In the process of working on a large project, borrowing other people's modules and turnkey solutions saves a huge amount of developer time and investor money. One of the largest repositories of such solutions is by far github.
Under the cut is a little trick that I use when searching and choosing github solutions.
Imagine the task of developing a large
OSINT system, let's say we need to look at all the available solutions on github in this direction. we use the standard global github search for the osint keyword. We get 1124 repositories, the ability to filter by the location of the keyword search (code, commits, issuse, etc), by the execution language. And sort by various attributes (such as most / fewest starts, forks, etc).
The choice of solution is carried out according to several criteria: functionality, number of stars, project support, development language.
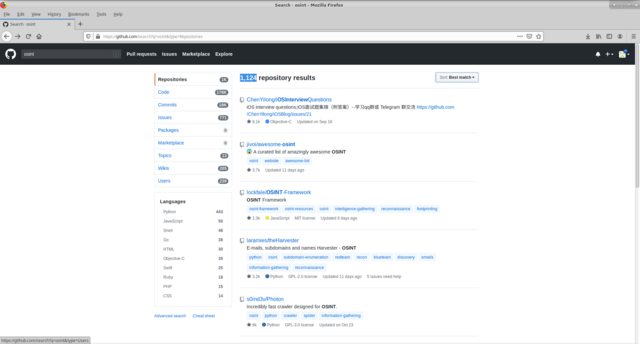
The decisions that interested me were summarized in a table, where the fields indicated above were filled in, appropriate notes were made based on the results of a particular test.
The lack of such a representation, it seems to me, is the lack of the ability to simultaneously sort and filter across multiple fields.
Using
api_github and python3 we outline a simple simple script that forms a csv document for us with the fields of interest to us.
Run the script
python3 git_repo_search.py osint
we get
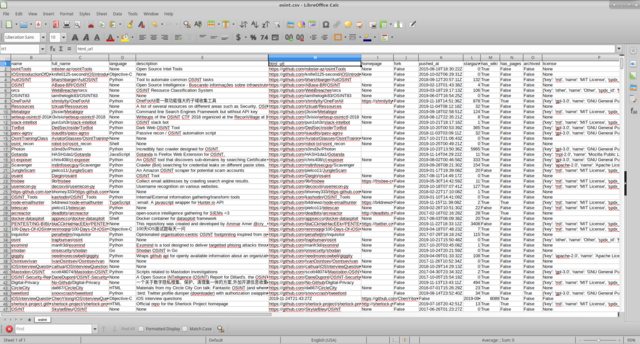
It seems to me that working with information is more convenient, having previously hidden unnecessary columns.
Code
hereI hope someone comes in handy.