Functionality switch is a tool that allows you to switch from the old functionality to the new one without rebuilding the application and releasing it again. It is implemented by adding a conditional operator (
if ) to the code, which makes it possible to control the behavior of the program by simply changing the desired value in the configuration file or database. If you have ever edited the settings in an ini-file, then this technology is familiar to you.
Digging deeper, you can find a huge number of different options for the switches and the new features that they provide. This raises many questions. Where to place the configuration? But what if it becomes unavailable? Perhaps you can write a simple framework for working with switches yourself? Maybe it's better to take a ready-made solution? Does this suit both monolith and microservices?
This material contains basic information about functionality switches in the context of development on the .NET platform. The first part contains general information about the switches; they are quite independent of the specific implementation and may be useful for professionals working with a variety of platforms. The second part discusses specific modern tools that facilitate the use of switches when developing for .NET.
I tried to write an article that will help you decide whether to implement functionality switches in your specific case, and if necessary, how. In our department, switches are so far used only for solving particular problems. For example, our application often needs to request legal and accounting information from a catalog, which can be presented in two forms: a remote full catalog and its local partial copy. In the application settings, users can choose which type of directory the application should work with at the moment. The plans include the introduction of switches as a common infrastructure for the whole project. Based on it, processes similar to those described above will be built.
Functionality Switch Overview
What is it
In simple terms, the meaning of the switches is as follows. The contractor advances in our code, representing the logic of the subject area, and stumbles upon a conditional operator. In this statement, the contractor asks if some conditional code needs to be executed from a registry that knows when and under what circumstances the functionality of interest should work.
As a result, the executor goes either along one branch or along another, and in a degenerate case the other branch is simply empty. In the simplest case, the switch takes one of two values (“on” and “off”) under the control of the responsible person who maintains the register. And you can come up with something more complicated, for example, include functionality only for specific users or for users from certain countries, or at a certain time.
The functionality registry may take a variety of forms. The point is when you can manage this registry without stopping the application or redeploying it. For example, switches can be stored in a file, in a database, or have a separate network service with switches. Below the operation of the switches is considered in more detail.
Is this even relevant?
In its
article, the creator of
featureflag.tech claims that switches become standard practice in software development. There are more and more materials about switches: theoretical articles, stories about the practice of implementing switches, reports at conferences. I have included links to the most interesting materials in the text of this article; All links are collected in the section
"Conclusion" .
I would say that the growth of the popularity of switches is facilitated by stabilization and standardization in some areas of information technology. In the "bloody enterprise" appears more and more islands of stability. The increase in the number of metrics in development, the automation of assembly, inspection and delivery of applications lead to the fact that development processes become more transparent and manageable. As a result, requirements for a new level begin to be presented to the creation of software. One of these requirements is the desire to spread in time the moments of publication of the application and the inclusion of new functionality, which is implemented by the switches. Industry capabilities have already matured to meet this industrial demand.
As for the tools that help to work with switches, there are very, very many of them, and for a variety of platforms. The appearance of a large number of tools is probably due to the simplicity with which the basic capabilities of the switches can be implemented. But the addition of more complex and “tasty” buns may require significant labor costs, so many open source projects that implement function switches stop developing and being supported. Nevertheless, a significant number of projects, both paid and free, remain afloat. The most interesting of them (from the point of view of .NET) are described in the
second part of the article .
A bit more
This article has a good diagram illustrating the operation of the switches; I suggest to get acquainted with it.
We begin our consideration of the circuit with code. Let in our example, new functionality - checking the correctness of filling out the document. We make sure that the document is checked only if this functionality is enabled. Let's make a switching point:
var document = GetDocument(); if (feature.IsEnabled("Feature #123. Document validation")) { Validate(document); }
In this case,
feature is a reference to the infrastructure that helps our application communicate with the router and the functionality registry. With the help of this infrastructure, we find out whether it is necessary to check the document, and if so, then check it.
The router uses the information available to it: the name of the functionality that we passed as an argument, and what we can extract from the static classes that it knows to determine if the requested functionality should work in this case. The router finds out how the switches in the registry are configured. If the registry is unavailable, you must either use the previously cached data, or resort to some other strategy for this case. You can also imagine a router that explicitly receives additional information (the context) through the arguments of the method that helps it decide whether to enable functionality at the moment.
Responsible personnel configure the switches in the selected way. In the most pleasant option, they go to the site that represents the registry of switches, and click on the selected switches with the mouse.
So, in terms of artifacts, the switch system consists of two parts. On the one hand, this is an infrastructure for a programmer to find out whether functionality should work in this case and direct execution along the appropriate code branch. On the other hand, it is a mechanism that allows a responsible employee to choose which functionality to enable and which to turn off. In degenerate cases (when the registry is sewn into the code, see below), both artifacts can coincide, and the programmer can control the on and off functionality.
Possible switch system requirements
As you can see, the switch system can be quite a complicated thing. We list the basic requirements that may be imposed on such a system.
- The dependence of the on and off functionality of different parameters. Examples of parameters: user (role, identifier, geographical location), time (daylight or dark, working days or weekdays, specific time periods), environment (for development, testing, industrial operation).
- Collection of usage statistics when analyzing domain processes: which user saw or did not see functionality under what conditions, how many times they used the new functionality.
- An audit of what is happening with the switches themselves: who presses them, when, what changes.
- Providing a flexible choice between local and remote registry functionality or some strategies in case the remote registry is unavailable.
- Configuring access to the switch system for different categories of employees both at the customer and the contractor: technical specialists, specialists in the subject area, as well as application users themselves.
Of course, striving to satisfy all these requirements is not necessary. In many cases, some requirements, on the contrary, may be undesirable. The more requirements you need to comply with, the obviously more burdensome is the development of your own switch system. This means that at some point after the introduction of the switches, support for your own system becomes unprofitable and it is time to take a ready-made solution.
Technological tree
We summarize the considered information about the switches of functionality, resorting to the metaphor of the
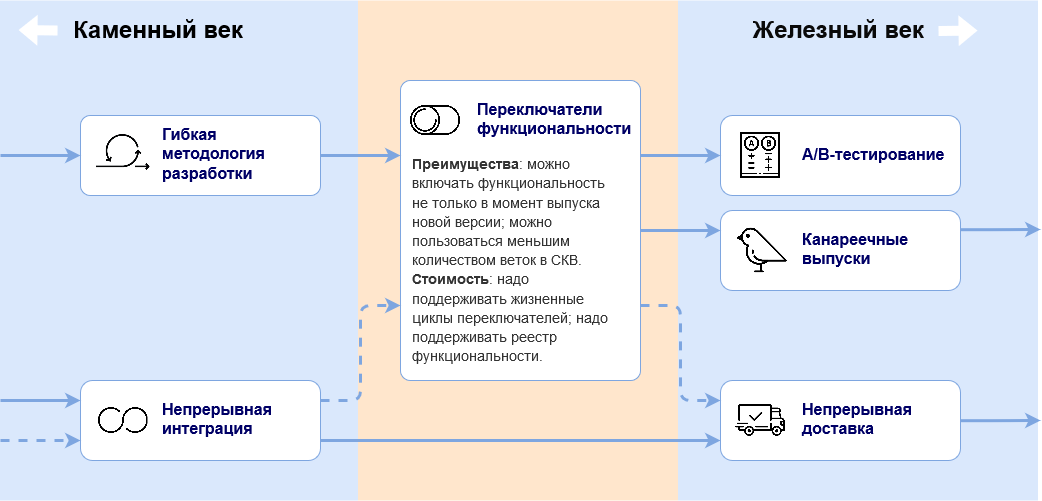
technological tree from video games. Let's imagine the switches as a technology that allows the company to roll out new functionality without being tied to the moments of the assembly and deployment of the application. This technology has a known cost (the cost of maintaining the life cycles of the switches and the registry) and the prerequisites for implementation: a flexible development methodology plus continuous integration. Of course, continuous integration is not a prerequisite, but it makes the switches much more efficient and allows for continuous delivery of the application. In addition, the “research” of the switches “opens” other technologies - A / B testing and canary releases. They will be discussed below.
Where the functionality registry may be located
Consider several options for placing the registry of functionality, arranging them in increasing complexity of implementation.
- Sew the configuration directly into the code, for example, comment out the unnecessary code and uncomment the necessary code or use the conditional compilation directives. Obviously, this option kills the essence of the introduction of switches, because with it you will need to re-compile and deploy the application to see the new functionality. Two difficulties should also be noted. Firstly, with this approach, an employee who includes functionality will require additional technical skills: editing the source code and the ability to work with the version control system (SLE). God knows what skills, of course, but most likely, the programmers themselves will have to include functionality. Secondly, the functionality will be the same on all nodes where this version of the application was published - to choose between the old and new functionality, you will need a balancer and several nodes with the application.
- Place the configuration in the application environment, for example, in environment variables. This option seems a little extravagant, because it is fraught with the appearance of excessive dependencies on the runtime or on the operating system.
- Use configuration files, which are a fairly standard place to store application settings. The disadvantage of this option will be the need to maintain configuration files separately next to each instance of the application. This drawback is inherent in the previous version.
- Maintain a table in the database that describes the switches for functionality. Application instances will knock on this database to see if the functionality that interests them works. In this option, the registry is centralized (unlike the previous version), but leaves it possible to include functionality separately for each node, if this is supported by the selected switch infrastructure.
- Raise the network service to which the application instances will access via the selected network protocol. If in the previous version it was meant that the switches will most likely be stored together with the entities of the subject area, and therefore the cost of polling the switches will be predictable, then here we will have additional access over the network. The cost of additional handling and the possibility of denial of service are serious drawbacks of this option, but, of course, caching is not prohibited. And for failures, you must provide default behavior.
Recommendations
Regarding the use of switches, the following general recommendations can be made.
The switching point and logic do not have to be together . In the simplest example, after the conditional statement, in which we interrogate the state of a specific switch, the code immediately implements the included functionality. This is not entirely convenient, because it adds redundant dependencies to the logic: knowledge about the infrastructure of switches and the name of specific functionality from the registry. In practice, this complicates the testing and removal process of the switch when it becomes unnecessary.
Set the switching point higher . Development of the previous paragraph. The points at which the switch infrastructure is accessed should be excluded from the logic of the subject area to the last possible opportunity, that is, they should be "pushed" closer to the place where the request was received. Thus, we reduce the dependence of individual modules on switches, simplify the processes of their support and testing.
Use strategies instead of conditional statements . If the switch is going to live for a long time, then the conditional operator can be improved to a strategy and explicitly isolate the switchable logic into something separately followed and tested.
Do not group switches . It is not necessary to form dependencies between the switches, group them and assemble them in hierarchies. This makes it easier to maintain code with new functionality and the life cycle of the switches themselves.
Consolidate switch points for one functionality . It may turn out that the behavior of several program blocks at once depends on the same switch. If the development is poorly coordinated, switching points can be duplicated in different places, and this leads to more expensive testing and support. If you are disciplined to try to “push” the switching points to the entrance to the application, then this recommendation - do not scatter points throughout the system - is usually performed automatically.
The main categories of switches
Consider the switch classification given in
this article . It is based on how long the switch “lives” and how often its state changes. The assignment of a switch to a specific class helps determine how to use the switch in the code and how to store the state of the switch.
Release SwitchesThis is the main view of the switches. They allow you to concentrate development in one main branch, which, moreover, regularly rolls out into commercial operation. Instead of developing in a separate branch and injecting it into the main branch to release the desired version, we introduce a switching point in the code, which hides the functionality that is not yet ready from users. When ready, the switches launch new functionality.
Such switches live for several days or weeks - while the development and implementation of new functionality is ongoing. When the functionality has been tested and considered suitable, the switch and the switching point in the code can be removed. The state of the switch usually changes either when a new version is released, or when the application configuration changes. It is permissible to store such a switch in the configuration file. There is a high probability that the switching point for the new functionality will be the only one; it makes sense not to dig in and place it in the form of a conventional conditional statement.
Experiment SwitchesTo run the new functionality, switches are used that live from several days to several months. During the experiment, you can monitor how users perceive the changes and how their behavior changes. It is desirable that the state of the switch can change very dynamically with each request. Some centralized storage, such as a database or network service, is more likely to be suitable here.
If the experiment fits into a foreseeable number of issues, then the switching point can also be issued in the form of a conditional statement.Technical switchesTechnical switches help manage the infrastructure parts of an application that affect its overall performance. They can come in handy when we roll out an update whose performance impact is difficult to evaluate. In this case, it would be nice to have a “switch” that instantly disables new functionality if it turns out that its use leads to disastrous consequences.Most likely, such switches will live for several weeks or longer, and will change state when the application configuration changes or more often. The criticality of the function that these switches implement suggests that they need to use a network service or at least a database. You need to start to make sure that in the code the switching points for the same functionality are not scattered in different places.Switches for access controlAnother obvious opportunity to use switches is to provide access to new functionality only to some users. This may be needed both for the canary release (when the new functionality gradually covers more and more users), and for creating private sections where only privileged users have access.It seems that such switches live quite a long time (perhaps as long as the application itself) and can change state with each new request. A network service for storing switches is also suitable here. It is recommended to use some kind of centralized mechanism for choosing between old and new functionality and not scatter conditional statements throughout the code.,
The introduction of functionality switches not only has obvious advantages, for which everything is usually started (diversity in time of publishing the application and switching on new functionality, reducing the number of branches in hard currency), but it can also simplify some side processes. We list them and then consider some in more detail.A / B testing. Comparison of the behavior of users using the new and old versions.Canary issues. Gradual increase in the number of users with access to new functionality.Blue-green releases. Send requests using the balancer to either the server with the old version or the server with the new version.Planned extreme functionality.The inclusion of functionality for a short period of time, for example during the promotion.Simultaneous inclusion of functionality in several places. The inclusion of functionality at the same time both on the site and in the mobile application. Or the inclusion of functionality simultaneously in different modules of the same application.Major infrastructure changes. For example, switching to another way of storing data.Testing new things by users. Providing users with the ability to turn on and off new functionality, customizing the application for themselves.A / B testingLet's briefly consider what A / B testing is. When preparing A / B testing, some measurable property of the information system or user behavior is formulated. Examples of this property: 1) the duration of a specific process in the subject area, 2) the relative number of users who have come to a particular page, 3) the number of resources that the application uses. In addition, an assumption is made how the value of this property changes when new functionality is included. Will users get a faster response? Will they buy more? Will the app eat less?Then, during A / B testing, for one group, the new functionality is turned on, and for the other, it remains off. The assumptions made during the preparation are checked, and on the basis of the results it is concluded whether the new functionality gives something good and does not lead to something bad. Sometimes users are divided into three groups, in two of which the functionality remains old. If the results of the two control groups are very different, then the whole test contains some kind of error, making conclusions based on this test unreliable.Functionality switches make it easy to divide users into groups and manage them. For each group, you can enable and disable new functionality without waiting for the next release of the application. This reduces the time it takes to verify assumptions and complete the entire A / B test cycle. Many companies seek to establish verification of several assumptions per week.You can learn more about this method from this article , here and here on the Habré, and it is definitely worth a look at the report “Feature Toggles, or How to roll features without release” , which reveals some interesting subtleties of A / B testing with functionality switches.Canary and blue-green issuesWhat does the canary have to do with it? Canaries were used in the mining industry: miners took canaries in a cage with them when they descended into a mine, where a high concentration of explosive gases was suspected. Canaries are very fond of clean air and much earlier than people begin to feel harmful and dangerous impurities in it. If the canary stops singing, turns off, or dies, then people need to urgently evacuate until it explodes. Here here you can read more about this (in English).Hence, as I understand it, the expression "testimony of the canary" came from. If you live in a state pursuing a repressive domestic policy (that is, in any), you may one day find that you have been instructed not only to transfer the personal data of your users to authorized departments, but also not to tell anyone that you they were handed over, not that you received such an order. Of course, you won’t be able to get out, but in some cases you can regularly send messages of this kind to your users: “Last month we did not receive orders to disclose your personal data.” That's how you chirp, chirp like a canary, and when you receive an order to provide personal data, you shut up. Thus, you fulfill the demand of the authorities, and give your users reason to be wary.And there are canary issues. Here the metaphor works like this: when a small part of users becomes ill, we urgently “evacuate” - we turn off new functionality that caused users to become ill and do not let it reach all users (do not let it “jerk”). To do this, you must be able to extend the new functionality to different groups. Here you can do without switches. For example, we have a balancer and two nodes where it redirects requests. On one node we have a stable version deployed, and on the second - an experimental version containing new functionality. By default, all requests are sent to the node with the stable version, and with the help of the balancer we start sending some requests to the node with the experimental version.But with the switch, you can achieve more flexibility in how new functionality extends to users. In the switch, you can combine different parameters of the received requests and provide responsible employees with a convenient graphical interface for managing the canary issue. In general, the process remains the same: we include new functionality for a small group of users, for example, for 1%. After that, we monitor the state of the application, how users working with the new functionality behave, and make a forecast about what will happen when we extend it to a larger number of users. Gradually embracing more and more users with new functionality, we can test and adjust our hypotheses. If we notice negative trends,then the new functionality can be easily disabled.During the blue-green release, two servers are used, tentatively called blue and green. We assume that before the release, the balancer sends all requests to the green server. During release, a new version of the application is deployed on a blue server, where the balancer also starts sending requests. If it turns out that the new version of the application contains errors, then we switch back to the green server.The basic version of the blue-green release assumes that users either work with all the new functionality included in the new version, or do not work with any. And with the use of switches, it becomes possible during the release to send requests to the blue server with the new version, for which the switches of all new functionality are turned off. After that, you can gradually incorporate the new functionality in parts.You can see that the functionality switches allow you to combine the benefits of canary and blue-green releases. Usually, during a blue-green release, there are two clearly separated nodes with the old and new versions of the application, and with the help of the balancer we redirect all requests at once to either one node or the other. And with the switches, we can redirect requests to the node with the new version, but with the new functionality turned off, and then gradually turn it on, as during the canary release.A little more details about the canary issues are in the corresponding note on the Fowler website or on “Habré”, for example here . About blue-green releases - in a review article. And the use of function switches in blue-green releases can be found here .Changing the way data is storedFor a long time, when studying such programming techniques as abstraction and development from interfaces, I often came across the following recommendation: try not to make your program tied to a specific method of data storage, for example, to a specific database, because in the future You may need to change the storage method. I wound it on my mustache and did as ordered. Since then, however, the reasons why I share the domain logic and the storage method have changed, and I, on the contrary, have become skeptical about the possibility of changing the database in a commercial product.And while preparing this material, I learned about the guys who assurethat many companies practice changing databases in industrially operated products. In addition, supposedly changing the database can be completely painless if you use the functionality switches. It is clear that the mentioned article was written by people interested (the site is supported by the manufacturer of a commercial tool for managing switches), but it will not hurt to consider the strategy of switching to another database that they have proposed.Briefly describe the strategy as follows. The process starts from the moment when our application works with one (old) database. Using the functionality switches, we sequentially force our application to first write data to a new database, and then to read data from the new database. At the same time, interaction with the old database is preserved: we both write and read from both databases!If the record is more or less clear, then reading should be clarified. When an application needs data, it reads them from both databases. These two reading points are always next to each other so that after reading you can compare the received data and check their consistency. After stabilization of the application (when both databases begin to stably return the same data), the application is disconnected from the old database, and the switches are deleted.A detailed description of the strategy for moving to a new database using MongoDB and DynamoDB as an example.MongoDB DynamoDB. DynamoDB: ( ) MongoDB. — , , , — . (DynamoDB).
, MongoDB, — DynamoDB. , DynamoDB ( MongoDB). , DynamoDB .

DynamoDB , MongoDB. - MongoDB. , . , («» «»), . - DynamoDB . , , . — .
MongoDB, DynamoDB. , , , , , , . - , , MongoDB, , . , , , . , .
, . , , DynamoDB. MongoDB, .
That's all. , , , DynamoDB , MongoDB , DynamoDB 100 %. , .
Simultaneous inclusion of functionality on different platformsThe already mentioned report “Feature Toggles, or How to roll out features without release” talked about the requirement to enable new functionality at the same time (minute per minute!) Both on the site and in the mobile application. And then you may also need to turn it off in the same way.Fulfilling such a requirement is not easy because delivering new versions for different platforms is very difficult to synchronize. If the servers with the site are under your control, then you can still guess something (and hope that this time the delivery will work like a clock), then the mobile application store can change the policy for updating updates as it pleases. In any case, updating the application is a long process, which includes checking the published application by the store itself. In addition, you should not hope that the mobile application itself will regularly request updates from its API and install them “inside” itself. This shop, as I understand it, is also under the careful supervision of the platform owner - there will certainly be problems with the execution of arbitrary code.But the switches help to fulfill the requirement of simultaneous inclusion of functionality in an environment where you can not completely control the delivery of the application. Obviously, delivery should still be guaranteed to happen until the expected inclusion. This method will probably come in handy during periods of temporary promotions, such as Black Friday.A similar situation exists with several modules of one system. If they are published separately and at the same time participate in supporting one process of the subject area, then the switches allow you to make coordinated changes to this process on the side of various modules.Switch Tools in .NET
Tools for working with switches can be divided into three groups. Firstly, these are universal heavy products (combines), which usually include a network service that works with a provider, and a set of libraries that allow you to communicate with this service for different programming languages. Almost always, you have to pay (and a lot) for using such products. Secondly, these are projects that are network services that must be run on their computers and which clients can access via the REST API. Of the projects in this group (for brevity, we will call them servers), only those that have a well-documented API or official client for .NET were included in the review. Thirdly, these are simple (relative to the two previous groups) libraries for .NET.They suggest storing the functionality registry in configuration files or accessing a remote registry that is not part of these projects over the network.An attentive reader will notice that there is another group of software tools that did not fall into the review. These are products that can be used as a configuration repository for a distributed system. Well- known representatives of such products include Apache ZooKeeper , Consul and etcd , and in the comments to this article they also mention Spring Cloud Config Server, which can be easily made friends with .NET. Indeed, in their basic capabilities, switches are very similar to configuration repositories, so these tools can be used as a starting point for creating your own switch infrastructure. Nevertheless, due to the fact that the purpose of the functionality switches has certain specifics, with the development of the culture of switches within the project, the disadvantages of universal configuration repositories will begin to be felt. For this reason, similar products are not further discussed.Harvesters
LaunchDarklyIt seems that this is the most hyped and “furious” product in the field of functionality switches. One gets the feeling that in this product fit almost everything that can only come to mind when talking about switches. This applies to the capabilities of the platform itself, and the variety of available clients, and types of integration with various tools such as Jira and Visual Studio Code. Everything is documented in great detail and with examples. The tool, of course, is paid, but during the trial 30-day period it can be used for free.Catamorphic Co., the manufacturer of this product, is also sponsoring a dedicated feature switch reference site .Microsoft.FeatureManagementMicrosoft development for .NET Core, which can be used in two main ways: firstly, as a client library, which allows working with switches and storing their state in a configuration file, and secondly, as a combine, including in addition to this library a centralized location to manage switches in Azure. The tool seems to be based on the more general Azure App Configuration infrastructure, for which there is a documented API .The client library offers interesting possibilities for integration with ASP.NET Core, for example, additional filters on the actions of controllers and conditional visualization of a view, depending on the state of the switches.In the comments to this article, they suggest that you familiarize yourself with the useful series of notes.Microsoft.FeatureManagement.RolloutThe site looks nice, but when you try to get specific information, problems begin. For example, it is indicated that the product has many interesting features for auditing switches, monitoring the use of functionality, and conducting experiments. But at the same time, manufacturers do not disclose pricing policies (it’s only clear that there is a 14-day free trial) and keep quite raw documentation of their REST API. The documentation for client libraries, however, is in order. The system supports storing switches in configuration files.OptimizelyIn general, Optimizely is some kind of cool platform for collecting analytics and conducting experiments. The system has a free Rollouts part .providing basic switch capabilities. It is written that, in addition to supporting targeting (“rolling out” functionality to certain user groups), this free part supports an infinite number of switches and projects. In addition, as many employees as you like can use this system. It is worth noting that the cost of many other products is determined precisely by these quantitative characteristics. How much it will cost to switch to a fully functional platform is a secret.Bullet trainThis platform looks pretty simple. It does not have any special features like analytics collection - only the main features of the switches. When placing the platform on your own servers, you can use it for free.SplitAnother platform that is shy of its prices. Of the additional "chips" offers integration with a few other development tools and support for conducting experiments (A / B testing).ConfigCatAnd here is a product with a fun site where there are cats. It looks provocatively. However, it is suspicious that the documentation for the REST API is not posted on it. With the client under .NET everything is all right. By the way, there is a free plan.MogglesAn open source project that includes a server with a site for managing switches and a client. To start the server, SQL Server is required. Looks pretty mature.Servers
UnleashA fairly mature open source project that involves hosting the system on company servers. Includes a simple switch management site. There are built-in simple tools to account for the use of functionality. Installation is quite simple; PostgreSQL required.There is no official .NET client library, but several third-party ones have already been created. In addition, thanks to the documented API, in theory, you can create your own library.Gitlab feature flagsGitLab built its switch system on top of Unleash, so the same client libraries are used to interact with GitLab as for Unleash. It differs from Unleash itself in that you need to dig less with the installation (except for the installation of GitLab itself), but you have to pay: the functionality switches are available starting from GitLab Premium plans (if GitLab runs on your own servers) and GitLab Silver (if GitLab runs on the servers of the provider).Feature flags API in GoThis open source project is a service with an API (a little documented) through which you can manage switches. Apparently, there is no graphical interface. Written in Go; uses built-in databases and a network server, so the configuration, judging by the instructions, is trivial. Provides rudimentary targeting capabilities. Last edited in the repository: February 20, 2019.BandieraAlso an open project. Service with API and GUI. Written in Ruby; requires MySQL or PostgreSQL to work, or can be installed from Docker. There are clients for Ruby, Node, Scala, PHP, but not for .NET. Supports a fairly variegated set of types of switches.FlagrAnother open source project on Go. Installed from Docker. There is a graphical interface, as well as clients for Ruby, Go, JavaScript, Python. It offers built-in simple tools for accounting for the use of functionality and experimentation. Each switch can be flexibly configured and equipped with its own configuration.Client Libraries
There are a huge number of libraries for .NET that provide the basic features of switches. But most of them are in an abandoned state. A quick review showed that in 2019, only two projects had edits in the repositories. I found two more interesting projects through the links in the comments to this article. All of them are presented below.EsquioThe most interesting, well-documented and functional project of his group. The built-in storage engine is either a configuration file or an EF Core. It integrates a bit with ASP.NET Core (like Microsoft.FeatureManagement); the documentation says that using Azure can simplify switch configuration.FeatureswitchIt can request the state of the switch both from the configuration file and remotely (it is configured using space classes FeatureSwitch.Strategies). The kit has a simple website framework that allows you to manage switches. It is unclear whether it is possible to make a more complex switch than on / off.Toggle.NetThe simplest library for working with switches, which it stores in a text file. Apparently, it only supports on / off switches.RimDev.FeatureFlagsClient Library for ASP.NET Core. In addition to allowing the use of functionality switches, it raises, along with the main project site, an additional page on which the switches can be controlled. The built-in configuration storage engine is SQL Server.( ) .
«» .
. , , .
. , , , .
. , A/B-.
. .
. .
Conclusion
It seems that in many companies it has already become common practice to use switches to span the moments of the release of the version and the inclusion of new functionality. Additionally, switches help reduce the degree of insanity during merging branches in a version control system. In addition, they open the way to such popular techniques as canary issues and A / B testing.To work with switches, so much software has been created, both paid and free, that any company can choose the tool to its liking.As a result, I will list the features of the functionality switches and voluntarily (as usual) will divide them into advantages and disadvantages.Benefits
- , — , , .
- , . , .
- , . , , , , .
- , . . , «» .
- , . , . , .
disadvantages
- . , . : , . , , .
- . , , . : , , , , . : ( ), .
- . ? , ? . , , . ? ? : , .
- — , . , . : (); ( ); .
- — , . : (); «/».
- , . : ; (, ).
- . , ? : , , , ( ).
References( )
( Medium)
( HighLoad++)
- ( )
- («»)
(«»)
(«»)
- ( Featureflags.io)
( Featureflags.io)
Microsoft ( )
( )
( Smithsonian)
(«»)