Hi Habr.
About a year ago, I examined the topic of using GPUs as an example of calculating 4x4 “magic squares”. There, everything is pretty obvious, there are only 7040 of these squares, and you can calculate them on almost anything, even on Arduin (but this is not accurate). In a similar way, I decided to find all 5x5 squares, and the results were very interesting, looking ahead, I’ll say right away, I couldn’t find them.
If anyone is interested, details of the solution to Friday's “uncomplicated task” under the cut.

In order not to repeat myself, for those who poorly remember what the “magic square” is and how to find it, I advise you to read the
first part . In a particular case, a 5x5 square is a field of 25 cells that contains numbers from 1 to 25, so that the sums of each horizontal, vertical and diagonal are equal. An example of such a square is shown in the picture above.
The search for the “magic square” is interesting for programming in that, on the one hand, the task is very simple and understandable even for a student, on the other hand, it is quite non-trivial in terms of the amount of computation, and opens up great scope for various optimizations. This problem can be solved both at 1m, and at 2m and at the 20th year of programming, and each time find something new for yourself. So let's get started.
C / C ++
The first option will be the simplest, without any multithreading. The idea of the code is very trivial - we take the first number from the set 1..25, then the second number from all but the first, and so on. The extreme numbers from the right and bottom columns do not need to be sorted, because they are calculated from the available ones.
In C ++, this can be easily written using std :: set:
const int N=5, S = 65, MAX=N*N; std::set<elem> mset = { 1,2,3,4,5, 6,7,8,9,10, 11,12,13,14,15, 16,17,18,19,20, 21,22,23,24,25 }; for(auto x11 : mset) { std::set<elem> set12(mset); set12.erase(x11); for(auto x12 : set12) { std::set<elem> set13(set12); set13.erase(x12); for(auto x13 : set13) { if (x11 + x12 + x13 >= S-2) continue; std::set<elem> set14(set13); set14.erase(x13); for(auto x14 : set14) { elem x15 = S - x11 - x12 - x13 - x14; if (x15 < 1 || x15 > MAX || x15 == x11 || x15 == x12 || x15 == x13 || x15 == x14) continue; ... } } }
We start, everything works, but somehow slowly. Purely for fun, I write the code “stupidly” in C, without any std, just checking in each cycle that the variable has already been used.
for(elem x11=1; x11<=MAX; x11++) { for(elem x12=1; x12<=MAX; x12++) { if (x12 == x11) continue; for(elem x13=1; x13<=MAX; x13++) { if (x13 == x11 || x13 == x12) continue; if (x11 + x12 + x13 >= S-2) continue; for(elem x14=1; x14<=MAX; x14++) { ... } } }
Of course, I understand that the implementation of sdt :: set is not so simple, but to such an extent ... The difference in execution time is 12.0 and 0.35s - C code works 34 times faster!
Go ahead. Let's try to estimate how much the calculation will take as a whole. To simplify the task, we divide the square into two parts. The upper two rows of the square would have a maximum of 25 * 24 * 23 * 22 * 21 * 20 * 19 * 18 = 43.609.104.000 numbering options, but since we discard some of the options with the wrong amount, there is "only" 8.340.768.000. Now consider the two remaining (3rd and 4th) rows. Simple profiling showed that iterating over lines with checks of the sum takes 1.48 s. Total, multiplying one by the other, we get that the time to check all the "magic squares" 5x5 will be
391 years . This is true without multithreading, but it will not save us here - how many cores are there in the CPU, 16 at best? Even if I speed up the calculation by 16 times, I’m probably still not waiting for the end. It's time to move on to NVIDIA CUDA.
NVIDIA CUDA
The principle of computing on a video card is essentially simple. In CUDA, the hardware of a video card is divided into many blocks, each block can have several threads. The whole bonus is that there are many blocks of these, and they can do the calculations in parallel.
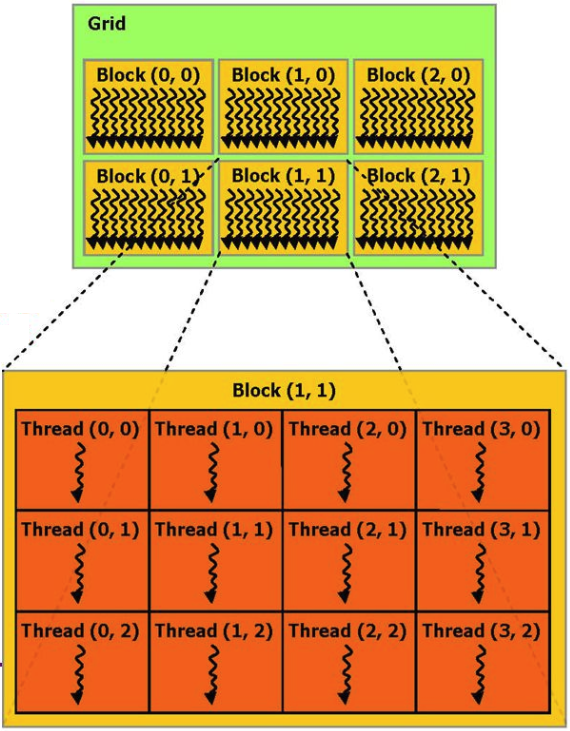
Logically, blocks can be addressed as a 1D, 2D or 3D array, within each block the addressing of flows can also be done as 1D, 2D or 3D. As the experiment showed, CUDA makes it possible to allocate 25x25x25 = 15625 blocks, with 25x25 = 625 processes per block. Maximum limits are specified in the CUDA specification.
Of course, in real life, 15625 * 625 = 9 million processes, the video card will not start in parallel - at least, obviously not the one that is on my PC. But we can hope that the NVIDIA driver will ensure maximum load of the cores, taking all the work on parallelization onto itself.
Thus, the logic of the code is quite simple - we sort out the external loop counting the first 16 numbers of magic squares on the CPU, and “give” the video loop to the graphics card, which (theoretically) should make the calculation noticeably faster. Each thread will do a fairly simple calculation with only three nested loops. It is also important to keep in mind that the video card works with its own memory, so before starting the calculation, you need to put the data there, and at the end of the calculation, take the results back.
I do not provide the code here, so as not to clutter up the text, a link to the source at the end of the article.
results
The results, of course, depend on the video card. The code was tested on 2 PCs - a laptop with a GeForce GTX 950M and a desktop with a GeForce GTX 1060.
GTX 950MThe internal cycle, which in the CPU version was executed in 1.48 s, with the help of the GPU was completed in ... 0.5 s. Alas, the increase was only 3 times. Apparently, 625 threads per core are still a heavy load for a laptop video card, and the overhead exceeds the benefits of parallelization. It is interesting that attempts to change the number of threads and blocks in different proportions did not improve the result - if you take out part of the code in the CPU, the GPU calculations are faster, but the rest is slower. In general, the NVIDIA driver seems to really do its job of parallelizing tasks quite well.
The result of the program is shown in the screenshot.

As you can see, the first “magic square” was found in 680s, and most likely I won’t wait for the final calculation results, unless of course medicine takes some real step forward;)
GTX 1060MEverything is noticeably more cheerful here:
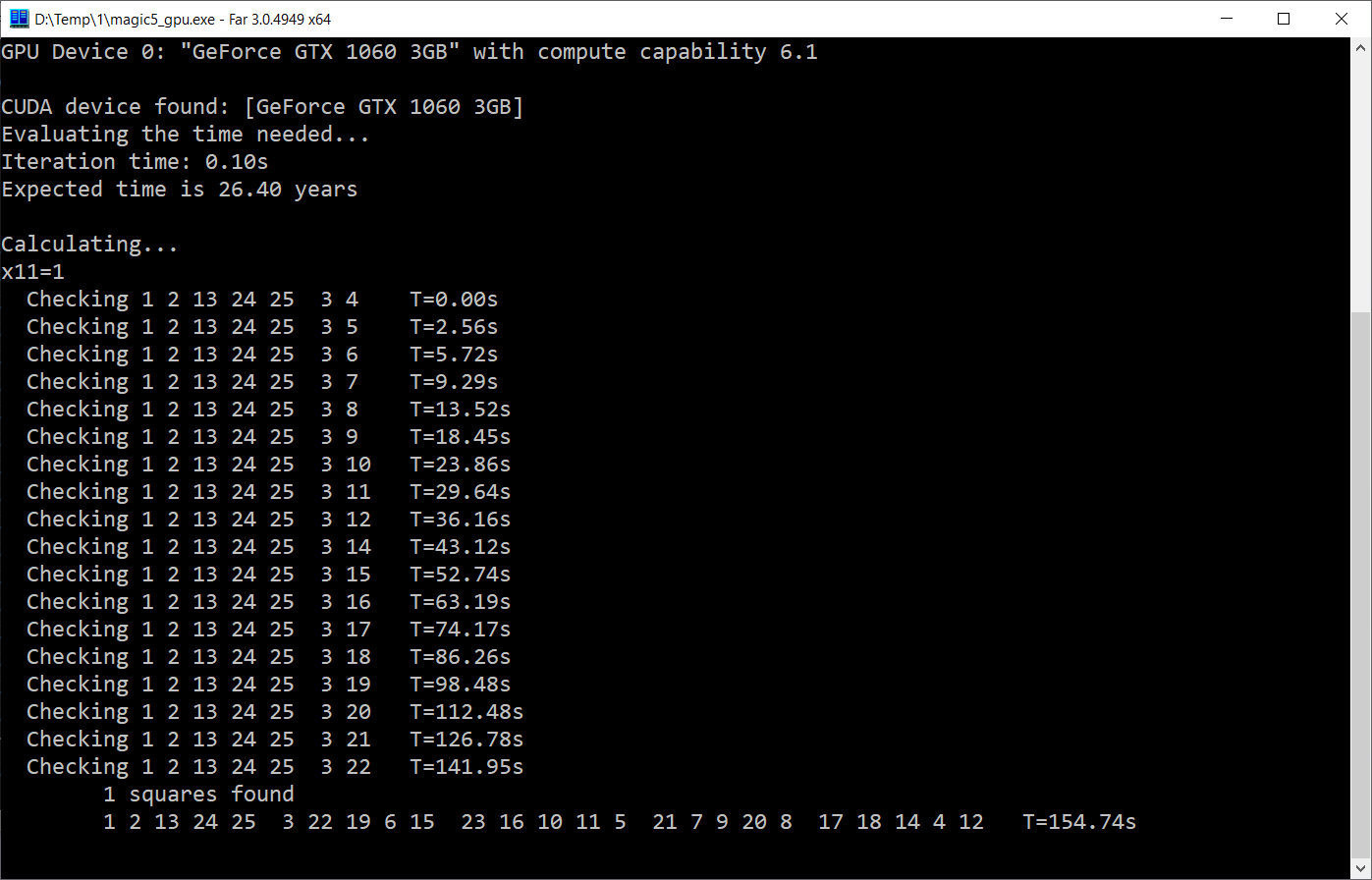
As you can see, the GPU version takes 0.1s to complete, which is 15 times faster. And I will probably live to see the end of the calculation. Of course, this is also very slow - there are clearly more than 15 physical blocks in the video card, and theoretically one could count on growth at least once every 100. But either I don’t know how to cook this, or this type of task doesn’t really fit into the logic of work CUDA.
In principle, the results could not have been laid out, because by and large, there is nothing to brag about, even to the simple children's question “how many magic squares are 5x5 in total” there is no answer yet. But on the other hand, I still decided to lay it all out for several reasons.
- It is interesting and makes you break your head and try something new. There are not so many problems that can be solved that take 100 years.
- The result is a rather interesting and cross-platform benchmark that allows you to compare the speed of calculations on different PCs.
- These results will be interesting from a historical point of view - it will be interesting in 10 years to run the same code on some Core i17 with a GeForce 10600 and compare the results. By the way, if anyone can run the code on an old PC made about 10 years ago, it would also be interesting.
- Finally, maybe someone will point out a bottleneck in the code or what I did wrong. Learning is never too late.
Conclusion
As you can see, even such a simple “school” problem with seemingly simple arithmetic can be difficult to calculate.
As suggested in the comments, changing the order of enumeration of numbers, you can save 2 nested cycles and speed up the calculation. On the latest version, the total computational time in multi-threaded mode on Core i7 was reduced to 76 days, and with CUDA, to 17 days.
The updated CPU version with source can be found here:
Windows version .
The next optimization strategy may be the rejection of a complete brute force enumeration to a more intellectual one, for example, so as not to count the turns and reflections of already found magic squares.
The question of the optimal use of CUDA for this type of calculation remains open.