CleverDATA is developing a platform for working with big data. In particular, on our platform it is possible to work with information from online shopping checks. Our task was to learn how to process the text data of checks and build on them conclusions about consumers to create the corresponding characteristics on the data exchange. It was natural to address machine learning to solve this problem. In this article we want to talk about the problems that we encountered in the classification of texts of online checks.
A sourceOur company develops solutions for data monetization. One of our products is the 1DMC data exchange, which allows you to enrich data from external sources (more than 9000 sources, its daily audience is about 100 million profiles). The tasks that 1DMC helps to solve are well known to marketers: building look-alike segments, broad-based media companies, targeting advertising campaigns for a highly specialized audience, etc. If your behavior is close to the behavior of the target audience of a store, then you are likely to fall into the look-alike segment. If information about your addiction to any area of interest has been recorded, then you can get into a highly specialized targeted advertising campaign. At the same time, all laws on personal data are implemented, you receive advertising more relevant to your interests, and companies effectively use their budget to attract customers.
Information about profiles is stored on the exchange in the form of various attributes interpreted by a person:
This may be information that a person owns motor equipment, for example, a motorcycle chopper. Or that a person has an interest in food of a certain type, for example, he is a vegetarian.
Statement of the problem and ways to solve it
Recently, 1DMC received data from one of the fiscal data operators. In order to present them in the form of exchange profile attributes, it became necessary to work with check texts in raw form. Here is a typical check text for one of the customers:
Thus, the task is to match the check with the attributes. Attracting machine learning to solve the described problem, first of all, there is a desire to try
teaching methods
without a teacher (Unsupervised Learning). The teacher is information about the correct answers, and since we do not have this information, teaching methods without a teacher could well fit the case being solved. A typical method of teaching without a teacher is clustering, thanks to which the training sample is divided into stable groups or clusters. In our case, after clustering the texts according to the words, we will have to compare the resulting clusters with the attributes. The number of unique attributes is quite large, so it was desirable to avoid manual markup. Another approach to teaching without a teacher for texts is called topic modeling, which allows you to identify the main topics in unplaced texts. After using thematic modeling, it will be necessary to compare the obtained topics with attributes, which I also wanted to avoid. In addition, it is possible to use semantic similarity between the text of the check and the text description of the attribute based on any language model. However, the experiments showed that the quality of models based on semantic proximity is not suitable for our tasks. From a business point of view, you need to be sure that a person is fond of jujitsu and that is why he buys sports goods. It is more profitable not to use intermediate, controversial and doubtful conclusions. Thus, unfortunately, unsupervised learning methods are not suitable for the task.
If we refuse unsupervised learning methods, then it is logical to turn to supervised learning methods and, in particular, to classification. The teacher is information about the true classes, and a typical approach is to carry out a multiclass classification, but in this case the task is complicated by the fact that too many classes are obtained (by the number of unique attributes). There is another feature: attributes can work on the same texts in several groups, i.e. classification should be multilabel. For example, information that a person has bought a case for a smartphone may contain attributes such as: a person who owns a device like Samsung with a Galaxy phone, buys the attributes of a Deppa Sky Case, and generally buys accessories for phones. That is, several attributes of a given person should be recorded in the profile at once.
To translate the task into the category "training with a teacher" you need to get markup. When people encounter such a problem, they hire assessors and, in exchange for money and time, get good markup and build predictive models from the markup. Then it often turns out that the markup was wrong, and assessors need to be connected to work regularly, because new attributes and new data providers appear. An alternative way is to use Yandex. Toloki ". It allows you to reduce the cost of assessors, but does not guarantee quality.
There is always an option to find a new approach, and it was decided to go this way. If there were a set of texts for one attribute, then it would be possible to build a binary classification model. Texts for each attribute can be obtained from search queries, and for the search you can use the text description of the attribute, which is in the taxonomy. At this stage, we encounter the following feature: the output texts are not so diverse as to build a strong model from them, and it makes sense to resort to text augmentation to get a variety of texts.
Text Augmentation
For text augmentation, it is logical to use the language model. The result of the work of the language model is embeddings - this is a mapping from the space of words into the space of vectors of a specific fixed length, and the vectors corresponding to words that are similar in meaning will be located next to each other in the new space, and far away in meaning. For the text augmentation task, this property is the key, because in this case it is necessary to look for synonyms. For a random set of words in the name of a taxonomy attribute, we sample a random subset of similar elements from the text representation space.
Let's look at augmentation with an example. A person has an interest in the mystical genre of cinema. We sample the sample, it turns out a diverse set of texts that can be sent to the crawler and collect search results. This will be a positive sample for classifier training.
And we select the negative sample more easily, we sample the same number of attributes that are not related to the movie theme:
Model training
When using the TF-IDF (for example,
here ) approach with a filter by frequencies and logistic regression, you can already get excellent results: initially very different texts were sent to the crawler, and the model copes well. Of course, it is necessary to verify the operation of the model on real data, below we present the result of the model’s operation according to the attribute “interest in buying AEG equipment”.
Each line contains the words AEG, the model managed without false positives. However, if we take a more complicated case, for example, a GAZ car, we will encounter a problem: the model focuses on keywords and does not use context.
Error handling
We will build on a model of interest in additional education - professional retraining courses.
The course of magic lessons for an ordinary cat is also a difficult case, which can be misleading to a person.
To filter out false positives, we use embeddings: we calculate the center of the positive sample in the embedding space and measure the distance to it for each line.
The difference in distance for the courses of magic lessons and the acquisition of abstracts is visible to the naked eye.
Another example: Audi brand owners. The distance in the space of embeddings in this case also saves from false positives.
Scalability issue
To date, the data exchange operates about 30 thousand attributes, and new ones appear regularly. The need for automation of training new models and marking up with new attributes is quite obvious. The sequence of steps for constructing a model of a new attribute is as follows:
- take the attribute name from the taxonomy;
- create a list of queries to the search engine using text augmentation;
- kraulim text selection;
- we train the classification model on the obtained sample;
- let's say a trained model raw purchase data;
- we filter the result by word2vec the distance to the center of the positive class.
There are a number of weak points in the algorithm described above:
- it is difficult to control the corpus of texts that is crouching;
- quality control of the training sample is difficult;
- there is no way to determine whether a well-trained model is doing its job.
It is important to understand that classical metrics are not suitable for quality control of a trained model, because missing information on true classes in check texts. Learning and prediction take place on different data, the quality of the model can be measured on a training sample, and there is no markup on the body of the main texts, which means that you cannot use the usual methods to evaluate quality.
Model quality assessment
To assess the quality of the trained model, we take two populations: one refers to objects below the threshold of the model’s response, the second refers to objects on which the model evaluated above the threshold.
For each of the populations, we calculate the word2vec distance to the center of the positive training sample. We get two distance distributions that look like this.
Red color indicates the distribution of distances for objects that have crossed the threshold, and blue indicates objects below the threshold according to the model's assessment. Distributions can be divided, and to estimate the distance between distributions, it is logical to turn first to the Kullback-Leibler divergence (DKL). A DCL is an asymmetric functional; the triangle inequality is not satisfied on it. This restriction complicates the use of DCL as a metric, but it can be used if it reflects the necessary dependence. In our case, DCL assumed constant values on all models regardless of threshold values, so it became necessary to look for other methods.
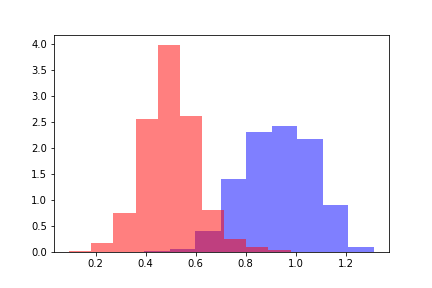
To estimate the distances between distributions, we calculate the difference between the average values of the distributions. The resulting difference is measurable in the standard deviations of the initial distribution of distances. Denote the obtained value by the Z-metric by analogy with the Z-value, and the value of the Z-metric will be a function of the threshold value of the predictive model. For each fixed threshold of the model, the Z-metric function returns the difference between the distributions in sigma of the initial distance distribution.
Of the many approaches tested, it was the Z-metric that gave the necessary dependence to determine the quality of the constructed model.
Consider the behavior of the Z-metric: the larger the Z-metric, the better the model coped, because the greater the distance between the distributions characterizes the qualitative classification. However, a clearly defined decision rule for determining the qualitative classification could not be derived. For example, a model with a Z-metric in the lower left corner of the figure receives a constant value of 10. This model determines the interest in traveling to Thailand. The training sample was predominantly advertised by various spas, and the model was trained on texts that were not directly related to trips to Thailand. That is, the model worked well, but it does not reflect interest in trips to Thailand.
Z-metic for a number of predictive models. The models in the right half of the picture are good, and the five models in the left half are bad.During searches and experiments, 160 models with markup according to the “good / bad” criterion have accumulated. Based on the signs of the z-metric, a meta-model based on gradient boosting was constructed that determines the quality of the constructed model. Thus, it was possible to configure the quality monitoring of models built in automatic mode.
Summary
At the moment, the sequence of actions is as follows:
- take the attribute name from the taxonomy;
- create a list of queries to the search engine using text augmentation;
- kraulim text selection;
- we train the classification model on the obtained sample;
- let's say a trained model raw purchase data;
- we filter the result by word2vec the distance to the center of the positive class;
- we calculate the Z-metric and build signs for the meta-model;
- we use a meta-model and evaluate the quality of the resulting model;
- if the model is of acceptable quality, then it is added to the set of models used. Otherwise, the model returns for revision.
According to the assessment of the meta-model in automatic mode, a decision is made to introduce it into production or to return for revision. Refinement is possible in various ways that have been derived for the analyst.
- Often models get in the way of certain words that have several meanings. The black list of deceptive words facilitates the model.
- Another approach is to create a rule to exclude objects from the training set. This approach helps if the first method does not work.
- For complex texts and multi-valued attributes, a specific dictionary is transferred to the model, which limits the model, but allows you to control errors.
But what about neural networks?
First of all, there was a desire to use neural networks for the described task. For example, one could train Transformer on a large body of texts, and then make Learning Transfer on a set of small training samples from each attribute. Unfortunately, the use of such a neural network had to be abandoned for the following reasons.
- If the model for one attribute ceases to work correctly, then it is necessary to be able to disable it without loss for the remaining attributes.
- If the model does not work well for one attribute, then it is necessary to tune and tune the model in isolation, without risk of spoiling the result for other attributes.
- When a new attribute appears, you need to get a model for it as soon as possible without long-term training of all models (or one large model).
- Solving the quality control problem for one attribute is faster and easier than solving the quality control problem for all attributes at once. If a large model does not cope with one of the attributes, you will have to tune and fine-tune the entire large model, which requires more time and specialist attention.
Thus, an ensemble of independent small models for solving the problem turned out to be more practical than a large and complex model. In addition, the language model and embeddings are still used for quality control and text augmentation, so it was not possible to completely avoid the use of neural networks, and there was no such purpose. The use of neural networks is limited to the tasks in which they are required.
To be continued
Work on the project continues: it is necessary to organize monitoring, updating models, working with anomalies, etc. One of the priority areas for further development is the task of collecting and analyzing those cases that have not been classified by any model from the ensemble. Nevertheless, already now we see the results of our work: about 60% of checks after applying the models get their attributes. Obviously, there is a significant proportion of checks that do not carry information about the interests of the owners, so a wholly-owned level is unattainable. Nevertheless, I am glad that the result so far obtained already exceeds our expectations and we continue to work in this direction.
This article was co-written with
samy1010 .