दुर्भाग्य से, इतने सारे पदों की गणना से शतरंज के लिए कोई बेहतर एल्गोरिदम नहीं हैं। सच है, क्रम में खोज (और एक नहीं) अनुकूलित है, लेकिन फिर भी यह एक बड़ी खोज है। प्रतिक्रिया चाल के लिए खोज करने के लिए, जड़ में प्रारंभिक चाल के साथ एक पेड़ का निर्माण किया जाता है, किनारों - उत्तर चाल और नोड्स - नए स्थान।
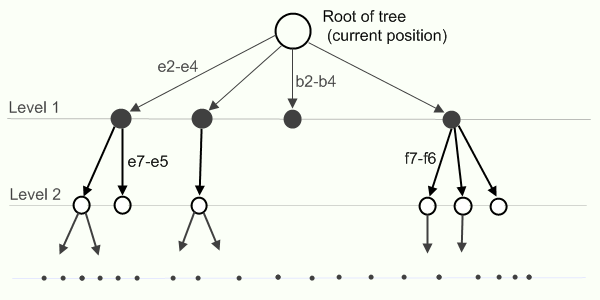
प्राथमिक एल्गोरिदम में अगला कदम कैसे चुनना है, यह स्पष्ट करना आसान है। अपनी बारी में, आप उस चाल (अपनी राय में) का चयन करते हैं जो सबसे बड़ा लाभ लाएगा (आपके लाभ को अधिकतम करता है), और आपके अगले कदम पर प्रतिद्वंद्वी उस कदम को चुनने की कोशिश करता है जो उसे सबसे अधिक लाभ लाएगा (उसके लाभ को अधिकतम करता है और आपका कम से कम करता है)। इस सिद्धांत के साथ एक एल्गोरिथ्म को मिनिमैक्स कहा जाता है। प्रत्येक चरण में, आप पेड़ में प्रत्येक नोड (उस पर बाद में) के लिए एक स्थिति अनुमान लगाते हैं और इसे अपने पाठ्यक्रम के दौरान अधिकतम करते हैं, और दुश्मन के दौरान इसे कम करते हैं। ऑपरेशन के दौरान, एल्गोरिथ्म को पेड़ के सभी नोड्स (जो कि गेम के सभी संभावित गेम पोजीशन पर) के माध्यम से जाना चाहिए, यानी यह समय के लिए पूरी तरह से अनुपयुक्त है।
उनका अगला सुधार अल्फा बीटा क्लिपिंग (शाखा और बाध्य विधि) है।
नाम से यह निम्नानुसार है कि एल्गोरिथ्म कुछ दो मापदंडों के अनुसार कटिंग करता है - अल्फा और बीटा। कतरन का मुख्य विचार यह है कि अब हम कतरन अंतराल (निचली और ऊपरी सीमाएँ - अल्फा और बीटा, क्रमशः - आपका के। ओ।) रखेंगे और सभी नोड्स के अनुमान जो नीचे के अंतराल में नहीं आते हैं, हम विचार नहीं करेंगे (क्योंकि वे नहीं करते हैं) परिणाम को प्रभावित करें - यह पहले से ही पाया गया सबसे खराब चाल है), और हम अंतराल को संकीर्ण कर देंगे क्योंकि हम सबसे अच्छी चाल पाते हैं। हालांकि अल्फा-बीटा क्लिपिंग मिनिमिक्स की तुलना में काफी बेहतर है, लेकिन इसका रनटाइम भी बहुत लंबा है। यदि हम मानते हैं कि खेल के बीच में एक तरफ लगभग 40 अलग-अलग चालें हैं, तो एल्गोरिथ्म के समय का अनुमान ओ (40 ^ पी) के रूप में लगाया जा सकता है, जहां पी चाल पेड़ की गहराई है। बेशक, मिनिमैक्स के साथ चाल पर विचार करने का ऐसा क्रम हो सकता है, जब हम कोई कटौती नहीं करेंगे, तो अल्फा-बीटा कटऑफ बस मिनिमैक्स में बदल जाएगी। सबसे अच्छा मामले में, अल्फा-बीटा क्लिपिंग का उपयोग करके, आप मिनिमैक्स में सभी चालों की जड़ की जांच करने से बच सकते हैं। लंबे समय तक काम करने से बचने के लिए (एल्गोरिथ्म के इस तरह के ओ-महान जटिलता के साथ), पेड़ में खोज कुछ निश्चित मूल्य के लिए की जाती है और वहां नोड का मूल्यांकन किया जाता है। यह आकलन नोड के वास्तविक मूल्यांकन के लिए एक बहुत बड़ा अनुमान है (यानी, पेड़ के अंत तक चलने वाला, और वहाँ परिणाम "जीत, हार, ड्रा" है)। नोड मूल्यांकन के लिए, बस विभिन्न तकनीकों का ढेर है (आप लेख के अंत में लिंक में पढ़ सकते हैं)। संक्षेप में - स्वाभाविक रूप से, मैं खिलाड़ी की सामग्री की गिनती कर रहा हूं (एक प्रणाली के अनुसार, पूर्णांक प्यादा - 100, नाइट और बिशप - 300, रूक - 500, रानी - 900; अन्य प्रणाली के अनुसार - इस के बोर्ड में एक + स्थिति के कुछ हिस्सों में मान्य) प्लेयर। स्थिति के अनुसार - यहाँ लेखन शतरंज की एक बुरे सपने की शुरुआत होती है, क्योंकि कार्यक्रम की गति मुख्य रूप से मूल्यांकन कार्य पर और, अधिक सटीक रूप से, स्थिति के मूल्यांकन पर निर्भर करेगी। यहां पहले से ही कोई है जो इतना है। खिलाड़ी + के लिए एक युग्मित दौर के लिए, अपने पंजे के साथ राजा के कवर के लिए +, बोर्ड के दूसरे छोर के पास एक प्यादा के लिए, आदि, और टुकड़ों को लटकाते हुए, एक खुला राजा, आदि, स्थिति को घटाता है। आदि - आप कारकों का एक गुच्छा लिख सकते हैं। यहां, खेल में स्थिति का आकलन करने के लिए, खिलाड़ी की स्थिति का एक आकलन किया जाता है, जो एक चाल बनाता है, और प्रतिद्वंद्वी की संबंधित स्थिति का मूल्यांकन इससे दूर ले जाता है। जैसा कि वे कहते हैं, एक तस्वीर कभी-कभी एक हजार शब्दों से बेहतर होती है, और शायद छद्म सी # में कोड का एक टुकड़ा भी स्पष्टीकरण के लिए बेहतर होगा:
enum CurentPlayer {Me, Opponent}; public int AlphaBetaPruning (int alpha, int beta, int depth, CurrentPlayer currentPlayer) {
मुझे लगता है कि कोड के बारे में कुछ स्पष्टीकरण बेमानी नहीं होंगे:
- GetOppositePlayerTo () बस CurrentPlayer को बदल देता है। CurrentPlayer को ले लीजिए। घटक और इसके विपरीत
- मेकमोव () चालों की सूची से अगला कदम बनाता है
- प्लाई - एक वैश्विक चर (वर्ग का हिस्सा) जो किसी दिए गए गहराई पर किए गए आधे चालों की संख्या रखता है
विधि का उपयोग करने का एक उदाहरण:
{ ply = 0; nodesSearched = 0; int score = AlphaBetaPruning (-MateValue, MateValue, max_depth, CurrentPlayer.Me); }
जहां MateValue काफी बड़ी संख्या है।
Max_depth पैरामीटर अधिकतम गहराई है जो एल्गोरिथ्म पेड़ में उतरेगा। यह ध्यान में रखा जाना चाहिए कि स्यूडोकोड शुद्ध रूप से प्रदर्शनकारी है, लेकिन काफी काम कर रहा है।
एक नए एल्गोरिथ्म के साथ आने के बजाय, अल्फा-बीटा क्लिपिंग को बढ़ावा देने वाले लोग कई अलग-अलग उत्तराधिकार के साथ आए। Heuristics बस एक छोटी सी हैक है जो कभी-कभी गति में बहुत बड़ा लाभ बनाती है। शतरंज के लिए बहुत सारे आंकड़े हैं, आपने उन सभी की गणना नहीं की है। मैं केवल मुख्य वाले को दूंगा, बाकी लेख के अंत में लिंक में पाए जा सकते हैं।
सबसे पहले, बहुत प्रसिद्ध
"शून्य चाल" अनुमानी का
उपयोग किया जाता है । एक शांत स्थिति में, दुश्मन को एक के बजाय दो चालें बनाने की अनुमति है, और उसके बाद वे पेड़ की गहराई (गहराई -2) की जांच करते हैं, और गहराई (-1) नहीं। यदि, इस तरह के एक उप-योग का मूल्यांकन करने के बाद, यह पता चलता है कि वर्तमान खिलाड़ी को अभी भी एक फायदा है, तो आगे उप-विचार करने का कोई मतलब नहीं है, क्योंकि उसके अगले कदम के बाद खिलाड़ी केवल अपनी स्थिति को बेहतर बनाएगा। चूंकि खोज बहुपद है, इसलिए गति में लाभ ध्यान देने योग्य है। कभी-कभी ऐसा होता है कि दुश्मन उनके लाभ को बराबर करेगा, फिर आपको अंत तक पूरे उपप्रकार पर विचार करने की आवश्यकता है। एक खाली चाल हमेशा नहीं की जानी चाहिए (उदाहरण के लिए, जब राजाओं में से एक चेक के नीचे, एक ज़ुग्ज़वांग में या एक एंडगेम में होता है)।
इसके अलावा, इस विचार का उपयोग पहले एक चाल बनाने के लिए किया जाता है जिसमें प्रतिद्वंद्वी के टुकड़े पर कब्जा होगा, जिसने अंतिम चाल बनाई। चूंकि खोज के दौरान लगभग सभी चालें
मूर्खतापूर्ण नहीं हैं, इसलिए ऐसा विचार शुरुआत में खोज विंडो को बहुत कम कर देगा, जिससे अनावश्यक अनावश्यक चालें कट जाएंगी।
यह भी ज्ञात है कि
इतिहास की सबसे बड़ी चाल या
सर्वश्रेष्ठ चाल की
सेवा है । खोज के दौरान, पेड़ के दिए गए स्तर पर सबसे अच्छी चालें बचाई जाती हैं, और जब किसी स्थिति पर विचार किया जाता है, तो आप पहली बार किसी दिए गए गहराई के लिए इस तरह की चाल बनाने की कोशिश कर सकते हैं (इस विचार के आधार पर कि पेड़ में समान गहराई पर समान सर्वोत्तम चालें अक्सर बनाई जाती हैं)।
यह ज्ञात है कि चालों के इस तरह के अजीब कैशिंग ने सोवियत कैस कार्यक्रम की उत्पादकता में 10 गुना सुधार किया।
चाल उत्पन्न करने के लिए कुछ विचार भी हैं। पहले, जीतने वाले कैप्चर को माना जाता है, अर्थात्, ऐसे कैप्चर जब एक कम स्कोर वाला एक टुकड़ा एक उच्च स्कोर के साथ एक टुकड़ा हिट करता है। तब वे पदोन्नति पर विचार करते हैं (जब बोर्ड के दूसरे छोर पर एक मोहरे को एक मजबूत टुकड़े द्वारा प्रतिस्थापित किया जा सकता है), तो बराबर लेता है और फिर इतिहास के कैश से चलता है। बाकी चालों को बोर्ड या किसी अन्य कसौटी पर नियंत्रण करके हल किया जा सकता है।
अगर अल्फा-बीटा क्लिपिंग की गारंटी बेहतर है तो बेहतर जवाब मिलेगा। यहां तक कि खोज करने के लिए लंबे समय पर विचार करना। लेकिन यह वहाँ नहीं था। समस्या यह है कि एक निश्चित मूल्य के अनुसार छंटनी के बाद, स्थिति का मूल्यांकन किया जाता है और यह सब, लेकिन जैसा कि यह निकला, कुछ गेम स्थितियों में आप खोज बंद नहीं कर सकते। कई प्रयासों के बाद, यह पता चला कि खोज को केवल शांत स्थितियों में रोका जा सकता है। इसलिए, मुख्य गणना में, एक अतिरिक्त गणना को जोड़ा गया था, जो केवल कब्जा, पदोन्नति और शा (जिसे
मजबूर गणना कहा जाता है) पर विचार करता है। हमने यह भी देखा कि बीच में एक विनिमय के साथ एक निश्चित स्थिति को भी गहरा माना जाना चाहिए। इसलिए
विस्तार और
कटौती के बारे में विचार थे, अर्थात्, भर्ती और कम करने वाले वृक्ष। गहरीकरण के लिए, सबसे उपयुक्त स्थिति, पिवन्स के साथ एंडगेम की तरह हैं, चेक से दूर, खोज के बीच में एक टुकड़ा बदलते हुए, आदि। "लघु पदों को छोटा करने के लिए उपयुक्त हैं। कैस के सोवियत कार्यक्रम में, जबरन पर्दाफाश करना थोड़ा विशेष था - वहाँ, भंडाफोड़ के दौरान लेने के बाद, जबरन पर्दाफाश तुरंत शुरू हो गया और इसकी गहराई सीमित नहीं थी (कुछ समय के लिए वह खुद को एक शांत स्थिति में समाप्त कर देगा)।
जैसा कि
एंथनी होयर ने कहा: "
समयपूर्व अनुकूलन प्रोग्रामिंग में सभी बुराई की जड़ है। " (नोट: उन लोगों के लिए जो मानते हैं कि यह उद्धरण नॉट का है,
यहां और
यहां दिलचस्प चर्चाएं
हैं )। शतरंज में, जहां पुनरावृत्ति की अपेक्षाकृत बड़ी गहराई होगी, आपको अनुकूलन के बारे में सोचने की जरूरत है, लेकिन बहुत सावधानी से।
यहाँ कुछ सामान्य विचार भी हैं:
- ओपनिंग लाइब्रेरी (शतरंज में शुरुआती सिद्धांत बहुत उन्नत है - विकी + डेटाबेस )
- एंडगेम लाइब्रेरी (इसी तरह, रेडीमेड एंडगेम के साथ कई डेटाबेस हैं)
- पुनरावृत्ति गहरीकरण + कैशिंग : विचार पहले 1, फिर 2, 3, और इसी तरह की गहराई पर एक खोज करने के लिए है। उसी समय, इस स्थिति को बचाएं, इसकी सबसे अच्छी चाल, गहराई, या कुछ और हैश तालिका में। पुनरावृत्ति की पूरी बात यह है कि अपूर्ण थकावट के परिणाम का उपयोग नहीं किया जा सकता है (तब एक shallower गहराई के लिए एक अपूर्ण थकावट खोज का संचालन करना बेहतर होता है) और अधिक गहराई की खोज करते समय, आप थकाऊ गहराई तक थकावट खोज के परिणामों का उपयोग कर सकते हैं। यह भी पता चला है कि 1 से 6 की गहराई की खोज तुरंत 6 की गहराई तक खोज की तुलना में तेज है।
लेख में कुछ संसाधनों की जानकारी का उपयोग किया गया था:
PS संपूर्ण सिद्धांत का उपयोग मेरे द्वारा व्यवहार में किया गया था और कुछ समय के लिए PHP में एक सरल रेस्ट-वेब सेवा थी शतरंज के लिए + C # में एक प्रोग्राम (.NET रिमोटिंग का उपयोग नेटवर्क गेम के लिए किया गया था), लेकिन अब साइट काम नहीं कर रही है और जब समय होता है, तो मैं इसे RubyOnRails पर स्थानांतरित करना चाहता हूं।
पीपीएस कौन
परवाह करता है - प्रोजेक्ट अब
Googlecode पर
रहता है और मेरे पास समय होने पर अपग्रेड होगा। कौन पिछले संस्करण का कोड चाहता है - मैं भेज सकता हूं।