording industry.
Speech "organ"
Bell Labs is famous for its telecommunications inventions. One of these inventions was Voder.
Back in 1928, Homer Dudley began work on a vocoder, a device capable of synthesizing speech. We will talk about him later. Now we will consider its part - the driver.
 Schematic representation of the driver
Schematic representation of the driverThe basic principle of the driver was the breakdown of human speech into acoustic components. The car was extremely difficult, and only a trained operator could operate it.
Voder imitated the effects of the human vocal tract. There were 2 basic sounds that the operator could choose with his wrist. Foot pedals were used to control the generator of discontinuous oscillations (humming sound) that created voiced vowels and nasal sounds. The gas discharge tube (hissing) created sibilants (fricative consonants). All these sounds passed through one of the 10 filters, which was chosen by the keys. There were also special keys for sounds like “p” or “d”, and for affricates “j” in the word “jaw” and “ch” in the word “cheese”.
This small excerpt from the presenter presentation clearly demonstrates the principle of its work and the actions of the operator.The operator could produce permissible recognizable speech only after several months of diligent practice and training.
For the first time the driver was shown at an exhibition in New York in 1939.
Saving through speech synthesis
Now consider the vocoder, of which the aforementioned driver was a part.
 One of the vocoder models: HY-2 (1961)
One of the vocoder models: HY-2 (1961)Vocoder was originally intended to save radio frequency frequencies when transmitting voice messages. Instead of the voice itself, the values of certain parameters were transmitted, which were processed by the speech synthesizer at the output.
Vocoder basis had three main properties:
- noise generator (consonant sounds);
- tone generator (vowel sounds);
- formal filters (recreating the individual characteristics of the speaker).
Despite its serious purpose, the vocoder attracted the attention of electronic musicians. The transformation of the source signal and its reproduction on another device made it possible to achieve various effects, such as the effect of a musical instrument singing in a “human voice”.
Counting for car
Back in 1952, technology was not as developed as it is now. But this did not prevent the enthusiastic scientists from setting themselves impracticable, in the opinion of many, tasks. Similarly, gentlemen Stephen Balashek (S. Balashek), Ralon Biddulf (R. Biddulph) and K.H. Davis (KH Davis) decided to teach the car to understand their speech. Audrey (Audrey) car appeared after the idea. Her possibilities were very limited - she could recognize only numbers from 0 to 9. But even that was enough to boldly declare a breakthrough in computer technology.
 Audrey with one of his creators (if you believe the Internet, correct me if it is not)
Audrey with one of his creators (if you believe the Internet, correct me if it is not)Despite her small abilities, Audrey could not boast the same dimensions. She was a rather large "girl" - the relay cabinet was almost 2 meters tall, and all the elements occupied a small room. What is not surprising for a computer of the time.
The operator interaction procedure and Audrey also had some conditions. The operator uttered the words (numbers, in this case) into the phone of a regular phone, necessarily keeping a pause of 350 milliseconds between each word. Audrey received information, translated it into electronic format and included a certain light bulb corresponding to one or another number. Not to mention that not every operator could get an exact answer. To achieve 97% accuracy, the operator had to be a person who had been practicing “chatter” with Audrey for a long time. In other words, Audrey understood only her creators.
Even taking into account all the flaws of Audrey, which are not connected with design errors, but with the limitations of the technology of those times, she became the first star in the sky of cars that understand the human voice.
Future in shoe box
In 1961, a new wonder device, the Shoebox, was developed at the IBM Advanced Development System Lab. It was capable of recognizing 16 words (in English exclusively) and numbers from 0 to 9. William C. Dersch was the author of this computer.
 IBM's shoebox
IBM's shoeboxThe unusual name corresponded to the appearance of the car, it was the size and shape of a shoe box. The only thing that caught the eye was the microphone, which joined the three audio filters needed to recognize high, medium and low sounds. The filters were connected to a logic decoder (diode transistor logic circuit) and a light-on mechanism.
The operator brought the microphone to his mouth and uttered a word (for example, the number 7). The machine converted acoustic data into electronic signals. The result of understanding was the inclusion of a light bulb with the signature "7". In addition to understanding individual words, Shoebox could understand simple arithmetic puzzles (like 5 + 6 or 7-3) and give the right answer.
Shoebox was introduced by its own creator in 1962 at the Seattle World Expo.
Telephone conversation with the machine
In 1971, IBM, known for its love of innovative inventions and technologies, decided to use speech recognition in practice. The Automatic Call Identification system allowed an engineer, located anywhere in the United States, to call a computer in Raleigh, North Carolina. The caller could ask a question and get a voice response to it. The uniqueness of this system was in the understanding of the plurality of voices, given their tonality, accent, loudness of speech, etc.
High flying harpy
The US Department of Defense's promising research projects (abbreviated DARPA) in 1971 announced the launch of a program for the development and research in the field of speech recognition, the purpose of which is to create a machine capable of recognizing 1000 words. A bold project, given the success of its predecessor, measured in dozens of words. But there is no limit to human resourcefulness. And in 1976, Carnegie Mellon University demonstrates Harpy, which can recognize 1011 words.
Video demonstration of how Harpy worksThe university has already developed speech recognition systems - Hearsay-1 and Dragon. They were used as the basis for the implementation of Harpy.
In Hearsay-1, knowledge (i.e., a dictionary of a machine) is presented in the form of procedures, and in Dragon - in the form of a Markov network with an a priori probability transition. In Harpy, it was decided to use the subsequent model, but without this transition.
In this video, the principle of operation is described in more detail.
Simply put, you can draw a network - a sequence of words and their combinations, as well as sounds with a single word, for the machine to understand the different pronunciation of the same word.
Harpy understood 5 operators, three of whom were men and two women. That said about the greater computational capabilities of this machine. Speech recognition accuracy was approximately 95%.
Tangora from IBM
In the early 1980s, IBM decided to develop a system by the middle of the decade that could recognize more than 20,000 words. This is how Tangora was born, in which hidden Markov models were used. Despite the rather impressive vocabulary, the system required no more than 20 minutes of working with a new operator (speaking person) to learn how to recognize his speech.
Revived doll
In 1987, toy company Worlds of Wonder released a revolutionary new product - a talking doll named Julie. The most impressive feature of the Danish toy was the ability to train it to recognize the owner's speech. Julie could quite tolerably communicate. In addition, the doll was equipped with a variety of sensors, thanks to which it reacted when it was lifted, tickled or transferred from a dark to a bright room.
Julie's Worlds of Wonder commercial with a demonstration of its capabilities.Her eyes and lips were mobile, which created an even more vivid image. In addition to the doll itself, it was possible to purchase a book in which pictures and words were made in the form of special stickers. If you hold the fingers of the doll on them, then it will sound what it "feels" to the touch. Julie doll was the first device with a speech recognition function that was available to anyone.
The first software for dictation

In 1990, Dragon Systems released the first personal computer software, which was based on speech recognition, DragonDictate. The program worked exclusively on Windows. The user had to make small pauses between each word so that the program could disassemble them. Later, a more advanced version appeared that allows you to talk continuously - Dragon NaturallySpeaking (it is exactly this one that is available now, while the original DragonDictate has stopped being updated since the days of Windows 98). Despite its “sluggishness”, the DragonDictate program has gained great popularity among PC users, especially among people with disabilities.
Non Egyptian Sphinx
Carnegie Mellon University, which has already been "lit up" earlier, became the birthplace of another historically important speech recognition system - Sphinx 2.
 The creator of Sphinx Xaedong Hang (Xuedong Huang)
The creator of Sphinx Xaedong Hang (Xuedong Huang)The direct author of the system was Xaedong Hang (Xuedong Huang). From its predecessor Sphinx 2 distinguished its speed. The system was focused on real-time speech recognition for programs that use spoken (everyday) language. Among the features of Sphinx 2 were: hypothesis formation, dynamic switching between language models, detection of equivalents, etc.
The Sphinx 2 code has been used in a variety of commercial products. And in 2000, on the SourceForge website, Kevin Lenzo posted the source code of the system for public viewing. Those who wish to explore the source code of Sphinx 2 and its other variations can follow the
link .
Medical dictation
In 1996, IBM launched MedSpeak, which became the first commercial product with speech recognition. It was supposed to use this program in the medical system for the formation of medical records. For example, a radiologist, looking at pictures of a patient, voiced her comments, which the MedSpeak system translated into text.
Before turning to the most famous representatives of programs with speech recognition, let's quickly, briefly, consider a few more historical events related to this technology.
Historical blitz
- 2002 - Microsoft integrates speech recognition into all its Office series products;
- 2006 - The US National Security Agency begins using speech recognition software to identify keyword keywords in conversation recordings;
- 2007 (January 30) - Microsoft releases Windows Vista - the first OS with speech recognition;
- 2007 - Google introduces GOOG-411 - a phone call forwarding system (a person calls the number, says which organization or person they need and the system connects them). The system worked within the United States and Canada;
- 2008 (November 14) - Google launches voice search on mobile devices iPhone. This was the first use of speech recognition technology in mobile phones;
And here we come to the time period when a lot of people collided with speech recognition technology.
Ladies, do not quarrel
On October 4, 2011, Apple announced Siri, the deciphering of the name speaks for itself - Speech Interpretation and Recognition Interface (i.e., Speech Interpretation and Recognition Interface).

The history of the development of Siri is very long (in fact it has 40 years of work) and interesting. The very fact of its existence and extensive functionality is the joint work of many companies and universities. However, we will not focus on this product, because the article is not about Siri, but about speech recognition in general.
Microsoft did not want to graze the rear, because already in 2014 (April 2) they announced their virtual digital assistant Cortana.

The functionality of Cortana is similar to its rival Siri, with the exception of a more flexible system of access to information.
Debate on “Cortana or Siri. Who is better? ”Conducted since their appearance on the market. As a whole, the struggle between users of iOS and Android. But it's good. Competing products, in an attempt to appear better than an opponent, will provide more and more new opportunities, develop and use more advanced technologies and techniques in the same area of speech recognition. Having only one representative in any field of consumer technologies, one cannot speak of the rapid development of this technology.
A small funny video conversation Siri and Cortana (obviously built, but from no less funny). Warning !: in this video there is profanity.
Talking with cars. How do they understand us?
As I mentioned earlier, roughly speaking, speech is sound. And what is the sound for the car? These are changes (fluctuations) in air pressure, i.e. sound waves. In order for the machine (computer or phone) to recognize speech, you must first read these vibrations. The measurement frequency should be at least 8000 times per second (even better - 44,100 times per second). If the measurements are carried out with large interruptions, we will get an inaccurate sound, which means illegible speech. The above process is referred to as 8kHz or 44.1kHz digitization.
When data on the vibrations of sound waves are collected, they need to be sorted. As in the general heap we have both speech and side sounds (noise of cars, rustling of paper, sound of a working computer, etc.). Carrying out mathematical operations allows to weed out exactly our speech, which needs recognition.
Next comes the analysis of the selected sound wave - speech. Since it consists of many individual components that form certain sounds (for example, "ah" or "ee"). Selecting these features and converting them into numerical equivalents allows you to define specific words.
English, for example, consists of more than 40 phonemes (44, to be exact, and according to some theories there are more than 100), i.e. speech sounds. The machine determines them all, because during its development, training tests were conducted, during which different people uttered the same words and phrases. So the machine could identify similarities and differences and form an algorithm for determining sounds. It is necessary to take into account the fact that not only a person (or rather, his pronunciation, accent, voice timbre, etc.) affects the way the sound “looks”, but also a combination of different phonemes in one word. For example, “t” in “sTar” and “t” in “ciTy” for a car look completely different.
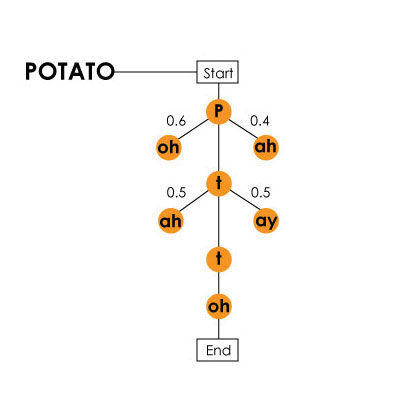 Markov's model on the example of the word "potato" (cartle) / is present in the video about the Harpy system
Markov's model on the example of the word "potato" (cartle) / is present in the video about the Harpy systemNext, the computer needs, following the patterns of formation of word sequences, to determine exactly where it is necessary to separate words. For example, there is the phrase “hang ten”, which the computer will not be able to share like this - “hey, ngten”, because it will not find in its database matches with “ngten”.
In order for the computer not to give out gibberish instead of the above phrase, it needs to understand which words follow which words. For this purpose, not only the knowledge base is used, which allows determining the constituent phrases (words), but also a partial hypothesis algorithm, with the help of which the machine determines whether the word # 2 is appropriate in conjunction with the word # 1. The phrase “What do you like for breakfast?” Can be heard as “water gaslight four brick vast?”. Brad, isn't it. It is to prevent such errors that the above described algorithm is needed. It can also take into account the possibility of combining words that, according to the logic of the machine, should not be combined. But this improvement in the hypothesis algorithm model requires much more power.
After the completion of all these complex mathematical, statistical and measurement procedures, the computer produces a result for the user. All the beauty of this technology, or rather, this technology at this stage of its development, lies in the incredible speed of the system.
Epilogue
As we can see, such a modern and amazing technology began its journey quite a long time ago. Even in the nineteenth century. If at that time someone would say that in the future it would be possible to talk with the phone (not to mention the fact that it is wireless), no one would have believed it. And the author of such statements might be forcibly treated in the appropriate hospital. But now this technology has become as commonplace as smartphones, laptops, the Internet and much more. Future generations in general may not remember that once, long ago, machines could not speak to humans.
As advertising. Hurry to take advantage of the interesting offer in the new year and get a 25% discount on the first payment when ordering for 3 or 6 months!
These are not just virtual servers! This is a VPS (KVM) with dedicated drives, which can be no worse than dedicated servers, and in most cases - better!
We made VPS (KVM) with dedicated drives in the Netherlands and the USA (configurations from VPS (KVM) - E5-2650v4 (6 Cores) / 10GB DDR4 / 240GB SSD or 4TB HDD / 1Gbps 10TB available at a uniquely low price - from $ 29 / month , options are available with RAID1 and RAID10) , do not miss the chance to place an order for a new type of virtual server, where all resources belong to you, as on a dedicated one, and the price is much lower, with a much more productive hardware!
How to build the infrastructure of the building. class c using servers Dell R730xd E5-2650 v4 worth 9000 euros for a penny? Dell R730xd 2 times cheaper? Only we have
2 x Intel Dodeca-Core Xeon E5-2650v4 128GB DDR4 6x480GB SSD 1Gbps 100 TV from $ 249 in the Netherlands and the USA!