
Good afternoon friends! Today I continue the series on
Extreme Switches with an article on Enterprise Network Design.
In the article I will try as briefly as possible:
- describe the modular approach to Etnterprise network design
- to consider the types of construction of one of the most important modules of the enterprise network - the backbone network (ip-campus)
- describe the advantages and disadvantages of backup options critical network nodes
- on an abstract example, design / update a small Enterprise network
- Choose Extreme Switches to Implement Your Designed Network
- work with fibers and IP addressing
This article will be of interest to network engineers and network administrators who are just starting their career as a network engineer, rather than experienced engineers who have worked for many years in telecom operators or in large corporations with geographically distributed networks.
In any case, interested please ask for cat.
Modular Network Design Approach
I will start my article with a fairly popular modular approach to network design, which allows you to assemble a puzzle from pieces of the network into one complete picture.
First, a bit of abstraction - I very often present this approach as a zoom on geo-maps, when in a first approximation a country is visible, in the second region, in the third city, etc.
As an example, consider this example:
- 1st approximation - the entire enterprise network is a set of different levels:
- core network or campus
- boundary level
- level of telecom operators
- remote zones
- 2nd approximation - each of these levels are detailed on separate modules
- core network or campus consists of:
- 3 or 2-level module that describes the enterprise network and its levels - access, distribution and / or core
- a module describing a data center - a data center (essentially the server part of the infrastructure)
- the boundary level in turn consists of:
- internet connection module
- WAN and MAN module, which is responsible for connecting geographically distributed objects of the enterprise
- module for building VPN tunnels and remote access access
- often many small enterprises have several of these modules, or even all of them, are combined in one
- provider level:
- This level includes communications “to the outside world” - dark optical fibers (fiber rental from operators), communication channels (Ethernet, G.703, etc.), Internet access.
- remote level:
- for the most part, these are branches of an enterprise that are distributed within a city, region, country, or even continents.
- this zone can also include a backup data center, which duplicate the work of the main
- and of course, teleworkers (remote workstations) gaining popularity lately
- 3rd approximation - each of the modules is split into smaller modules or levels. For example, on a campus network:
- 3-level network is divided into:
- access level
- distribution level
- core level
- Data center in more complex cases can be divided into:
- 2 or 3-level network part
- server side
I will try to display all of the above in the following simplified figure:

As can be seen from the figure above, the modular approach helps to detail and structure the overall picture into the constituent elements, which you can already work with in the future.
In this article, I will focus on the Campus Enterprise level and describe it in more detail.
Types of IP-Campus Networks
When I was working in a provider and especially later in the work of an integrator, I came across different “maturity” of customer networks. I do not use the term maturity for nothing, since quite often there are cases when the network structure grows with the growth of the company itself and this is in principle natural.
In a small company located within the same building, an enterprise network can consist of only 1 border router acting as a firewall, several access switches and a couple of servers.
I call such a network for myself a “one-tier” network - there is absolutely no explicit network core level in it, the distribution level is shifted to the border router (with firewall, VPN and possibly proxy functions), and access switches serve both employees' computers and the server.

In the case of enterprise growth - an increase in the number of employees, services and servers, often you have to:
- increase the number of switches in the network and access ports
- increase server capacity
- fight broadcast domains - implement network segmentation and inter-segment routing
- to deal with network failures that cause employee downtime, as this entails additional financial costs for management (the employee is idle, the salary is paid, but the work is not done)
- in the process of dealing with failures, think about reserving critical network nodes - routers, switches, servers and services
- tighten security policy, as commercial risks may arise and, again, for more stable network operation
All this leads to the fact that the engineer (network administrator) sooner or later thinks about the correct construction of the network and comes to a 2-level model.
This model already clearly distinguishes itself from 2 levels - the access level and the distribution level, which in combination is also the core level (collapsed-core).
The combined level of distribution and the kernel performs the following functions:
- aggregates links from access switches
- introduces the routing of network segments - there are so many users and devices that they do not fit on one network / 24, and if they are placed, broadcast storms cause permanent failures (especially if users help them by creating loops)
- provides communication between neighboring switch segments (via faster links)
- It provides communication between users and their devices and the server farm, which also by this time begins to stand out in a separate network segment - the data center.
- begins to provide, together with access switches, to one degree or another, the security policy that begins to appear in the enterprise by this time. The company is growing, commercial risks are also growing (here I mean not only provisions on trade secrets, differentiation of access policies, etc., but also on elementary downtimes of the network and employees).
Thus, the network sooner or later grows to a 2-level model:
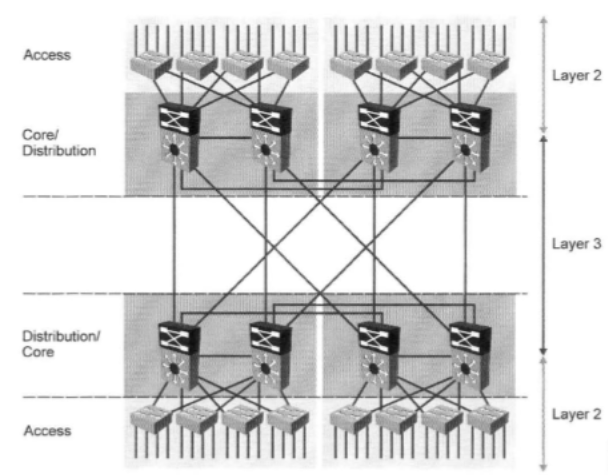
In this model, special requirements appear for both access level switches that aggregate links from users and network devices (printers, access points, VoIP devices, IP phones, IP cameras, etc.) and distribution level switches and kernels.
Access switches should already be more intelligent and functional to meet the requirements of network performance, security and flexibility, and should:
- have different types of access ports and trunk ports - preferably with the possibility of a margin for traffic growth, and the number of ports
- have sufficient switching capacity and bandwidth
- have the necessary security functionality that would satisfy the current security policy (and ideally, the growth of its further requirements)
- be able to power hard-to-reach network devices with the ability to remotely reboot them on power (PoE, PoE +)
- be able to reserve their own electrical power to use it in those places where it is necessary
- to have (if possible) a further growth potential of a functional is a frequent example when an access switch turns into a distribution switch over time
Distribution switches, in turn, are also subject to the following requirements:
- both in terms of trunk downstream ports towards access switches, and towards peer interfaces of neighboring distribution switches (and subsequently possible uplink interfaces towards the core)
- in terms of L2 and L3 functional
- in terms of security functionality
- in terms of ensuring fault tolerance (redundancy, clustering and redundancy of power supply)
- regarding flexibility in balancing traffic
- have (if possible) further functional growth potential (transformation over time of the aggregation device into the core)
- in some cases on distribution switches, it may be appropriate to use PoE, PoE + ports.
Further - more: if the company pursues a policy of active growth and development of the enterprise, the network will also continue to develop in the future - the company can begin to rent neighboring buildings, build its own buildings or absorb smaller competitors, thereby increasing the number of jobs for employees. At the same time, the network is also growing, which requires:
- providing employees with jobs - new access switches with access ports are needed
- availability of new distribution switches for link aggregation from access switches
- building new, as well as modernizing existing communication lines
As a result, there is an increase in traffic for the following reasons:
- due to the increase in access ports and, accordingly, network users
- due to the increase in traffic of related subsystems that choose the enterprise network for themselves as transport - telephony, security, engineering systems, etc.
- due to the introduction of additional services - with the growth of staff, new departments appear that require certain software
- data center computing capacity to meet infrastructure and application requirements
- security requirements for network and information are growing - the famous CIA triad (just kidding), but seriously, the CIA - Confidentiality, Integrity and Availability:
- in this regard, to the critical levels of the network - distribution and data center there are additional requirements for fault tolerance and redundancy
- Again, there is an increase in traffic due to the introduction of new security systems - for example, RKVI, etc.
Sooner or later, the growth of traffic, services and the number of users will lead to the need to introduce an additional layer of the network - the kernel, which will perform high-speed packet switching / routing using high-speed communication links.
At this point, the enterprise can move on to a 3-tier network model:
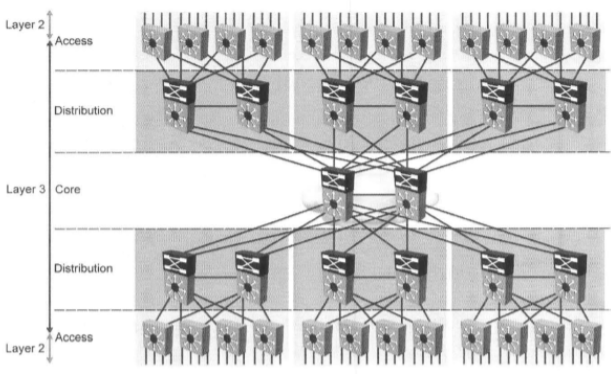
As you can see in the figure above - in such a network there is a core level that aggregates in itself high-speed links from distribution switches. Thus, kernel switches also have requirements for:
- interface bandwidth - 1GE, 2.5GE, 10GE, 40GE, 100GE
- switch performance (switching capacity and forwarding perfomance)
- interface types - 1000BASE-T, SFP, SFP +, QSFP, QSFP +
- number and set of interfaces
- redundancy options (stacking, clustering, redundancy of control cards (relevant for modular switches), redundancy of power supply, etc.)
- functional
At this level of the network, it is definitely necessary as its technical modification:
- Reservation of kernel nodes and links (very, very, very desirable)
- reservation of nodes and links of distribution level links (depending on criticality)
- reservation of communication links between access switches and distribution level (if necessary)
- dynamic routing protocol input
- balancing traffic both in the kernel and at the distribution and access levels (if necessary)
- introduction of additional services - both transport and security services (if necessary)
and legal, defining the network security policy of the enterprise, which complements the general security policy in terms of:
- requirements for the implementation and configuration of certain security functions on access and distribution switches
- requirements for access, monitoring and management of network equipment (remote access protocols allowed to manage network segments, logging settings, etc.)
- reservation requirements
- requirements for the formation of the minimum necessary spare parts set
In this section, I briefly described the evolution of the network and the enterprise from several switches and a couple of dozens of employees to several dozens (or maybe hundreds of switches) and several hundreds (or even thousands) of only those employees who work directly in the enterprise network (and after all there are also production departments and engineering networks).
It is clear that in reality such a “wonderful” and rapid development of the enterprise does not occur.
It usually takes years for an enterprise and network to grow from its initial 1st level to the 3rd described by me.
Why am I writing all these common truths? Then, what I want to mention here is a term such as ROI - return-on-investment (return / return on investment) and consider its side that relates directly to the choice of network equipment.
When choosing equipment, network engineers and their managers often choose equipment based on 2 factors - the current price of the equipment and the minimum technical functionality that is currently needed to solve a specific task or tasks (I will discuss the purchase of equipment for backup later).
At the same time, the possibilities of further "growth" of equipment are rarely considered. If a situation arises when the equipment exhausts itself in terms of functionality or productivity, then more powerful and functional is purchased in the future, and the old one is delivered to the warehouse, or somewhere to the network on the principle “to stay” (this, by the way, also causes a large zoo of equipment and procuring a bunch of information systems working with it).
Thus, instead of buying part of the licenses for add. functionality and performance, which are much cheaper than new, more high-performance equipment, you have to buy a new piece of hardware and overpay for the following reasons:
- the network often grows slowly and the expansion of functionality, or the performance of the switch of your network may last for a long time
- It is no secret that the equipment of foreign vendors is tied to foreign currency (dollar or euro). To be honest - the growth of the dollar or the euro (or the periodic mini-devaluation of the ruble, here's how to look) leads to the fact that the dollar 10 years ago and the dollar are now completely different things from the point of view of the ruble
Summarizing all the above, I want to note that buying network equipment with wider functionality now can lead to savings in the future.
Here, I consider the cost of purchasing equipment in the context of investing in my network and infrastructure.
Thus, many vendors (not only Extreme) adhere to the principle of pay-as-you-grow, laying in the equipment a bunch of functionality and opportunities to increase the productivity of interfaces, which are subsequently activated by the purchase of individual licenses. They also offer modular switches with a wide range of interface and processor cards, and the ability to gradually increase both their number and performance.
Critical Node Reservation
In this part of the article, I would like to briefly describe the basic principles of redundancy of such important network nodes as core switches, data centers, or distributions. And I want to start by looking at the general types of redundancy - stacking and clustering.
Each of the methods has its pros and cons, which I would like to talk about.
The following is a general summary table comparing 2 methods:
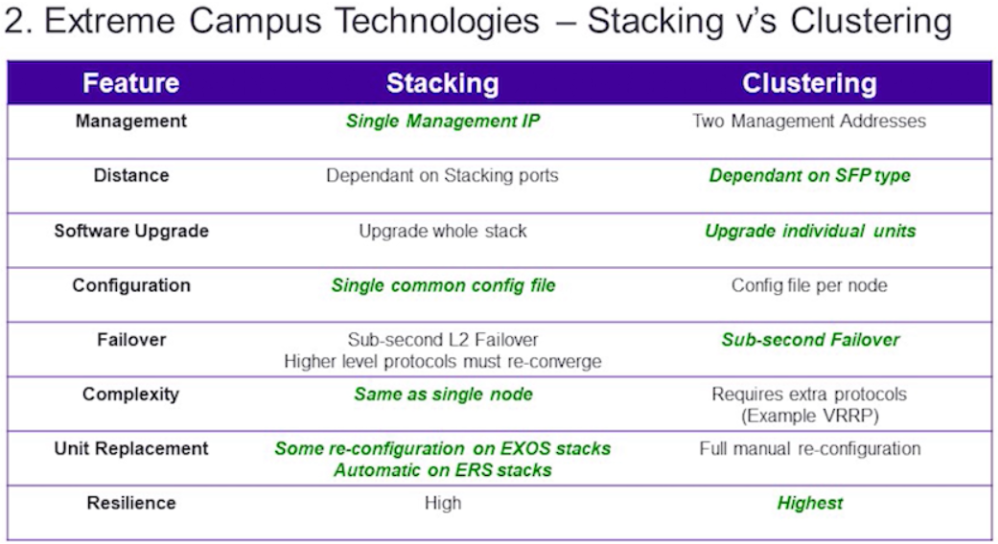
- management - as can be seen from the table, stacking is an advantage in this regard, since from the point of view of management, a stack of several switches is represented by one switch with a large number of ports. Instead of managing for example 8 different switches during clustering, you can only manage one when stacking.
- distance - at the moment, strictly speaking, the advantage in clustering is not so obvious, since there are technologies for stacking switches through stacking ports or dual-purpose ports (for example, SummitStack-V with Extreme, VSS with Cisco, etc.), which also depend on the types of transceivers. Here the advantage is given to clustering on the principle that when stacking there are options in which you have to use the usual stacking ports, which are often connected with special cables of a limited length - 0.5, 1, 1.5, 3 or 5 meters.
- software update - here we see that clustering has an advantage over stacking and the thing is the following - when updating the software version of the equipment during stacking, you update the software on the master switch, which later takes on the role of placing new software on the standby-member switches of the stack. On the one hand, this makes your work easier, but software updates often require a hardware reboot of the equipment, which leads to a reboot of the entire stack and thus interruption of its work and all services associated with it for a time = reboot time. This is usually very critical for the core and the data center. With clustering - you have 2 devices that are independent of each other, on which you can update the software sequentially one after another. At the same time, service interruptions can be avoided.
- configuration of settings - here the advantage is of course with stacking, since in the case and with management you need to edit the settings for only one device and its configuration file. In clustering, the number of configuration files will be equal to the number of cluster nodes.
- fault tolerance - here both technologies are approximately equal, but clustering nevertheless has a slight advantage. The reason here lies in the following - if we consider the stack from the point of view of running processes and protocols, then we will see the following:
- there is a master-switch on which all the main processes and protocols are running (for example, the dynamic routing protocol - OSPF)
- there are other slave-switch switches that run the basic processes necessary for working in the stack and serving the traffic passing through them
- if the switch master-switch fails, the next priority slave switch detects a master failure
- it initiates itself as a master and starts all the processes that worked on the master (including the OSPF protocol that we observe)
- after some time of starting processes (usually quite small), the OSPF protocol itself begins to work out
- thus, OSPF, when one of the nodes fails during clustering, will work a little faster than when stacking (for the time it takes to start and initialize processes and protocols on the slave switch of the stack). Although I must say that modern stacking protocols and switches work out very quickly, often the duration of a traffic break when switching a stack takes less than one second, but still nominally clustering wins by this parameter.
- complexity - as can be seen from the table, stacking wins in terms of complexity. This is a direct consequence of the “control” and “configuration settings” items. A single node takes much less time to configure and manage. Also, during clustering, quite often you have to configure additional routing protocols or gateway reservation protocols - VRRP, HSRP and others.
- replacement of nodes is a clear advantage for stacking. Very often, to replace the switch in the stack, it is necessary to carry out the minimum necessary equipment settings, for example:
- update the software of the new switch to the software version of the stack (and this can be done immediately when the switches enter the spare parts)
- configure several basic commands for stacking (and for some types of switches even this may not be required)
- pull out the failed stack switch and connect a new
- connect power and patch cords
- elasticity - I consider for myself as one of the main parameters. In general, elasticity is a complex characteristic, which means the property of something to change under the influence of a load and return to its original form after its disappearance. It is not strange for clustering, it will be higher even taking into account the score 4: 3 in terms of characteristics in favor of stacking. It's all about the human factor. Yes, do not be surprised - the power of such stacking parameters as a single control, configuration settings and lightweight complexity lies in the weakness of stacking when the human factor comes into play.
For my work in the field of IT, I have come across situations many times (but it’s a sin to hide and stepped on the same rake myself, especially at the beginning), when the engineer was mistaken in entering a command or turning on / off a particular functional when setting up the stack on equipment, which led to the failure of the entire stack and its manual reboot. Separately, it is worth mentioning Putty application lovers for Windows (oh this is right-click copying).
In fact, both technologies are pretty good (especially compared to the lack of redundancy) and each has its own strengths and weaknesses, but for the core level and for the high-loaded data center, I would still prefer to use clustering.
Although this is only my opinion. Many professional engineers who have been professionally supporting the network for many years can equally use both technologies - it all depends on experience and qualifications.
In addition to the technologies of stacking and reservation of network nodes, there are also general principles of reservation of parts of the network node itself and the connections between nodes:
By backup inside a host, I mean:
- redundancy of power supplies - installation of 2 power supplies that duplicate each other (moreover, it is desirable to be connected to the 1st category of power supply) can greatly simplify your life.
- redundancy of control cards - to a greater extent applies to modular switches, which provide for the connection of several duplicate control cards.
- interface card redundancy - also applies for the most part to modular switches.
By redundancy of links / links, it is mainly understood as the presence of overlapping cable routes (or radio links in the case of open spaces) with:
- distribution over different cable shafts and channels inside the building
- geographical distribution over the territory at the level of 2 or more buildings, a city, region or country (the so-called volumetric rings)
At the same time, when building backup communication links, it is necessary to observe a number of recommendations for equipment:
- in case of duplication of interface cards of a modular switch, or in the presence of a stack, it is necessary to distribute links between units - interface cards in the case of modular switches and switches in the case of a stack.
- It is advisable to use communication aggregation protocols (LACP, MLT, PAgP, etc.) to combine links into groups and balance the load between them.
- use routers supporting ECMP (Equal-Cost-Multi-Path) protocols - when several packets are delivered along the same route, these packets do not go through one best path (and interface) but are distributed over several best-path (and several interfaces), which are determined by the equality of the metrics of the routing protocol, which in turn is responsible for filling out the final routing table.
And now, as promised, I will describe the real case from my practice and the principle of saving when reserving critical nodes that occurred several years ago:
- in one company, I’ll call it X, there was a standard 3-level network model:
- with multiple cores
- dozens of aggregations
- several thousand access switches
- tens of thousands of users
- the network was rather complicated to build:
- with a bunch of dynamic routing protocols and protocols - OSPF, MP-BGP, MPLS, PIM, IGMP, IPv6, etc.
- a bunch of services - Internet access, L2 and L3 VPN, VoIP, IPTV, leased lines, etc.
- but there was one bottleneck in the network - the border router, which combined the functions of a BGP border and terminated some user services
- yes, it was like an airplane wing (several million rubles)
- Yes, at that time he was one of the top devices in the lineup of the most famous network vendor
- yes, it had to be very reliable - with excellent MTBF
- Yes, he had 4 power supplies assembled according to a 2x2 scheme and included from different UEPS and inputs.
But all this did not negate the fact that it was a single point of network failure.
And on one day, far from a wonderful day for me and my colleagues, this router ordered a long life (we later found out that there was some kind of failure on the power line through the UEPS, which led to the output of 2 power supplies at the same time and when this one of the blocks burned down the RP module of the router and the interface card, which were connected to the device’s common data bus).
We had no redundant boards - RP and interface card, but there was a contract for the replacement of equipment or its components with one of the partners under the NBD scheme.
Unfortunately, at that time the partners had only an interface card in stock, but there was no RP card, it arrived only after a few days (after 3 days).
As a result, the presence of a single point of failure in the network (even with a support contract and equipment replacement) resulted in the following financial costs:
- the share of company services attributable to or related to this border was about 60-70%
- as it was later calculated, the daily profit was about 900 thousand rubles (approximately) at that time
- Thus, in 3 days of downtime, theoretically, profits in the amount of 1 million 620 thousand rubles to 1 million 890 thousand rubles were lost
Of course, the net losses were less, since the compensation of the bulk of the users was returned not in the form of money, but in the form of services, but they were still:
- part of compensation to corporate users
- increased costs for employees who worked all these 3-4 days in full force - processing, night shifts, increased shifts, etc.
- reputation losses, which is also not unimportant
- and most importantly, the nerves of both management and employees as well as customers
As a result, the company policy was revised:
- refused a replacement contract under NBD
- left the usual service contract
- bought a backup router worth about 1 - 1.3 million rubles to reserve 90% of the main functionality
In the future, the purchase of additional equipment and redundancy of the main one made it possible to balance the load between the external links, traffic and users between them, and provided a safety margin for the company in further accidents.
Enterprise Network Design Example
In this part of the article I will try to state the main points in calculating the core network of the enterprise. I will not overload you with the entire PPDIOO methodology (Prepare-Planning-Design-Implement-Operate-Optimize), but I will only outline its main points:
- Prepare / Preparation - you need to decide on your leadership about the goals of network modernization that you want to achieve - increase fault tolerance, introduce new services or technologies. I will skip the definition of limitations - technical and organizational, as I assume that you are an employee of the organization and have a large margin in time to overcome them. I will return to the topic of the budget below.
- Planning - here you will need to build a full description of your current network (if you do not already know it), i.e. describe the network as it is now:
- quantity and type of equipment
- number and types of ports
- existing cable routes and switching schemes inside and between buildings
- power circuits
- L2 and L3 addressing
- build Wi-Fi network cards with access points and controllers
- describe your server farm
- It is desirable to describe all your services and the relationships between them.
- if you have already implemented in one form or another a policy of network security and differentiation of network access, be sure to take it into account when designing
- , , , , ( ). - . , . . operate.
- Design/ — , , - . .
, .
Prepare , :
- , 700-800 ( , )
- - :
- :
- :
- ( , ) :
- 2- L2:
- 1Gb RJ-45 — 24
- 1Gb SFP — 4
- 1- L2:
- —
- peer-to-peer
- :
- :
- L2 16 x 100 Mb RJ-45 2- combo- RJ-45/SFP
- :
- (hub-and-spoke — ) /
- /spoke — 3
- 9 ( )
- :
- :
- 2- 8
- 1- ( ) 8
- 1- . 4 ( )
- — /SMF
- 2- SFP
- (ODF) (-/),
- :
- :
- Cat5e — 10 ( 100 )
- /MMF 4 8 — 1
- /MMF 4
- Cat5e
- :
- L2, L3 :
- VLAN — 2,3
- /24
- B, — 172.16.0.0/16
- L3 /
- :
- :
- :
- :
- :
- , :
- N
- — , port-security 802.1.
- — , —
- — ,
- — , , , — , 1 ( ). — 3- .
- :
- DHCP - , STP .
- DHCP VLAN
- , /
- ...
Planning — , , . :
, :

, , :
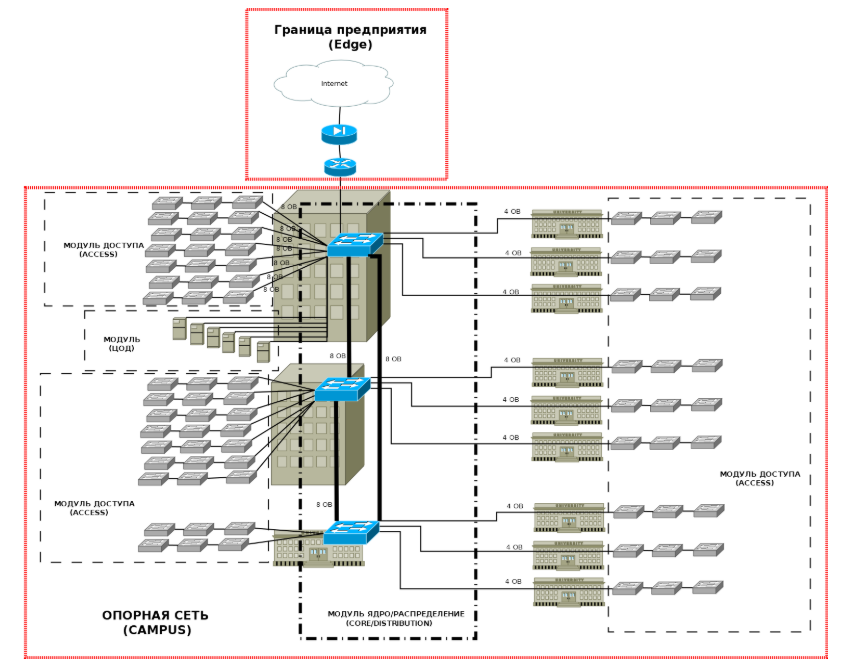
(Edge) , Campus:
- — :
- —
- VLAN
- VLAN
- QoS
- PoE
- IP multicast
- ()
- — :
- — :
- — :
.
—
, . .
—
:
:
- — 24- 48- , 1Gb uplink SFP PoE :
- 504 , spare , 2 — IP- .
- 48- PoE , :
- — 102 spare (22%) . — 25%.
- video monitoring
- — SFP 12 48 SFP+ 2- , , .
- — 12 24- SFP/SFP+ , MC-LAG. , . L3 ECMP 4 .
- — 8 24- SFP/SFP+ , MC-LAG.
Extreme
— . Extreme:
* — Extreme
, 2 , :
. :
( , 2- ) — 10 .
, 8 . What to do in this situation?
:
- — 1 — 1 1- 2 ( — 2 8 ). 1 SFP .
- — CWDM — . DWMD . SFP/SFP+ . — .
- .
. 2-10. :
- -, — 2 ( 4 )
- -, , MMF , SMF MMF ( 300-400 )
:
- SMF :
- :
- x440-G2 — 1 SMF , 6 3
- 2 . STP .
IP-
.
B — 172.16.0.0/16. IP :
- 4 — 172.16.0.0/12.
- 3 .
- 3 octets = 255 will be allocated for point-to-point links of equipment and the control network.
- one VLAN managment per floor for switch management.
- one user VLAN per switch (24 ports on average).
- one Voice VLAN per switch (average 24 ports).
- one VLAN for video surveillance system per floor.
- One vlan for Wi-Fi devices per floor.
I got something like the following tables:
network 172.16.0.0/14
network 172.20.0.0/14
In the table above, I gave an approximate separation of networks between buildings and floors on the one hand and networks (user, management, and service) on the other.
In fact, the choice of the gray network 172.16.0.0/12 is not the most optimal, since it limits us in the number of networks (from 16 to 31) for buildings, and there are also remote offices that also need to cut network blocks, possibly more optimal there will be an option using 10.0.0.0/8 networks, or sharing 172.16.0.0/12 networks (for example, for office needs and servers) and 10.0.0.0/8 (for user networks).
In general, the approach to the allocation of IP networks is also modular and it is advisable to adhere to the rules of summing subnets into one summary network at distribution levels, as well as at border routers in remote branches. This is done for several reasons:
- to minimize routing tables on routers
- to minimize the overhead of routing protocols (all kinds of update messages, if subnets are unavailable)
- to simplify administration and better readability of L3 networks
Although the first 2 points it is worth noting that the power of modern routers is much higher than those that were 15-20 years ago and allow you to contain large routing tables in your RAM, and the ratio of price and bandwidth of communication channels has decreased compared to with prices of times of general use of flows E1 / T1 (G.703).
Conclusion
Friends, in this article I tried to briefly talk about the basic principles of designing campus networks. Yes, there was quite a lot of material, and this despite the fact that I did not touch upon such topics as:
- organization of the enterprise border (and this is another story with its switches, borderboards, firewall, IPS / IDS systems, DMZ, VPN and other things)
- organization of Wi-Fi networks
- organization of VoIP networks
- data center organization
- security (and this is also its own separate world, which in terms of volume and requirements is not inferior to the design of a clean network infrastructure, and sometimes surpasses it)
- power engineering
- the list goes on and on
In fact, designing and building an enterprise network is a rather painstaking task, requiring a lot of time and resources.
But I hope my article will help you evaluate and understand at the initial level how to approach this task.
This is far from the last article on Extreme Networks , so stay tuned ( Telegram , Facebook , VK , TS Solution Blog )!