The two previous series of articles have focused on
isolation and multiversionism and
journaling .
In this series we will talk about locks. I will adhere to this term, but in literature there may also be another:
castle .
The cycle will consist of four parts:
- Relationship locks (this article);
- Row locks ;
- Locks of other objects and predicate locks;
- Locks in RAM.
The material of all articles is based on administrative
training courses that Pavel
pluzanov and I
do , but do not repeat them verbatim and are intended for thoughtful reading and independent experimentation.
General information about locks
PostgreSQL uses many different mechanisms that are used to block something (or at least are called that). Therefore, I will start with the most general words about why locks are needed at all, what they are and how they differ from each other. Then we will see what of this variety is found in PostgreSQL and only after that we will begin to deal with different types of locks in detail.
Locks are used to streamline concurrent access to shared resources.
Competitive access refers to the simultaneous access of several processes. The processes themselves can be performed both in parallel (if the equipment allows) and sequentially in the time-sharing mode - this is not important.
If there is no competition, then there is no need for locks (for example, a shared buffer cache requires locks, but a local one does not).
Before accessing a resource, a process must acquire the lock associated with that resource. That is, we are talking about a certain discipline: everything works as long as all processes comply with the established rules for accessing a shared resource. If the DBMS manages the locks, then it itself monitors the order; if blocking is set by the application, then this obligation falls on him.
At a low level, a lock is represented by a portion of shared memory, in which it is noted in some way whether the lock is free or captured (and, possibly, additional information is recorded: process number, capture time, etc.).
You may notice that such a piece of shared memory is in itself a resource to which competitive access is possible. If we go down to a lower level, we will see that special accessory primitives (such as semaphores or mutexes) provided by the OS are used to organize access. Their meaning is that the code accessing the shared resource should be executed in only one process at a time. At the lowest level, these primitives are implemented based on atomic processor instructions (such as test-and-set or compare-and-swap).
After the resource is no longer needed by the process, it
releases the lock so that others can use the resource.
Of course, locking the lock is not always possible: the resource may already be taken by someone else. Then the process either enters the waiting queue (if the locking mechanism gives such an opportunity), or retries to capture the lock after a certain time. One way or another, this leads to the fact that the process is forced to stand idle in anticipation of the release of the resource.
Sometimes it is possible to apply other non-blocking strategies. For example, the multi- versioning mechanism allows several processes in some cases to work simultaneously with different versions of data without blocking each other.
In principle, a protected resource can be anything, if only this resource could be unambiguously identified and matched with a blocking address.
For example, the resource can be the object that the DBMS is working with, such as a data page (identified by the file name and position within the file), a table (oid in the system directory), a table row (page and offset inside the page). A resource can be a structure in memory, such as a hash table, buffer, etc. (identified by a pre-assigned number). Sometimes it is even convenient to use abstract resources that do not have any physical meaning (they are identified simply by a unique number).
The effectiveness of locks is influenced by many factors, of which we distinguish two.
- Granularity (granularity) is important if resources form a hierarchy.
For example, a table consists of pages that contain table rows. All of these objects can act as resources. If processes are usually interested in just a few rows, and the lock is set at the table level, then other processes will not be able to work with different rows at the same time. Therefore, the higher the granularity, the better for the possibility of parallelization.
But this leads to an increase in the number of locks (information about which must be stored in memory). In this case, an increase in the level (escalation) of locks can be applied: when the number of low-level, granular locks exceeds a certain limit, they are replaced with one lock of a higher level.
- Locks can be captured in different modes .
The names of the modes can be absolutely arbitrary, only the matrix of their compatibility with each other is important. A regime incompatible with any regime (including itself) is usually called exclusive or exclusive. If the modes are compatible, then the lock can be captured by several processes simultaneously; such modes are called shared. In general, the more different modes compatible with each other can be distinguished, the more opportunities are created for parallelism.
According to the time of use, locks can be divided into long and short.
- Long-term locks are captured for a potentially long time (usually until the end of the transaction) and most often relate to resources such as tables (relationships) and rows. PostgreSQL typically manages these locks automatically, but the user nevertheless has some control over this process.
Long locks are characterized by a large number of modes so that as many simultaneous actions as possible can be performed on the data. Typically, for such locks, there is a developed infrastructure (for example, support of waiting queues and detection of deadlocks) and monitoring tools, since the costs of maintaining all these amenities are still incomparably lower than the cost of operations on protected data.
- Short-term locks are captured for a short time (from a few processor instructions to fractions of a second) and usually refer to data structures in shared memory. PostgreSQL manages such locks completely automatically - you just need to know about their existence.
Short locks are characterized by a minimum of modes (exclusive and shared) and a simple infrastructure. In some cases, even monitoring tools may not be available.
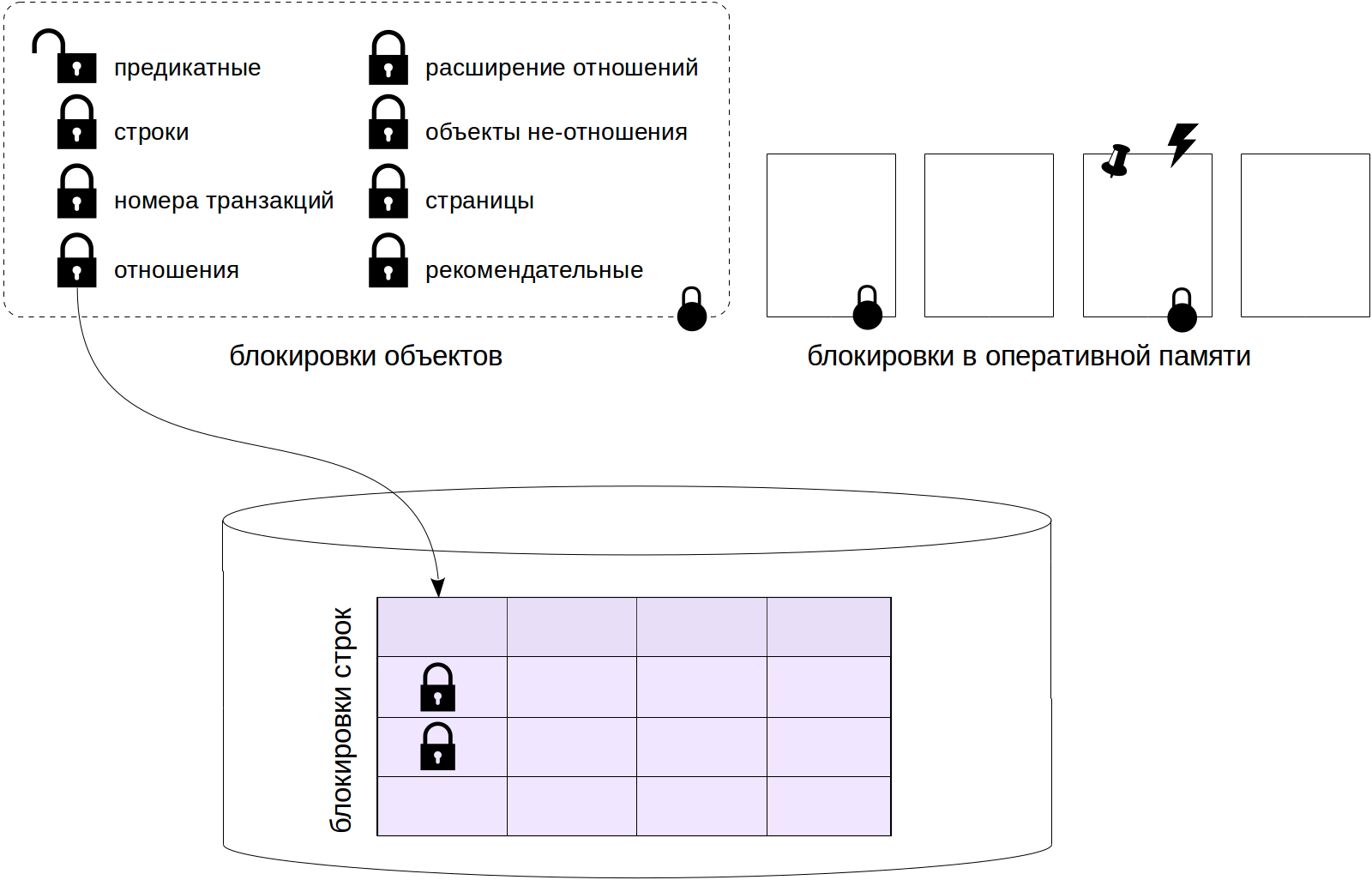
PostgreSQL uses different types of locks.
Locks at the object level are long-term, “heavy ones”. The resources here are relations and other objects. If the word blocking appears in the text without clarification, then it denotes just such a “normal” blocking.
Among long-term locks,
row-level locks stand out separately. Their implementation is different from other long-term locks due to their potentially huge number (imagine updating a million rows in one transaction). Such locks will be discussed in the next article.
The third article in the series will be devoted to the remaining locks at the object level, as well as
predicate locks (since information about all these locks is stored in RAM in the same way).
Short locks include various
locks of RAM structures . We will consider them in the last article of the cycle.
Object locks
So, we start with object level locks. Here, an object is understood primarily as
relations (relations), that is, tables, indexes, sequences, materialized representations, but also some other entities. These locks usually protect objects from being changed at the same time or from being used while the object is changing, but also for other needs.
Vague wording? It is, because locks from this group are used for a variety of purposes. What unites them is how they are arranged.
Device
Object locks are located in the server’s shared memory. Their number is limited by the product of the values of two parameters:
max_locks_per_transaction ×
max_connections .
The lock pool is common for all transactions, that is, one transaction can capture more locks than
max_locks_per_transaction : it is only important that the total number of locks in the system does not exceed the set limit. The pool is created at startup, so changing either of the two options indicated requires a server reboot.
All locks can be viewed in the pg_locks view.
If a resource is already locked in incompatible mode, a transaction trying to capture this resource is queued and waits for the lock to be released. Pending transactions do not consume processor resources: the corresponding service processes “fall asleep” and wake up by the operating system when the resource is released.
A
deadlock or
deadlock situation is possible in which one transaction requires a resource occupied by the second transaction to continue, and the second requires a resource occupied by the first (in the general case, a deadlock and more than two transactions can occur). In this case, the wait will continue indefinitely, so PostgreSQL will automatically detect such situations and crash one of the transactions so that others can continue to work. (We'll talk more about deadlocks in the next article.)
Object Types
Here is a list of lock types (or, if you will, types of objects) that we will deal with in this and the next article. The names are given in accordance with the locktype column of the pg_locks view.
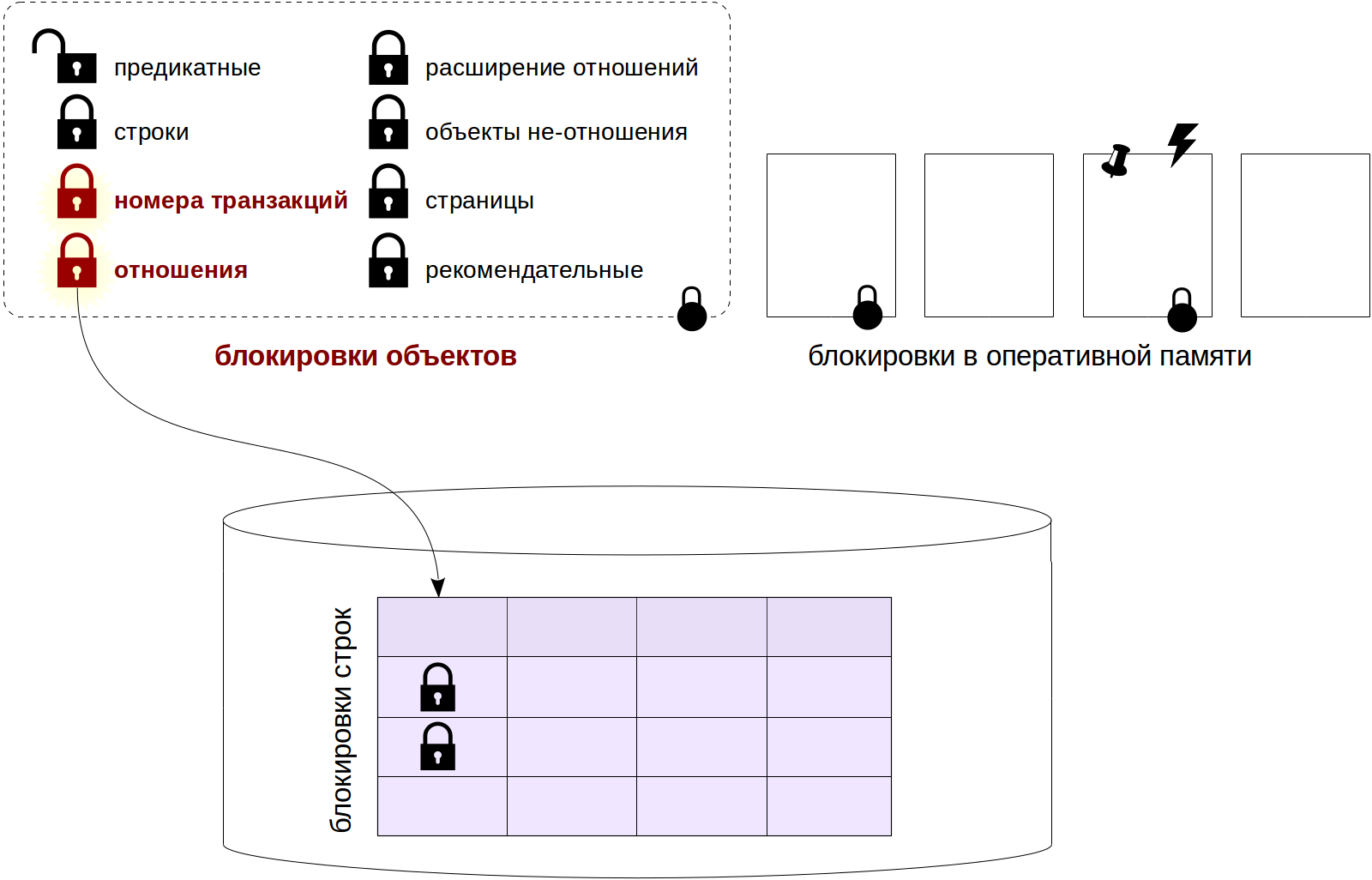
- relation
Relationship locks.
- transactionid and virtualxid
Blocking a transaction number (real or virtual). Each transaction itself holds an exclusive lock of its own number, so such locks are convenient to use when you need to wait until the end of another transaction.
- tuple
String version lock. It is used in some cases to set priority among several transactions that expect to lock the same row.
We will postpone the discussion of the remaining types of locks until the third article in the cycle. All of them are captured either only in exceptional mode, or in exclusive and shared.
- extend
Used when adding pages to a file of any relationship.
- object
Locking objects that are not relationships (databases, schemas, subscriptions, etc.).
- page
Page lock is used infrequently and only by some types of indexes.
- advisory
Recommended blocking, manually set by the user.
Relationship locks
In order not to lose context, I will mark on such a picture those types of locks, which will be discussed later.
Modes
If not the most important, then certainly the most “branchy” blocking - blocking relations. For her, as many as 8 different modes are defined. Such a quantity is necessary so that the greatest possible number of commands related to one table can be executed simultaneously.
It makes no sense to learn these modes by heart or try to understand the meaning of their names; the main thing is to have a
matrix in front of your eyes at the right time, which shows which locks conflict with each other. For convenience, it is reproduced here along with examples of commands that require appropriate locking levels:
Some comments:
- The first 4 modes allow simultaneous data changes in the table, and the next 4 do not.
- The first mode (Access Share) is the weakest, it is compatible with any other than the last (Access Exclusive). This last mode is exclusive, it is not compatible with any mode.
- The ALTER TABLE command has many options, different of which require different levels of locking. Therefore, in the matrix, this command appears on different lines and is marked with an asterisk.
For example, for example
give an example. What happens if I run the CREATE INDEX command?
We find in the documentation that this command sets the lock in Share mode. According to the matrix, we determine that the command is compatible with itself (that is, you can simultaneously create multiple indexes) and with reading commands. Thus, the SELECT commands will continue to work, but the UPDATE, DELETE, INSERT commands will be blocked.
And vice versa - incomplete transactions that modify data in the table will block the operation of the CREATE INDEX command. Therefore, there is a variant of the command - CREATE INDEX CONCURRENTLY. It works longer (and may even fall with an error), but allows for simultaneous data changes.
This can be seen in practice. For experiments, we will use
the table of “bank” accounts familiar from the
first cycle , in which we will store the account number and amount.
=> CREATE TABLE accounts( acc_no integer PRIMARY KEY, amount numeric ); => INSERT INTO accounts VALUES (1,1000.00), (2,2000.00), (3,3000.00);
In the second session, start the transaction. We need a service process number.
| => SELECT pg_backend_pid();
| pg_backend_pid | ---------------- | 4746 | (1 row)
What locks does the newly started transaction hold? We look in pg_locks:
=> SELECT locktype, relation::REGCLASS, virtualxid AS virtxid, transactionid AS xid, mode, granted FROM pg_locks WHERE pid = 4746;
locktype | relation | virtxid | xid | mode | granted ------------+----------+---------+-----+---------------+--------- virtualxid | | 5/15 | | ExclusiveLock | t (1 row)
As I already said, a transaction always holds an exclusive (ExclusiveLock) lock of its own number, in this case, a virtual one. There are no other locks on this process.
Now update the table row. How will the situation change?
| => UPDATE accounts SET amount = amount + 100 WHERE acc_no = 1;
=> \g
locktype | relation | virtxid | xid | mode | granted ---------------+---------------+---------+--------+------------------+--------- relation | accounts_pkey | | | RowExclusiveLock | t relation | accounts | | | RowExclusiveLock | t virtualxid | | 5/15 | | ExclusiveLock | t transactionid | | | 529404 | ExclusiveLock | t (4 rows)
Now there are locks on the mutable table and index (created for the primary key), which is used by the UPDATE command. Both locks are taken in RowExclusiveLock mode. In addition, an exclusive lock on the real transaction number was added (which appeared as soon as the transaction began to change data).
Now in another session we’ll try to create an index on a table.
|| => SELECT pg_backend_pid();
|| pg_backend_pid || ---------------- || 4782 || (1 row)
|| => CREATE INDEX ON accounts(acc_no);
The command freezes in anticipation of the release of the resource. What kind of lock is she trying to capture? Check:
=> SELECT locktype, relation::REGCLASS, virtualxid AS virtxid, transactionid AS xid, mode, granted FROM pg_locks WHERE pid = 4782;
locktype | relation | virtxid | xid | mode | granted ------------+----------+---------+-----+---------------+--------- virtualxid | | 6/15 | | ExclusiveLock | t relation | accounts | | | ShareLock | f (2 rows)
We see that the transaction is trying to get the table lock in ShareLock mode, but cannot (granted = f).
It is convenient to find the number of the blocking process, and in general several numbers, using the function that appeared in version 9.6 (before that, I had to draw conclusions by carefully looking at all the contents of pg_locks):
=> SELECT pg_blocking_pids(4782);
pg_blocking_pids ------------------ {4746} (1 row)
And then, to understand the situation, you can get information about the sessions, which include the numbers found:
=> SELECT * FROM pg_stat_activity WHERE pid = ANY(pg_blocking_pids(4782)) \gx
-[ RECORD 1 ]----+------------------------------------------------------------ datid | 16386 datname | test pid | 4746 usesysid | 16384 usename | student application_name | psql client_addr | client_hostname | client_port | -1 backend_start | 2019-08-07 15:02:53.811842+03 xact_start | 2019-08-07 15:02:54.090672+03 query_start | 2019-08-07 15:02:54.10621+03 state_change | 2019-08-07 15:02:54.106965+03 wait_event_type | Client wait_event | ClientRead state | idle in transaction backend_xid | 529404 backend_xmin | query | UPDATE accounts SET amount = amount + 100 WHERE acc_no = 1; backend_type | client backend
After the transaction is completed, the locks are released and the index is created.
| => COMMIT;
| COMMIT
|| CREATE INDEX
In queue!..
In order to better imagine what the appearance of an incompatible lock leads to, we will see what happens if the VACUUM FULL command is executed during system operation.
Let the SELECT command be executed first on our table. She gets a lock on the weakest level of Access Share. To control the lock release time, we execute this command inside the transaction - until the transaction ends, the lock will not be released. In reality, several commands can read (and modify) the table, and some of the queries can take quite a while.
=> BEGIN; => SELECT * FROM accounts;
acc_no | amount --------+--------- 2 | 2000.00 3 | 3000.00 1 | 1100.00 (3 rows)
=> SELECT locktype, mode, granted, pid, pg_blocking_pids(pid) AS wait_for FROM pg_locks WHERE relation = 'accounts'::regclass;
locktype | mode | granted | pid | wait_for ----------+-----------------+---------+------+---------- relation | AccessShareLock | t | 4710 | {} (1 row)
The administrator then runs the VACUUM FULL command, which requires an Access Exclusive level lock that is incompatible with anything, even Access Share. (The LOCK TABLE command also requires the same lock.) The transaction queues.
| => BEGIN; | => LOCK TABLE accounts;
=> SELECT locktype, mode, granted, pid, pg_blocking_pids(pid) AS wait_for FROM pg_locks WHERE relation = 'accounts'::regclass;
locktype | mode | granted | pid | wait_for ----------+---------------------+---------+------+---------- relation | AccessShareLock | t | 4710 | {} relation | AccessExclusiveLock | f | 4746 | {4710} (2 rows)
But the application continues to issue queries, and now the SELECT command appears in the system. Purely theoretically, she could have “slipped” while VACUUM FULL is waiting, but no - she honestly takes a place in the queue for VACUUM FULL.
|| => SELECT * FROM accounts;
=> SELECT locktype, mode, granted, pid, pg_blocking_pids(pid) AS wait_for FROM pg_locks WHERE relation = 'accounts'::regclass;
locktype | mode | granted | pid | wait_for ----------+---------------------+---------+------+---------- relation | AccessShareLock | t | 4710 | {} relation | AccessExclusiveLock | f | 4746 | {4710} relation | AccessShareLock | f | 4782 | {4746} (3 rows)
After the first transaction with the SELECT command completes and releases the lock, the VACUUM FULL command begins (which we simulated with the LOCK TABLE command).
=> COMMIT;
COMMIT
| LOCK TABLE
=> SELECT locktype, mode, granted, pid, pg_blocking_pids(pid) AS wait_for FROM pg_locks WHERE relation = 'accounts'::regclass;
locktype | mode | granted | pid | wait_for ----------+---------------------+---------+------+---------- relation | AccessExclusiveLock | t | 4746 | {} relation | AccessShareLock | f | 4782 | {4746} (2 rows)
And only after VACUUM FULL completes its work and removes the lock, all the commands accumulated in the queue (SELECT in our example) will be able to capture the corresponding locks (Access Share) and execute.
| => COMMIT;
| COMMIT
|| acc_no | amount || --------+--------- || 2 | 2000.00 || 3 | 3000.00 || 1 | 1100.00 || (3 rows)
Thus, an inaccurate command can paralyze the operation of the system for a time significantly longer than the execution time of the command itself.
Monitoring tools
Of course, locks are necessary for correct operation, but can lead to undesirable expectations. Such expectations can be monitored in order to understand their cause and possibly eliminate them (for example, by changing the application algorithm).
We already got acquainted with one method: at the moment of a long lock, we can execute a request to the pg_locks view, look at the lockable and blocking transactions (pg_blocking_pids function) and decrypt them using pg_stat_activity.
Another way is to enable the
log_lock_waits parameter. In this case, information will appear in the server’s message log if the transaction has been waiting longer than
deadlock_timeout (despite the fact that the parameter for deadlocks is used, we are talking about normal expectations).
Let's try it.
=> ALTER SYSTEM SET log_lock_waits = on; => SELECT pg_reload_conf();
The default
deadlock_timeout parameter value is one second:
=> SHOW deadlock_timeout;
deadlock_timeout ------------------ 1s (1 row)
Play the lock.
=> BEGIN; => UPDATE accounts SET amount = amount - 100.00 WHERE acc_no = 1;
UPDATE 1
| => BEGIN; | => UPDATE accounts SET amount = amount + 100.00 WHERE acc_no = 1;
The second UPDATE command expects a lock. We will wait a second and complete the first transaction.
=> SELECT pg_sleep(1); => COMMIT;
COMMIT
Now the second transaction can be completed.
| UPDATE 1
| => COMMIT;
| COMMIT
And all the important information got into the journal:
postgres$ tail -n 7 /var/log/postgresql/postgresql-11-main.log
2019-08-07 15:26:30.827 MSK [5898] student@test LOG: process 5898 still waiting for ShareLock on transaction 529427 after 1000.186 ms 2019-08-07 15:26:30.827 MSK [5898] student@test DETAIL: Process holding the lock: 5862. Wait queue: 5898. 2019-08-07 15:26:30.827 MSK [5898] student@test CONTEXT: while updating tuple (0,4) in relation "accounts" 2019-08-07 15:26:30.827 MSK [5898] student@test STATEMENT: UPDATE accounts SET amount = amount + 100.00 WHERE acc_no = 1;
2019-08-07 15:26:30.836 MSK [5898] student@test LOG: process 5898 acquired ShareLock on transaction 529427 after 1009.536 ms 2019-08-07 15:26:30.836 MSK [5898] student@test CONTEXT: while updating tuple (0,4) in relation "accounts" 2019-08-07 15:26:30.836 MSK [5898] student@test STATEMENT: UPDATE accounts SET amount = amount + 100.00 WHERE acc_no = 1;
To be continued .