
The faster the development process, the faster the technology company is developing.
Unfortunately, modern applications work against us - our systems must be updated in real time and at the same time not to interfere with anyone and not lead to downtime and interruptions. Deployment in such systems becomes a difficult task and requires complex continuous delivery pipelines even in small teams.
These pipelines usually have a narrow application, work slowly and are not reliable. Developers must first create them manually, and then manage them, and companies often hire entire DevOps teams for this.
The speed of development depends on the speed of these pipelines. For the best teams, deployment takes 5-10 minutes, but usually it takes much longer, and for one deployment it takes several hours.
In Dark, it takes 50 ms. Fifty. Milliseconds Dark is a complete solution with a programming language, editor and infrastructure designed specifically for continuous delivery, and all aspects of Dark, including the language itself, are built with a view of secure instant deployment.
Why are continuous delivery conveyors so slow?
Let's say we have a Python web application and we have already created a wonderful and modern continuous delivery pipeline. For a developer who is busy with this project every day, deploying one minor change will look something like this:
Alteration
- Creating a new branch in git
- Making Changes Behind Function Switch
- Unit testing to verify changes with and without function switch
Pool request
- Commit commit
- Posting changes to a remote repository on github
- Pool request
- CI builds automatically in the background
- Code review
- A few more reviews, if necessary
- Merge changes with git wizard.
CI runs on the wizard
- Setting frontend dependencies via npm
- Building and optimizing HTML + CSS + JS resources
- Run in the front end of unit and function tests
- Install Python dependencies from PyPI
- Run in the backend of unit and functional tests
- Integration testing at both ends
- Send frontend resources to CDN
- Building a container for a Python program
- Sending a container to the registry
- Kubernetes manifest update
Replacing old code with new
- Kubernetes launches multiple instances of a new container
- Kubernetes is waiting for instances to become operational
- Kubernetes adds instances to HTTP load balancer
- Kubernetes waits for old instances to cease to be used
- Kubernetes stops old instances
- Kubernetes repeats these operations until new instances replace all old ones
Turn on the new function switch
- The new code is included only for myself, to make sure that everything is fine
- New code is included for 10% of users, operational and business metrics are tracked
- New code is included for 50% of users; operational and business metrics are tracked
- The new code is included for 100% of users, operational and business metrics are tracked
- Finally, you repeat the whole procedure to remove the old code and switch
The process depends on the tools, language, and use of service-oriented architectures, but in general terms, it looks like this. I did not mention database migration deployments because it requires careful planning, but below I will describe how Dark deals with this.
There are many components here, and many of them can easily slow down, crash, cause temporary competition or bring down the working system.
And since these pipelines are almost always created for a special occasion, it is difficult to rely on them. Many people have days when the code cannot be deployed, because there are problems in the Dockerfile, one of the dozens of services crashed or the right specialist on vacation.
Even worse, many of these steps do nothing at all. We needed them before when we deployed the code right away for users, but now we have switches for the new code, and these processes are divided. As a result, the step at which the code is deployed (the old one is replaced by the new one) has now become just an extra risk.
Of course, this is a very thoughtful pipeline. The team that created it took the time and money to quickly deploy. Usually deployment pipelines are much slower and more unreliable.
Implementing Continuous Delivery in Dark
Continuous delivery is so important to Dark that we set our sights on time in less than a second. We went through all the steps of the pipeline to remove everything unnecessary, and brought the rest to mind. This is how we removed the steps.
Jessie Frazelle coined the new word deployless at the Future of Software Development conference in Reykjavik
We immediately decided that Dark would be based on the concept of “deployless” (thanks to Jesse Frazel for neologism). Deployless means that any code is instantly deployed and ready for use in production. Of course, we will not miss a faulty or incomplete code (I will describe safety principles below).
At the Dark demo, we were often asked how we managed to speed up the deployment. Weird question. People probably think that we have come up with some kind of supertechnology that compares the code, compiles it, packs it into a container, launches a virtual machine, launches a container on a cold one and stuff like that - and all this in 50 ms. It is hardly possible. But we have created a special deployment engine that does not need all this.
Dark launches interpreters in the cloud. Suppose you are writing code in a function or handler for HTTP or events. We send diff to the abstract syntax tree (the implementation of the code internally used by our editor and servers) to our servers, and then run this code when requests are received. So the deployment looks just like a modest record in the database - instant and elementary. Deployment is so fast because it includes the bare minimum.
In the future, we plan to make the infrastructure compiler out of Dark, which will create and run the ideal infrastructure for high performance and reliability of applications. Instant deployment, of course, is not going anywhere.
Secure deployment
Structured Editor
The code in Dark is written in the Dark editor. The structured editor does not make syntax errors. In fact, Dark doesn't even have an analyzer. As you type, we work directly with the Abstract Syntax Tree (AST) like Paredit , Sketch-n-Sketch , Tofu , Prune, and MPS .
Any incomplete code in Dark has valid execution semantics, much like typed holes in Hazel . For example, if you change a function call, we keep the old function until the new one becomes usable.
Each program in Dark has its own meaning, so incomplete code does not interfere with the finished work.
Editing modes
You write code in Dark in two cases. First: you write new code and are the only user. For example, it is in the REPL, and other users will never get access to it, or it is a new HTTP route that you do not refer anywhere. You can work here without any precautions, and now you are approximately working in the development environment.
Second situation: the code is already in use. If traffic passes through the code (functions, event handlers, databases, type), care must be taken. To do this, we block all used code and require the use of more structured tools for editing it. I’ll talk about structural tools below: function switches for HTTP and event handlers, a powerful migration platform for databases, and a new version control method for functions and types.
Function switches
One way to remove the extra complexity in Dark is to fix several problems with one solution. Function switches perform many different tasks: replacing the local development environment, git branches, deploying code, and, of course, the traditional slow and controlled release of new code.
Creation and deployment of a function switch is performed in our editor in one operation. It creates an empty space for the new code and provides access controls for the old and new code, as well as buttons and commands for the gradual transition to the new code or its exclusion.
Function switches are built into the Dark language, and even incomplete switches perform their task - if the condition in the switch is not met, the old blocked code will be executed.
Development environment
Function switches replace the local development environment. Today, it’s difficult for teams to ensure that everyone uses the same versions of tools and libraries (code formatters, linters, package managers, compilers, preprocessors, testing tools, etc.) With Dark, you don’t need to install dependencies locally, control the local installation of Docker or take other measures to ensure at least a semblance of equality between the development environment and production. Given that such equality is still impossible , we won’t even pretend that we are striving for it.
Instead of creating a cloned local environment, the switches in Dark create a new sandbox in production that replaces the development environment. In the future, we also plan to create a sandbox for other parts of the application (for example, instant database clones), although for now this does not seem so important.
Branches and Deployments
Now there are several ways to enter new code into systems: git branches, the deployment phase, and function switches. They solve one problem in different parts of the workflow: git - at the stages before deployment, deployment - at the time of transition from the old code to the new one, and function switches - for the controlled release of new code.
The most effective way is function switches (at the same time the easiest to understand and use). With them, you can completely abandon the other two methods. It is especially useful to remove the deployment - if we use function switches to include the code anyway, the step of transferring the servers to the new code only creates unnecessary risks.
Git is difficult to use, especially for beginners, and it really limits it, but it has convenient branches. We smoothed out many of the git flaws Dark is edited in real time and provides the ability to work together in the style of Google Docs, so that you do not have to send the code and you can less often perform relocation and merging.
Feature switches underpin secure deployment. Together with instant deployments, they allow you to quickly test concepts in small fragments with low risk, instead of applying one major change that can bring down the system.
Versioning
To change functions and types we use versioning. If you want to change a function, Dark creates a new version of this function. Then you can invoke this version using the switch in the HTTP or event handler. (If this function is deep in the call graph, a new version of each function is created in the process. It may seem like it is too much, but the functions do not interfere if you do not use them, so you won’t even notice it.)
For the same reasons, we are versioning types. We talked in detail about our type system in a previous post .
By versioning functions and types, you can make changes to the application gradually. You can verify that each individual handler works with the new version, you do not need to immediately make all changes to the applications (but we have tools to quickly do this if you want).
This is much safer than fully deploying everything at once, as it is now.
New package versions and standard library
When you update a package in Dark, we do not immediately replace the use of each function or type in the entire code base. It's not safe. The code continues to use the same version that it used, and you update the use of functions and types to a new version for each individual case using the switches.

A screenshot of part of an automatic process in Dark showing two versions of the Dict :: get function. Dict :: get_v0 returned type Any (which we refuse), and Dict :: get_v1 returned type Option.
We often provide a new feature in the standard library and exclude older versions. Users with old versions in the code will retain access to them, but new users will not be able to get them. We are going to provide tools to transfer users from old versions to new ones in 1 step, and again using function switches.
Dark also provides a unique opportunity: once we execute your working code, we can test new versions ourselves, comparing the output for new and old requests to inform you about the changes. As a result, package updates, which are often performed blindly (or require rigorous security testing), pose far fewer risks and can happen automatically.
New versions of Dark
The transition from Python 2 to Python 3 has stretched over a decade and still remains a problem. Once we create Dark for continuous delivery, these language changes need to be considered.
When we make small changes to the language, we create a new version of Dark. The old code remains in the old version of Dark, and the new code is used in the new version. To switch to the new version of Dark, you can use the switches or versions of functions.
This is especially useful considering that Dark has appeared recently. Many changes to the language or library may fail. The gradual versioning of the language allows us to make minor updates, that is, we can not rush and put off many decisions about the language until we have more users, and therefore more information.
Database migrations
There is a standard formula for safe database migration:
- Rewrite code to support new and old formats
- Convert all data to a new format
- Delete old data access
As a result, database migration is delayed and requires a lot of resources. And we are accumulating outdated schemes, because even simple tasks, such as correcting the name of a table or column, are not worth the effort.
Dark has an effective database migration platform that (we hope) will simplify the process so much that you will stop being afraid of it. All data stores in Dark (key-value pairs or persistent hash tables) are of type. To migrate a data warehouse, you simply assign it a new type and a rollback and rollback function to convert values between the two types.
Access to data warehouses in Dark is through versioned variable names. For example, the Users data store would initially be called Users-v0. When a new version with a different type is created, the name changes to Users-v1. If the data is saved through Users-v0, and you access it through Users-v1, the roll-over function is applied. If the data is saved through Users-v1, and you access it through Users-v0, the rollback function is used.
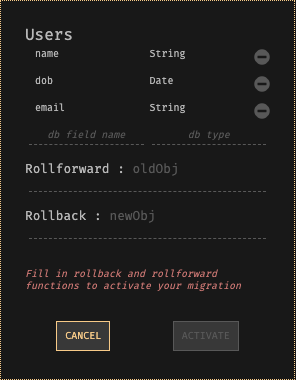
Database migration screen with field names for the old database, rollback and rollback expressions, and instructions for enabling migration.
Use the function switches to route calls to Users-v0 to Users-v1. This can be done one HTTP handler at a time to reduce risks, and the switches also work for individual users so that you can verify that everything is working as expected. When Users-v0 is not left, Dark converts all remaining data in the background from the old format to the new one. You won’t even notice it.
Testing
Dark is a functional programming language with static typing and immutable values; therefore, its testing surface is significantly smaller compared to object-oriented languages with dynamic typing. But you still need to test.
In Dark, the editor automatically runs unit tests in the background for editable code, and by default runs these tests for all function switches. In the future, we want to use the static types to automatically fuzz the code to find bugs.
In addition, Dark runs your infrastructure in production, and this opens up new possibilities. We automatically save HTTP requests in the Dark infrastructure (for now we save all requests, but then we want to switch to fetching). We test new code on them and conduct unit tests, and if you wish, you can easily convert interesting queries into unit tests.
What we got rid of
Since we do not have a deployment, but there are function switches, about 60% of the deployment pipeline remains overboard. We do not need git branches or pool requests, building backend resources and containers, sending resources and containers to registries or deployment steps in Kubernetes.
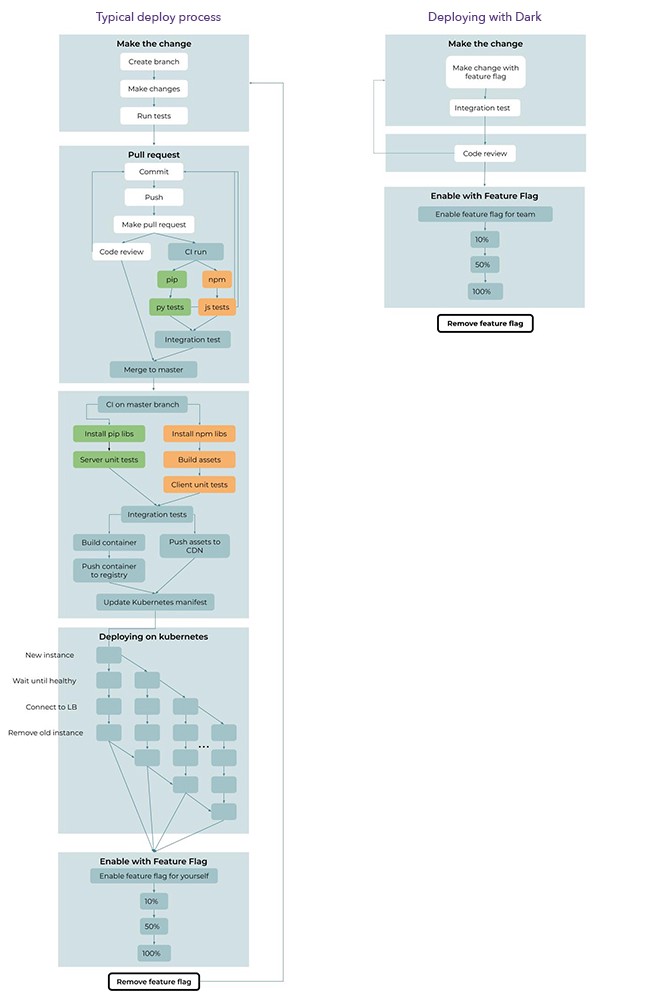
Comparison of the standard continuous delivery pipeline (left) and the continuous supply of Dark (right). In Dark, the delivery consists of 6 steps and one cycle, while the traditional version includes 35 steps and 3 cycles.
In Dark, there are only 6 steps and 1 cycle in the deployment (steps that are repeated several times), while the modern continuous supply pipeline consists of 35 steps and 3 cycles. In Dark, tests run automatically, and you don’t even see it; dependencies are installed automatically; anything related to git or github is no longer needed; It is not necessary to collect, test and send Docker containers; Kubernetes deployment is no longer needed.
Even the remaining steps in Dark have become easier. Since function switches can be controlled in one action, you do not have to go through the entire deployment pipeline a second time to remove the old code.
We simplified code delivery as much as possible, reducing the time and risks of continuous delivery. We also greatly simplified package updates, database migrations, testing, version control, dependency installation, equality between the development environment and production, and fast and safe language version upgrades.
I answer questions about this on HackerNews .
To learn more about the Dark device, read the Dark article , follow us on Twitter (or me ), or sign up for a beta version and receive notifications of the following posts . If you are coming to StrangeLoop in September, come to our launch site.