Do you think it's difficult to write your own chatbot in Python that can support the conversation? It turned out to be very easy if you find a good data set. Moreover, this can be done even without neural networks, although some mathematical magic will still be needed.
We will go in small steps: first, remember how to load data into Python, then learn to count words, gradually connect linear algebra and theorver, and in the end we make a bot for Telegram from the resulting chat algorithm.
This tutorial is suitable for those who have already touched Python a little bit, but are not particularly familiar with machine learning. I intentionally did not use any nlp-sh libraries to show that something working can be built on bare sklearn as well.
Search for an answer in the dialog dataset
A year ago, I was asked to show the guys who had not previously been involved in data analysis some inspirational machine learning application that you can build on your own. I tried to put together a bot-chatter, and we really did it in one evening. We liked the process and the result, and wrote about it on
my blog . And now I thought that Habru would be interesting.
So here we go. Our task is to create an algorithm that will give an appropriate answer to any phrase. For example, to “how are you?” To answer “excellent, but what about you?”. The easiest way to achieve this is to find a ready-made database of questions and answers. For example, take subtitles from a large number of movies.
However, I’ll act even more cheatingly, and take the data from
the Yandex.Algorithm 2018 competition - these are the same dialogs from the films for which Toloka workers marked out good and not bad sequels. Yandex collected this data to train Alice (articles about her guts
1 ,
2 ,
3 ). Actually, I was inspired by Alice when I came up with this bot. The last three phrases and the answer to them (reply) are given in the
table from Yandex , but we will use only the most recent one (context_0).
Having such a database of dialogs, you can simply search in it for each replica of the user, and give a ready answer on it (if there are many such replicas, choose randomly). With “how are you?” This turned out great, as evidenced by the attached screenshot. This, if anything, is a
jupyter notebook in Python 3. If you want to repeat this yourself, the easiest way is to install
Anaconda - it includes Python and a bunch of useful packages for it. Or you can not install anything, but run a notepad
in a Google cloud .

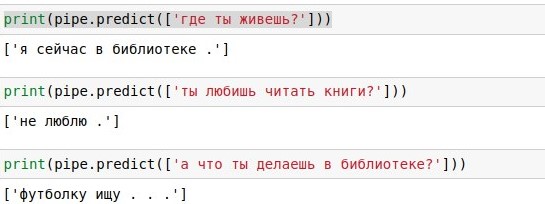
The problem with verbatim searches is that it has low coverage. The phrase “how are you doing?” In the database of 40 thousand answers did not find an exact match, although it has the same meaning. Therefore, in the next section, we will supplement our code using different maths to implement an approximate search. Before that, you can read about the
pandas library and figure out what each of the 6 lines of the above code does.
Text Vectorization
Now we are talking about how to turn texts into numerical vectors in order to perform an approximate search on them.
We have already met with the pandas library in Python - it allows you to load tables, search in them, etc. Now let's touch on the
scikit-learn (sklearn) library, which allows for trickier data manipulation - what is called machine learning. This means that any algorithm must first show the data (fit) so that it learns something important about them. As a result, the algorithm "learns" to do something useful with this data - transform it (transform), or even predict unknown values (predict).
In this case, we want to convert texts (“questions”) into numerical vectors. This is necessary so that it is possible to find texts that are “close” to each other, using the mathematical concept of distance. The distance between two points can be calculated by the Pythagorean theorem - as the root of the sum of the squares of the differences of their coordinates. In mathematics, this is called the Euclidean metric. If we can turn texts into objects that have coordinates, then we can calculate the Euclidean metric and, for example, find in the database a question that most closely resembles “what are you thinking?”.
The easiest way to specify the coordinates of the text is to number all the words in the language, and say that the i-th coordinate of the text is equal to the number of occurrences of the i-th word in it. For example, for the text “I can’t help crying”, the coordinate of the word “not” is 2, the coordinates of the words “I”, “can” and “cry” are 1, and the coordinates of all other words (tens of thousands of which) are 0. This representation loses information about word order, but still works pretty well.
The problem is that for words that are often found (for example, particles “and” and “a”), the coordinates will be disproportionately large, although they carry little information. To mitigate this problem, the coordinate of each word can be divided by the logarithm of the number of texts where such a word occurs - this is called tf-idf and also works well.

There is only one problem: in our database of 60 thousand textual “questions”, which contain 14 thousand different words. If you turn all the questions into vectors, you get a matrix of 60k * 14k. It’s not very cool to work with this, so we’ll talk about reducing the dimension later.
Dimensional reduction
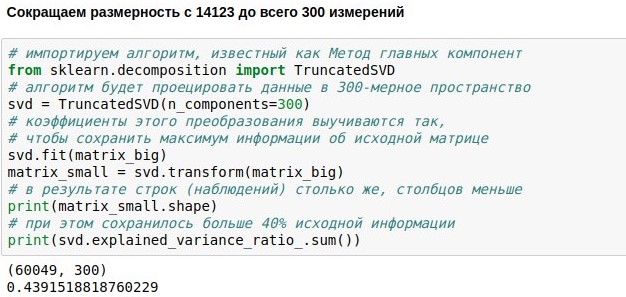
We have already set the task of creating a chat chatbot, downloaded and vectorized data for its training. Now we have a numerical matrix representing user replicas. It consists of 60 thousand rows (there were so many replicas in the database of dialogs) and 14 thousand columns (there were so many different words in them). Our task now is to make it smaller. For example, to present each text not as a 14123-dimensional, but only a 300-dimensional vector.
This can be achieved by multiplying our matrix of size 60049x14123 by a specially selected matrix of projection of size 14123x300, in the end we get the result 60049x300. The PCA algorithm (
principal component method ) selects the projection matrix so that the original matrix can then be reconstructed with the smallest standard error. In our case, it was possible to keep about 44% of the original matrix, although the dimension was reduced by almost 50 times.
What makes such effective compression possible? Recall that the original matrix contains counters for mentioning individual words in the texts. But words, as a rule, are used not independently of each other, but in context. For example, the more times the word “blocking” occurs in the text of the news, the more times, most likely the word “telegrams” is also found in this text. But the correlation of the word "blocking", for example, with the word "caftan" is negative - they are found in different contexts.
So, it turns out that the method of principal components remembers not all 14 thousand words, but 300 typical contexts by which these words can then be tried to be restored. The columns of the projection matrix corresponding to synonymous words are usually similar to each other because these words are often found in the same context. So, it is possible to reduce redundant measurements without losing informativeness.
In many modern applications, the word projection matrix is computed by neural networks (e.g.
word2vec ). But in fact, simple linear algebra is already enough for a practically useful result. The method of principal components is computationally reduced to SVD, and it is to the calculation of the eigenvectors and eigenvalues of the matrix. However, you can program this without even knowing the details.
Search for nearby neighbors
In the previous sections, we downloaded the body of dialogs into python, vectorized it, and reduced the dimension, and now we want to finally learn how to look for the nearest neighbors in our 300-dimensional space and finally answer questions meaningfully.
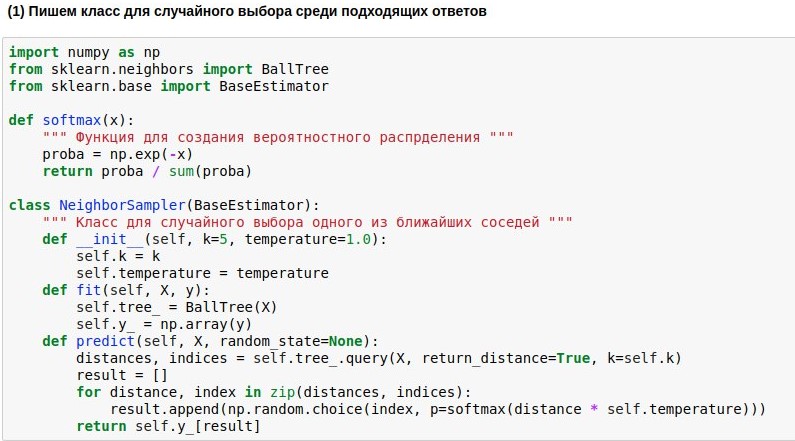
Since we learned how to map questions to the Euclidean space of not very high dimension, the search for neighbors in it can be done quite quickly. We will use the ready-made
BallTree neighbor search algorithm. But we will write our wrapper model, which would choose one of the k nearest neighbors, and the closer the neighbor, the higher the probability of his choice. For to always take one of the closest neighbors is boring, but not to be tied to the resemblance at all is dangerous.
Therefore, we want to turn the found distances from the request to the reference texts into the probability of choosing these texts. To do this, you can use the softmax function, which is often still at the exit from neural networks. She turns her arguments into a set of non-negative numbers, the sum of which is 1 - just what we need. Further, we can use the obtained "probabilities" for a random choice of answer.
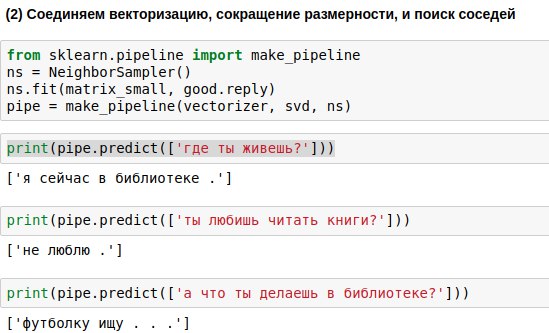
The phrases that the user will enter must be passed through all three algorithms - the vectorizer, the principal component method, and the response selection algorithm. To write less code, you can link them into a single chain (pipeline), which uses the algorithms sequentially.
As a result, we got an algorithm that, on a user's question, is able to find a question similar to it and give an answer to it. And sometimes these answers even sound almost meaningful.
Publish a bot in Telegram
We have already figured out how to make a chatbot chat room that would give out approximately relevant answers to user requests. Now I'm showing you how to release such a chatbot on Telegram.
The easiest way to use this is the ready-made wrapper Telegram API for python - for example,
pytelegrambotapi . So, step by step instructions:
- Register your future bot with @botfather and get an access token, which you will need to insert into your code.
- Run the installation command once - pip install pytelegrambotapi on the command line (or via! Directly in notepad).
- Run the code like in the screenshot. The cell will go into execution mode (*), and while it is in this mode, you can communicate with your bot as much as you want. To stop the bot, press Ctrl + C. The sad, but important truth: if you are in Russia, then most likely, before starting this cell, you will need to turn on the VPN so as not to get an error when connecting to telegrams. A simpler alternative to VPN is to write all the code not on your local computer, but in google colab ( something like this ).
- If you want the bot to work permanently, you need to put its code on some cloud service - for example, AWS, Heroku, now.sh or Yandex.Cloud. You can learn about how to run them in the smallest details on the sites of these services or in articles right there on Habré. For example, a turnip with a small example of a bot running on heroku and putting logs in mongodb.
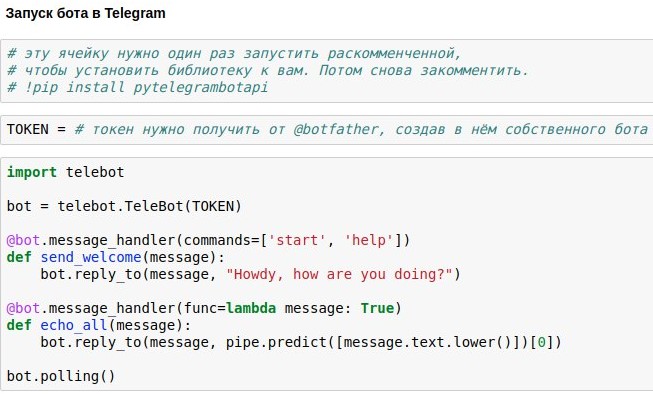
I intentionally do not post the full code for the article - you will get much more pleasure and useful experience when you print it yourself and get a working bot as a result of your own efforts. Well, or if you are too lazy to do this, you can chat with
my version of the bot.