Limit
There is such a restriction on LinkedIn - the
Commercial Use Limit . It is very likely that you, like me, until recently, have never encountered or heard of him.
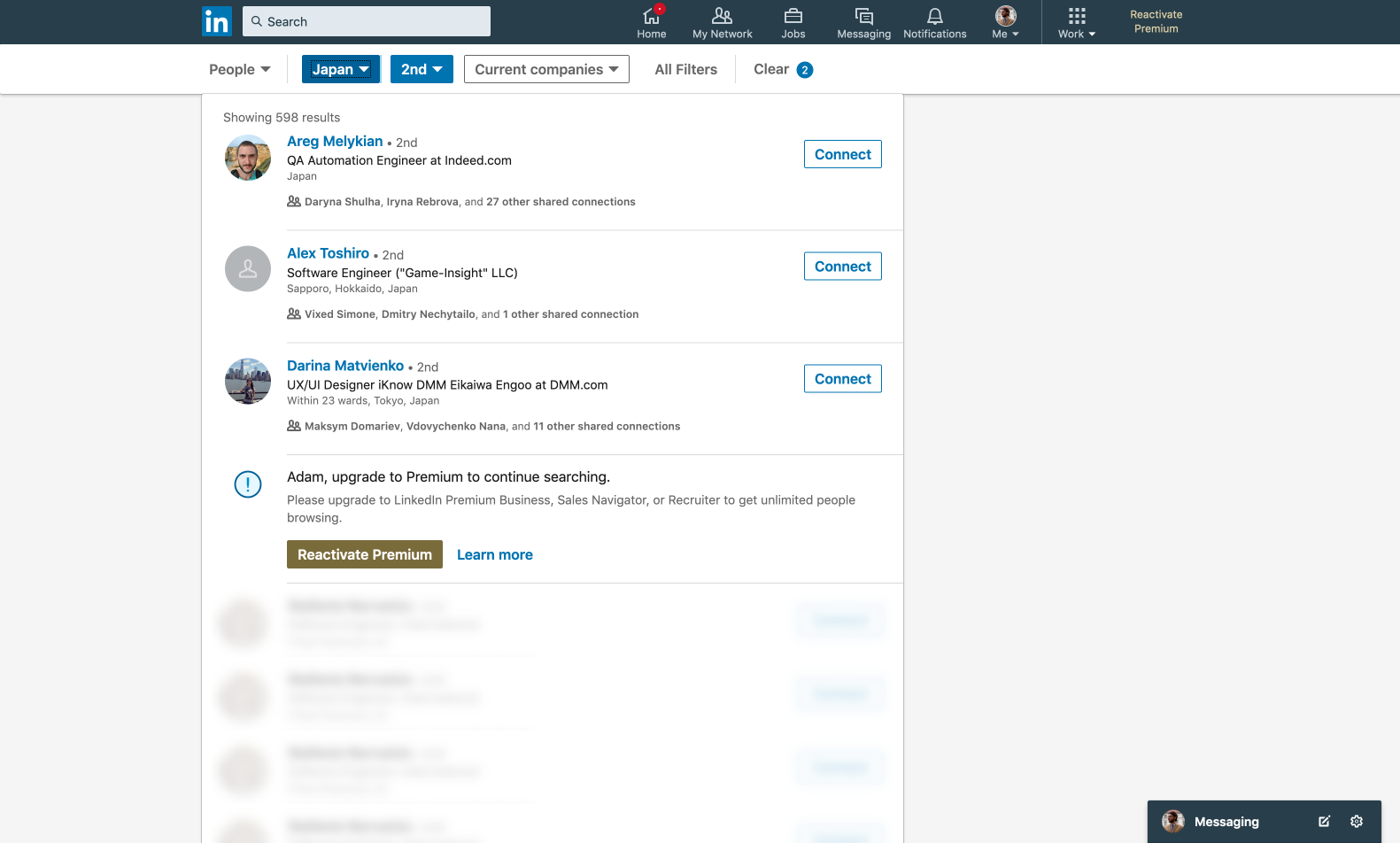
The essence of the limit is that if you use people search outside your contacts too often (there are no exact metrics, the algorithm solves it, based on your actions - how often you searched and added people), then the search result will be limited to three profiles, instead of 1000 ( default 100 pages, 10 profiles per page). The limit is reset at the beginning of each month. Naturally,
premium accounts do not have such a restriction .
But not so long ago, for one pet project, I began to play a lot with search on LinkedIn and suddenly got this restriction. Naturally, I didn’t really like this, because I did not use it for any commercial purposes, so the first thought was to study the restriction and try to get around it.
[
Important clarification - the materials in the article are presented for informational and educational purposes only. The author does not encourage their use for commercial purposes. ]
We study the problem
We have: instead of ten profiles with pagination, the search returns only three, after which a block with the “recommendation” of a premium account is inserted and below are blurry and non-clickable profiles.
Immediately, a hand reaches into the developer's console to see these hidden profiles - perhaps we can remove some styles that put blues, or extract information from the block in the markup. But, as expected, these profiles are just
stub images and do not store any information.

Ok, now let's look at the Network tab and see if the alternative search results returned that return only three profiles actually work. We find the query of interest to us “/ api / search / blended” and look at the answer.
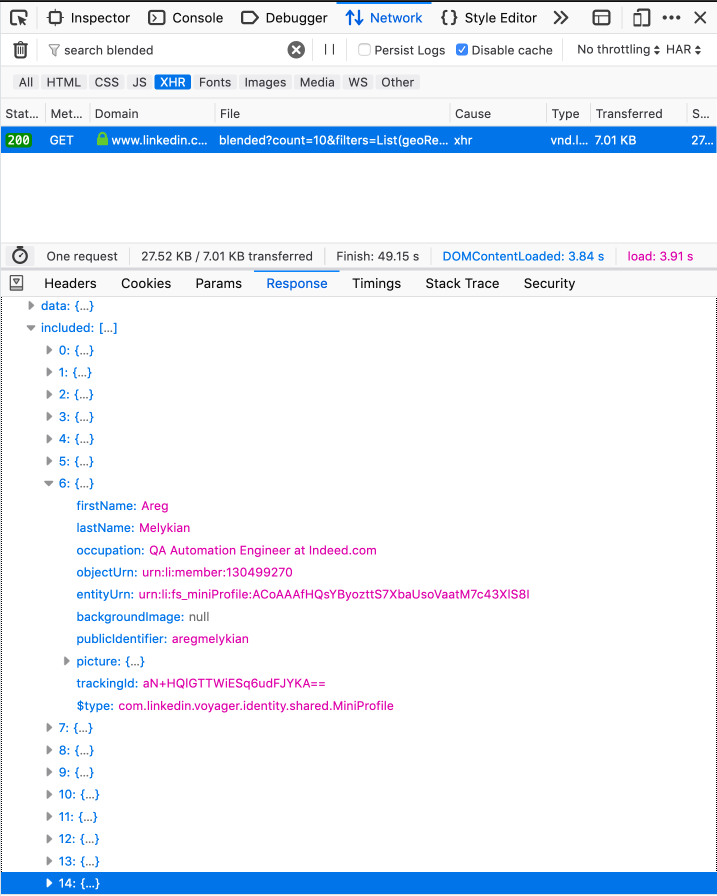
Profiles come in the `included` array, but there are already 15 entities in it. In this case, the first three of them are objects with additional information, each object contains information on a specific profile (for example, is the profile a premium).

The next 12 are real profiles - search results, of which only three will be shown to us. As you can already guess, it shows only those who receive additional information (the first three objects). For example, if you take the answer from the profile without a limit, then 28 entities will come - 10 objects with ext. information and 18 profiles.
Answer for profile without limit Why there are more than 10 profiles, although 10 are requested, and they do not participate in the display, even on the next page they will not be - I don’t know yet. If you analyze the url of the request, you can see that count = 10 (how many profiles to return in the response, a maximum of 49).

I will be glad to any comments on this subject.
Experimenting
Well, the most important thing now we know for sure - more profiles come in the answer than they show us. So we can get more data, despite the limit. Let's try to pull the api ourselves, right from the console, using fetch.

It is expected that we get an error 403. This is due to security, here we do not send a CSRF token (
CSRF on Wikipedia . In a nutshell, a unique token is added to each request, which is checked on the server for authenticity).
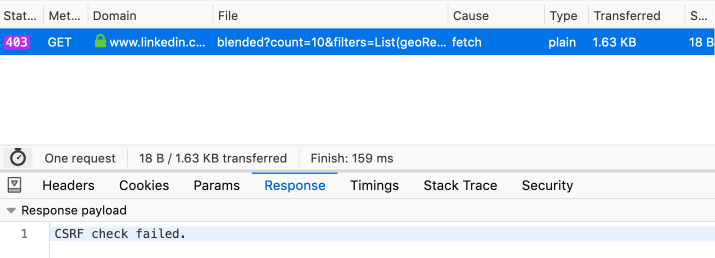
It can be copied from any other successful request or from cookies, where it is stored in the 'JSESSIONID' field.
Where to find a tokenHeader of another request:

Or from cookies, directly through the console:

We try again, this time pass the settings to fetch, in which we specify our csrf-token as a parameter in the header.

Success, we get all 10 profiles. : tada:
Due to the difference in the headers, the structure of the response is slightly different from what comes in the original request. You can get the same structure if you add 'Accept:' application / vnd.linkedin.normalized + json + 2.1 'to our object, next to the csrf token.
Sample response with added header
More about the Accept Header
What's next?
Then you can edit (with your hands or automate) the `start` parameter, indicating the index, starting from which we will be given 10 profiles (default = 0) from the entire search result. In other words, incrementing it by 10 after each request, we get the usual pagination, 10 profiles at a time.
At this stage, I had enough data and freedom to continue working on the pet project. But it was a sin not to try to display this data right on the spot, since they are on hand. In Ember, which is used at the front, we will not climb. JQuery was connected to the site, and digging out the knowledge of the basic syntax in memory, you can create the following in a couple of minutes.
JQuery code const createProfileBlock = ({ headline, publicIdentifier, subline, title }) => { $('.search-results__list').append( `<li class="search-result search-result__occluded-item ember-view"> <div class="search-entity search-result search-result--person search-result--occlusion-enabled ember-view"> <div class="search-result__wrapper"> <div class="search-result__image-wrapper"> <a class="search-result__result-link ember-view" href="/in/${publicIdentifier}/"> <figure class="search-result__image"> <div class="ivm-image-view-model ember-view"> <img class="lazy-image ivm-view-attr__img--centered EntityPhoto-circle-4 presence-entity__image EntityPhoto-circle-4 loaded" src="http://www.userlogos.org/files/logos/give/Habrahabr3.png" /> </div> </figure> </a> </div> <div class="search-result__info pt3 pb4 ph0"> <a class="search-result__result-link ember-view" href="/in/${publicIdentifier}/"> <h3 class="actor-name-with-distance search-result__title single-line-truncate ember-view"> ${title.text} </h3> </a> <p class="subline-level-1 t-14 t-black t-normal search-result__truncate">${headline.text}</p> <p class="subline-level-2 t-12 t-black--light t-normal search-result__truncate">${subline.text}</p> </div> </div> </div> <li>` ); };
If you do this directly in the console on the search page, this will add a button that loads 10 new profiles each time you click, and renders them a list. Of course, token and url before this change to the necessary. The profile block will contain a name, position, location, a link to the profile and a stub image.

Conclusion
Thus, with a minimum of effort, we were able to find a weak spot and regain our search without restrictions. It was enough to analyze the data and their path, to look into the query itself.
I can’t say that this is a serious problem for LinkedIn, because it poses no threat. The maximum is the lost profit due to such "rounds", which allows not to pay for the premium. Perhaps such a server response is necessary for the other parts of the site to work correctly, or is this simply
laziness of the developers, lack of resources that does not allow doing well. (The restriction appeared in January 2015, before this limit was not).
PS
Naturally, jQuery code is a fairly primitive example of features. At the moment, I have created an extension for the browser to fit my needs. It adds control buttons and renders full profiles with pictures, an invitation button and general connections. Plus, it dynamically collects filters of locations, companies and other things, takes a token from cookies. So you don’t need to hardcode anything. Well, it adds additional settings fields, a la "how many profiles to request at a time, up to 49."

I am still working on this add-on and I plan to put it in the public domain. Write if you are interested.