From time to time, in order to move to the Central nervous system, I will interview in various large companies, mainly St. Petersburg and Moscow, for the position of DevOps. I noticed that in many companies (in many good companies, for example, Yandex) they ask two similar questions:
- what is inode;
- for what reasons it is possible to get an error writing to the disk (or for example: why the disk space may run out, one essence).
As often happens, I was sure that I knew this topic well, but as soon as I began to explain, there were marked gaps in knowledge. In order to systematize my knowledge, fill in the gaps and no longer disgrace, I am writing this article, it may still come in handy.
I will start “from below”, i.e. from the hard drive (flash drives, SSDs and other modern things, we discard, for example, consider any 20 or 80 gigabyte old drive, because there the block size is 512 bytes).
The hard drive does not know how to address its space by byte, conditionally it is divided into blocks. Block numbering starts with 0. (this is called LBA, details here:
en.wikipedia.org/wiki/LBA )
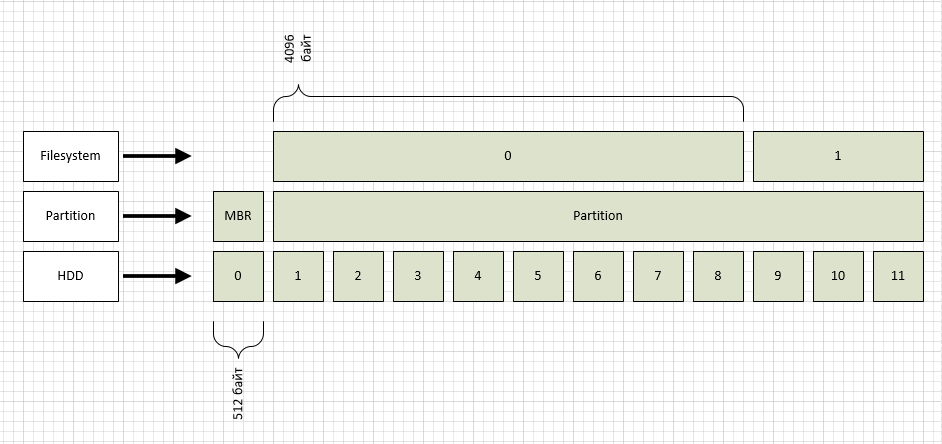
As you can see from the figure, I designated the LBA blocks as the HDD level. By the way, you can see what block size your disk has:
root@ubuntu:/home/serp
A higher level partition is marked up, one for the entire disk (again for simplicity). Most often, two types of partition markup are used: msdos and gpt. Accordingly, msdos is an old format that supports disks up to 2Tb, gpt is a new format that can address up to 1 zetabyte of 512 byte blocks. In our case, we have a section of type msdos, as can be seen from the figure, the section in this case begins with block No. 1, while the zero section is used for MBR.
In the first section, I created the ext2 file system, by default it has a block size of 4096 bytes, which is also shown in the figure. You can see the file system block size like this:
root@ubuntu:/home/serp
The parameter we need is “Block size”.
Now the most interesting is how to read the file / home / serp / testfile? A file consists of one or more blocks of the file system in which its data is stored. Knowing the file name, how to find it? What blocks to read?
This is where inodes come in handy. The ext2fs file system has a “table” that contains information on all inodes. The number of inodes in the case of ext2fs is set when creating the file system. We look at the necessary numbers in the “Inode count” parameter of the tune2fs output, i.e. we have 65536 pieces. The inode contains the information we need: a list of file system blocks for the file you are looking for. How to find the inode number for the specified file?
The correspondence of the name and inode number is contained in the directory, and the directory in ext2fs is a file of a special type, i.e. also has its own inode number. To break this vicious circle, a “fixed” inode number “2” was assigned to the root directory. We look at the contents of the inode number 2:
root@ubuntu:/
As you can see, the directory we need is contained in the block with the number 579. In it we will find the node number for the home folder, and so on along the chain until we see the node number for the requested file in the serp directory. If suddenly someone wants to check if the number is correct and if there is the right info there, it's not difficult. We do:
root@ubuntu:/
In the output, you can read the file names in the directory.
So I came to the main question: "for what reasons can a recording error occur"?
Naturally, this will happen if there are no free blocks in the file system. What can be done in this case? Besides the obvious “delete something unnecessary”, it should be remembered that in ext2,3 and 4 file systems there is such a thing as “Reserved block count”. If you look at the listing above, then we have such blocks "13094". These blocks are writable only by root. but if you need to quickly resolve the issue, how can a temporary solution be made available to everyone, resulting in a little free space:
root@ubuntu:/mnt
Those. by default, you do not have 5% of the disk space available for writing, and given the volume of modern disks, it can be hundreds of gigabytes.
What else could be? Another situation is possible when there are free blocks, but the nodes are over. This usually happens if you have a bunch of files in the file system that are smaller than the file system block size. Considering that 1 inode is spent on 1 file or directory, and in total we have them (for this file system) 65536 - the situation is more than real. This can be clearly seen from the output of the df command:
serp@ubuntu:~$ df -hi Filesystem Inodes IUsed IFree IUse% Mounted on udev 493K 480 492K 1% /dev tmpfs 493K 425 493K 1% /run /dev/xvda1 512K 240K 273K 47% / none 493K 2 493K 1% /sys/fs/cgroup none 493K 2 493K 1% /run/lock none 493K 1 493K 1% /run/shm none 493K 2 493K 1% /run/user /dev/xvdc1 320K 4,1K 316K 2% /var /dev/xvdb1 64K 195 64K 1% /home /dev/xvdh1 4,0M 3,1M 940K 78% /var/www serp@ubuntu:~$ df -h Filesystem Size Used Avail Use% Mounted on udev 2,0G 4,0K 2,0G 1% /dev tmpfs 395M 620K 394M 1% /run /dev/xvda1 7,8G 2,9G 4,6G 39% / none 4,0K 0 4,0K 0% /sys/fs/cgroup none 5,0M 0 5,0M 0% /run/lock none 2,0G 0 2,0G 0% /run/shm none 100M 0 100M 0% /run/user /dev/xvdc1 4,8G 2,6G 2,0G 57% /var /dev/xvdb1 990M 4,0M 919M 1% /home /dev/xvdh1 63G 35G 25G 59% /var/www
As is clearly seen on the / var / www section, the number of free blocks in the file system and the number of free nodes vary greatly.
In case I run out of inode, I won’t tell you spells, because they are not (if not right, let me know). So for the sections in which small files multiply, you should correctly select the file system. So for example in btrfs inodes cannot end, because dynamically create new ones if necessary.