Modern information systems are quite complex. Last but not least, their complexity is due to the complexity of the data processed in them. The complexity of the data often lies in the variety of data models used. So, for example, when the data becomes "large", one of the inconvenient characteristics is considered not only their volume ("volume"), but also their variety ("variety").
If you still do not find a flaw in reasoning, then read on.

The content of the article Polyglot persistence
The foregoing leads to the fact that sometimes in the framework of even one system it is necessary to use several different DBMSs for storing data and solving various problems in processing them, each of which supports its own data model. With the light hand of M. Fowler, the author of a number of famous books and one of the co-authors of Agile Manifesto, this situation was called multivariate storage (“polyglot persistence”).
Fowler also owns the following example of organizing data storage in a fully functional and highly loaded application in the field of electronic commerce.

This example, of course, is somewhat exaggerated, but some considerations in favor of choosing one or another DBMS for the corresponding purpose can be found, for example, here .
It’s clear that being a minister in such a zoo is not easy.
- The amount of code that performs data storage grows in proportion to the number of DBMSs used; the amount of code that synchronizes the data is good if not proportional to the square of that number.
- A multiple of the number of DBMSs used is increasing the costs of providing enterprise characteristics (scalability, fault tolerance, high availability) for each of the DBMSs used.
- It is not possible to provide the enterprise characteristics of the storage subsystem as a whole - especially transactional.
From the point of view of the director of the zoo, everything looks like this:
- A multiple increase in the cost of licenses and technical support from the DBMS manufacturer.
- Staff bloat and longer lead times.
- Direct financial losses or penalties due to inconsistent data.
There is a significant increase in the total cost of ownership of the system (TCO). Is there any way out of the “multivariate storage” situation?
Multimodel
The term "multivariate storage" came into use in 2011. Awareness of the problems of the approach and the search for a solution took several years, and by 2015 the answer was formulated by the mouth of Gartner analysts:
It seems that this time Gartner analysts were not mistaken with the forecast. If you go to the page with the main DBMS rating on DB-Engines, you can see that most of its leaders position themselves precisely as multi-model DBMSs. The same can be seen on the page with any private rating.
The table below shows the DBMS - the leaders in each of the private ratings, declaring their multi-model. For each DBMS, the initial supported model (once the only one) is indicated and, along with it, the models supported now. There are also DBMSs that position themselves as “initially multimodel”, which do not have any original inherited model, according to the creators.
Table notesAsterisks in the table mark statements that require reservations:
- PostgreSQL does not support a graph data model, but it is supported by a product based on it , such as, for example, AgensGraph.
- As applied to MongoDB, it is more correct to speak more about the presence of graph operators in the query language (
$lookup , $graphLookup ) than about support for the graph model, although, of course, their introduction required some optimizations at the physical storage level in the direction of graph model support. - For Redis, this refers to the RedisGraph extension.
Further, for each of the classes we will show how the support of several models in the DBMS from this class is implemented. We will consider the most important relational, document and graph models and show with examples of specific DBMS how the "missing" are implemented.
Multimodel DBMS Based on a Relational Model
The leading DBMSs are currently relational; the Gartner forecast could not be considered true if the RDBMSs did not show movement in the direction of multi-model. And they demonstrate. Now, the idea that a multimodel DBMS is like a Swiss knife, which cannot be done well, can be sent immediately to Larry Ellison.
The author, however, likes the implementation of multimodeling in Microsoft SQL Server, on the example of which the RDBMS support for document and graph models will be described.
Document Model in MS SQL Server
About how MS SQL Server supports document model, there were already two excellent articles on Habr, I will limit myself to a brief retelling and commentary:
The way to support the document model in MS SQL Server is quite typical for relational DBMSs: JSON documents are proposed to be stored in plain text fields. Document model support is to provide special operators to parse this JSON:
The second argument to both operators is an expression in JSONPath-like syntax.
It can be abstractly said that documents stored in this way are not “first-class entities” in a relational DBMS, unlike tuples. Specifically, MS SQL Server currently lacks indexes on fields of JSON documents, which makes it difficult to join tables by the values of these fields and even select documents by these values. However, it is possible to create a computable column and an index on it in this field.
Additionally, MS SQL Server provides the ability to conveniently construct a JSON document from the contents of tables using the FOR JSON PATH statement - a feature that, in a sense, is the opposite of the previous, regular storage. It is clear that no matter how fast the RDBMS is, this approach contradicts the ideology of documented DBMSs, which in fact store ready-made answers to popular queries, and can only solve problems of ease of development, but not speed.
Finally, MS SQL Server allows you to solve the problem, the inverse of the design of the document: you can decompose JSON into tables using OPENJSON . If the document is not completely flat, you will need to use CROSS APPLY .
Graph model in MS SQL Server
Support for graph ( LPG ) models implemented in Microsoft SQL Server is also quite predictable : it is proposed to use special tables for storing nodes and for storing graph edges. Such tables are created using the expressions CREATE TABLE AS NODE and CREATE TABLE AS EDGE respectively.
The tables of the first type are similar to ordinary tables for storing records with the only external difference that the table contains the system field $node_id - a unique identifier for the graph node within the database.
Similarly, tables of the second type have the system fields $from_id and $to_id , records in such tables clearly define the relationships between nodes. A separate table is used to store relationships of each type.
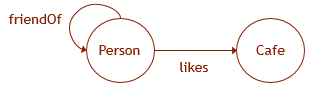 We illustrate what was said by example. Let the graph data have a scheme as shown in the figure. Then, to create the appropriate structure in the database, you need to execute the following DDL queries:
We illustrate what was said by example. Let the graph data have a scheme as shown in the figure. Then, to create the appropriate structure in the database, you need to execute the following DDL queries:
CREATE TABLE Person ( ID INTEGER NOT NULL, name VARCHAR(100) ) AS NODE; CREATE TABLE Cafe ( ID INTEGER NOT NULL, name VARCHAR(100), ) AS NODE; CREATE TABLE likes ( rating INTEGER ) AS EDGE; CREATE TABLE friendOf AS EDGE;
The main specificity of such tables is that it is possible to use graph patterns with Cypher-like syntax in queries to them (however, “ * ”, etc., are not yet supported). Also, based on performance measurements, it can be assumed that the method of storing data in these tables is different from the mechanism for storing data in ordinary tables and is optimized to perform such graph queries.
SELECT Cafe.name FROM Person, likes, Cafe WHERE MATCH (Person-(friendOf)-(likes)->Cafe) AND Person.name = 'John';
Moreover, it’s quite difficult not to use these graph patterns when working with such tables, since in ordinary SQL queries to solve similar problems, additional efforts will be required to obtain system “graph” node identifiers ( $node_id , $from_id , $to_id ; for this for the same reason, data insertion requests are not presented here as too cumbersome).
Summing up the description of the implementations of the document and graph models in MS SQL Server, I would note that such implementations of one model on top of another do not seem successful primarily from the point of view of language design. It is required to expand one language with another, languages are not quite “orthogonal”, the compatibility rules can be quite bizarre.
Multimodel DBMS Based on a Document Model
In this section, I would like to illustrate the implementation of multimodel in document DBMSs using the example of not the most popular of them MongoDB (as was said, it contains only conditionally graph operators $lookup and $graphLookup that do not work on shard collections), but on the example it is more mature and “ Enterprise »DBMS MarkLogic .
So, let the collection contain a set of XML documents of the following form (MarkLogic also allows storing JSON documents):
<Person INN="631803299804"> <name>John</name> <surname>Smith</surname> </Person>
Relational Model at MarkLogic
A relational representation of a collection of documents can be created using a display template (the contents of the value elements in the example below can be arbitrary XPath):
<template xmlns="http://marklogic.com/xdmp/tde"> <context>/Person</context> <rows> <row> <view-name>Person</view-name> <columns> <column> <name>SSN</name> <value>@SSN</value> <type>string</type> </column> <column> <name>name</name> <value>name</value> </column> <column> <name>surname</name> <value>surname</value> </column> </columns> </row> <rows> </template>
An SQL query can be addressed to the created view (for example, via ODBC):
SELECT name, surname FROM Person WHERE name="John"
Unfortunately, the relational view created using the display template is read-only. When processing a request to it, MarkLogic will try to use document indexes . There used to be limited relational views in MarkLogic that were entirely index-based and writable, but now they are considered deprecated.
Graph Model in MarkLogic
With graph ( RDF ) model support, things are pretty much the same. Again, using the display template, you can create an RDF representation of the collection of documents from the example above:
<template xmlns="http://marklogic.com/xdmp/tde"> <context>/Person</context> <vars> <var> <name>PREFIX</name> <val>"http://example.org/example#"</val> </var> </vars> <triples> <triple> <subject><value>sem:iri( $PREFIX || @SSN )</value></subject> <predicate><value>sem:iri( $PREFIX || surname )</value></predicate> <object><value>xs:string( surname )</value></object> </triple> <triple> <subject><value>sem:iri( $PREFIX || @SSN )</value></subject> <predicate><value>sem:iri( $PREFIX || name )</value></predicate> <object><value>xs:string( name )</value></object> </triple> </triples> </template>
The resulting RDF graph can be addressed with a SPARQL query:
PREFIX : <http://example.org/example
Unlike the relational, MarkLogic graph model supports in two other ways:
- The DBMS can be a full-fledged separate repository of RDF data (triplets in it will be called managed, as opposed to extracted above).
- RDF in special serialization can simply be inserted into XML or JSON documents (and triplets will then be called unmanaged ). This is probably such an alternative to
idref mechanisms, etc.
The Optic API gives a good idea of how “really” everything works in MarkLogic, in this sense it is low-level, although its purpose is rather the opposite - to try to abstract from the data model used, to ensure consistent work with data in different models, transactionality and etc.
Multimodel DBMS “without the main model”
DBMSs are also available on the market, positioning themselves as initially multi-model, not having any inherited basic model. These include ArangoDB , OrientDB (since 2018, the development company belongs to SAP) and CosmosDB (a service included in the Microsoft Azure cloud platform).
In fact, there are “basic” models in ArangoDB and OrientDB. In both cases, these are proprietary data models, which are document generalizations. Generalizations are mainly to facilitate the ability to produce graph and relational queries.
These models are the only ones available for use in the indicated DBMSs; their own query languages are designed to work with them. Of course, such models and DBMSs are promising, but the lack of compatibility with standard models and languages makes it impossible to use these DBMSs in legacy systems - replacing them with the DBMS they already use.
About ArangoDB and OrientDB on Habré there was already a wonderful article: JOIN in NoSQL databases .
Arangodb
ArangoDB announces support for the graph data model.
Graph nodes in ArangoDB are ordinary documents, and edges are documents of a special kind that have, along with the usual system fields ( _key , _id , _rev ), the system fields _from and _to . Documents in document DBMSs are traditionally combined into collections. Collections of documents representing edges in ArangoDB are called edge collections. By the way, documents of edge collections are also documents, therefore edges in ArangoDB can also act as nodes.
Initial dataSuppose we have a collection of persons whose documents look like this:
[ { "_id" : "people/alice" , "_key" : "alice" , "name" : "" }, { "_id" : "people/bob" , "_key" : "bob" , "name" : "" } ]
Let also have a collection of cafes :
[ { "_id" : "cafes/jd" , "_key" : "jd" , "name" : " " }, { "_id" : "cafes/jj" , "_key" : "jj" , "name" : "-" } ]
Then the likes collection might look like this:
[ { "_id" : "likes/1" , "_key" : "1" , "_from" : "persons/alice" , "_to" : "cafes/jd", "since" : 2010 }, { "_id" : "likes/2" , "_key" : "2" , "_from" : "persons/alice" , "_to" : "cafes/jj", "since" : 2011 } , { "_id" : "likes/3" , "_key" : "3" , "_from" : "persons/bob" , "_to" : "cafes/jd", "since" : 2012 } ]
Queries and ResultsA graph-style query in the AQL language used in ArangoDB that returns in human-readable form information about who likes which cafe looks like this:
FOR p IN persons FOR c IN OUTBOUND p likes RETURN { person : p.name , likes : c.name }
In a relational style, when we are more likely to “calculate” the relationships, rather than store them, this query can be rewritten like this (by the way, you could do without the likes collection):
FOR p IN persons FOR l IN likes FILTER p._key == l._from FOR c IN cafes FILTER l._to == c._key RETURN { person : p.name , likes : c.name }
The result in both cases will be the same:
[ { "person" : "" , likes : "-" } , { "person" : "" , likes : " " } , { "person" : "" , likes : " " } ]
More queries and resultsIf it seems that the format of the result above is more typical for a relational DBMS than for a document one, you can try this query (or you can use COLLECT ):
FOR p IN persons RETURN { person : p.name, likes : ( FOR c IN OUTBOUND p likes RETURN c.name ) }
The result will be as follows:
[ { "person" : "" , likes : ["-" , " "] } , { "person" : "" , likes : [" "] } ]
Oriententb
The implementation of the graph model on top of the document model in OrientDB is based on the ability of document fields to have, in addition to more or less standard scalar values, values of types such as LINK , LINKLIST , LINKSET , LINKMAP and LINKBAG . The values of these types are links or collections of links to system document identifiers .
The document identifier assigned by the system has “physical meaning”, indicating the position of the record in the database, and looks something like this: @rid : #3:16 . Thus, the values of reference properties are really more likely pointers (as in a graph model), rather than selection conditions (as in a relational model).
As in ArangoDB, in OrientDB the edges are represented by separate documents (although if the edge does not have its own properties, it can be made lightweight and a separate document will not correspond to it).
Initial dataIn a format close to the OrientDB database dump format , the data from the previous example for ArangoDB would look something like this:
[ { "@type": "document", "@rid": "#11:0", "@class": "Person", "name": "", "out_likes": [ "#30:1", "#30:2" ], "@fieldTypes": "out_likes=LINKBAG" }, { "@type": "document", "@rid": "#12:0", "@class": "Person", "name": "", "out_likes": [ "#30:3" ], "@fieldTypes": "out_likes=LINKBAG" }, { "@type": "document", "@rid": "#21:0", "@class": "Cafe", "name": "-", "in_likes": [ "#30:2", "#30:3" ], "@fieldTypes": "in_likes=LINKBAG" }, { "@type": "document", "@rid": "#22:0", "@class": "Cafe", "name": " ", "in_likes": [ "#30:1" ], "@fieldTypes": "in_likes=LINKBAG" }, { "@type": "document", "@rid": "#30:1", "@class": "likes", "in": "#22:0", "out": "#11:0", "since": 1262286000000, "@fieldTypes": "in=LINK,out=LINK,since=date" }, { "@type": "document", "@rid": "#30:2", "@class": "likes", "in": "#21:0", "out": "#11:0", "since": 1293822000000, "@fieldTypes": "in=LINK,out=LINK,since=date" }, { "@type": "document", "@rid": "#30:3", "@class": "likes", "in": "#21:0", "out": "#12:0", "since": 1325354400000, "@fieldTypes": "in=LINK,out=LINK,since=date" } ]
As we can see, the vertices also store information about incoming and outgoing edges. When using the Document API, you have to follow the referential integrity yourself, and the Graph API takes care of this. But let's see what the call to OrientDB looks like in “clean”, non-integrated into programming languages, query languages.
Queries and ResultsA query similar in purpose to the query from the example for ArangoDB in OrientDB looks like this:
SELECT name AS person_name, OUT('likes').name AS cafe_name FROM Person UNWIND cafe_name
The result will be obtained as follows:
[ { "person_name": "", "cafe_name": " " }, { "person_name": "", "cafe_name": "-" }, { "person_name": "", "cafe_name": "-" } ]
If the format of the result again seems too "relational", you need to remove the line with UNWIND() :
[ { "person_name": "", "cafe_name": [ " ", "-" ] }, { "person_name": "", "cafe_name": [ "-" ' } ]
OrientDB query language can be described as SQL with Gremlin-like inserts. Version 2.2 introduced a Cypher-like request form, MATCH :
MATCH {CLASS: Person, AS: person}-likes->{CLASS: Cafe, AS: cafe} RETURN person.name AS person_name, LIST(cafe.name) AS cafe_name GROUP BY person_name
The format of the result will be the same as in the previous query. Think about what needs to be removed to make it more “relational”, as in the very first query.
Azure CosmosDB
To a lesser extent, what was said above about ArangoDB and OrientDB refers to Azure CosmosDB. CosmosDB provides the following data access APIs: SQL, MongoDB, Gremlin, and Cassandra.
The SQL API and MongoDB API are used to access data in the document model. Gremlin API and Cassandra API - for accessing data in graph and column, respectively. Data in all models is saved in the format of the CosmosDB internal model: ARS (“atom-record-sequence”), which is also close to the document one.

But the data model selected by the user and the API used are fixed at the time of creating the account in the service. It is impossible to access data loaded in one model in the format of another model, which would be illustrated by something like this:

Thus, multimodel in Azure CosmosDB today is only an opportunity to use several databases that support different models from one manufacturer, which does not solve all the problems of multivariate storage.
Multimodel DBMS Based on a Graph Model?
It is noteworthy that on the market there are no multimodel DBMSs based on a graph model (except for multimodel support for simultaneously two graph models: RDF and LPG; see this in a previous publication ). The greatest difficulties are the implementation on top of the graph model of the document, rather than the relational one.
The question of how to implement a relational model over a graph model was considered even at the time of the formation of the latter. As David McGovern said , for example:
There is nothing inherent in the graph approach that prevents creating a layer (eg, by suitable indexing) on a graph database that enables a relational view with (1) recovery of tuples from the usual key value pairs and (2) grouping of tuples by relation type.
When implementing the document model on top of the graph, you need to keep in mind, for example, the following:
- Elements of the JSON array are considered ordered, coming from the top of the edge of the graph - no;
- The data in the document model is usually denormalized, you still do not want to store several copies of the same attached document, and subdocuments usually do not have identifiers;
- On the other hand, the ideology of documented DBMSs is that documents are ready-made “aggregates” that do not need to be rebuilt every time. It is required to provide in the graph model the ability to quickly obtain the subgraph corresponding to the finished document.
Some advertisingThe author of the article is related to the development of the NitrosBase DBMS, the internal model of which is graphical, and the external models - relational and document - are its representations. All models are equal: almost any data is available in any of them using the query language natural for it. Moreover, in any representation, the data is subject to change. Changes will be reflected in the internal model and, accordingly, in other representations.
What model matching looks like in NitrosBase - I will describe, I hope, in one of the following articles.
Conclusion
I hope that the general contours of what is called multimodeling have become more or less clear to the reader. Quite different DBMSs are called multimodels, and “support for several models” may look different. To understand what is called “multi-model” in each case, it is useful to answer the following questions:
- Is it about supporting traditional models, or about a single hybrid model?
- Are the models “equal”, or is one of them subject to the others?
- Are the models "indifferent" to each other? Can the data recorded in one model be read in another or even overwritten?
I think that it is already possible to give a positive answer to the question of the relevance of multi-model DBMSs, but the interesting question is which of their varieties will be more in demand in the near future. It seems that multi-model DBMSs that support traditional models, primarily relational ones, will be more in demand; , , , — .