Alexey Lizunov, head of the center of competence of remote service channels of the Directorate of Information Technologies of the ICD
As an alternative to the ELK stack (ElasticSearch, Logstash, Kibana), we are conducting research on the use of the ClickHouse database as a data warehouse for logs.
In this article, we would like to talk about our experience using the ClickHouse database and about preliminary results from the pilot operation. It should be noted right away that the results were impressive.
Next, we will describe in more detail how our system is configured and what components it consists of. But now I would like to talk a little about this database as a whole, and why you should pay attention to it. The ClickHouse database is a high-performance analytical column database from Yandex. It is used in Yandex services, initially it is the main data warehouse for Yandex.Metrica. The open-source system is free. From the point of view of the developer, I was always wondering how they implemented it, because there is fantastically big data. And the Metrica user interface itself is very flexible and fast. At the first acquaintance with this database, the impression: “Well, finally! Made "for people"! Starting from the installation process and ending with sending requests. "
This database has a very low entry threshold. Even an average skilled developer can install this database in a few minutes and start using it. Everything works clearly. Even people who are new to Linux can quickly get through the installation and do simple operations. Earlier, when the word Big Data, Hadoop, Google BigTable, HDFS, the usual developer had the idea that they were talking about some terabytes, petabytes, that some superhumans were involved in the settings and development for these systems, then with the advent of the ClickHouse database we got A simple, understandable tool with which you can solve the previously unattainable range of tasks. Just one fairly average car and five minutes to install. That is, we got such a database as, for example, MySql, but only to store billions of records! Some kind of SQL supervisor. It is as if people were given weapons of aliens.
About our log collection system
To collect information, IIS log files of web applications of a standard format are used (we are also engaged in parsing application logs, but the main goal at the stage of pilot operation with us is collecting IIS logs).
For various reasons, we failed to completely abandon the ELK stack, and we continue to use the LogStash and Filebeat components, which have proven themselves well and work quite reliably and predictably.
The general logging scheme is presented in the figure below:
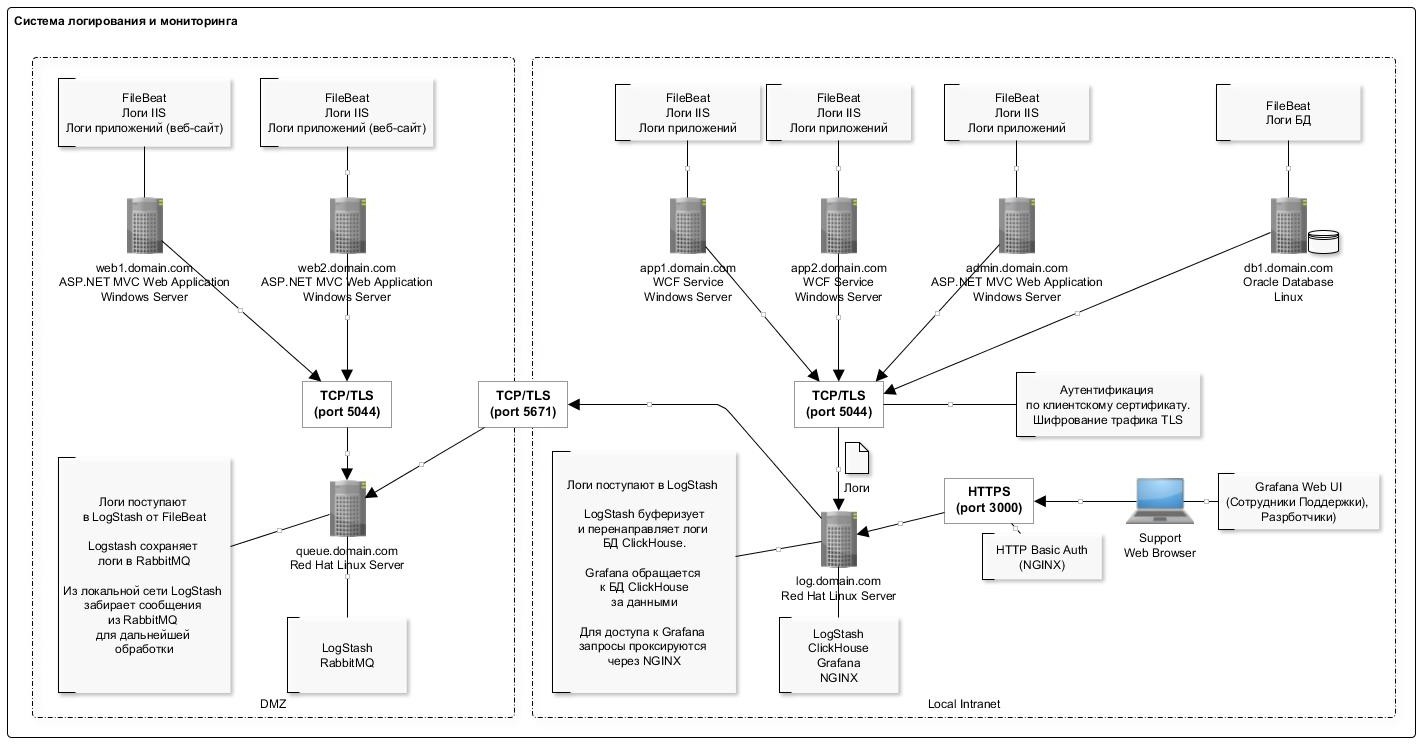
A feature of writing data to the ClickHouse database is the infrequent (once per second) insertion of records in large batches. This, apparently, is the most “problematic” part that you encounter when you first experience working with the ClickHouse database: the scheme is a bit complicated.
The LogStash plugin, which directly inserts data into ClickHouse, helped a lot here. This component is deployed on the same server as the database itself. So, generally speaking, it is not recommended to do it, but from a practical point of view, so as not to produce separate servers while it is deployed on the same server. We did not observe any failures or resource conflicts with the database. In addition, it should be noted that the plugin has a retray mechanism in case of errors. And in case of errors, the plugin writes to the disk a packet of data that could not be inserted (the file format is convenient: after editing, you can easily insert the corrected packet using clickhouse-client).
The full list of software used in the scheme is presented in the table:
The server configuration with the ClickHouse database is presented in the following table:
As you can see, this is a regular workstation.
The structure of the table for storing logs is as follows:
log_web.sqlCREATE TABLE log_web ( logdate Date, logdatetime DateTime CODEC(Delta, LZ4HC), fld_log_file_name LowCardinality( String ), fld_server_name LowCardinality( String ), fld_app_name LowCardinality( String ), fld_app_module LowCardinality( String ), fld_website_name LowCardinality( String ), serverIP LowCardinality( String ), method LowCardinality( String ), uriStem String, uriQuery String, port UInt32, username LowCardinality( String ), clientIP String, clientRealIP String, userAgent String, referer String, response String, subresponse String, win32response String, timetaken UInt64 , uriQuery__utm_medium String , uriQuery__utm_source String , uriQuery__utm_campaign String , uriQuery__utm_term String , uriQuery__utm_content String , uriQuery__yclid String , uriQuery__region String ) Engine = MergeTree() PARTITION BY toYYYYMM(logdate) ORDER BY (fld_app_name, fld_app_module, logdatetime) SETTINGS index_granularity = 8192;
We use default values for partitioning (by months) and granularity of the index. All fields practically correspond to IIS log entries for registering http-requests. Separately, separate fields for storing utm tags (they are parsed at the stage of insertion into the table from the query string field).
Also in the table are added several system fields for storing information about systems, components, servers. See the table below for a description of these fields. In one table, we store logs for several systems.
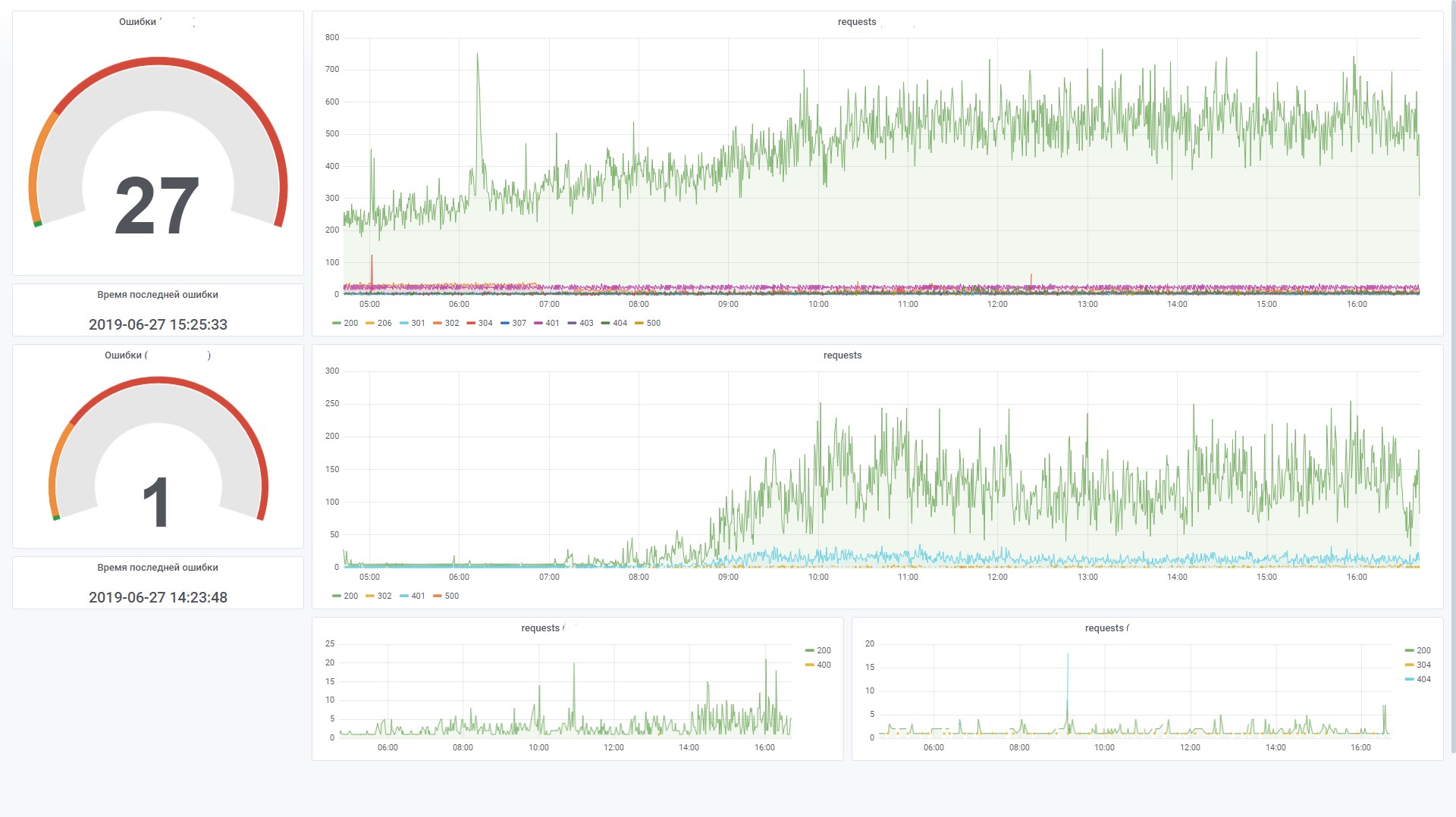
This allows you to effectively build graphics in Grafana. For example, view requests from the frontend of a specific system. This is similar to the site counter in Yandex.Metrica.
Here are some statistics on using the database for two months.
Number of records by system and component SELECT fld_app_name, fld_app_module, count(fld_app_name) AS rows_count FROM log_web GROUP BY fld_app_name, fld_app_module WITH TOTALS ORDER BY fld_app_name ASC, rows_count DESC ┌─fld_app_name─────┬─fld_app_module─┬─rows_count─┐ │ site1.domain.ru │ web │ 131441 │ │ site2.domain.ru │ web │ 1751081 │ │ site3.domain.ru │ web │ 106887543 │ │ site3.domain.ru │ svc │ 44908603 │ │ site3.domain.ru │ intgr │ 9813911 │ │ site4.domain.ru │ web │ 772095 │ │ site5.domain.ru │ web │ 17037221 │ │ site5.domain.ru │ intgr │ 838559 │ │ site5.domain.ru │ bo │ 7404 │ │ site6.domain.ru │ web │ 595877 │ │ site7.domain.ru │ web │ 27778858 │ └──────────────────┴────────────────┴────────────┘ Totals: ┌─fld_app_name─┬─fld_app_module─┬─rows_count─┐ │ │ │ 210522593 │ └──────────────┴────────────────┴────────────┘ 11 rows in set. Elapsed: 4.874 sec. Processed 210.52 million rows, 421.67 MB (43.19 million rows/s., 86.51 MB/s.)
The amount of data on the disk SELECT formatReadableSize(sum(data_uncompressed_bytes)) AS uncompressed, formatReadableSize(sum(data_compressed_bytes)) AS compressed, sum(rows) AS total_rows FROM system.parts WHERE table = 'log_web' ┌─uncompressed─┬─compressed─┬─total_rows─┐ │ 54.50 GiB │ 4.86 GiB │ 211427094 │ └──────────────┴────────────┴────────────┘ 1 rows in set. Elapsed: 0.035 sec.
Column data compression ratio SELECT name, formatReadableSize(data_uncompressed_bytes) AS uncompressed, formatReadableSize(data_compressed_bytes) AS compressed, data_uncompressed_bytes / data_compressed_bytes AS compress_ratio FROM system.columns WHERE table = 'log_web' ┌─name───────────────────┬─uncompressed─┬─compressed─┬─────compress_ratio─┐ │ logdate │ 401.53 MiB │ 1.80 MiB │ 223.16665968777315 │ │ logdatetime │ 803.06 MiB │ 35.91 MiB │ 22.363966401202305 │ │ fld_log_file_name │ 220.66 MiB │ 2.60 MiB │ 84.99905736932571 │ │ fld_server_name │ 201.54 MiB │ 50.63 MiB │ 3.980924816977078 │ │ fld_app_name │ 201.17 MiB │ 969.17 KiB │ 212.55518183686877 │ │ fld_app_module │ 201.17 MiB │ 968.60 KiB │ 212.67805817411906 │ │ fld_website_name │ 201.54 MiB │ 1.24 MiB │ 162.7204926761546 │ │ serverIP │ 201.54 MiB │ 50.25 MiB │ 4.010824061219731 │ │ method │ 201.53 MiB │ 43.64 MiB │ 4.617721053304486 │ │ uriStem │ 5.13 GiB │ 832.51 MiB │ 6.311522291936919 │ │ uriQuery │ 2.58 GiB │ 501.06 MiB │ 5.269731450124478 │ │ port │ 803.06 MiB │ 3.98 MiB │ 201.91673864241824 │ │ username │ 318.08 MiB │ 26.93 MiB │ 11.812513794583598 │ │ clientIP │ 2.35 GiB │ 82.59 MiB │ 29.132328640073343 │ │ clientRealIP │ 2.49 GiB │ 465.05 MiB │ 5.478382297052563 │ │ userAgent │ 18.34 GiB │ 764.08 MiB │ 24.57905114484208 │ │ referer │ 14.71 GiB │ 1.37 GiB │ 10.736792723669906 │ │ response │ 803.06 MiB │ 83.81 MiB │ 9.582334090987247 │ │ subresponse │ 399.87 MiB │ 1.83 MiB │ 218.4831068635027 │ │ win32response │ 407.86 MiB │ 7.41 MiB │ 55.050315514606815 │ │ timetaken │ 1.57 GiB │ 402.06 MiB │ 3.9947395692010637 │ │ uriQuery__utm_medium │ 208.17 MiB │ 12.29 MiB │ 16.936148912472955 │ │ uriQuery__utm_source │ 215.18 MiB │ 13.00 MiB │ 16.548367623199912 │ │ uriQuery__utm_campaign │ 381.46 MiB │ 37.94 MiB │ 10.055156353418509 │ │ uriQuery__utm_term │ 231.82 MiB │ 10.78 MiB │ 21.502540454070672 │ │ uriQuery__utm_content │ 441.34 MiB │ 87.60 MiB │ 5.038260760449327 │ │ uriQuery__yclid │ 216.88 MiB │ 16.58 MiB │ 13.07721335008116 │ │ uriQuery__region │ 204.35 MiB │ 9.49 MiB │ 21.52661903446796 │ └────────────────────────┴──────────────┴────────────┴────────────────────┘ 28 rows in set. Elapsed: 0.005 sec.
Description of components used
FileBeat. File Log Transfer
This component monitors changes in the log files on disk and transfers information to LogStash. It is installed on all servers where log files are written (usually IIS). It works in tail mode (i.e., transfers only added records to a file). But separately, you can configure the entire file transfer. This is useful when you need to download data from previous months. Just put the log file in a folder and he will read it in its entirety.
When the service stops, the data ceases to be transferred further to the storage.
An example configuration is as follows:
filebeat.yml filebeat.inputs: - type: log enabled: true paths: - C:/inetpub/logs/LogFiles/W3SVC1
LogStash Log collector
This component is intended for receiving log entries from FileBeat (or through the RabbitMQ queue), parsing and inserting bundles into the ClickHouse database.
To insert into ClickHouse, the Logstash-output-clickhouse plugin is used. The Logstash plugin has a mechanism for retrieving requests, but with a regular shutdown, it is better to stop the service itself. When you stop, messages will accumulate in the RabbitMQ queue, so if you stop for a long time, then it is better to stop Filebeats on the servers. In a scheme where RabbitMQ is not used (on a local network, Filebeat sends logs directly to Logstash), Filebeats work quite reasonably and safely, so for them the inaccessibility of output goes without consequences.
An example configuration is as follows:
log_web__filebeat_clickhouse.conf input { beats { port => 5044 type => 'iis' ssl => true ssl_certificate_authorities => ["/etc/logstash/certs/ca.cer", "/etc/logstash/certs/ca-issuing.cer"] ssl_certificate => "/etc/logstash/certs/server.cer" ssl_key => "/etc/logstash/certs/server-pkcs8.key" ssl_verify_mode => "peer" add_field => { "fld_server_name" => "%{[fields][fld_server_name]}" "fld_app_name" => "%{[fields][fld_app_name]}" "fld_app_module" => "%{[fields][fld_app_module]}" "fld_website_name" => "%{[fields][fld_website_name]}" "fld_log_file_name" => "%{source}" "fld_logformat" => "%{[fields][fld_logformat]}" } } rabbitmq { host => "queue.domain.com" port => 5671 user => "q-reader" password => "password" queue => "web_log" heartbeat => 30 durable => true ssl => true
ClickHouse. Log storage
Logs for all systems are saved in one table (see the beginning of the article). It is intended for storing information about requests: all parameters are similar for different formats, for example, IIS logs, apache and nginx logs. For application logs in which, for example, errors, informational messages, warings are recorded, a separate table will be provided with the corresponding structure (now at the design stage).
When designing a table, it is very important to determine the primary key (by which data will be sorted during storage). The degree of data compression and query speed depend on this. In our example, the key is
ORDER BY (fld_app_name, fld_app_module, logdatetime)
That is, by the name of the system, the name of the system component and the date of the event. The original date of the event was in first place. After moving it to the last place, queries began to work about twice as fast. Changing the primary key will require re-creating the table and reloading the data in order for ClickHouse to re-sort the data on disk. This is a difficult operation, so it is advisable to think ahead of time what should be included in the sort key.
It should also be noted that relatively in recent versions the LowCardinality data type has appeared. When using it, the size of compressed data is sharply reduced for those fields that have low cardinality (few options).
Now version 19.6 is used, and we plan to try to update the version to the latest. They included such wonderful features as Adaptive Granularity, Skipping indices and the DoubleDelta codec, for example.
By default, during installation, the configuration log level is set to trace. Logs are rotated and archived, but expand to a gigabyte. If it is not necessary, then you can set the warning level, then the size of the log decreases sharply. Logging settings are set in the config.xml file:
<level>warning</level>
Some useful commands Debian, Linux Altinity. : https://www.altinity.com/blog/2017/12/18/logstash-with-clickhouse sudo yum search clickhouse-server sudo yum install clickhouse-server.noarch 1. sudo systemctl status clickhouse-server 2. sudo systemctl stop clickhouse-server 3. sudo systemctl start clickhouse-server ( ";") clickhouse-client
LogStash FileBeat log router to RabbitMQ queue
This component is used to route logs coming from FileBeat to the RabbitMQ queue. There are two points:
- Unfortunately, FileBeat does not have an output plugin for writing directly to RabbitMQ. And such functionality, judging by the ish on their github, is not planned for implementation. There is a plugin for Kafka, but for some reason we can not use it at home.
- There are requirements for collecting logs in the DMZ. Based on them, the logs must first be added to the queue and then LogStash from the outside reads the entries from the queue.
Therefore, it is precisely for the case of server location in the DMZ that you have to use such a slightly complicated scheme. An example configuration is as follows:
iis_w3c_logs__filebeat_rabbitmq.conf input { beats { port => 5044 type => 'iis' ssl => true ssl_certificate_authorities => ["/etc/pki/tls/certs/app/ca.pem", "/etc/pki/tls/certs/app/ca-issuing.pem"] ssl_certificate => "/etc/pki/tls/certs/app/queue.domain.com.cer" ssl_key => "/etc/pki/tls/certs/app/queue.domain.com-pkcs8.key" ssl_verify_mode => "peer" } } output {
RabbitMQ. Message queue
This component is used to buffer log entries in the DMZ. Recording is done through a bunch of Filebeat → LogStash. Reading is done from outside the DMZ via LogStash. When operating through RabboitMQ, about 4 thousand messages are processed per second.
Message routing is configured according to the name of the system, i.e. based on the FileBeat configuration data. All messages fall into one queue. If for some reason the queue service is stopped, this will not lead to loss of messages: FileBeats will receive connection errors and suspend temporary sending. And LogStash, which reads from the queue, will also receive network errors and wait for the connection to resume. The data, of course, will no longer be written to the database.
The following instructions are used to create and configure queues:
sudo /usr/local/bin/rabbitmqadmin/rabbitmqadmin declare exchange
Grafana Dashboards
This component is used to visualize monitoring data. In this case, you must install the ClickHouse datasource for Grafana 4.6+ plugin. We had to tweak it a bit to increase the efficiency of processing SQL filters on a dashboard.
For example, we use variables, and if they are not set in the filter field, we would like it to not generate a condition in the WHERE form (uriStem = '' AND uriStem! = ''). In this case, ClickHouse will read the uriStem column. In general, we tried different options and finally fixed the plugin (macro $ valueIfEmpty), so that in case of an empty value it would return 1, without mentioning the column itself.
And now you can use this query for the graph
$columns(response, count(*) c) from $table where $adhoc and $valueIfEmpty($fld_app_name, 1, fld_app_name = '$fld_app_name') and $valueIfEmpty($fld_app_module, 1, fld_app_module = '$fld_app_module') and $valueIfEmpty($fld_server_name, 1, fld_server_name = '$fld_server_name') and $valueIfEmpty($uriStem, 1, uriStem like '%$uriStem%') and $valueIfEmpty($clientRealIP, 1, clientRealIP = '$clientRealIP')
which is converted to such SQL (note that empty uriStem fields were converted to just 1)
SELECT t, groupArray((response, c)) AS groupArr FROM ( SELECT (intDiv(toUInt32(logdatetime), 60) * 60) * 1000 AS t, response, count(*) AS c FROM default.log_web WHERE (logdate >= toDate(1565061982)) AND (logdatetime >= toDateTime(1565061982)) AND 1 AND (fld_app_name = 'site1.domain.ru') AND (fld_app_module = 'web') AND 1 AND 1 AND 1 GROUP BY t, response ORDER BY t ASC, response ASC ) GROUP BY t ORDER BY t ASC
Conclusion
The appearance of ClickHouse database has become a landmark event in the market. It was hard to imagine that for free in an instant, we were armed with a powerful and practical tool for working with big data. Of course, with increasing needs (for example, sharding and replication to multiple servers), the scheme will become more complex. But according to first impressions, working with this database is very nice. It can be seen that the product is made "for people."
Compared to ElasticSearch, the cost of storing and processing logs, according to preliminary estimates, is reduced from five to ten times. In other words, if for the current amount of data we would have to configure a cluster of several machines, then when using ClickHouse we need only one low-power machine. Yes, of course, ElasticSearch also has mechanisms for compressing data on the disk and other features that can significantly reduce resource consumption, but compared to ClickHouse, this will be very expensive.
Without any special optimizations for its part, on default settings, loading data and retrieving data from the database works at amazing speed. We still have a little data (about 200 million records), but the server itself is weak. In the future, we can use this tool for other purposes not related to the storage of logs. For example, for end-to-end analytics, in the field of security, machine learning.
In the end, a little about the pros and cons.
Minuses
- Downloading records in large bundles. This, on the one hand, is a feature, but still you have to use additional components to buffer records. This task is not always simple, but still solvable. And I would like to simplify the scheme.
- Some exotic functionality or new features often break in new versions. This raises concerns, reducing the desire to upgrade to a new version. For example, the Kafka table engine is a very useful feature that allows you to directly read events from Kafka, without the implementation of consumers. But judging by the number of Issues on the github, we are still wary of using this engine in production. However, if you do not make sudden gestures to the side and use the basic functionality, then it works stably.
pros
- It does not slow down.
- Low entry threshold.
- Open source
- It’s free.
- Scales well (out-of-box sharding / replication)
- Included in the registry of Russian software recommended by the Ministry of Communications.
- The presence of official support from Yandex.