The classic question that a developer comes to his DBA or a business owner, a PostgreSQL consultant, almost always sounds the same:
“Why are queries performed on the database for so long?”The traditional set of reasons:
- inefficient algorithm
when you decided to make a JOIN of several CTEs for a couple of tens of thousands of records - irrelevant statistics
if the actual distribution of data in the table is already very different from the last time ANALYZE collected - "Gag" by resources
and there is already not enough dedicated computing power of the CPU, gigabytes of memory are constantly pumped or the disk does not keep up with all the database “Wishlist” - blocking from competing processes
And if the locks are quite complicated in capturing and analyzing, then for everything else, we need
a query plan that can be obtained using
the EXPLAIN operator (
better, of course, immediately EXPLAIN (ANALYZE, BUFFERS) ... ) or
the auto_explain module .
But, as stated in the same documentation,
“Understanding a plan is an art, and to master it, you need some experience, ...”
But you can do without it, if you use the right tool!
What does a query plan usually look like? Something like that:
Index Scan using pg_class_relname_nsp_index on pg_class (actual time=0.049..0.050 rows=1 loops=1) Index Cond: (relname = $1) Filter: (oid = $0) Buffers: shared hit=4 InitPlan 1 (returns $0,$1) -> Limit (actual time=0.019..0.020 rows=1 loops=1) Buffers: shared hit=1 -> Seq Scan on pg_class pg_class_1 (actual time=0.015..0.015 rows=1 loops=1) Filter: (relkind = 'r'::"char") Rows Removed by Filter: 5 Buffers: shared hit=1
or like this:
"Append (cost=868.60..878.95 rows=2 width=233) (actual time=0.024..0.144 rows=2 loops=1)" " Buffers: shared hit=3" " CTE cl" " -> Seq Scan on pg_class (cost=0.00..868.60 rows=9972 width=537) (actual time=0.016..0.042 rows=101 loops=1)" " Buffers: shared hit=3" " -> Limit (cost=0.00..0.10 rows=1 width=233) (actual time=0.023..0.024 rows=1 loops=1)" " Buffers: shared hit=1" " -> CTE Scan on cl (cost=0.00..997.20 rows=9972 width=233) (actual time=0.021..0.021 rows=1 loops=1)" " Buffers: shared hit=1" " -> Limit (cost=10.00..10.10 rows=1 width=233) (actual time=0.117..0.118 rows=1 loops=1)" " Buffers: shared hit=2" " -> CTE Scan on cl cl_1 (cost=0.00..997.20 rows=9972 width=233) (actual time=0.001..0.104 rows=101 loops=1)" " Buffers: shared hit=2" "Planning Time: 0.634 ms" "Execution Time: 0.248 ms"
But reading the plan with the text “from the sheet” is very difficult and beloved:
- the node displays the sum of the subtree resources
that is, to understand how much time it took to execute a particular node, or exactly how much this reading from the table raised data from the disk - you need to somehow subtract one from the other - node time must be multiplied by loops
yes, subtraction is not the most difficult operation that needs to be done “in the mind” - after all, the runtime is indicated averaged for one node execution, and there may be hundreds - well, and all this together makes it difficult to answer the main question - so who is the “weakest link” ?
When we tried to explain all this to several hundred of our developers, we realized that from the outside it looks something like this:

And that means we need ...
Tool
In it, we tried to collect all the key mechanics that help according to the plan and request to understand "who is to blame and what to do." Well, share some of your experience with the community.
Meet and use -
explain.tensor.ruClear plans
Is it easy to understand a plan when it looks like this?
Seq Scan on pg_class (actual time=0.009..1.304 rows=6609 loops=1) Buffers: shared hit=263 Planning Time: 0.108 ms Execution Time: 1.800 ms
Not really.
But like this,
in abbreviated form , when key indicators are separated - it’s already much clearer:
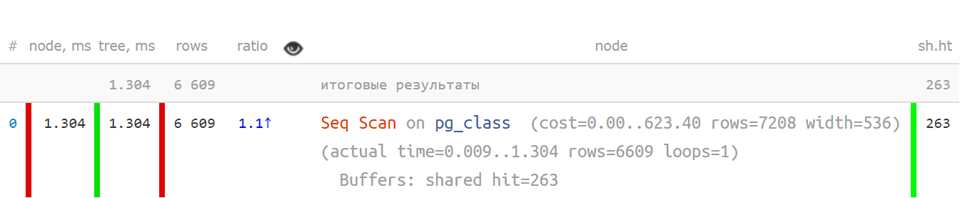
But if the plan is more complicated,
piechart time distribution by nodes will come to the
rescue :
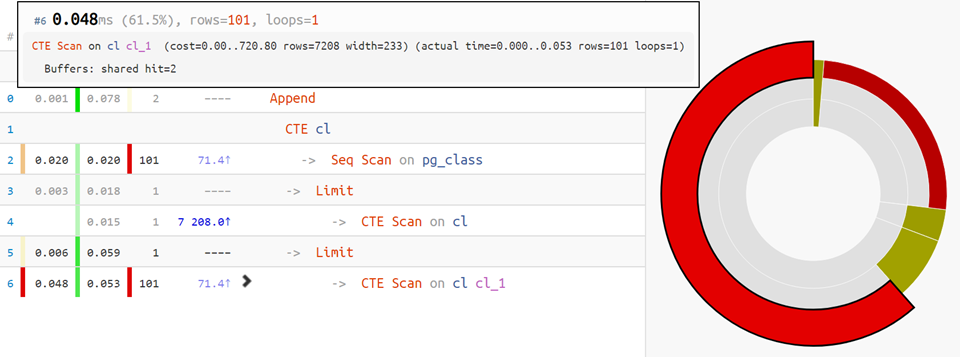
Well, for the most complex options,
the execution diagram hurries to help:
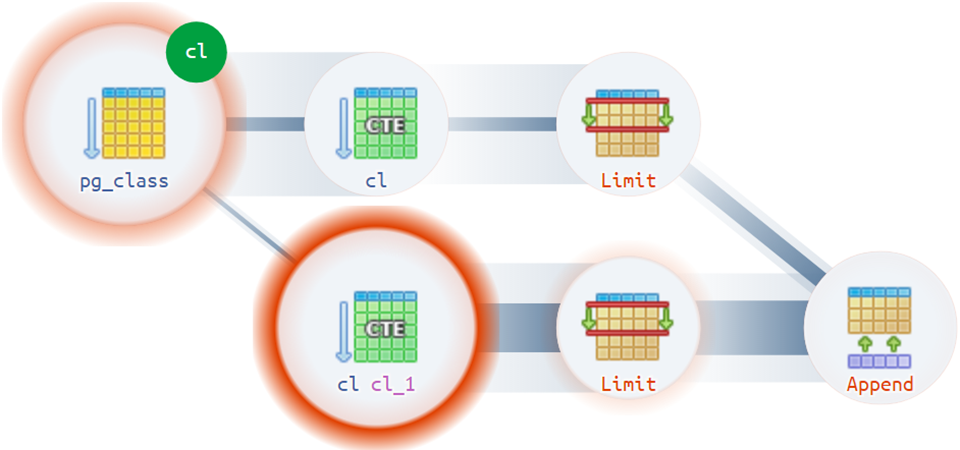
For example, there are quite non-trivial situations when a plan can have more than one actual root:
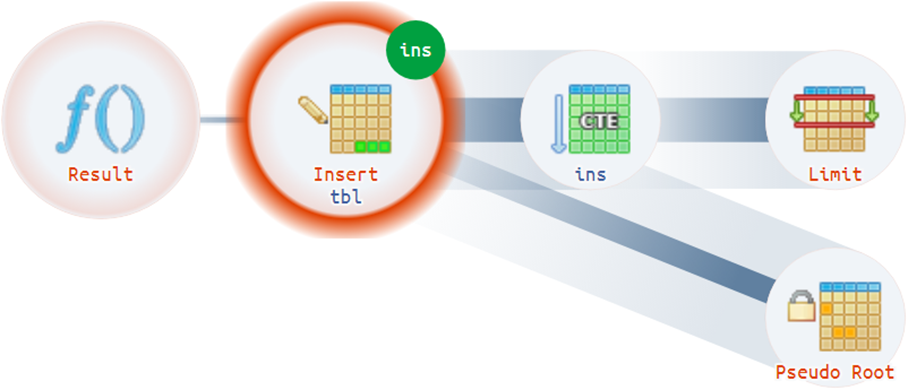
Structural Tips
Well, and if the entire structure of the plan and its sore spots are already laid out and visible - why not highlight them with the developer and explain them with the “Russian language”?

We have already collected a couple of dozen such recommendation templates.
Query profiler
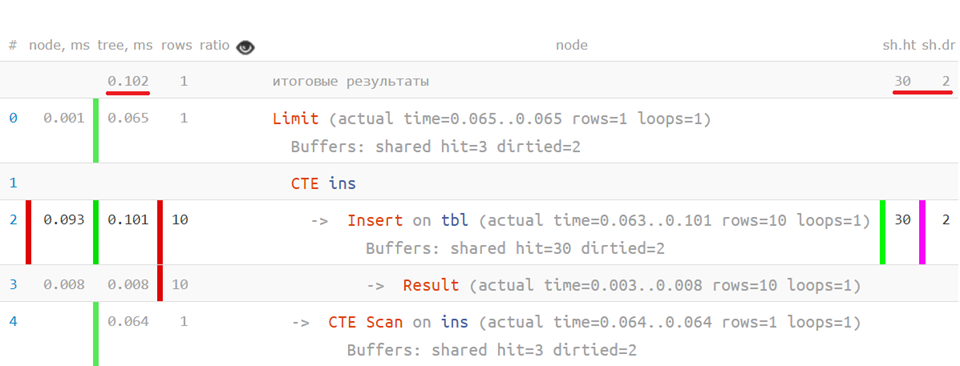
Now, if you put the original request on the analyzed plan, you can see how much time it took for each individual operator - something like this:
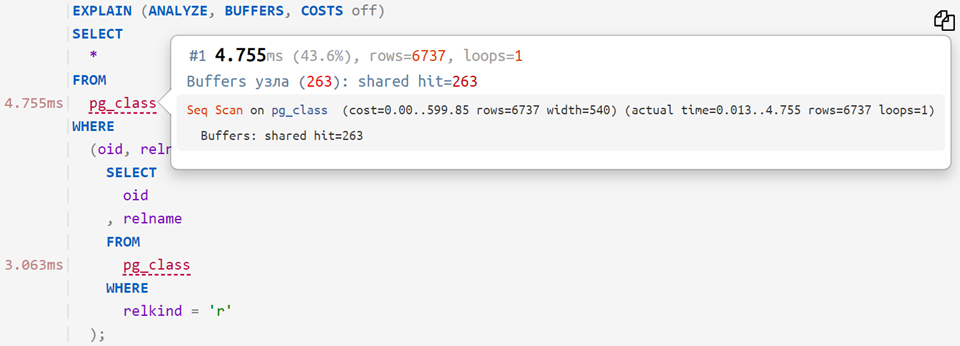
... or even so:

Substitution of parameters in the request
If you “attached” to the plan not only the request, but also its parameters from the DETAIL line of the log, you can copy it additionally in one of the options:
- with substitution of values in the request
for direct execution on its base and further profiling
SELECT 'const', 'param'::text;
- with value substitution via PREPARE / EXECUTE
to emulate the work of the scheduler when the parametric part can be ignored - for example, when working on partitioned tables
DEALLOCATE ALL; PREPARE q(text) AS SELECT 'const', $1::text; EXECUTE q('param'::text);
Archive of plans
Insert, analyze, share with colleagues! The plans will remain in the archive, and you can return to them later:
explain.tensor.ru/archiveBut if you do not want others to see your plan, do not forget to check the "do not publish in the archive" checkbox.
In the following articles I will talk about the difficulties and decisions that arise in the analysis of the plan.