
Currently, more and more companies are moving their infrastructure from iron servers and their own virtual machines to the clouds. This solution is easy to explain: there is no need to take care of the hardware, the cluster is easily configured in many different ways ... and most importantly, the available technologies (like Kubernetes) make it easy to scale computing power depending on the load.
The financial aspect is always important. The tool, which will be discussed in this article, is designed to help reduce budgets when using cloud infrastructure with Kubernetes.
Introduction
Kubecost is a California-based startup from Google who creates a solution for calculating infrastructure costs in cloud services (inside the Kubernetes cluster + shared resources), finding bottlenecks in the cluster settings, and sending appropriate notifications to Slack.
We have clients with Kubernetes both in the familiar AWS and GCP clouds, as well as in the rarer Azure Linux community - in general, on all platforms supported by Kubecost. For some of them, we consider the costs of intra-cluster services on our own (using a technique similar to that used by Kubecost), as well as monitor infrastructure costs and try to optimize them. Therefore, it is logical that we were interested in the ability to automate such tasks.
The source code of the Kubecost main module is open under the terms of the Open Source-license (Apache License 2.0). It can be used freely, and the available functions should be enough for small projects. However, business is business: the rest of the product is closed, it can be used for
paid subscriptions , which also imply commercial support. In addition, the authors offer a free license for small clusters (1 cluster with
10 nodes - during the writing of this article this limit has expanded to 20 nodes) or a trial period with full capabilities for 1 month.
How it works
So, the bulk of Kubecost is a
cost-model application written in Go. The helm-chart, which describes the whole system, is called
cost-analyzer and is essentially a cost-model assembly with Prometheus, Grafana and several dashboards.
Generally speaking, cost-model has its own web interface, which displays graphs and detailed statistics on costs in a tabular form, as well as, of course, tips on optimizing costs. The dashboards presented in Grafana are an earlier stage in the development of Kubecost and contain much the same data as the cost-model, supplementing them with the usual statistics on CPU / memory / network / disk space consumption in the cluster and its components.
How does Kubecost work?
- Cost-model through the cloud providers API receives service prices.
- Further, depending on the iron type of the node and the region, the cost of the nodes is considered.
- Based on the cost of the nodes, each final pod receives the cost per hour of using the processor, spending a gigabyte of memory and the cost of an hour of storing a gigabyte of data - depending on the node on which it worked, or the storage class.
- Based on the cost of the work of individual pods, payment is considered for namespaces, services, Deployments, StatefulSets.
- Metrics provided by kube-state-metrics and node-exporter are used to calculate statistics.
It’s important to note that Kubecost
only considers resources available in Kubernetes by default . External databases, GitLab servers, S3 storages, and other services that are not in the cluster (albeit located in the same cloud) are not visible to it. Although for GCP and AWS, you can add the keys of your service accounts and calculate everything together.
Installation
For Kubecost to function, you need:
- Kubernetes version 1.8 and higher;
- kube-state-metrics;
- Prometheus;
- node-exporter.
It so happened that in our clusters all of these conditions were met in advance, so it turned out to be sufficient only to specify the correct endpoint for access to Prometheus. Nevertheless, the official kubecost Helm-chart contains everything you need to start on a bare cluster.
There are several ways to install Kubecost:
- The standard installation method described in the instructions on the developer's website. You need to add the cost-analyzer repository to Helm, and then install the chart . It remains only to forward the port and finish the settings to the desired state manually (via kubectl) and / or using the cost-model web interface.
We didn’t even try this method, because we don’t use third-party ready-made configurations, however it looks like a good option “just try for yourself”. If you already have some of the system components installed or you want more fine-tuning, it is better to consider the second way.
- Use essentially the same chart , but independently configure and install it in any convenient way.
As already mentioned, in addition to kubecost itself, this chart contains the Grafana and Prometheus charts, which can also be customized as you wish.
The values.yaml chart for cost-analyzer available on the chart allows you to configure:
- list of cost-analyzer components to be deployed;
- your endpoint for Prometheus (if you already have one);
- Domains and other ingress settings for cost-model and Grafana;
- annotations for pods;
- the need for permanent storage and their size.
A full list of available configuration options with a description is in the documentation .
Since kubecost in the basic version is not able to restrict access, you will need to immediately configure basic-auth for the web panel.
- Install only the core of the system - cost-model. To do this, you must have Prometheus installed in the cluster and specify the corresponding value of its address in the
prometheusEndpoint variable for Helm. After that, apply the set of YAML configurations in the cluster.
Again, you have to manually add Ingress with basic-auth. And finally, you need to add a section to collect cost-model metrics in extraScrapeConfigs in the Prometheus config:
- job_name: kubecost honor_labels: true scrape_interval: 1m scrape_timeout: 10s metrics_path: /metrics scheme: http dns_sd_configs: - names: - < kubecost> type: 'A' port: 9003
What do we get?
With a full installation, we have at our disposal the web panel kubecost and Grafana with a set of dashboards.
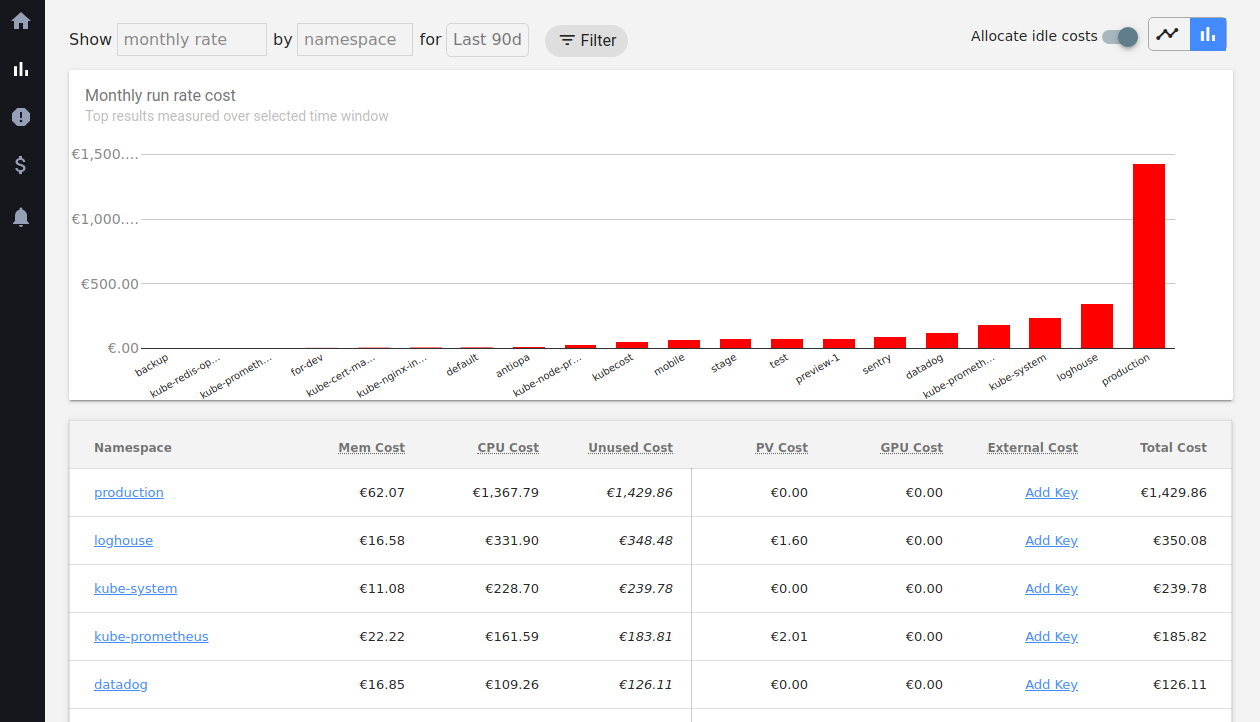
The total cost displayed on the main screen actually shows the estimated cost of resources for the month. This is the
predicted price that displays the cost of using the cluster (per month) at the current level of resource consumption.
This metric is more for cost analysis and optimization. It’s not very convenient to watch the total costs for abstract July in kubecost: you will have
to go to billing for this. But you can see the costs by namespace, label, pod for 1/2/7/30/90 days, which billing will never show you.
Speaking of
labels . You should immediately go into the settings and set the label names, which will be used as additional categories for grouping costs:
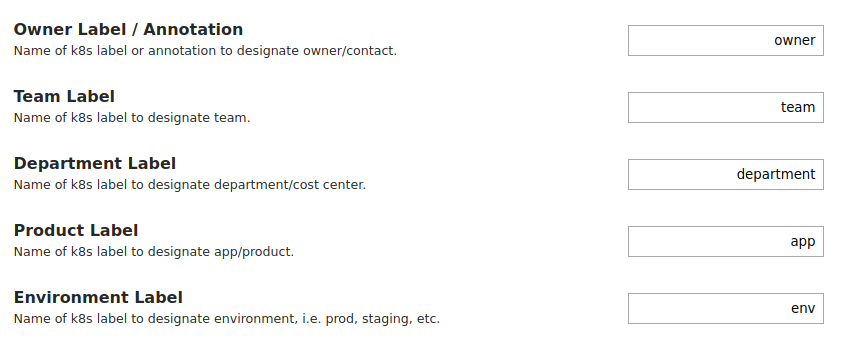
You can hang any labels on them - it’s convenient if you already have your own labeling system.
There you can also change the endpoint API address to which the cost-model connects, configure the discount size in GCP and set your own prices for resources and currency to measure them (for some reason, the feature does not affect Total cost).
Kubecost can show various
problems in the cluster (and even alert in case of danger). Unfortunately, the option is not configurable, and therefore - if you have developer environments and they are used, you can constantly observe something like this:
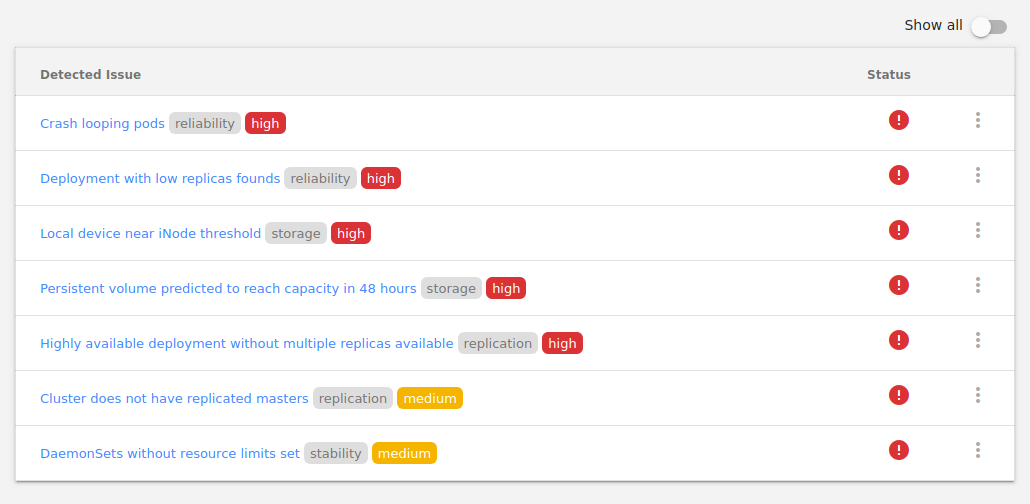
An important tool is
Cluster Savings . It measures the activity of pods (consumption of resources, including network), and also considers how much money and what can be saved.
It might seem that optimization tips are pretty obvious, but experience suggests that there’s still something to look at. In particular, the network activity of pods is monitored (Kubecost offers to pay attention to inactive ones), the requested and actual memory and CPU consumption are compared, as well as the CPU used by the cluster nodes (offers to collapse several nodes into one), disk load and a couple dozen parameters.
As with any optimization issue, resource optimization based on Kubecost data should be
treated with caution . For example, Cluster Savings suggests deleting nodes, claiming that it is safe, but it does not take into account the presence of node-selectors and taint on pods deployed on them that are not present on other nodes. Anyway, even the authors of the product in their
recent article (by the way, it can be very useful for those who are interested in the topic of the project) recommend not to rush headlong into cost optimization, but to approach the issue thoughtfully.
Summary
After using kubecost for a month on a couple of projects, we can conclude that this is an interesting (and even easy to learn and install) tool for analyzing and optimizing the costs of cloud providers used for Kubernetes clusters. The calculations are very accurate: in our experiments, they coincided with what the providers actually required.
Not without drawbacks: there are non-critical bugs, the functionality in places does not cover the requirements specific to some projects. However, if you need to quickly understand where the money goes and what can be “cut” in order to consistently reduce the bill for cloud services by 5-30% (this happened in our case), this is an excellent option.
PS
Read also in our blog: