Welcome, Habr!
At one time, we were the first to
introduce the Kafka theme to the Russian market and continue to
monitor its development. In particular, the topic of interaction between Kafka and
Kubernetes seemed interesting to us. A review (and rather cautious)
article on this topic was published on the Confluent company blog last October, authored by Gwen Shapira. Today, we want to draw your attention to a more recent, April article by Johann Gyger, who, although he could not do without a question mark in the title, considers the topic in a more substantive manner, accompanying the text with interesting links. Please forgive us the free translation of “chaos monkey” if you can!
Introduction
Kubernetes is designed to handle stateless loads. As a rule, such workloads are presented in the form of microservice architecture, they are lightweight, well-suited to horizontal scaling, obey the principles of 12-factor applications, and allow working with circuit breakers and chaos monkeys.
Kafka, located on the other hand, essentially acts as a distributed database. Thus, when working, you have to deal with the condition, and it is much heavier than a microservice. Kubernetes supports stateful loads, but as Kelsey Hightower points out in two of his tweets, they should be handled with care:
To some, it seems that if you roll Kubernetes onto a stateful load, it turns into a fully managed database that can compete with RDS. This is not true. Maybe if you just work hard, screw on additional components and attract a team of SRE engineers, you can install RDS on top of Kubernetes.
I always recommend that everyone exercise extreme caution when starting up stateful loads on Kubernetes. Most of those who are interested in “can I run stateful loads on Kubernetes” do not have sufficient experience working with Kubernetes, and often with the load they are asking about.
So, should I run Kafka on Kubernetes? Counter-question: will Kafka work better without Kubernetes? That's why I want to emphasize in this article how Kafka and Kubernetes complement each other, and what pitfalls can come across when combined.
Time of completion
Let's talk about the basic thing - the runtime environment itself
ProcessKafka brokers are convenient when working with the CPU. TLS may incur some overhead. At the same time, Kafka clients can load the CPU more if they use encryption, but this does not affect brokers.
MemoryKafka brokers gobble up the memory. The JVM heap size is usually fashionable to limit 4–5 GB, but you will also need a lot of system memory, since Kafka uses the page cache very heavily. In Kubernetes, appropriately set the container limits for resources and requests.
Data storeThe data storage in the containers is ephemeral - data is lost upon restart. You can use the
emptyDir volume for Kafka data, and the effect will be similar: your broker data will be lost after completion. Your messages can still be saved on other brokers as replicas. Therefore, after a restart, a failed broker must first replicate all the data, and this process may take a lot of time.
This is why long-term data storage should be used. Let it be non-local long-term storage with the XFS file system or, more precisely, ext4. Do not use NFS. I warned. NFS versions v3 or v4 will not work. In short, the Kafka broker will end if it cannot delete the data directory due to the “stupid renaming” problem that is relevant in NFS. If I still have not convinced you,
read this article very carefully. The data warehouse must be non-local so that Kubernetes can more flexibly select a new node after a restart or relocation.
NetworkAs with most distributed systems, Kafka's performance is very much dependent on network latency being minimal and bandwidth being maximum. Do not try to place all brokers on the same node, as this will decrease availability. If the Kubernetes node fails, the entire Kafka cluster also fails. Also, do not disperse the Kafka cluster across entire data centers. The same goes for the Kubernetes cluster. A good compromise in this case is to choose different access zones.
Configuration
Common manifestosThe Kubernetes website has a
very good guide on how to configure ZooKeeper using manifests. Since ZooKeeper is part of Kafka, it is from this that it is convenient to begin to get acquainted with what Kubernetes concepts are applicable here. Once you figure this out, you can use the same concepts with the Kafka cluster.
- Sub : sub is the smallest deployable unit in Kubernetes. The pod contains your workload, and the pod itself corresponds to the process in your cluster. A hearth contains one or more containers. Each ZooKeeper server in the ensemble and each broker in the Kafka cluster will work in a separate approach.
- StatefulSet : StatefulSet is a Kubernetes object that works with multiple stateful workloads, which require coordination. StatefulSet provides guarantees regarding ordering of hearths and their uniqueness.
- Headless services : Services allow you to detach pods from clients using a logical name. Kubernetes in this case is responsible for load balancing. However, when maintaining stateful workloads, as in the case of ZooKeeper and Kafka, clients need to exchange information with a specific instance. This is where headless services come in handy: in this case, the client will still have a logical name, but you won’t have to go directly to the bottom.
- Volume for long-term storage : these volumes are needed for the configuration of the non-local block long-term storage, which was mentioned above.
Yolean provides a comprehensive set of manifests that make it easy to get started with Kafka on Kubernetes.
Helm chartsHelm is a package manager for a Kubernetes, which can be compared to package managers for OSs like yum, apt, Homebrew or Chocolatey. Using it is convenient to install predefined software packages described in Helm diagrams. A well-chosen Helm diagram facilitates the difficult task: how to properly configure all the parameters for using Kafka on Kubernetes. There are several Kafka diagrams: the official one is
in an incubator state , there is one from
Confluent , one more from
Bitnami .
OperatorsSince Helm has certain flaws, another tool is gaining considerable popularity: Kubernetes operators. The operator does not just pack the software for Kubernetes, but also allows you to deploy such software and also manage it.
The list of
awesome operators mentions two operators for Kafka. One of them is
Strimzi . With the help of Strimzi it’s not difficult to raise a Kafka cluster in a matter of minutes. Virtually no configuration is required, in addition, the operator itself provides some nice features, for example, TLS encryption of the "point-to-point" type inside the cluster. Confluent also provides
its own operator .
PerformanceIt is very important to test the performance by supplying the installed Kafka instance with control points. These tests will help you identify potential bottlenecks before problems begin. Fortunately, Kafka already provides two performance testing tools:
kafka-producer-perf-test.sh and
kafka-consumer-perf-test.sh . Use them actively. For reference, you can consult the results described in
this post by Jay Kreps, or use
this Amazon MSK
review from Stéphane Maarek as a guide.
Operations
MonitoringTransparency in the system is very important - otherwise you will not understand what is happening in it. Today there is a solid toolkit that provides monitoring based on metrics in the style of cloud native. Two popular tools for this purpose are Prometheus and Grafana. Prometheus can collect metrics from all Java processes (Kafka, Zookeeper, Kafka Connect) using the JMX exporter - in the simplest way. If you add cAdvisor metrics, you can better understand how resources are used in Kubernetes.
Strimzi has a very convenient Grafana dashboard example for Kafka. It visualizes key metrics, for example, about underreplicated sectors or those that are offline. Everything is very clear there. These metrics are supplemented by information about resource use and performance, as well as stability indicators. Thus, you get basic monitoring of the Kafka cluster for no reason!
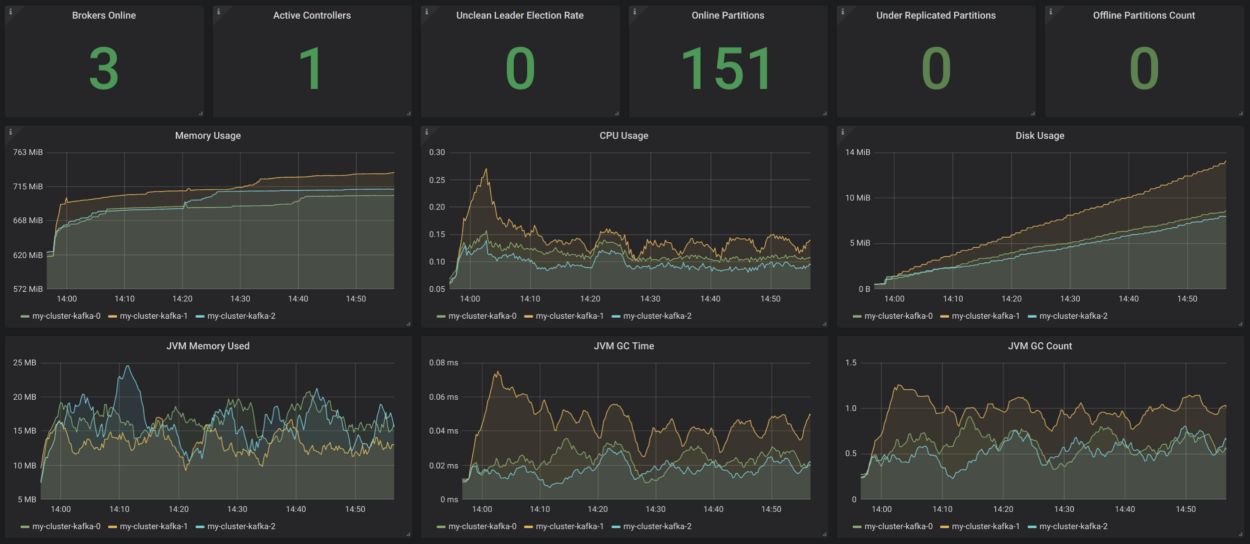
Source:
strimzi.io/docs/master/#kafka_dashboardIt would be nice to supplement all this with customer monitoring (metrics for consumers and producers), as well as lag monitoring (for this there is
Burrow ) and end-to-end monitoring - for this, use
Kafka Monitor .
LoggingLogging is another critical task. Make sure that all containers in your Kafka installation are logged in
stdout and
stderr , and make sure that your Kubernetes cluster aggregates all logs in a central
logging infrastructure, such as
Elasticsearch .
Health CheckKubernetes uses liveness and readiness probes to check if your pods are working properly. If the live test fails, Kubernetes will stop this container, and then automatically restart it if the restart policy is set accordingly. If the availability check fails, then Kubernetes isolates this under from the request service. Thus, in such cases, manual intervention is no longer required at all, and this is a big plus.
Rolling out updatesStatefulSet supports automatic updates: when choosing a RollingUpdate strategy, each under Kafka will be updated in turn. In this way, downtime can be reduced to zero.
ScalingScaling a Kafka cluster is no easy task. However, in Kubernetes it’s very easy to scale pods to a certain number of replicas, which means that you can declaratively identify as many Kafka brokers as you want. The most difficult in this case is reassignment of sectors after scaling up or before scaling down. Again, Kubernetes will help you with this task.
AdministrationTasks related to administering your Kafka cluster, in particular, creating topics and reassigning sectors, can be done using existing shell scripts, opening the command line interface in your pods. However, this solution is not too beautiful. Strimzi supports managing topics using another operator. There is something to modify here.
Backup & RestoreNow the availability of Kafka with us will depend on the availability of Kubernetes. If your Kubernetes cluster falls, then in the worst case, the Kafka cluster falls as well. Under Murphy’s law, this will happen and you’ll lose data. To mitigate this risk, have a good backup concept. You can use MirrorMaker, another option is to use S3 for this, as described in this
post from Zalando.
Conclusion
When working with small or medium-sized Kafka clusters, it is definitely advisable to use Kubernetes, as it provides additional flexibility and simplifies the work with operators. If you have very serious non-functional requirements regarding latency and / or throughput, then it might be better to consider some other deployment option.