Habr, hello.
This post is a brief overview of general machine learning algorithms. Each is accompanied by a brief description, guides and useful links.
Principal Component Method (PCA) / SVD
This is one of the basic machine learning algorithms. Allows you to reduce the dimensionality of the data, losing the least amount of information. It is used in many fields, such as object recognition, computer vision, data compression, etc. The calculation of the main components reduces to calculating the eigenvectors and eigenvalues of the covariance matrix of the source data or to the singular decomposition of the data matrix.
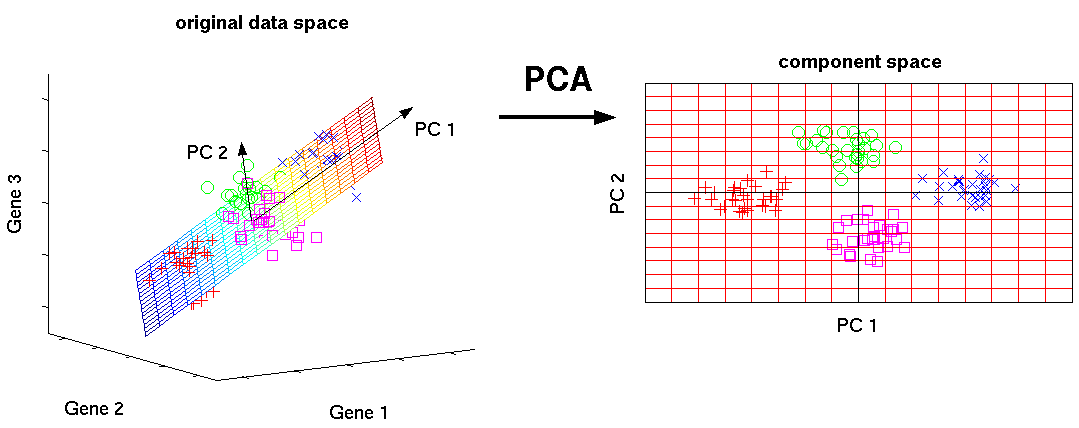
SVD is a way of calculating ordered components.
Useful links:
Introductory Guide:
Least square method
The least squares method is a mathematical method used to solve various problems, based on minimizing the sum of the squares of the deviations of some functions from the desired variables. It can be used to “solve” overdetermined systems of equations (when the number of equations exceeds the number of unknowns), to find a solution in the case of ordinary (not redefined) nonlinear systems of equations, and also to approximate the point values of a function.
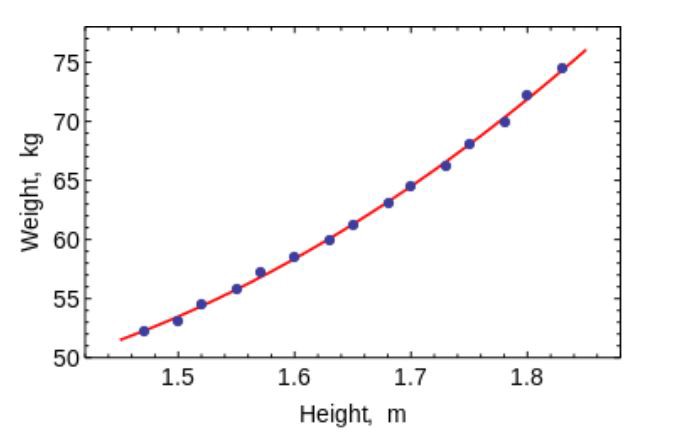
Use this algorithm to fit simple curves / regression.
Useful links:
Introductory Guide:
Limited linear regression
The least squares method can confuse outliers, false fields, etc. Constraints are needed to reduce the variance of the line that we put in the data set. The correct solution is to fit a linear regression model that ensures that weights do not behave “badly”. Models can have the norm L1 (LASSO) or L2 (Ridge Regression) or both (elastic regression).
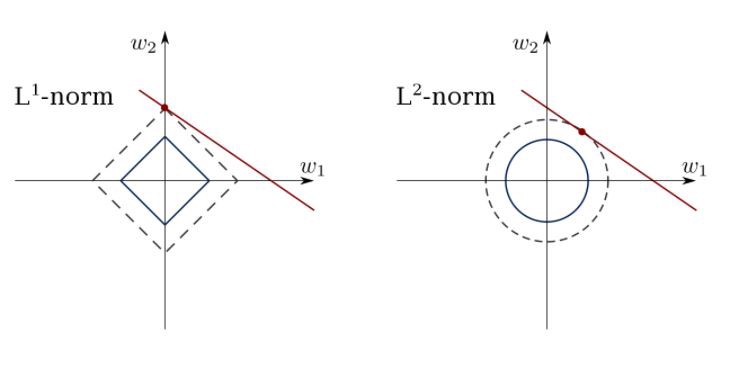
Use this algorithm to match constrained regression lines, avoiding overriding.
Useful link:
Introductory Guides:
K-means method
Everyone's favorite uncontrolled clustering algorithm. Given a dataset in the form of vectors, we can create clusters of points based on the distances between them. This is one of the machine learning algorithms that sequentially moves the centers of the clusters and then groups the points with each center of the cluster. The input is the number of clusters to be created and the number of iterations.
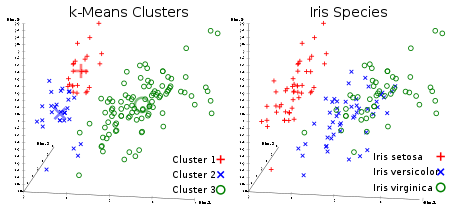
Useful link:
Introductory Guides:
Logistic Regression
Logistic regression is limited by linear regression with non-linearity (mainly using the sigmoid function or tanh) after applying weights, therefore, the output limitation is close to the +/- classes (which is 1 and 0 in the case of a sigmoid). Cross-entropy loss functions are optimized using the gradient descent method.
Note for beginners: logistic regression is used for classification, not regression. In general, it is similar to a single-layer neural network. Trained using optimization techniques such as gradient descent or L-BFGS. NLP developers often use it, calling it “maximum entropy classification”.

Use LR to train simple but very “strong” classifiers.
Useful link:
Introductory Guide:
SVM (Support Vector Method)
SVM is a linear model such as linear / logistic regression. The difference is that it has a margin-based loss function. You can optimize the loss function using optimization methods such as L-BFGS or SGD.

One unique thing that SVM can do is learn class classifiers.
SVM can be used to train classifiers (even regressors).
Useful link:
Introductory Guides:
Direct Neural Networks
Basically, these are multilevel classifiers of logistic regression. Many layers of weights are separated by non-linearities (sigmoid, tanh, relu + softmax and cool new selu). They are also called multilayer perceptrons. FFNNs can be used for classification and “teacherless training” as auto-encoders.

FFNN can be used to train the classifier or to extract functions as auto-encoders.
Useful links:
Introductory Guides:
Convolutional neural networks
Almost all modern achievements in the field of machine learning were achieved using convolutional neural networks. They are used to classify images, detect objects, or even segment images. Invented by Jan Lekun in the early 90s, networks have convolutional layers that act as hierarchical extractors of objects. You can use them to work with text (and even to work with graphics).
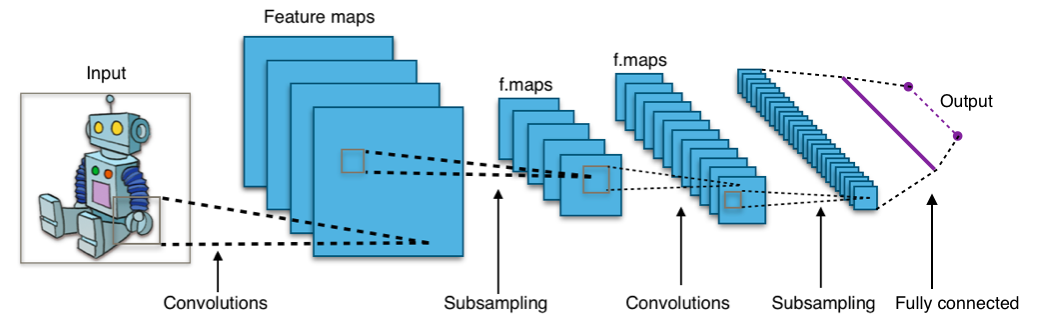
Useful links:
Introductory Guides:
Recurrent Neural Networks (RNNs)
RNNs model sequences by applying the same set of weights recursively to the state of the aggregator at time t and the input at time t. Pure RNNs are rarely used now, but its counterparts, such as LSTM and GRU, are the most advanced in most sequence modeling tasks. LSTM, which is used instead of a simple dense layer in pure RNN.

Use RNN for any task of text classification, machine translation, language modeling.
Useful links:
Introductory Guides:
Conditional Random Fields (CRFs)
They are used for sequence modeling, like RNNs, and can be used in combination with RNNs. They can also be used in other structured forecasting tasks, for example, in image segmentation. CRF models each element of the sequence (say, a sentence) so that neighbors influence the label of the component in the sequence, and not all labels that are independent of each other.
Use CRF for linking sequences (in text, image, time series, DNA, etc.).
Useful link:
Introductory Guides:
Decision Trees and Random Forests
One of the most common machine learning algorithms. Used in statistics and data analysis for predictive models. The structure consists of “leaves” and “branches”. Attributes on which the objective function depends are recorded on the “branches” of the decision tree, the values of the objective function are written in the “leaves”, and the attributes that distinguish cases are recorded in the remaining nodes.
To classify a new case, you need to go down the tree to the leaf and issue the corresponding value. The goal is to create a model that predicts the value of the target variable based on several input variables.
Useful links:
Introductory Guides:
You will learn more information about machine learning and Data Science by subscribing to my account on
Habré and the Telegram channel
Neuron . Do not skip future articles.
All knowledge!