The idea of the article was born spontaneously from a discussion in the comments on the article
“Something about inode” .
The fact is that the internal specifics of our services is the storage of a huge number of small files. At the moment, we have about hundreds of terabytes of such data. And we came across some obvious and not very rake and successfully walked on them.
Therefore, I share our experience, maybe someone will come in handy.
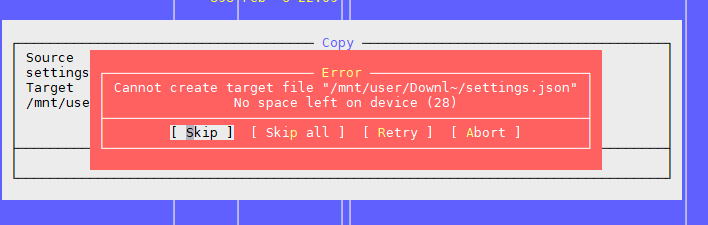
Problem One: “No space left on device”
As mentioned in the above article, the problem is that there are free blocks on the file system, but the inode is over.
You can check the number of used and free inodes with the
df -ih :
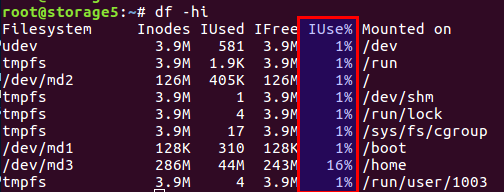
I will not retell the article, in short, there are both blocks directly for data and blocks for meta-information on the disk, they are also inodes (index node). Their number is set during file system initialization (we are talking about ext2 and its descendants) and does not change further. The balance of data blocks and inodes is calculated from the average statistical data, in our case, when there are a lot of small files, the balance should shift towards the number of inodes - there should be more of them.
Linux has already provided options with different balances, and all these pre-calculated configurations are in the
/etc/mke2fs.conf file.
Therefore, during the initial initialization of the file system through mke2fs, you can specify the desired profile.
Here are some examples from the file:
small = { blocksize = 1024 inode_size = 128 inode_ratio = 4096 } big = { inode_ratio = 32768 } largefile = { inode_ratio = 1048576 blocksize = -1 }
You can select the desired use case with the -T option when calling mke2fs. You can also manually set the necessary parameters if there is no ready-made solution.
More details are described in manuals for
mke2fs.conf and
mke2fs .
A feature not mentioned in the above article is that you can set the size of the data block. Obviously, for large files, it makes sense to have a larger block size, for small files - in a smaller one.
However, it is worth considering such an interesting feature as the processor architecture.
I once thought that I needed a larger block size for large photo files. It was at home, on the home file name WD on the ARM architecture. Without hesitation, I set the block size to either 8k or 16k instead of the standard 4k, having previously measured the savings. And everything was wonderful exactly up to the moment when the storage itself did not fail, while the disk was alive. Having put the disk into a regular computer with a regular Intel processor, I got a surprise: unsupported block size. Sailed. There is data, everything is fine, but impossible to read. Processors i386 and the like do not know how to work with block sizes that do not match the size of the memory page, but it is exactly 4k. In general, the case ended with the use of utilities from user space, everything was slow and sad, but the data was saved. Who cares - google the name of the utility
fuseext2 . Moral: either think through all the cases in advance, or not build yourself a superhero and use the standard settings for housewives.
UPD. As
noted by user
berez, I clarify that for i386 the block size should not exceed 4k, but it does not have to be exactly 4k, i.e. valid 1k and 2k.
So, how we solved the problems.
Firstly, we encountered a problem when a multi-terabyte disk was full of data, and we could not redo the file system configuration.
Secondly, a solution was needed urgently.
As a result, we came to the conclusion that we need to change the balance by reducing the number of files.
To reduce the number of files, it was decided to put the files in one common archive. Given our specifics, we put all the files in one archive for a certain period of time, and archived cron task daily at night.
Selected a zip archive. In the comments to the previous article, tar was proposed, but there is one complication with it: it does not have a table of contents, and the files in it are thread-safe (for a reason, “tar” is an abbreviation for “Tape Archive”, a legacy of tape drives), i.e. . if you need to read the file at the end of the archive, you need to read the entire archive, since there are no offsets for each file relative to the beginning of the archive. And so this is a long operation. In zip, everything is much better: it has the same table of contents and file offsets inside the archive, and the access time to each file does not depend on its location. Well, in our case, it was possible to set the compression option to “0”, because all the files had already been compressed in gzip beforehand.
Clients take files through nginx, and according to the old API, just the file name is specified, for example like this:
http://www.server.com/hydra/20170416/0453/3bd24ae7-1df4-4d76-9d28-5b7fcb7fd8e5
To unpack files on the fly, we found and connected the nginx-unzip-module module (
https://github.com/youzee/nginx-unzip-module ) and set up two upstream.
The result is this configuration:

Two hosts in the settings looked like this:
server { listen *:8081; location / { root /home/filestorage; } }
server { listen *:8082; location ~ ^/hydra/(\d+)/(\d+)/(.*)$ { root /home/filestorage; file_in_unzip_archivefile "/home/filestorage/hydra/$1/$2.zip"; file_in_unzip_extract "$2/$3"; file_in_unzip; } }
And the upstream configuration on the upstream nginx:
upstream storage { server server.com:8081; server server.com:8082; }
How does it work:
- Client goes to front nginx
- Front nginx tries to give the file from the first upstream, i.e. directly from the file system
- If there is no file, it tries to give it from the second upstream, which tries to find the file inside the archive
The second problem: again, "No space left on device"
This is the second problem we encountered when there are a lot of files in the directory.
We are trying to create a file, the system swears that there is no space. Change the file name and try to create it again.
It turns out.
It looks something like this:

Checking inodes gave nothing - there are a lot of them free.
Checking the place is the same.
We thought that there might be too many files in the directory, but there is a restriction on this, but again not: Maximum number of files per directory: ~ 1.3 × 10 ^ 20
Yes, and you can create a file if you change the name.
The conclusion is a problem in the file name.
Further searches showed that the problem is in the hashing algorithm when building the directory index, with a large number of files there are collisions with all the ensuing consequences. More details can be found here:
https://ext4.wiki.kernel.org/index.php/Ext4_Disk_Layout#Hash_Tree_DirectoriesYou can disable this option, but ... searching for a file by name can become unpredictably long when sorting through all the files.
tune2fs -O "^dir_index" /dev/sdb3
In general, how a workaround might work.
Moral: many files in a directory are usually bad. This is not necessary.
Usually in such cases they create subdirectories, by the first letters of the file name or by some other parameters, for example, by dates, in most cases this saves.
But the total number of small files is still bad, even if they are divided into directories - then see the first problem.
The third problem: how to see the list of files if there are a lot of them
In our situation, when we have a lot of files, one way or another we were faced with the problem of how to view the contents of the directory.
The standard solution is the
ls .
Ok, let's see what happens on the 4772098 files:
$ time ls /home/app/express.repository/offercache/ >/dev/null real 0m30.203s user 0m28.327s sys 0m1.876s
30 seconds ... it will be too much. And most of the time it takes to process files in user space, and not at all to the kernel.
But there is a solution:
$ time find /home/app/express.repository/offercache/ >/dev/null real 0m3.714s user 0m1.998s sys 0m1.717s
3 seconds 10 times faster.
Hooray!
UPD.An even faster solution from the
berez user is to disable sorting on
ls time ls -U /home/app/express.repository/offercache/ >/dev/null real 0m2.985s user 0m1.377s sys 0m1.608s
The fourth problem: large LA when working with files
Periodically, a situation arises when you need to copy a bunch of files from one machine to another. At the same time, LA often grows unrealistically, because everything depends on the performance of the disks themselves.
The most reasonable thing you want is to use an SSD. Really cool. The only question is the cost of multi-terabyte SSDs.
But if the disks are ordinary, you need to copy the files, and this is also a production system, where overload leads to dissatisfied exclamations from customers? There are at least two useful tools:
nice and
ionice .
nice - reduces the priority of the process, respectively, the sheduler distributes more time slices to other, more priority processes.
In our practice, it helped to set nice to maximum (19 is the minimum priority, -20 (minus 20) is the maximum).
ionice - accordingly adjusts the priority of input / output (I / O scheduling)
If you use RAID and need to suddenly synchronize (after an unsuccessful reboot or need to restore the RAID array after replacing the disk), then in some situations it makes sense to reduce the synchronization speed so that other processes can work more or less adequately. To do this, the following command will help:
echo 1000 > /proc/sys/dev/raid/speed_limit_max
The fifth problem: How to synchronize files in real-time
We have all the same huge amounts of files that need to be backed up to a second server to avoid ... Files are constantly being written, therefore, in order to have a minimum of losses, you need to copy them as quickly as possible.
Standard Solution: Rsync over SSH.
This is a good option, unless you need to do it once every few seconds. And there are a lot of files. Even if you do not copy them, you need to somehow still understand what has changed, and to compare several million files is the time and load on the disks.
Those. we need to immediately know what to copy, without starting the comparison every time.
Salvation -
lsyncd .
Lsyncd -
Live Syncing (Mirror) Daemon . It also works through rsync, but it additionally monitors the file system for changes using inotify and fsevents and starts copying only for those files that have appeared or changed.
The sixth problem: how to understand who loads the disks
Everyone probably knows this, but nevertheless for the
iotop completeness: to monitor the disk subsystem there is the
iotop command - like
top , but it shows the processes that use disks most actively.

By the way, the good old top also allows you to understand that there are problems with the disks or not. There are two most suitable parameters for this:
Load Average and
IOwait .
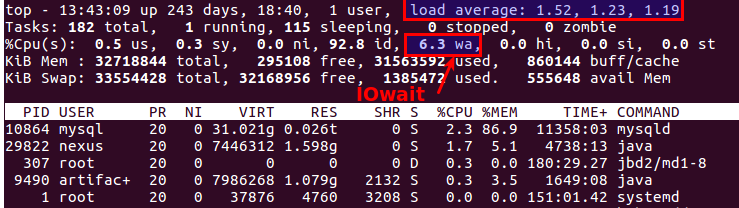
The first shows how many processes are in the service queue, usually more than 2 - something is already going wrong. With active copying to backup servers, we allow up to 6-8, after which the situation is considered abnormal.
The second is how much the processor is busy with disk operations. IOwait> 10% is a cause for concern, although on servers with a specific load profile it is stable 40-50%, and this is really the norm.
I’ll end there, although there are probably many points that we did not have to face, I will be happy to wait for comments and descriptions of interesting real cases.