फिलहाल, विशेष रूप से छवियों में मल्टीमीडिया संसाधनों की संख्या में हिमस्खलन जैसी वृद्धि देखी जा रही है। परिणामस्वरूप, ऐसे संसाधनों के आयोजन और खोज के साधनों के लिए आवश्यकताएं बढ़ रही हैं। वर्तमान में अधिकांश मौजूदा सिस्टम
विवरण द्वारा जानकारी खोजना (अंग्रेजी विवरण-आधारित छवि पुनर्प्राप्ति, DBIR), अब मानव आवश्यकताओं को पूरी तरह से संतुष्ट नहीं कर सकता है। इसलिए, सामग्री (Eng। सामग्री-आधारित छवि पुनर्प्राप्ति, CBIR) द्वारा वस्तुओं को खोजने में रुचि बढ़ रही है।
यह ध्यान दिया जाना चाहिए कि गतिविधि के कई क्षेत्रों में उपयोगकर्ता को मानव चेहरे की छवियों से निपटना पड़ता है: तेजी से विकासशील सामाजिक नेटवर्क से लेकर फॉरेंसिक के क्षेत्र तक। हालांकि सामान्य खोज और वर्गीकरण विधियाँ इस समस्या पर लागू होती हैं, इसके लिए समाधान की उच्च सटीकता की आवश्यकता होती है। इस तरह की आवश्यकता को चेहरे की संरचना की जटिलता और कई विवरणों द्वारा समझाया गया है, और कई विवरण जो सामान्य प्रकार के चेहरे (मोल्स, हेयर स्टाइल, चेहरे के बाल, आदि) को भेद करना मुश्किल बनाते हैं। यह स्वाभाविक है कि परिणाम की सटीकता की आवश्यकता चेहरे की खोज और मान्यता एल्गोरिदम की कम्प्यूटेशनल लागत में वृद्धि की ओर ले जाती है।
काफी बड़ी संख्या में तरीके हैं जो आपको चेहरों की छवियों को संसाधित करने की अनुमति देते हैं: स्वयं के व्यक्तियों, तंत्रिका नेटवर्क, आदि की विधि। उनमें से, हम छिपे हुए मार्कोव मॉडल के आधार पर एल्गोरिदम को अलग कर सकते हैं। यह विधि चेहरे की पहचान के कार्यों में कुछ उच्चतम परिणाम दिखाती है।
छिपे हुए मार्कोव मॉडल
मॉडलों के विचार पर आगे बढ़ने से पहले, हम विचार करते हैं कि मार्कोव श्रृंखला (मार्कोव प्रक्रिया) क्या है। यादृच्छिक चर
X n के अनुक्रम को
मार्कोव श्रृंखला कहा जाता है यदि:
P (X n = a | X n-1 = b, X n-2 = c, ..., X 0 = x) = P (X n - X = b) |
यह साबित होता है कि मार्कोव श्रृंखला आपको काफी सरल और ज्ञानवर्धक पेंटिंग बनाने की अनुमति देती है। उदाहरण के लिए, आप प्रत्येक राज्य के लिए नोड के साथ भारित निर्देशित ग्राफ और प्रत्येक किनारे पर एक भार गुणांक दर्शा सकते हैं, जो राज्यों के बीच संक्रमण की संभावना को दर्शाता है:
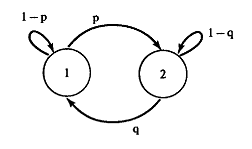
एक यादृच्छिक चर
X n का अवलोकन करते समय
, यह ज्ञात होता है कि सर्किट किस अवस्था में है। यह मॉडल, दुर्भाग्य से, बहुत सीमित है और यह कई दबाने वाली समस्याओं का समाधान नहीं दे सकता है। एक बेहतर मॉडल यह मानकर प्राप्त किया जा सकता है कि अनुक्रम के प्रत्येक तत्व के लिए एक अलग यादृच्छिक चर है जिसकी संभावना वितरण श्रृंखला की स्थिति पर निर्भर करता है - कुछ चर
Y n मनाया जाता है, और कुछ बिंदु
P (Y n | X n / s i ) = पर संभावना वितरण।
q i (Y n ) । ये तत्व मैट्रिक्स
Q में एकत्र किए जा सकते हैं
। इस तरह के मॉडल को
छिपे हुए मार्कोव मॉडल (एसएमएम) कहा जाता है। एसएमएम को निर्दिष्ट करने के लिए, राज्यों के बीच संक्रमण, राज्य के बीच संबंध और संभाव्यता वितरण सुनिश्चित करना आवश्यक है
Y n , और राज्यों के प्रारंभिक वितरण को भी जानते हैं।
छिपे हुए मार्कोव मॉडल के औपचारिक विवरण पर विचार करें। प्रत्येक मॉडल निम्नलिखित मापदंडों द्वारा निर्धारित किया जाता है:
- सेट S = {s 1 , s 2 , ..., s N } N राज्यों का।
- प्रारंभिक संभाव्यता वितरण P = {p i } है ।
- A = {a i } राज्यों के बीच संक्रमण की संभावनाओं की मैट्रिक्स।
- अवलोकन बी = {बी जे (ओ टी ) } उत्पन्न करने की संभावना मैट्रिक्स, जहां बी जे (ओ टी ) राज्य में समय टी में एक अवलोकन ओ टी पैदा करने की संभावना है क्यू टी = एस जे , बी जे (ओ टी ) = पी (ओ) t | q t = s j ) ।
यह ध्यान रखना महत्वपूर्ण है कि माना गया मॉडल एक आयामी है। बहु-आयामी मार्कोव मॉडल (छद्म-बहुआयामी एसएमएम) भी हैं। इस कार्य के ढांचे में, छद्म द्वि-आयामी मॉडल व्यावहारिक रुचि के हैं, क्योंकि मुख्य कार्य छवियों के साथ किया जाता है।
एम्बेडेड एसएमएम के प्रत्येक तत्व को एक
सुपरस्टेट कहा जाता है और ऊपर वर्णित मापदंडों के साथ एक अलग आयामी डायनोव मॉडल का प्रतिनिधित्व करता है।
मान्यता छवि
एक डिजिटल छवि सिस्टम द्वारा देखे गए एक यादृच्छिक द्वि-आयामी असतत संकेत का सार है। टिप्पणियों के अनुक्रम (ऑब्जर्वेशन वेक्टर) को विभिन्न तरीकों से छवि से निकाला जा सकता है। इस वजह से, परिणामस्वरूप मॉडल की वर्णनात्मक क्षमता भिन्न हो सकती है। सबसे पसंदीदा एक आयताकार खिड़की के साथ छवि को स्कैन करने का विकल्प है। ब्लॉक की सीमाओं पर डेटा हानि की संभावना को कम करने के लिए, छवि को स्कैन करने की सिफारिश की जाती है ताकि पिक्सल के आसन्न ब्लॉक एक-दूसरे को ओवरलैप कर सकें। ओवरलैप मान को प्रयोगात्मक रूप से चुना गया है।
कम्प्यूटेशनल जटिलता को कम करने और संकेतों के स्थान को कम करने के लिए, पिक्सल के प्रत्येक निकाले गए ब्लॉक में कुछ परिवर्तन होता है, जिसके परिणामस्वरूप संख्यात्मक डेटा का कुछ सेट होता है, जो अवलोकन वेक्टर है।
कार्य के लिए सबसे उपयुक्त दो परिवर्तन हैं:
- करुनेन-लोवे ट्रांसफ़ॉर्म (अंग्रेज़ी करहुनेन-लोव ट्रांस्फ़ॉर्म - एब्बर। KLT);
- असतत कोसाइन ट्रांसफॉर्म
रूपांतरण - सार। डीसीटी)।
KLT रूपांतरण में काफी समय लगता है और इसके लिए बड़े कंप्यूटिंग संसाधनों की आवश्यकता होती है। असतत कोसाइन परिवर्तन इन कमियों से रहित है। इसके अलावा, डीसीटी आपको सिस्टम की संवेदनशीलता को शोर, परिवर्तनों और विकृतियों को कम करने की अनुमति देता है। पिक्सल के प्रत्येक ब्लॉक को निकालने के बाद, उनमें से प्रत्येक को असतत कोसाइन रूपांतरण का उपयोग करके वेक्टर
एफ में परिवर्तित किया जाता है। इस वेक्टर की लंबाई महत्वपूर्ण गुणांक की संख्या है। केवल असतत कोसिन विस्तार के पहले कुछ गुणांक को महत्वपूर्ण कहा जाता है। समस्या हल होने के आधार पर उनकी संख्या भिन्न हो सकती है।
इसके अलावा, प्राप्त वैक्टर मॉडल राज्यों के अनुसार वितरित किए जाते हैं। यहां यह ध्यान दिया जाना चाहिए कि प्रत्येक व्यक्ति एसएमएम वस्तुओं की एक निश्चित श्रेणी का प्रतिनिधित्व करता है। तब मॉडल राज्यों को कक्षा की कुछ प्रमुख विशेषताओं द्वारा निर्धारित किया जाता है। उदाहरण के लिए, चेहरे की खोज के लिए एक एसएमएम में चेहरे (ललाट भाग, आंखें, नाक, मुंह, ठोड़ी) के क्षेत्रों के अनुरूप 5 सुपरस्टेट्स होते हैं, जिनमें से प्रत्येक को अलग-अलग राज्यों में विभाजित किया जाता है।
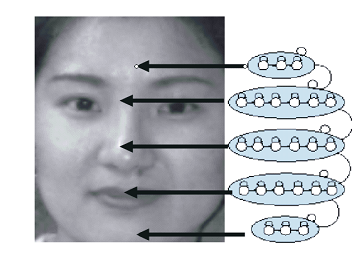
अगले राज्य के लिए संक्रमण पिछले एक के बाद ही संभव है, और अगले सुपरस्टेट के लिए संक्रमण वर्तमान सुपरस्टेट के सभी राज्यों के बाद ही संभव है। एक निश्चित श्रेणी से संबंधित एक निश्चित वस्तु की संभावना को उसके फीचर वेक्टर के अनुरूप सिग्नल उत्पन्न करने की संभावना के रूप में अनुमानित किया जाता है।
चेहरे की खोज
हम मानते हैं कि संग्रह में छवियों के बारे में जानकारी किसी तरह के संबंधपरक डेटाबेस में संग्रहीत है। अमूर्त के विभिन्न स्तरों पर छवियों की सामग्री को परिभाषित किया जा सकता है। सबसे निचले स्तर पर, एक छवि पिक्सेल का एक सेट है। खोज कार्य में पिक्सेल स्तर का उपयोग शायद ही कभी किया जाता है, क्योंकि इसमें बहुत अधिक कम्प्यूटेशनल और समय लगता है।
विशेष रूप से दृश्य विशेषताओं का वर्णन करने वाले संख्यात्मक विवरणों को उत्पन्न करने के लिए कच्चे डेटा भेजे जा सकते हैं जिन्हें
हस्ताक्षर कहा जाता
है । आमतौर पर, एक छवि हस्ताक्षर स्तर को एक छवि की तुलना में बहुत कम जगह की आवश्यकता होती है।
छवि खोज बहुआयामी अंतरिक्ष में समानता की खोज पर आधारित है। इस मामले में, छवि अपने हस्ताक्षर के सेट से निर्धारित होती है। एक समानता माप एक ऐसा फ़ंक्शन है जो कुछ पूर्वनिर्धारित मानदंडों के अनुसार दो वस्तुओं के बीच समानता के अनुरूप मूल्य की गणना और रिटर्न करता है। समानता की माप की अवधारणा एक
मीट्रिक की अवधारणा पर आधारित है। एक मीट्रिक किसी भी बिंदु
x, y, z के लिए मीट्रिक सेट पर निर्धारित दूरी
d का एक कार्य है
शर्तें पूरी होती हैं:
1।

।
2।
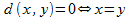
।
3।

।
संग्रह में छवियों को अनुक्रमित करना और खोजना
त्रिकोण ट्री (ट्री ट्री) पर आधारित है, जिसे वास्तव में फिक्स्ड क्वेरी ट्री भी कहा जाता है। त्रिकोणीय पेड़ एक डेटा संरचना है जिसे खोज प्रयासों के आधार पर अनुमानित मैचों को खोजने के लिए डिज़ाइन किया गया है। यह एक दूरी माप, कुंजी छवियों का एक सेट और डेटाबेस तत्वों के एक सेट के साथ जुड़ा हुआ है। त्रिक आकार एक पेड़ के आकार का होता है जिसमें पसलियां जड़ से लेकर पत्ती के सूचकांक का निर्धारण करती हैं। पेड़ की पत्तियों में आधार के तत्व होते हैं। पेड़ में प्रत्येक आंतरिक किनारे एक गैर-नकारात्मक संख्या के साथ जुड़ा हुआ है। पेड़ का प्रत्येक स्तर एक कुंजी के साथ जुड़ा हुआ है। रूट से पत्तियों तक का मार्ग डेटाबेस आइटम से प्रत्येक कुंजी की दूरी है।
आंकड़ा 4 तत्वों (
डब्ल्यू ,
एक्स ,
वाई , जेड) और 2 कुंजी (
जे ,
के ) के साथ एक त्रिकोणीय पेड़ दिखाता है। शीट
W से कुंजी
J की दूरी 3 है,
W से
K की दूरी 1 है। इस प्रकार, प्रत्येक छवि को संख्यात्मक मानों के एक निश्चित सेट की विशेषता होगी, इस छवि से मौजूदा कुंजियों तक की दूरी के रूप में परिभाषित किया गया है।
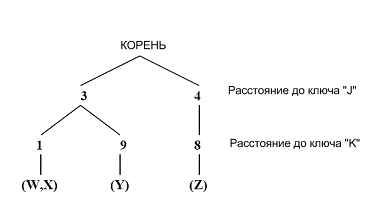
एक संग्रह में छवियों को अनुक्रमित करने की प्रक्रिया प्रत्येक छवि से प्रत्येक कुंजी के लिए दूरी खोजने के लिए है। पूर्वगामी के आधार पर, खोज सिद्धांत को निम्नानुसार निर्धारित करना संभव है। आइए
मैं एक आधार वस्तु का प्रतिनिधित्व करता
हूं ,
क्यू एक क्वेरी ऑब्जेक्ट का प्रतिनिधित्व करता है,
कश्मीर कुंजी छवियों का प्रतिनिधित्व करता है, और
डी समानता के कुछ उपायों को परिभाषित करता है - मीट्रिक। मीट्रिक (3) की संपत्ति का उपयोग करते हुए, हम यह निष्कर्ष निकालते हैं कि निम्नलिखित असमानताएँ सच होंगी:

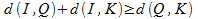
असमानताओं को जोड़ते हुए, हम एक अभिव्यक्ति प्राप्त करते हैं जो अनुरोध वस्तु से संग्रह वस्तु तक की दूरी निर्धारित करती है:
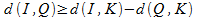
इस प्रकार, डेटाबेस से ऑब्जेक्ट्स की तुलना करना और ऑब्जेक्ट्स को तीसरी कुंजी ऑब्जेक्ट के साथ तुलना करना, दो ऑब्जेक्ट्स के बीच की दूरी की निचली सीमा प्राप्त की जा सकती है। इस सीमा के आधार पर, आप अनुरोध को पूरा नहीं करने के रूप में अधिकांश संग्रह को काट सकते हैं।
यह भी ध्यान दिया जाना चाहिए कि खोज प्रक्रिया दो चरणों में होती है। पहले चरण में, अनुरोध छवि से संग्रह छवियों तक की दूरी की निचली सीमा निर्धारित की जाती है। इस स्तर पर, संग्रह का हिस्सा क्लिप किया जाता है। दूसरे चरण में, एक शोधन खोज होती है: पहले चरण में पाए जाने वाले प्रत्येक छवि से अनुरोध छवि से दूरी निर्धारित की जाती है। अधिकतम दूरी के अनुरूप छवियां अंतिम खोज परिणाम बनाती हैं।
पूर्वगामी के आधार पर, हम यह निष्कर्ष निकाल सकते हैं कि प्रत्येक छवि के लिए खोज और अनुक्रमण का उपयोग करने के लिए, आपको निम्नलिखित क्रियाएं करने में सक्षम होना चाहिए।
- छवि हस्ताक्षर हाइलाइट करें। एकल छवियों के लिए, हस्ताक्षर उस पर निहित प्रत्येक चेहरे के अवलोकन वैक्टर होंगे
- मुख्य हस्ताक्षर हाइलाइट करें। इसके अलावा, एसएमएम पर आधारित एक खोज प्रणाली के लिए, चाबियाँ एक व्यक्ति की छवियों के सेट और इन छवियों के लिए प्रशिक्षित मॉडल के हस्ताक्षर पैरामीटर होंगे।
- कुंजी और छवि हस्ताक्षर और साथ ही दो छवियों की तुलना करें। इस मामले में, तुलना का परिणाम अंतर होना चाहिए, एक पूर्णांक के रूप में व्यक्त किया गया, अंतराल में झूठ बोलना [0; 99]।
छिपे हुए मार्कोव मॉडल का उपयोग करते हुए चेहरे की खोज करते समय मुख्य समस्या यह है कि इन मॉडलों पर आधारित तरीकों के साथ, वे केवल छवि मॉडल की अनुरूपता का आकलन करते हैं। दूसरे शब्दों में, यह अनुमान आपको यह तय करने की अनुमति देता है कि कौन सा मॉडल दूसरों की तुलना में छवि से अधिक मेल खाता है।
दूसरी समस्या यह है कि इस स्तर पर दो अलग-अलग छवियों के बीच की दूरी का पता लगाने के लिए एसएमएम का उपयोग करना संभव नहीं है। ऐसा इसलिए है क्योंकि खोज एल्गोरिदम को एक प्रशिक्षित मॉडल की आवश्यकता होती है: एक छवि में एक मॉडल को प्रशिक्षित करना समस्याग्रस्त है।
लेख तैयार करने में, निम्नलिखित सामग्रियों का उपयोग किया गया था:
- नेफियन, एवी हिडन मार्कोव मैडल-आधारित दृष्टिकोण चेहरे का पता लगाने और मान्यता / आरा नेफियन के लिए। 1999।
- जोसन, ओ.वी. चेहरे की छवियों में आईरिस का पता लगाने के लिए छिपे हुए मार्कोव मॉडल का उपयोग: 2006 / ए.वी. जोसन, मॉस्को स्टेट यूनिवर्सिटी लोमोनोसोव। - 2006।
- गुल्तियावा, टी। ए। चेहरे की पहचान की समस्या / T.A में वन-आयामी टोपोलॉजी वाले छिपे हुए मार्कोव मॉडल। गुल्तियावा, ए.ए. पोपोव; NSTU। - 2006।
- बर्मन, एपी एक फ्लेक्सिबल इमेज डेटाबेस सिस्टम फॉर कंटेंट-बेस्ड रिट्रीवल: कंप्यूटर विजन एंड इमेज अंडरस्टैंडिंग / एपी बर्मन, एलजी पपीरो। 1999।