
When you listen all day for technical interviews, you begin to notice patterns. Rather, in our case, their absence. I managed to discover just two things that remain unchanged. I even came up with an alcoholic game based on them: every time someone decides that the answer to the question is a hash table, we drink a stack, if the correct answer is really a hash table, we drink two. But I don’t advise playing it, I almost died.
Why am I listening to interviews all day? Because a few years ago he became one of the creators of the
interviewing.io service, an
interview platform where people from the IT sphere can develop communication skills with the employer and find work in the meanwhile.
As a result, I have access to a large amount of data about how the same user shows himself at different interviews. And they turn out to be so unpredictable that inevitably you will think about how generally indicative the results of a single meeting are.
How do we get the data
When the user conducting the interview and the user looking for work find each other, they meet in a joint code editor. There the ability to communicate in voice and through text messages is connected, there is an analogue of a marker board for recording decisions - you can immediately start technical issues.
Questions at our interviews are usually from the category of those asked during the telephone interview to applicants for the position of backend software developer. Users conducting interviews are usually employees of large companies (Google, Facebook, Yelp) or representatives of startups with a strong technical bias (Asana, Mattermark, KeepSafe and others). At the end of each meeting, employers evaluate candidates according to several criteria, one of which is programming skills. Ratings are put on a scale from one (“so-so”) to four (“great!”). On our platform, grades from three and above in most cases mean that the candidate is strong enough to go to the next stage.
Here you can say: “This is all wonderful, but what is special about it? Many companies collect such statistics in the selection process. ” Our data differ from these statistics in one respect: the same user can take part in several interviews, each of them will be with a new employee from the new company. This opens up opportunities for a very interesting comparative analysis in a more or less stable environment.
Conclusion # 1: Results vary greatly from interview to interview
Let's start with a couple of pictures. In the graph below, each icon in the form of a little man shows the average individual rating of one of the users who took part in two or more interviews. One of the parameters that is not displayed on this chart is the time period.
You can see how people's successes change over time, here. There is something in the spirit of primitive chaos.
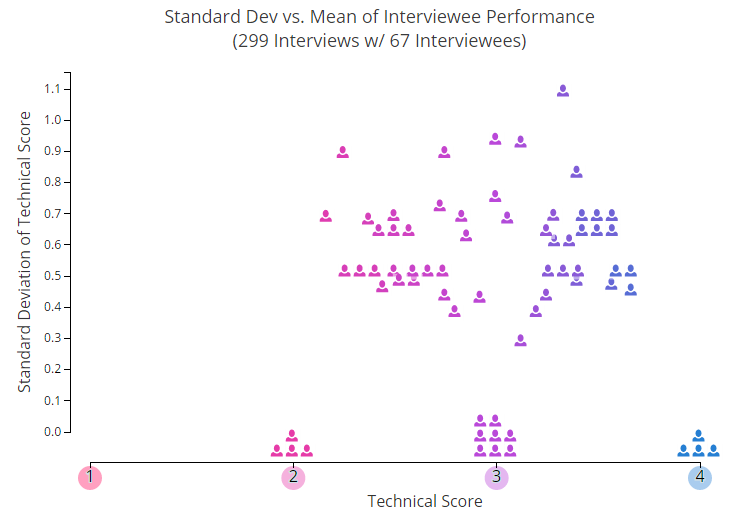
The Y axis shows a typical deviation from the average values - accordingly, the higher we go up, the more unpredictable are the results of the interviews. As you can see, approximately 25% of the participants are stably kept at the same level, while the rest of them all jump up and down.
Having carefully studied this schedule, you, in spite of a pile of data, would probably be able to roughly figure out which of the users you would like to invite for an interview. But here it is important to remember: we took average values. Now imagine that you need to make a decision based on one single assessment, which was used to calculate it. This is where the problems begin.
For greater clarity, you can open a
drop dead interactive version of the chart . There, each icon opens when you hover over and you can see what grade the user received at each of the interviews. The results can greatly surprise you! Well, for example:
- The lion's share of those who have at least one four have at least once found themselves in the “doubles”
- Even if you select only the strongest candidates (average score is from 3.3 and higher), the results still fluctuate significantly
- The "average" (average score - from 2.6 to 3.3), the results are particularly contradictory
We wondered if there was any relationship between the level of the candidate and the amplitude of the vibrations. In other words, maybe for those weaker, there are characteristic sharp jumps, while strong programmers are stable? As it turns out, no. When we performed a regression analysis of a typical deviation with respect to the average estimate, we failed to establish any significant relationship (R squared was about 0.03). And this means that people get different grades, regardless of their general level.
I would say this: when you look at all this data, and then imagine that you need to choose a person based on the results of one interview, it feels like you are looking at a beautiful, luxuriously furnished room through a keyhole. In one case, you are lucky to see a picture on the wall, in another - a collection of wines, and in the third - you’ll bury yourself in the back of the sofa.
In real situations, when we are trying to decide whether to call an applicant for an interview in the office, we usually try to avoid mistakes of the first kind (that is, do not randomly select those who are short of the bar) and mistakes of the second kind (that is, not to refuse those who it would be worth inviting). In this case, market leaders usually build a strategy based on the fact that mistakes of the second kind do less harm. It seems logical, right? If there are enough resources and the number of applicants is large, even with a large number of errors of the second kind, there will still be someone suitable.
But this strategy of making mistakes of the second kind has a shadow side, and now it makes itself felt, spilling into the current hiring crisis in the IT sphere. Do single interviews in their current form provide enough information? Are we rejecting, despite the increased demand for talented developers, competent workers simply because we are trying to consider an extensive schedule with strong differences through a tiny peephole?
So, if we ignore metaphors and moral reading: since the results of the interviews are so unpredictable, what is the likelihood that a strong candidate will fail in a telephone interview?
Conclusion No. 2: The probability of failure at the interview based on the results of past attempts
Below is the percentage distribution of our entire user base by average estimates.
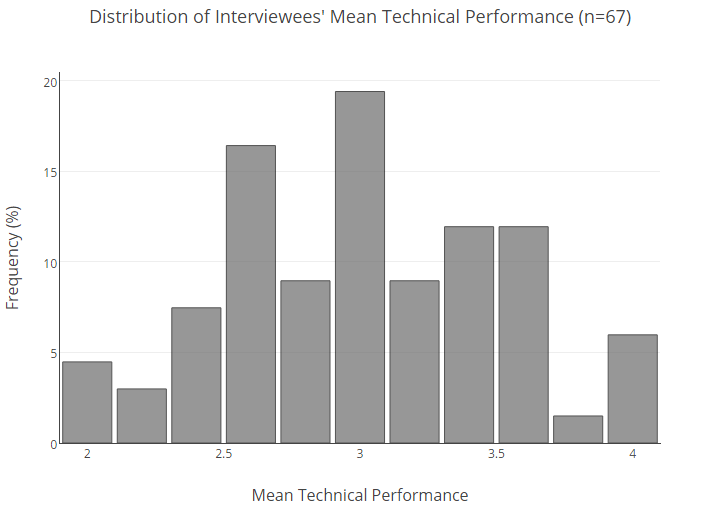
To understand the likelihood that a candidate with a certain average result will not show himself well in an interview, we had to do statistics.
First, we divided the interviewees into groups based on average ratings (with the values being rounded up within 0.25). Then, for each group, the probability of failure was calculated, that is, obtaining a score of 2 or lower. Further, to compensate for the modest amount of data, we
re-sampled .
When compiling the re-sampling, we considered the result of a future interview as a multi-nominal distribution. In other words, we presented that its results are determined by the roll of a dice with four faces, and for each group the center of gravity of the cube is shifted in a certain way.
Then we began to roll these dice until we created a new set of simulated data for each group. New failure probabilities for users with different estimates were calculated based on these data. Below you can see the graph that we received after 10,000 such throws.
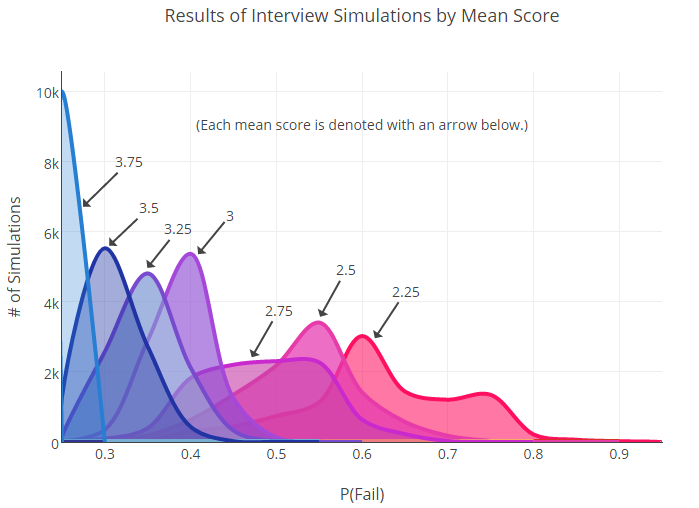
As you can see, there are many intersections. This is important: the fact of overlap tells us that between some of the groups (for example, 2.75 and 3) there can be no statistically significant differences.
Of course, when we have more data (much more), the boundaries between the groups will be clearer. On the other hand, the very fact that a huge sample is needed to find the difference between the failure rate indicators may indicate an initially high variability in the results for the average user.
In the end, with confidence we can say the following: the difference between the extreme points of the scale (2.25 and 3.75) is significant, but everything in between is already much less unambiguous.
Nevertheless, based on this distribution, we made an attempt to calculate the percentage probability that a candidate with one or another average rating will show a poor result in a single interview:
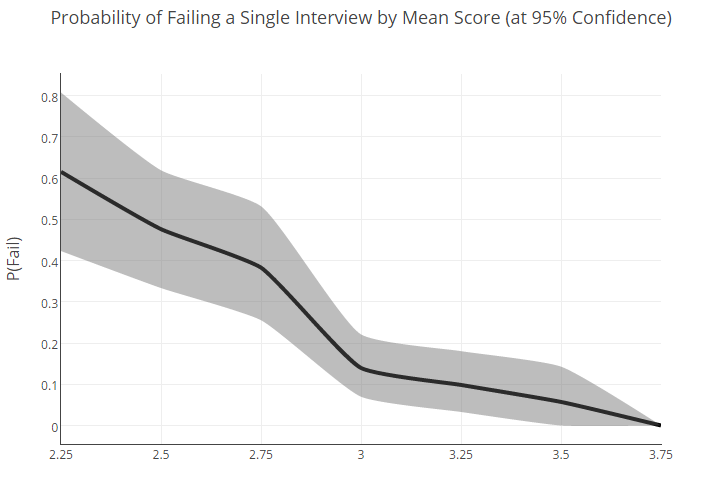
The fact that people with a good general level (i.e., an average rating of about 3) can fail with a probability of 22% shows that the selection schemes that we use now can and should be improved. Foggy results for the "average" only confirm this conclusion.
So, are interviews doomed?
In general, the word “interviews” evokes in our minds an image of something informative and giving reproducible results. However, the data we have collected speaks about something completely different. And this has something else in common with my personal experience in hiring employees, and with the opinions that I often hear in the community.
Zack Holman's article
Startup Interviewing is F ***** elucidates this discrepancy between the grounds for selecting candidates and the work they have to do. The honorable gentlemen of TripleByte
came to similar conclusions , having processed their own data. The
rejected.us platform recently provided vivid evidence of inconsistency in the interview process.
It can be argued that many who were screened out after a telephone interview with company A showed the best result at another interview, turned up in some of the companies that are considered decent - and now, six months later, they receive offers to talk from recruiters from company A. And despite all the efforts of both parties, this process of slurred, unpredictable and, ultimately, random selection of candidates continues, as if in a magic circle.
So yes, of course, one of the conclusions that can be drawn is that technical interviews have come to a standstill, they do not provide enough reliable information to predict the outcome of an individual interview. Interviews with algorithmic problems are a very hot topic in the community, and we would like to analyze it in detail in the future.
It will be especially interesting to trace the relationship between the success of candidates and the type of interview - we have more and more approaches and variations appearing on our platform. In fact, this is one of our long-term goals: how to dig into the collected data, examine the range of current candidate selection strategies and make some serious, data-backed conclusions about which interview formats provide the most useful information.
In the meantime, I am inclined to the idea that it is better to look at a generalized level than to be guided in an important decision by the arbitrary results of a single meeting. The generalized data allows us to make a correction not only for those who in an isolated case responded uncharacteristically weakly, but also for those who left a good impression purely out of luck or eventually bowed their heads in front of this monster and memorized Cracking the Coding Interview.
I understand that it is not always practical or even possible for a company to collect other evidence of candidate skill somewhere in the wild. But if, say, a borderline case or a person does not show himself at all as you expected, it probably makes sense to talk to them again and switch to another material before making a final decision.