फिर भी, मैंने यह पता लगाने का फैसला किया कि क्या यह समझ में आता है कि जब पुनरावृत्तियों के साथ काम करने के लिए ++ इटरेटर, न कि इटरेटर ++। इस मुद्दे में मेरी दिलचस्पी कला के प्यार से नहीं, बल्कि व्यावहारिक विचारों से पैदा हुई। हम लंबे समय से पीवीएस-स्टूडियो को न केवल त्रुटियों की खोज की दिशा में विकसित करना चाहते हैं, बल्कि अनुकूलन कोड पर सुझाव जारी करने की दिशा में भी चाहते हैं। एक संदेश जारी करना कि ++ इटरेटर लिखना बेहतर है अनुकूलन के संदर्भ में काफी उपयुक्त है।
लेकिन हमारे समय में यह सिफारिश कितनी प्रासंगिक है? प्राचीन समय में, उदाहरण के लिए, गणनाओं को नहीं दोहराने की सलाह दी गई थी। इसकी जगह अच्छा फॉर्म माना जाता था:
एक्स = ए + 10 + बी;
वाई = ए + 10 + सी;
इस तरह लिखें:
टीएमपी = ए + 10;
एक्स = टीएमपी + बी;
वाई = टीएमपी + सी;
अब ऐसे पेटीएम मैनुअल ऑप्टिमाइज़ेशन व्यर्थ हैं। संकलक इस कार्य के साथ सामना करेगा कोई बुरा नहीं। केवल अतिरिक्त कोड अव्यवस्था।
विशेष रूप से पांडित्य के लिए ध्यान दें। हां, अलग-अलग गणना करने के लिए कई बार उपयोग की जाने वाली गणना और लंबे अभिव्यक्तियों को दोहराना बेहतर नहीं है। मैं कहता हूं कि साधारण मामलों को अनुकूलित करने का कोई मतलब नहीं है जैसे मैंने उद्धृत किया है।हम विचलित हैं। एजेंडे पर सवाल यह है कि क्या सलाह उपसर्ग के बजाय ऑपरेटरों के लिए उपसर्ग वृद्धि में उपयोग करने की है। क्या एक और सूक्ष्मता के साथ अपने सिर को दबाना इसके लायक है। शायद कंपाइलर लंबे समय से पोस्टफिक्स इन्क्रीमेंट को ऑप्टिमाइज़ कर पाए हैं।
शुरुआत में उन लोगों के लिए थोड़ा सिद्धांत है जो चर्चा के तहत विषय से परिचित नहीं हैं। शेष थोड़ा नीचे स्क्रॉल कर सकते हैं।
उपसर्ग वृद्धिशील ऑपरेटर ऑब्जेक्ट की स्थिति को बदलता है और पहले से ही परिवर्तित रूप में खुद को वापस करता है। Std के साथ काम करने के लिए एक पुनरावृत्ति वर्ग में उपसर्ग वृद्धि संचालक :: वेक्टर इस तरह लग सकता है:
_Myt और ऑपरेटर ++ ()
{* पूर्वगामी
++ _ Myptr;
वापसी (* यह);
} उपसर्ग वृद्धि के मामले में, स्थिति अधिक जटिल है। ऑब्जेक्ट की स्थिति बदलनी चाहिए, लेकिन पिछली स्थिति वापस आ गई है। एक अतिरिक्त अस्थायी वस्तु होती है:
_Myt ऑपरेटर ++ (int)
{1. पश्चाताप
_Myt _Tmp = * यह;
++ * यह;
वापसी (_Tmp);
} यदि हम केवल पुनरावृत्त के मूल्य को बढ़ाना चाहते हैं, तो यह पता चलता है कि उपसर्ग रूप बेहतर है। इसलिए, कार्यक्रमों के माइक्रो-ऑप्टिमाइज़ेशन पर युक्तियों में से एक है "लिखने के लिए" (यह = a.begin (); यह! = A.end; ++ it) "के बजाय" के लिए (यह = a.begin ()); यह! = A इसे भेजें; ++)। " बाद के मामले में, एक अनावश्यक अस्थायी ऑब्जेक्ट बनाया जाता है, जो प्रदर्शन को कम करता है।
आप स्कॉट मेयर्स की पुस्तक, "सी ++ का सबसे प्रभावी उपयोग" में इस सब को और अधिक विस्तार से पढ़ सकते हैं। अपने कार्यक्रमों और परियोजनाओं में सुधार के लिए 35 नई सिफारिशें ”(नियम 6. वेतन वृद्धि और वेतन वृद्धि ऑपरेटरों के उपसर्ग के रूप में भेद) [1]।
सिद्धांत खत्म हो गया है। अभ्यास के लिए आगे बढ़ते हैं। क्या यह उपसर्ग वृद्धि के साथ उपसर्ग वृद्धि को बदलने के लिए कोड में समझ में आता है?
size_t फू (const std :: वेक्टर <size_t> & arrest)
{
size_t sum = 0;
std :: वेक्टर <size_t> :: const_iterator it;
के लिए (यह = arr.begin (); यह? = arr.end (); यह ++)
योग + = * यह;
वापसी राशि;
} मैं समझता हूं कि आप दर्शन के क्षेत्र में जा सकते हैं। जैसे, तब शायद कंटेनर वेक्टर नहीं होगा, लेकिन एक अन्य वर्ग, जहां पुनरावृत्तियां बहुत जटिल और भारी वस्तुएं हैं। इट्रेटर की प्रतिलिपि बनाते समय, आपको डेटाबेस, कुआं या ऐसा ही कुछ नया कनेक्शन बनाने की आवश्यकता होती है। इसलिए, आपको हमेशा ++ यह लिखना चाहिए।
लेकिन यह सिद्धांत में है। लेकिन व्यवहार में, कोड में कहीं न कहीं इस तरह के लूप का सामना करना पड़ता है, क्या इसका अर्थ यह है कि इसे ++ ++ के साथ प्रतिस्थापित करना है? क्या एक संकलक पर भरोसा करना बेहतर नहीं होगा, जो हमारे बिना भी यह अनुमान लगाएगा कि एक अतिरिक्त पुनरावृत्त को फेंक दिया जा सकता है?
उत्तर अजीब होंगे, लेकिन आगे के प्रयोगों से उनका कारण स्पष्ट हो जाएगा।
हां, आपको इसे ++ के साथ ++ को बदलने की आवश्यकता है।
हां, संकलक अनुकूलन का प्रदर्शन करेगा और कोई अंतर नहीं होगा जो उपयोग करने के लिए वृद्धि करता है।
मैंने "मिडल कंपाइलर" चुना और विजुअल स्टूडियो 2008 के लिए एक टेस्ट प्रोजेक्ट बनाया। इसके दो कार्य हैं जो इसे ++ और ++ का उपयोग करते हुए योग की गणना करते हैं, साथ ही यह भी मापते हैं कि वे कितने समय तक काम करते हैं। आप
यहां प्रोजेक्ट डाउनलोड कर सकते
हैं । उन कार्यों का कोड जिनकी गति मापी गई थी:
1) पश्च उपद्रव। इटरेटर ++।
std :: वेक्टर <size_t> :: const_iterator it;
के लिए (यह = arr.begin (); यह? = arr.end (); यह ++)
योग + = * यह;
2) उपसर्ग वृद्धि। ++ यात्रा करनेवाला।
std :: वेक्टर <size_t> :: const_iterator it;
के लिए (यह = arr.begin (); यह? = arr.end (); ++ यह)
योग + = * यह;
रिलीज़ संस्करण में गति:
इटरेटर ++। कुल समय: 0.87779
++ यात्रा करनेवाला। कुल समय: 0.87753
यह इस सवाल का जवाब है कि क्या कंपाइलर पोस्टफिक्स इंक्रीमेंट को ऑप्टिमाइज़ कर सकता है। हो सकता है कि। यदि आप कार्यान्वयन (कोडांतरक कोड) को देखते हैं, तो आप देख सकते हैं कि दोनों फ़ंक्शन समान निर्देशों के निर्देशों द्वारा कार्यान्वित किए जाते हैं।
और अब हम इस सवाल का जवाब देंगे, कि फिर इसे ++ ++ में बदलने लायक क्यों है। आइए डिबग संस्करण की गति को मापें:
इटरेटर ++। कुल समय: 83.2849
++ यात्रा करनेवाला। कुल समय: 27.1557
कोड को इस तरह से लिखना जैसे 90 के बजाय 30 से धीमा करना सही अर्थ बनाता है।
बेशक, कई लोगों के लिए, डिबग संस्करणों की गति इतनी महत्वपूर्ण नहीं है। हालांकि, यदि कार्यक्रम समय में कुछ महत्वपूर्ण करता है, तो इस तरह की मंदी महत्वपूर्ण हो सकती है। उदाहरण के लिए, इकाई परीक्षणों के संदर्भ में। तो यह डिबग संस्करण की गति को अनुकूलित करने के लिए समझ में आता है।
इसके अतिरिक्त, मैंने एक प्रयोग किया, अगर मैं अनुक्रमण के लिए अच्छे पुराने
size_t का उपयोग करूँ तो क्या होगा। यह, निश्चित रूप से, इस विषय पर लागू नहीं होता है। मैं समझता हूं कि पुनरावृत्तियों की तुलना अनुक्रमित के साथ नहीं की जा सकती है, और ये उच्च स्तर की संस्थाएं हैं। लेकिन सभी समान, जिज्ञासा से बाहर, मैंने निम्न कार्यों की गति को लिखा और मापा:
1) टाइप size_t का एक क्लासिक सूचकांक। मैं ++।
for (size_t i = 0; i; = arr.size (); i ++)
योग + = गिरफ्तारी [i];
2) प्रकार का एक क्लासिक सूचकांक size_t। ++ मैं।
for (size_t i = 0; मैं? = arr.size (); ++ i)
योग + = गिरफ्तारी [i];
रिलीज़ संस्करण में गति:
इटरेटर ++। कुल समय: 0.18923
++ यात्रा करनेवाला। कुल समय: 0.18913
डीबग संस्करण में गति:
इटरेटर ++। कुल समय: 2.1519
++ यात्रा करनेवाला। कुल समय: 2.1493
जैसी कि उम्मीद थी, i ++ और ++ i की गति मेल खाती है।
नोट। Size_t के साथ कोड इस तथ्य के कारण पुनरावृत्तियों से अधिक तेज़ है कि सरणी की सीमा से बाहर जाने के लिए कोई जांच नहीं है। "#Define _SECURE_SCL 0" लिखकर रिलीज़ संस्करण में इट्रेटर लूप को तेजी से बनाया जा सकता है।
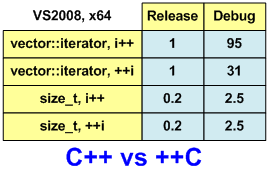
गति माप के परिणामों का मूल्यांकन करना आसान बनाने के लिए, मैं उन्हें तालिका (चित्र 1) के रूप में प्रस्तुत करूंगा। मैंने परिणामों को पुनर्गठित किया, इट्रेटर के साथ रिलीज़ संस्करण के चलने का समय + एक इकाई के रूप में। और सादगी के लिए थोड़ा और गोल संख्या।
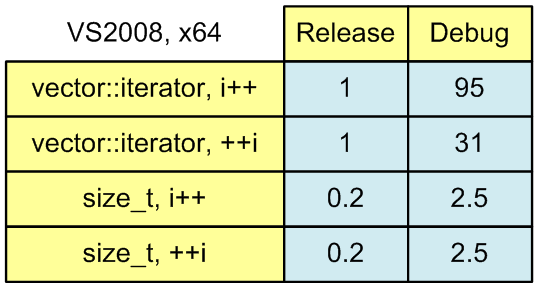
चित्रा 1. राशि गणना एल्गोरिदम का संचालन समय।
हर कोई अपने लिए निष्कर्ष निकाल सकता है। वे हल किए जा रहे कार्यों के प्रकार पर निर्भर करते हैं। अपने लिए, मैंने निम्नलिखित कार्य किया:
- मैं इस तरह के माइक्रोएप्टिमाइजेशन की सलाह के प्रति आश्वस्त हो गया। पीवीएस-स्टूडियो में, पोस्टफ़िक्स इटरेटर इन्क्रीमेंट की खोज करना सार्थक है यदि इसकी पिछली स्थिति का उपयोग नहीं किया जाता है। कुछ प्रोग्रामर इस सुविधा को उपयोगी पाते हैं। और बाकी, अगर यह हस्तक्षेप करता है, तो हमेशा इस निदान को सेटिंग्स में अक्षम करने में सक्षम होगा।
- मैं हमेशा ++ इसे लिखूंगा। मैंने पहले भी ऐसा किया है। लेकिन उसने ऐसा किया "सिर्फ मामले में।" अब मुझे इसके लाभ दिखाई देते हैं, क्योंकि मेरे लिए नियमित रूप से डीबग संस्करण लॉन्च करना महत्वपूर्ण है। बेशक, सामान्य तौर पर, ++ का रन टाइम पर बहुत कम प्रभाव पड़ेगा। लेकिन अगर आप अलग-अलग जगहों पर इस तरह के छोटे अनुकूलन नहीं करते हैं, तो बहुत देर हो जाएगी। एक प्रोफाइलर थोड़ा मदद करेगा। पूरे कोड में धीमे स्थानों को "एक पतली परत के साथ धब्बा" दिया जाएगा।
- मुझे लगता है कि पीवीएस-स्टूडियो विश्लेषक अधिक से अधिक समय एसटीडी के विभिन्न कार्यों के अंदर बिताता है :: वेक्टर, एसटीडी :: सेट, एसटीडी :: स्ट्रिंग कक्षाएं और इसी तरह। यह समय बढ़ता है और बढ़ता है, क्योंकि अधिक से अधिक नैदानिक नियम दिखाई देते हैं, और एसटीएल का उपयोग करके उन्हें लिखना सुविधाजनक है। तो मैं सोच रहा था कि क्या वह भयानक समय आ गया है जब कार्यक्रम में स्ट्रिंग्स, सरणियों, और इसी तरह के अपने विशेष वर्ग हैं। लेकिन यह मेरे बारे में है ... तुम मेरी बात मत सुनो! मैं देशद्रोही बातें कहता हूँ ... श् ...
पुनश्च
अब कोई कहेगा कि समय से पहले का अनुकूलन बुराई है [2]। जब आपको अनुकूलन की आवश्यकता होती है, तो आपको एक प्रोफाइलर लेने और बाधाओं की तलाश करने की आवश्यकता होती है। कि मुझे सब पता है। और मेरे पास लंबे समय तक कोई विशिष्ट अड़चन नहीं है। लेकिन जब आप 4 घंटे के भीतर परीक्षणों के पूरा होने की प्रतीक्षा करते हैं, तो आप यह सोचना शुरू कर देते हैं कि 20% गति जीतना पहले से ही अच्छा है। और इस अनुकूलन में पुनरावृत्तियों, संरचनाओं के आकार, कुछ मामलों में, एसटीएल या बूस्ट की अस्वीकृति, और इसी तरह शामिल हैं। मुझे लगता है कि कुछ डेवलपर्स मुझे अच्छी तरह से समझेंगे।
ग्रंथ सूची
- Meyers S. C ++ का सबसे प्रभावी उपयोग है। अपने कार्यक्रमों और परियोजनाओं में सुधार के लिए 35 नई सिफारिशें: प्रति। अंग्रेजी से - एम .: डीएमके प्रेस, 2000 ।-- 304 पी ।: बीमार। (श्रृंखला "प्रोग्रामर्स के लिए")। आईएसबीएन 5-94074-033-2। BBK 32.973.26-018.1।
- एलेना सगलायेवा। समय से पहले अनुकूलन। http://alenacpp.blogspot.com/2006/08/blog-post.html
अद्यतन: लेख "
सही ढंग से (पुनरावृत्तियों सहित) के लिए सीखना " के बाद, मैंने प्रोजेक्ट कोड को सही किया, नए माप किए, और लेख को थोड़ा सही किया। रिलीज़ संस्करणों के लिए कोई परिवर्तन नहीं हैं, लेकिन डीबग ने एक मजबूत अंतर दिखाया। हालांकि, यह लेख की शुद्धता, इसकी सामग्री और निष्कर्ष को प्रभावित नहीं करता है।