
Today, on Wednesday, the next release of Kubernetes
will be held - 1.16. According to the tradition that has developed for our blog, for the tenth anniversary time, we are talking about the most significant changes in the new version.
The information used to prepare this material is taken from
the Kubernetes enhancements tracking table ,
CHANGELOG-1.16 and related issues, pull requests, as well as Kubernetes Enhancement Proposals (KEP). So let's go! ..
Knots
A truly large number of notable innovations (in the alpha version status) are presented on the side of the nodes of K8s-clusters (Kubelet).
Firstly, the so-called
" ephemeral containers " (Ephemeral Containers) , designed to simplify the process of debugging in pod'ah . The new mechanism allows you to run special containers that start in the namespace of existing pods and live for a short time. Their purpose is to interact with other pods and containers in order to solve any problems and debugging. For this feature, a new
kubectl debug command is
kubectl debug , similar in essence to
kubectl exec : only instead of starting the process in the container (as in the case of
exec ) it starts the container in pod. For example, such a command will connect a new container to the pod:
kubectl debug -c debug-shell --image=debian target-pod -- bash
Details on ephemeral containers (and examples of their use) can be found in the
corresponding KEP . The current implementation (in K8s 1.16) is the alpha version, and among the criteria for its transfer to the beta version is “testing the Ephemeral Containers API for at least 2 releases [Kubernetes]”.
NB : In essence and even the name of the feature resembles the already existing kubectl-debug plugin, which we already wrote about . It is assumed that with the advent of ephemeral containers, the development of a separate external plug-in will stop.Another innovation,
PodOverhead is designed to provide a
mechanism for calculating overhead costs for pods , which can vary greatly depending on the runtime used. As an example, the authors of
this KEP cite Kata Containers, which require the launch of the guest kernel, kata agent, init system, etc. When the overhead becomes so large, it cannot be ignored, which means that a way is needed to take it into account for further quotas, planning, etc. To implement
PodSpec , the
Overhead *ResourceList field has been added to
PodSpec (mapped to data in the
RuntimeClass , if one is used).
Another notable innovation is the
Node Topology Manager , designed to unify the approach to fine-tuning the distribution of hardware resources for various components in Kubernetes. This initiative is caused by the growing demand of various modern systems (from the field of telecommunications, machine learning, financial services, etc.) for high-performance parallel computing and minimizing delays in the execution of operations, for which they use the advanced capabilities of CPU and hardware acceleration. Such optimizations in Kubernetes have so far been achieved thanks to disparate components (CPU manager, Device manager, CNI), and now they will add a single internal interface that unifies the approach and simplifies the connection of new similar - the so-called topology-aware - components on the Kubelet side. Details are in the
corresponding KEP .
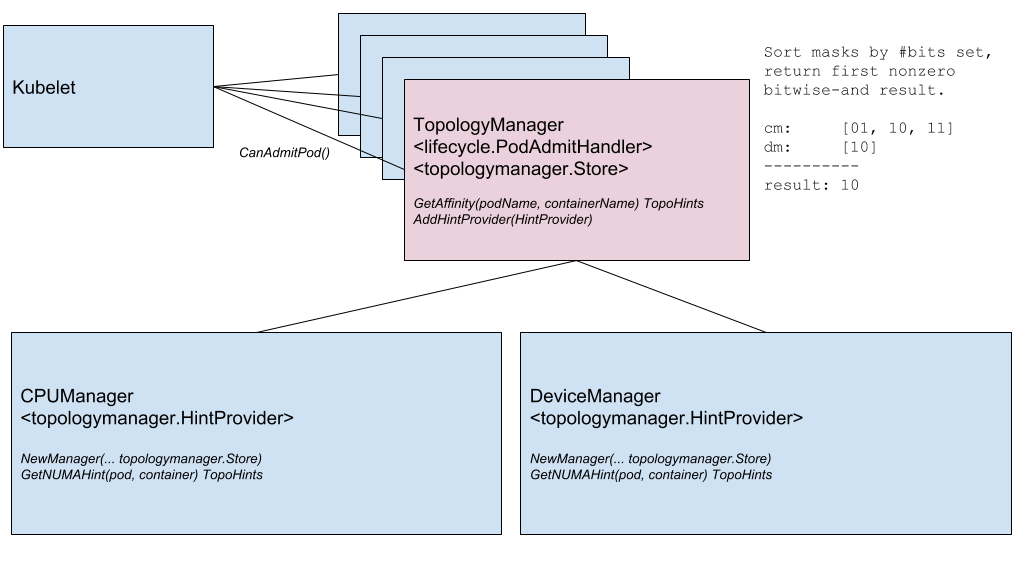 Topology Manager Component Diagram
Topology Manager Component DiagramThe next feature is
checking containers during startup ( startup probe ) . As you know, for containers that run for a long time, it is difficult to get the current status: they are either "killed" before the actual start of operation, or they end up in a deadlock for a long time. A new check (enabled through the feature gate called
StartupProbeEnabled ) cancels - or rather, postpones - the action of any other checks until the moment the pod has finished its launch. For this reason, the feature was originally called
pod-startup liveness-probe holdoff . For pods that start for a long time, it is possible to conduct a state survey in relatively short time intervals.
In addition, immediately in beta status an improvement for RuntimeClass is added, adding support for “heterogeneous clusters”. With
RuntimeClass Scheduling, now it’s not necessary for every node to have support for each RuntimeClass: for pods, you can choose RuntimeClass without thinking about the cluster topology. Previously, to achieve this — in order for pods to appear on nodes with support for everything they needed — they had to assign appropriate rules to NodeSelector and tolerations.
KEP talks about usage examples and, of course, implementation details.
Network
Two significant network features that first appeared (in the alpha version) in Kubernetes 1.16 are:
- Support for a dual network stack - IPv4 / IPv6 - and its corresponding "understanding" at the level of pods, nodes, services. It includes the interaction of IPv4-to-IPv4 and IPv6-to-IPv6 between pods, from pods to external services, reference implementations (as part of Bridge CNI, PTP CNI and Host-Local IPAM plug-ins), as well as the reverse Compatible with Kubernetes clusters that work only over IPv4 or IPv6. Implementation details are in KEP .
An example of outputting two types of IP addresses (IPv4 and IPv6) in the list of pods:
kube-master
- The new API for Endpoint is the EndpointSlice API . It solves the problems of the existing Endpoint API with performance / scalability that affect various components in the control-plane (apiserver, etcd, endpoints-controller, kube-proxy). The new API will be added to the Discovery API group and will be able to serve tens of thousands of backend endpoints on each service in a cluster consisting of a thousand nodes. To do this, each Service is mapped to N
EndpointSlice objects, each of which by default has no more than 100 endpoints (the value is configurable). The EndpointSlice API will also provide opportunities for its future development: support for many IP addresses for each pod, new states for endpoints (not only Ready and NotReady ), dynamic subsetting for endpoints.
The
finalizer presented in the last release called
service.kubernetes.io/load-balancer-cleanup and attached to each service with the type
LoadBalancer advanced to the beta version. At the time of removal of such a service, it prevents the actual deletion of the resource until the "cleansing" of all the corresponding resources of the balancer is completed.
API Machinery
The real "stabilization milestone" is fixed in the area of the Kubernetes API server and interaction with it. In many respects, this happened due to the
transfer to the stable status of CustomResourceDefinitions (CRD) that
did not need a special presentation , which had beta status since the distant Kubernetes 1.7 (and this is June 2017!). The same stabilization came to the features related to them:
- "Subresources" with
/status and /scale for CustomResources; - version conversion for CRD, based on an external webhook;
- recently introduced (in K8s 1.15) default values (defaulting) and automatic field deletion (pruning) for CustomResources;
- the possibility of using the OpenAPI v3 scheme for creating and publishing OpenAPI documentation used to validate CRD resources on the server side.
Another mechanism that has long been familiar to Kubernetes administrators:
admission webhook , has also been in beta status for a long time (since K8s 1.9) and has now been declared stable.
Two other features reached beta:
server-side apply and
watch bookmarks .
And the only significant innovation in the alpha version was the
rejection of SelfLink - a special URI that represents the specified object and is part of
ObjectMeta and
ListMeta (i.e., part of any object in Kubernetes). Why refuse it? The “simple” motivation
sounds like the absence of real (insurmountable) reasons for this field to continue to exist. More formal reasons are to optimize performance (removing an unnecessary field) and simplify the work of generic-apiserver, which is forced to process such a field in a special way (this is the only field that is set right before the object is serialized). The real "obsolescence" (in the beta version) of
SelfLink will happen to Kubernetes version 1.20, and the final one - 1.21.
Data storage
The main work in the field of storage, as in previous releases, is observed in the field of
support for CSI . The main changes here are:
- for the first time (in the alpha version) , support for CSI plug-ins for working nodes with Windows appeared : the actual way to work with repositories will replace the in-tree plugins in the Kubernetes core and Powershell-based FlexVolume plug-ins from Microsoft;
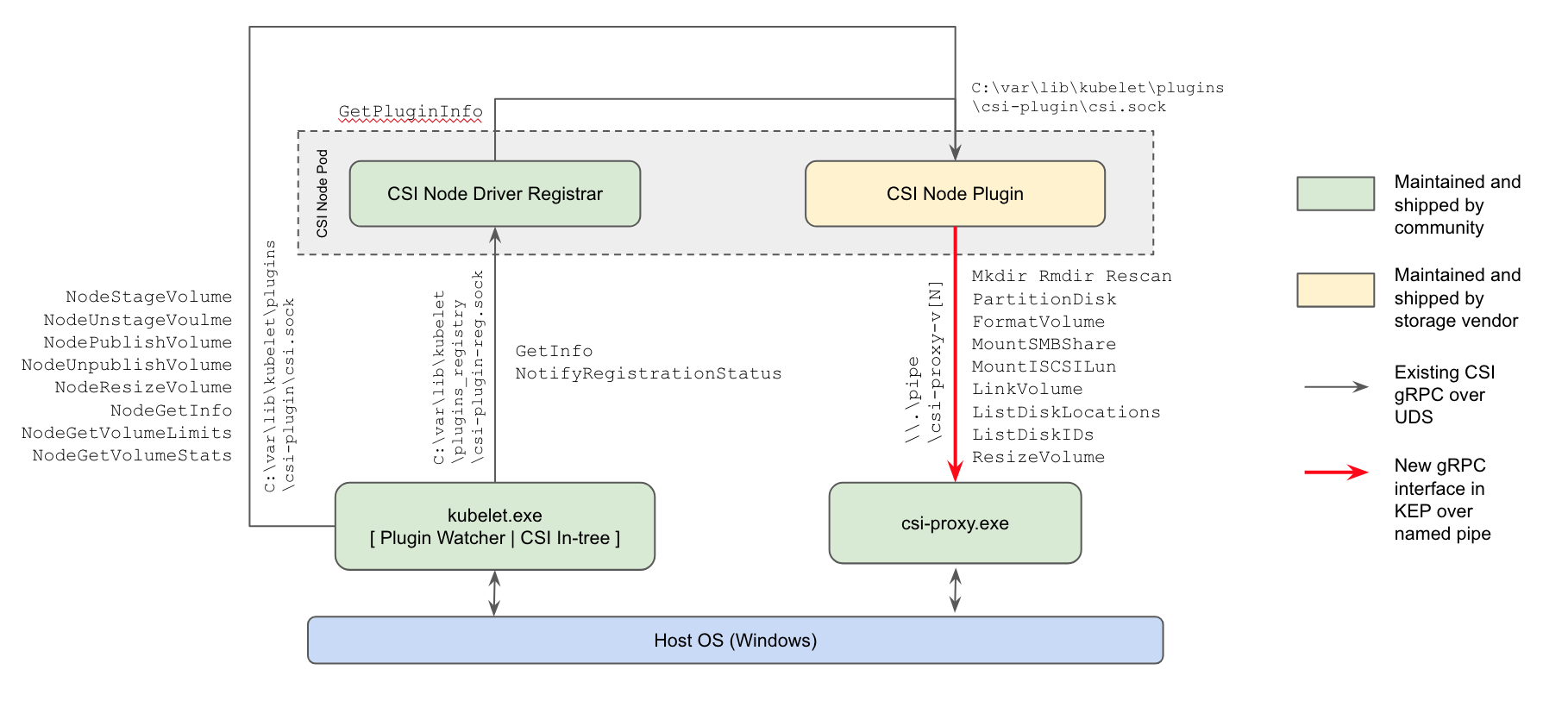
Kubernetes Windows CSI Plugin Implementation Scheme
- the ability to resize CSI volumes , introduced back in K8s 1.12, has grown to a beta version;
- the possibility of using CSI to create local ephemeral volumes ( CSI Inline Volume Support ) has reached a similar “increase” (from alpha to beta).
The
function for cloning volumes that appeared in the previous version of Kubernetes (using existing PVCs as a
DataSource to create new PVCs) has also now received beta status.
Scheduler
Two notable changes in planning (both in the alpha version):
EvenPodsSpreading is the ability to use EvenPodsSpreading to "fairly distribute" loads instead of application logical units (like Deployment and ReplicaSet) and adjust this distribution (as a strict requirement or as a mild condition, i.e. priority). The feature will expand the existing distribution capabilities of planned pods, now limited by the PodAffinity and PodAntiAffinity , giving administrators more control over this issue, which means better accessibility and optimized resource consumption. Details are in the KEP .- Using the BestFit Policy in the RequestedToCapacityRatio Priority Function during pod scheduling, which allows bin packing (“packing in containers”) to be used for both core resources (processor, memory) and extended (like GPU). See KEP for details.

Pod scheduling: before using the best fit policy (directly through default scheduler) and using it (via scheduler extender)
In addition,
the opportunity
is presented to create your own plug-ins for the scheduler outside the main Kubernetes (out-of-tree) development tree.
Other changes
Also in Kubernetes 1.16 release, one can note an
initiative to bring existing metrics in full order , or more precisely, in accordance with
official K8s instrumentation requirements. They basically rely on the relevant
Prometheus documentation . The inconsistencies were formed for various reasons (for example, some metrics were simply created before the current instructions appeared), and the developers decided that it was time to bring everything to a single standard, "in line with the rest of the Prometheus ecosystem." The current implementation of this initiative has the status of the alpha version, which will gradually increase in subsequent versions of Kubernetes to beta (1.17) and stable (1.18).
In addition, the following changes can be noted:
- Development of Windows support with the advent of the Kubeadm utility for this OS (alpha version), the possibility of
RunAsUserName for Windows containers (alpha version), improvement of support for the Group Managed Service Account (gMSA) to beta version, mount / attach support for vSphere volumes. - Redesigned data compression mechanism in API responses . Previously, an HTTP filter was used for these purposes, which imposed a number of restrictions that prevented its inclusion by default. Now transparent query compression works: clients sending
Accept-Encoding: gzip in the header receive a GZIP-compressed response if its size exceeds 128 Kb. Clients on Go automatically support compression (send the desired header), so they immediately notice a decrease in traffic. (For other languages, minor modifications may be required.) - It became possible to scale HPA from / to zero pods based on external metrics . If scaling is based on objects / external metrics, then when workloads are idle, you can automatically scale to 0 replicas to save resources. This feature should be especially useful for cases when workers request GPU resources, and the number of different types of idle workers exceeds the number of available GPUs.
- A new client -
k8s.io/client-go/metadata.Client - for "generalized" access to objects. It is designed to easily obtain metadata (i.e., the metadata subsection) from cluster resources and perform operations with them from the category of garbage collection and quotas. - Kubernetes can now be built without outdated ("built-in" in-tree) cloud providers (alpha version).
- The experimental (alpha version) ability to apply kustomize patches during
init , join and upgrade operations has been added to the kubeadm utility. For details on how to use the --experimental-kustomize , see KEP . - The new endpoint for apiserver is
readyz , which allows you to export readiness information. The API server also has a flag --maximum-startup-sequence-duration , which allows you to adjust its restarts. - Two features for Azure are declared stable: support for Availability Zones and cross resource group (RG). In addition, Azure added:
- AWS has support for EBS on Windows and optimized EC2 API calls
DescribeInstances . - Kubeadm now migrates its CoreDNS configuration on its own when upgrading to CoreDNS.
- The binaries etcd in the corresponding Docker image made world-executable, which allows you to run this image without the need for root privileges. In addition, the etcd migration image has dropped support for the etcd2 version.
- Cluster Autoscaler 1.16.0 switched to using distroless as a base image, improved performance, and added new cloud providers (DigitalOcean, Magnum, Packet).
- Updates in the used / dependent software: Go 1.12.9, etcd 3.3.15, CoreDNS 1.6.2.
PS
Read also in our blog: