In the code of various projects, one often has to operate on time - for example, to tie the application’s logic to the user’s current time. Victor Khomyakov, Victor
-homyakov, senior interface
designer, described the typical errors he encountered in projects in Java, C # and JavaScript from various authors. They faced the same tasks: get the current date and time, measure the intervals or execute the code asynchronously.
- Before Yandex, I worked at other food companies. It’s not like a freelancer - I wrote, passed and forgot. It takes a very long time to work with one code base. And I actually watched, read, wrote a lot of code in different languages and saw a lot of interesting things. As a result, I was born the theme of this story.
For example, I saw that in different projects in different languages the same or very similar tasks arise - working with date, time. In addition to such work itself, it can be pop-up operations in the code with date and time objects.

It turns out that regardless of whether you are the front-end or back-end, you have similar tasks for working with asynchronous code. If you are on the backend, these are queries to the database, remote calls. If the front-end - you naturally have AJAX. Different people in different projects solve these problems almost the same way, this is the essence of man. With a similar task, you make a similar decision, regardless of the language in which you think. And it is logical that at the same time you - we, I - make very similar mistakes.
What do I want to talk about in the end? About these repeating patterns that occur regardless of the language you write in, errors that are easy to make, and how not to make them.
The first part is devoted, in fact, to time. As you know, time moves. Example: you need to write a report for yesterday, for the full past day. You make a request to the database, you need to get all the records whose date is greater than or equal to yesterday and less than today. That is, you start from the date “today minus one day” and to today's date, not including it.

So linearly, in general, you write code. Start date - today minus one day, end date - today. It would seem that everything works, but then exactly at midnight you have a strange thing. Your start date is here. Start date minus one day - it turns out this. After that, for some reason, the end date of the report is completely different.

You, or rather your boss, get a report for two days instead of one. The technical manager and manager come, complain and politely offer you to switch to another team in six months.

But then you are enriched with new knowledge. You understand that time does not stand still. That is, calling Date.now () twice or getting new Date (), you are not hoping to get the same value. It may sometimes be the same, but it may not be the same. Accordingly, if you have one method, any one piece of logic, then most likely there should be only one call to Date.now () or getting new Date (), the current point in time.
Or let’s go on the other hand: in the data processing stream, all values related by meaning - the beginning and end of the report - must be calculated strictly from one object. Not from two of some similar ones, for example, but from exactly one. You are enriched with this new knowledge, move to a new team. There, people are more concerned about the speed and performance of the code.

And they suggest that you overlay the code with logging, measure how long it takes for you to perform some operation. If this is a difficult operation, it is important that it does not slow down on the client. If you write something on the backend, on Node, it’s also a difficult transaction, then they ask you: “Please write to the log how long it takes, and then we will calculate how our customers behave depending on the user agent.”
Then two already new bosses come to you and show you an entry in the log, where you suddenly log negative times. And they also politely offer you to switch to another team in six months.

You gain valuable knowledge that, in fact, the methods of obtaining the date, time that you use - they just show what you have in your operating system's clock. Nor do they guarantee even uniform change. That is, for your second of real time, your Date.now () can both jump for a second, and a little more - a little less. And in principle, they generally do not guarantee the monotony of change. That is, as in this example, it may suddenly decrease, the value of Date.now () may suddenly decrease.
What is the reason? In time synchronization. On Linux-like systems, there is such a thing as NTP daemon, which synchronizes the clock of your operating system with the exact clock on the Internet. And if you have any lag or lead, it can either artificially slow down or speed up your watch, or if you have a very large time gap, he will understand that he will not be able to catch the right time with inconspicuous steps, and just with one jump changes it. As a result, you get a gap in the readings of your watch.
Or you can greatly complicate it: the user himself, who has control over the clock, he may also want to just change the clock. He really wanted to. And we have no right to stop him. And in the logs we get breaks. And, accordingly, a solution to this problem also already exists. It's simple: there are time providers. If you are in a browser, then this is performance.now (), if you are writing in Node, then there is a High Resolution Timer, which, both of them, have these properties of uniformity and monotony. That is, these suppliers of time stamps, they always only increase, and at the same time evenly in one second of real time.
The backend has the same problem. It doesn't matter what language you write. For example, you can search for a monotonous consistent watch, and the issue gives you, in which almost all languages are represented. There is the same problem in Rust. There is also the pain of a programmer who is in Python, and in Java, and in other languages. In these languages, people have also stepped on a rake, this problem is known, there is a solution. For example, for Java there is a call that has the same properties of uniformity and monotony.
If you have a distributed system, fashionable microservices, for example, then it’s still more complicated. There are N different services on N different machines, the clock on which, in general, can never even converge to one indication in principle, there is nothing even to hope for.
And if you have a problem logging actions, then you can log just a time vector. You, it turns out, logs N times from N systems involved in processing one request. Or you just go to the abstract counter, which simply increases: 1, 2, 3, 4, 5, just on this machine it ticks evenly with each operation. And you write such counters in order to link all these stages of processing your any requests on different machines, and get some understanding about when, what happens, in what sequence.
Also, do not forget: if you are front-end or back-end, which work with the front-end in close connection, then our front-end plus back-end is also a distributed system. And if you are also interested in some kind of difficult session of the client’s work, then, please, try not to confuse, first of all, when you look in the logs, what time do you see: “here is the record that this operation occurred at so many times "- do you see server time or client time?" And secondly, try to collect both times, because, as I said, times can go in different directions.
Enough of the time. The second part is more erratic.
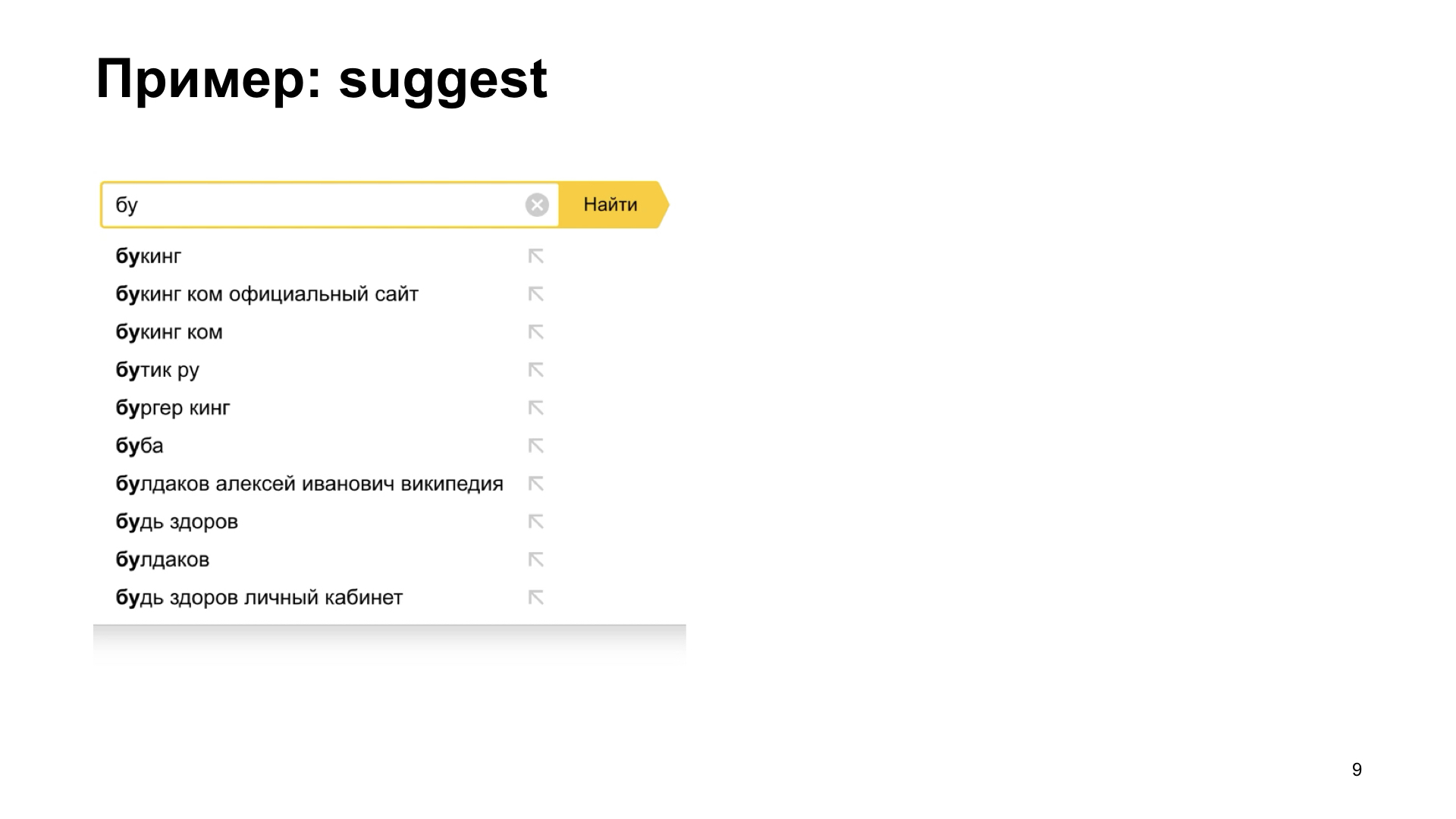
Here is an example. There is such a very useful interface element when the user does not know exactly what he wants. This is called suggest, or autocomplete. We can tell him options to continue the request. That is, for the user this is a very big benefit. It is much more convenient for him to work when we immediately show him that we know what we can recruit further.
But, unfortunately, if we get a slightly slow network, or if the backend, which gives answers, options for continuation, slows down, then we can get such interesting effects. The user types, types, then the correct answer comes, we see it, and then everything breaks. For some reason, we are not seeing at all what we wanted to see. Here we see the correct answer, and immediately some nonsense to some kind of intermediate state. Again, sheer pain and suffering. Our bosses come to us and ask us to fix this bug.

We begin to understand. What do we get? When the user types his text, we get the generation of sequential asynchronous requests. That is, what he managed to type, we send to the backend. He dials further, we send a second request for the backend, and no one has ever guaranteed us that our callbacks will be called in exactly the same sequence.
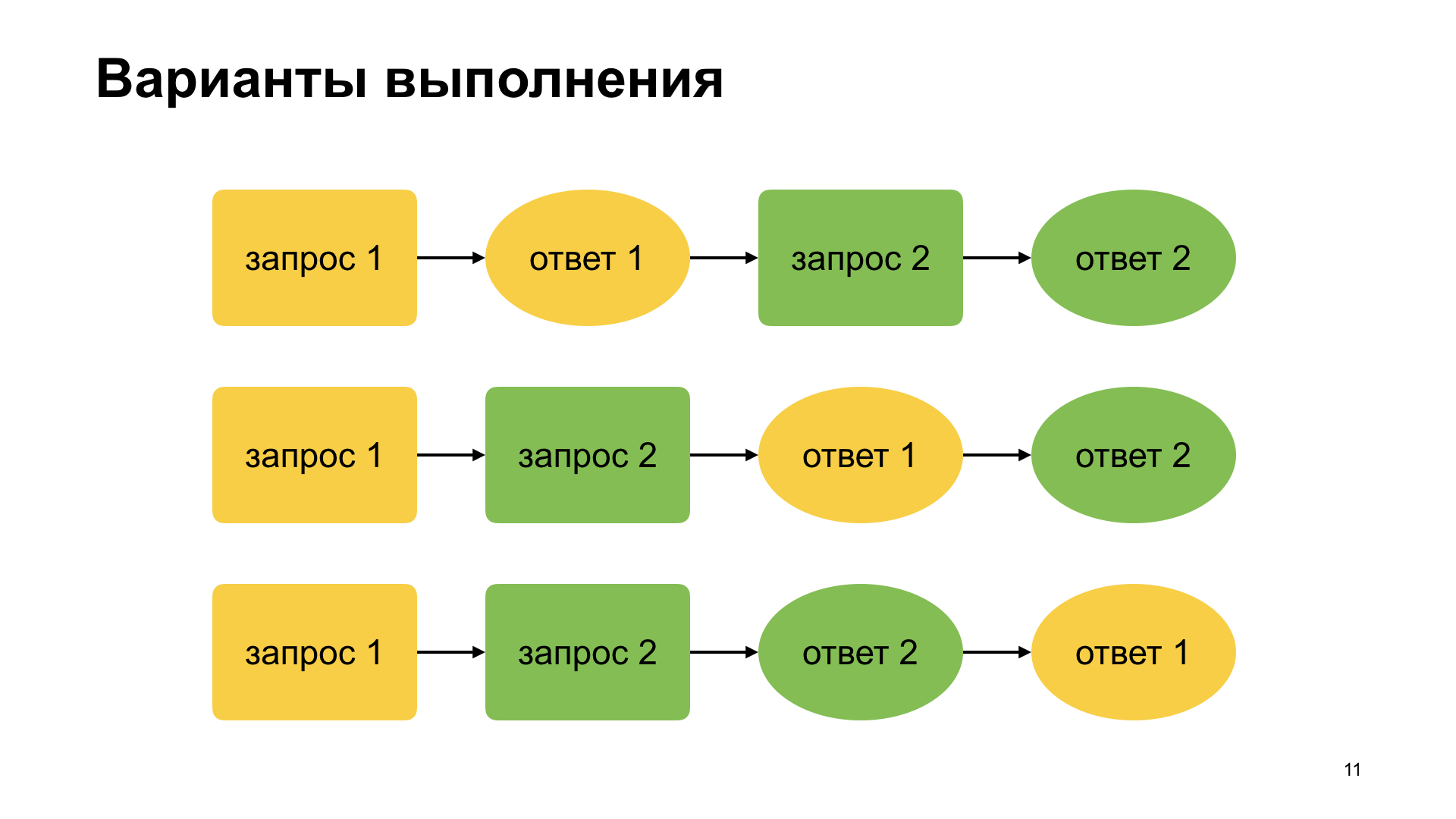
These are the possible query and callback options. The most obvious thing when we write, we think: they sent the first request, received the first response, sent the second request, received the answer. If the user types very quickly, then we can think up the second option that we managed to send the first request, the user managed to type something before receiving the first answer. Then came the first answer, the second answer. And here is what we saw in the video, when suggest didn’t work correctly, this is the third option, which is often forgotten, that no one guarantees the order of answers, in general.

And in front-end vendors this problem is very common if you are developing interfaces. In particular, the example with suggest, with autocomplete, which we just saw. That is, there is a stream of requests, and there is a stream of responses asynchronously arriving.
If you have tabs. Raise your hands, who on GitHub did at least one pull request ever? You remember that there, in fact, the tabbed interface is based, that is, there is a tab where there is a sequence of comments, there is a tab with commits, and there is a tab with the code itself. This is such a tabbed interface. And if you switch to a neighboring tab, then its contents are loaded asynchronously for the first time.
If you quickly click on different tabs, it may happen that you switch them on, and then you see the loading of the content blinking. And in the end, it’s not a fact that you will see the contents of the correct tab, if you are correct, of course, do not write your own.
For example, if you have a store, if you quickly drag goods to the basket. Some quick, sharp user dragged ten goods, and then he sees how his price is blinking and, relatively speaking, 100 rubles, 10 rubles, 50 rubles, 75 rubles, and stops at one ruble. He does not believe you, he thinks that you write poorly, you want to deceive him, and leaves your store without buying anything.
Example. If you have any kind of scrum or kanban or anything else and you use electronic boards to drag and drop cards, you probably missed the cards at least once when you dragged them, dropped it into the wrong column. Has this happened? Of course, you catch yourself and immediately grab it sharply and drag it to where it should be. In this case, you very quickly generate two queries. And in different systems there are bugs that arise just after that. You dragged it into the correct column - the answer comes to the first request, and the card again jumps to the column where you transferred it. It turns out very ugly.

What is the moral? Suppose you have a source of the same type of request. Then, if possible, if the next request arrives, interrupt all incomplete requests so as not to waste resources, so that the backend knows - you do not need it anymore.
Thus, when processing responses, you also control everything. And if a response arrives at an earlier request that you do not need, you also explicitly ignore it.

Accordingly, the problem has existed for a long time, and the solution also already exists. For example, in the RxJS library. This is directly an example from the documentation, right Hello world, how to write the correct autocomplete. There right out of the box there is such a disregard for answers to older incorrect requests.

If you write on Redux and Redux-Saga, there it is, too, in general, and everything is also written in the documentation. But there it is deeply buried, and it is clearly not said that it is such a bug and we fix it like that. Just a description is.
Since we have moved on to React, we’ll move closer to it.

This is a piece of real code that we had in our repository. Someone draws cards with us. And please, when you get a map, it is very advisable to show a mark on it where the user is located. But this is all happening in the browser. That is, if you have geolocation enabled, then we can get your coordinates, and we can directly indicate where you are on the map.
If geolocation is not allowed, or some kind of error has occurred there, then it is advisable for us to show some kind of dice with an error. That is, here we show a die that we could not show where you are, dude, and after three seconds we remove it, this die. You managed to read, probably. Moreover, a moving object, like a retractable die and disappearing, it immediately attracts attention, and you will immediately notice it, read it.
But if you carefully look at what happens in this code, then we change the state of our component after three seconds in time. Anything can happen in these three seconds. Including the user can close this card for a long time, and your component will be unmounted, clean its state.

Accordingly, you shoot yourself in the leg, and shoot on a ballistic trajectory, which will end in three seconds. And what should be done? Do not forget that if you do such pending operations, you can clean them correctly with unmount. And in other frameworks with other life cycle methods, the same is logical. When you have some kind of destruct, destroy, something else, unmount, you must correctly remember to clean such things.

Where in the browser can your code be so deferred from? There are things like throttle and debounce. They have setTimeout, setInterval under the hood, something that I already showed about. There is still requestAnimationFrame, there is still requestIdleCallback. And AJAX requests too - AJAX request callbacks can be called deferred. Do not forget about them, too, they also need to be cleaned.
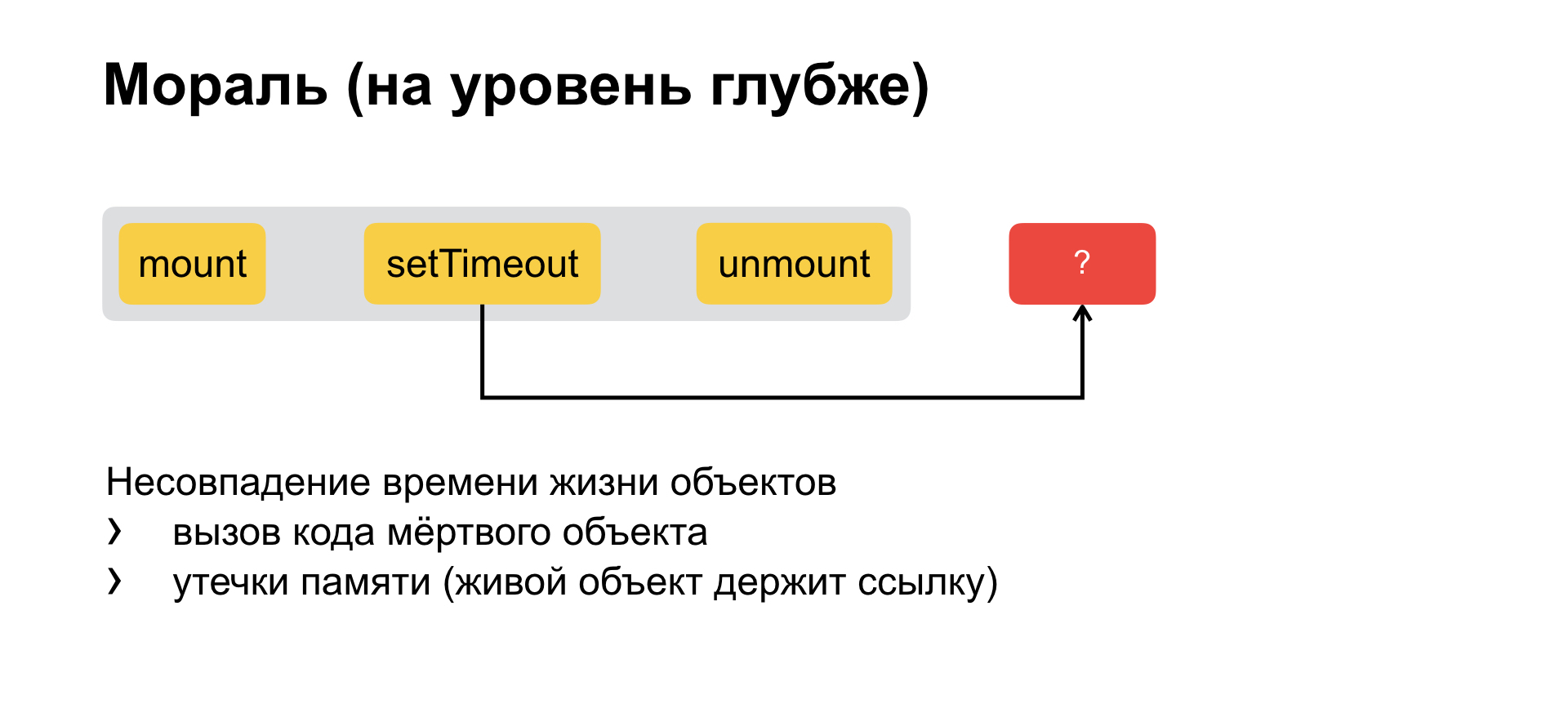
And if we dive even one level further, we will understand that initially the whole problem is abstracted to such that we have some kind of component with some kind of life cycle and we put off the call. We create inside a long-living object, which has a longer life than the original one. That is, there are two objects with a mismatching life cycle, with a mismatching life span. And from this two bugs immediately flow.
The first is what we have now: a long-lived object holds a link to your function and calls it, although you have already died. And the second is the leak of concomitant memory. That is, again, a long-lived object holds a link to your code and does not allow it to be cleaned, collected from memory.
The third part is the opposite of the second. She, on the contrary, about synchronization.

There is, as usual, a chain of promise - then, then, then something there. And in this code, if you look, if you write cleanly, if you are a supporter, or have heard at least about the functional approach, about clean functions, about the absence of side effects, then you can understand that something can be done in this code speed up.
Because these two requests are asynchronous, they are clearly independent of each other. If you are not sure about this, it means that you are writing something wrong, that is, there you obviously have some kind of side-effects, a global state, and so on. If you write well, then it immediately becomes apparent to you. Here, by the way, is a clear profit from the purity of the function, from the lack of side effects. Because right here, when reading this code, you understand that they can be parallelized. They are independent of each other. And, in general, they can be exchanged even in places, most likely.

This is done like this. We run two queries in parallel, wait for them to finish, and then execute the following code. That is, what is the profit? In the fact that, firstly, our code runs faster, we do not wait for one request to start the second. And we will fall faster. If we have an error in the second request, then we will not waste time waiting for the first request to be executed in order to immediately fall on the second.

For completeness, what else do we have in the Promise API? Here is Promise.all (), which runs all requests in parallel, and waits for execution. There is Promise.race (), which is waiting for the first of them to succeed. And, in general, there is nothing else in the standard API.

We already understand that if there is a problem, then someone has already solved it for us. There is an Async library that has a pretty rich selection for managing asynchronous tasks. There are methods for running asynchronous tasks in parallel. There are methods to run sequentially one after another. There are methods for organizing asynchronous iterators. That is, you know that you have, say, an array on which you can run forEach (). But if you need to call an asynchronous function in forEach (), then you either have a problem right away and you refuse forEach () and write something yourself, or use a ready-made library that is ready to use the same asynchronous things. You understand, call map () with some sort of iterator asynchronous, call forEach () - there it is already in the box.

Another alternative is the bluebird library. There is, as they call it, the correct Promise.any (). , , : N , N - , , . , , . .
Promise.race(), , promise , , , . . Promise.any() — reject. . reject , resolve , , . . promise — , .
, map, reduce, each, filter . API , Async JS, . promise . , , , promise. .
promise? , async/await.

. . . ,
«» . , webdriver. , , - , . . . webdriver.
, await. . , - . await, — , , ! .

— Promise.all(). , await.

: await , then . , .
, . : await, , — , .
, , :
, -, :
? , — Lodash, RxJS . . , . , - . . — , , . .