शुरुआत
सामाजिक नेटवर्क में कनेक्शन के अध्ययन का विषय विभिन्न कारणों से तेजी से प्रासंगिक हो रहा है: नेटवर्क प्रतिभागियों की कनेक्टिविटी की डिग्री के बारे में सवाल का जवाब देने का प्रयास; गति और सूचना के प्रसार के तरीके; सब के बाद, लक्षित विज्ञापन की प्रभावशीलता के बारे में। हां, और शोध की प्रक्रिया और निहित संबंधों की खोज नशे की लत है!
इस दिशा में अपने शोध के लिए, मैंने RuNet के सबसे "उबलते" टुकड़े को चुना, जिसका अर्थ है
LiveJournal का रूसी खंड। धूमिल-शब्द वाले प्रश्न कुछ इस तरह से लग रहे थे: क्या
यह संभव है कि लाइवजर्नल सेवा के उपयोगकर्ताओं के बीच संबंधों की संरचना के आधार पर ब्लॉगिंग "समूहों" को अलग किया जाए, अर्थात्। केवल दोस्तों के बारे में जानकारी के साथ ।
एक कामकाजी परिकल्पना के रूप में विचार करना कि इस तरह की जानकारी लोकप्रिय पत्रिकाओं के दर्शकों के विश्लेषण से निकाली जा सकती है, मुझे इन दर्शकों के बारे में विश्वसनीय डेटा प्राप्त करने के कार्य के साथ सामना करना पड़ा।
Livejournal सेवा के बुनियादी उपकरण बहु-हजार ब्लॉग के पाठकों की पूरी सूची प्राप्त करने का अवसर प्रदान नहीं करते हैं। इसलिए, पहला कदम घरेलू कंप्यूटर पर रूसी एलजे लिंक की संरचना को इकट्ठा करना था।
आगे देखते हुए, मैं कहता हूं: मेरे अध्ययन में रूसी एलजे के सामाजिक ग्राफ में 2.08 मिलियन कोने और 58.05 मिलियन आर्क हैं। रुचि रखते हैं? फिर, कट के नीचे बहुत सारे अक्षर, संख्या और चित्र हैं।
जानकारी जुटाना
Yandex.Blogs सेवा के अनुसार, LiveJournal के रूसी खंड में 2 मिलियन से अधिक ब्लॉग हैं। इस सूची को एक आधार के रूप में लेते हुए, मैंने ब्लॉगों के बीच "मैत्रीपूर्ण" संबंधों के डेटाबेस को भरने पर कुछ स्वचालित काम किया, जो मुझे कम से कम एक प्रश्न का उत्तर देने की अनुमति देता है: जो एक विशेष ब्लॉग को पढ़ता है।
कुछ संख्याएँ
कनेक्शन
2.08 मिलियन उपयोगकर्ता एकत्र किए गए थे। यानी
० million/१३/२०१ million को २.० ar मिलियन कोने के साथ ग्राफ ने
५.05.०५ मिलियन आर्क्स (उपयोगकर्ताओं के बीच निर्देशित दोस्ती) प्राप्त किया। इसके अलावा, केवल आधे - 1.08 मिलियन उपयोगकर्ता किसी और को पढ़ रहे हैं (एक आउटगोइंग आर्क है) और 1.26 मिलियन में पाठक हैं। एक दृष्टांत के रूप में, हम दोस्तों (पाठकों) की संख्या पर कुछ आँकड़ों का हवाला दे सकते हैं:

डेटाबेस में "रूसी खंड" के बाहर भेजे गए कनेक्शन शामिल नहीं थे (यह कहीं-कहीं 6 मिलियन से अधिक 0.9 मिलियन चोटियों के बराबर है) जिनकी जांच अतिरिक्त रूप से नहीं की गई थी और उन्हें "विदेशी" के रूप में वर्गीकृत किया गया था, हालांकि जीवित रूसी हैं ब्लॉग।
त्रुटि का अनुमान
एकत्र किए गए ग्राफ़ की पूर्णता का आकलन करने के लिए, हम
शीर्ष livejournal.com के पाठकों की "आधिकारिक" संख्या की तुलना एक ही ब्लॉगर्स के लिए संख्या के साथ करते हैं, लेकिन ग्राफ पर आने वाले आर्क को संक्षेप में प्राप्त करते हैं। अधिक सटीकता के लिए, दो TOP-50 टुकड़े लिए गए:
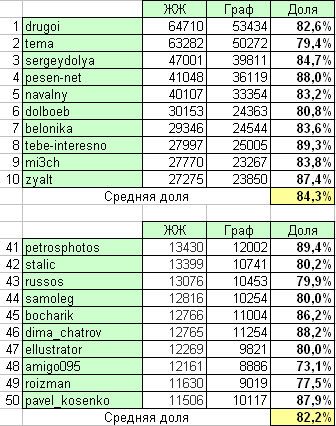
जैसा कि आप तालिका से देख सकते हैं, पाठकों का उत्पन्न ग्राफ 80% से थोड़ा अधिक वास्तविक से मेल खाता है। त्रुटि "रूसी खंड" (यानी, विदेशी दोस्तों का बहिष्कार) और रूसी पत्रिकाओं की सूची के अपूर्णता के प्रारंभिक अलगाव के कारण हो सकती है। भविष्य में, स्थानीय ग्राफ की संरचना का कुछ मामूली शोधन संभव है।
TOP-10 दर्शकों के प्रतिच्छेदन का विश्लेषण
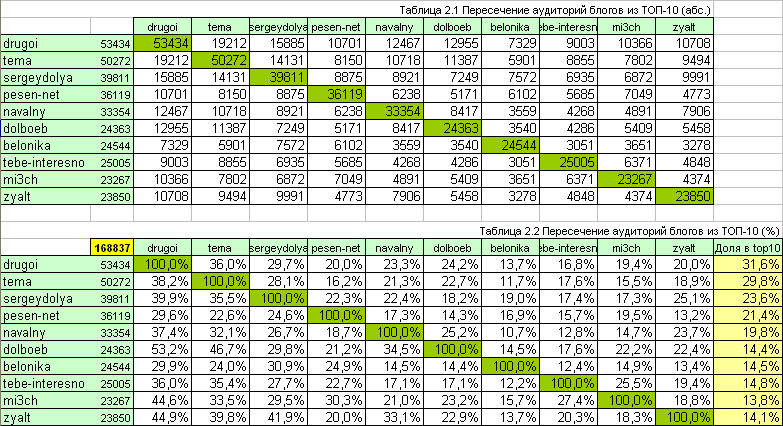
विश्लेषण स्वयं सरल और सपाट है - हम TOP-10 से प्रत्येक ब्लॉग के पाठकों की सूचियां लेते हैं और उनके चौराहे की तलाश करते हैं, परिणाम को एक टैबलेट में डालते हैं। अधिक सटीक रूप से, दो गोलियों में - पूर्ण में, मात्रात्मक मूल्यों और रिश्तेदार के साथ - दर्शकों के प्रतिशत का संकेत।
 सबसे पहले
सबसे पहले , दूसरी तालिका से पता चलता है कि TOP-10 (यानी कम से कम एक शीर्ष ब्लॉग की सदस्यता लेने वाले लोग) से पत्रिकाओं के कुल दर्शक: 168837 लोग (हम त्रुटि के बारे में याद करते हैं)।
दूसरी बात , हम यह कह सकते हैं कि एंटोन
नोसिक (
डॉलबोब ) के श्रोताओं में से एक तिहाई (34.5%) नवलनी को भी पढ़ता है, लेकिन
नीका बेलोटेर्सकोवस्काया (उसी
नवलनी के बेनोनिका ) के पाठकों का केवल 14.5%। लेकिन इसके 30.9% पाठक सर्गेई डोली (
सर्गेयडोल्या ) की नई रिपोर्ट और एक चौथाई (24.9%) - स्लाव से (
सेसन_नेट ) के जीवन की कहानियों के लिए
तत्पर हैं । और वैसे, एंटोन नोसिक के पाठकों के लगभग आधे (46.7%) आर्टेम लेबेदेव (टेम्पा) के टुंड्रा पर आंदोलनों का पालन करते हैं, और शीर्ष नेता रुस्तम अदगमोव (ड्रगोई) के दर्शकों का 20% स्रोत से हमारे राजनीतिक आंदोलन की हॉट फोटो रिपोर्ट प्राप्त करना पसंद करते हैं - इल्या
वरलामोवा (
zyalt )।
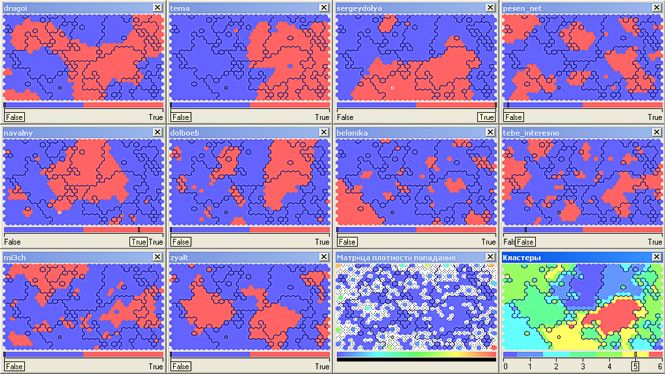
तीसरा , उच्चतर आदेशों के दर्शकों का निर्माण और प्रतिच्छेदन संभव है। उदाहरण के लिए, तीन ब्लॉगर्स के दर्शकों के चौराहों का विश्लेषण एक घन है। अलेक्सई नवलनी के अनुसार एक समान घन का एक टुकड़ा निम्नलिखित चित्र देगा:

मैट्रिक्स मुख्य विकर्ण के संबंध में सममित है। संख्या दो पत्रिकाओं (पंक्ति और स्तंभ का
अंतरच्छेदन ) के कुल श्रोताओं के अनुपात को दर्शाती है, जो अलेक्सी
नवालनी (
नौसेना ) भी पढ़ती है।
तालिका से आप देख सकते हैं कि
टेम्पा और
ड्रगोई ब्लॉगों के कुल दर्शकों में से केवल एक तिहाई (34.4%) भी
नौसेना पढ़ते हैं, जबकि दर्शकों से लगभग दो तिहाई
zyalt और
dolboeb इसे पढ़ते हैं - 64.2%। ऑनलाइन भ्रष्टाचार के खिलाफ लड़ाई में न्यूनतम रुचि
बेलोनिका-सेर्गेयडोल्या (26.6%) और
बेलोनिका-पेसेन_नेट (25.5%) के दर्शकों को दिखाई गई है।
ठीक है,
और चौथा , यदि आप हजारों लोगों के ब्लॉग पर विज्ञापन पोस्ट लगाने में लगे हुए हैं और TOP-50 में ऐसे लेआउट नहीं हैं - तो बाज़ार में
आग लगाइए :)
कैसे अपार गले लगाओ?
एक ओर, संख्यात्मक डेटा विभिन्न लागू अनुसंधानों के लिए पर्याप्त हैं। दूसरी ओर, कुछ शोधकर्ताओं के लिए केवल दृश्य कार्य क्षेत्र का मूल्यांकन करना आवश्यक है। आइए हमारी आंखों के सामने डेटा को ट्विस्ट करने की कोशिश करें। कैसे?
यहां, घटते आयामों के साथ बहुआयामी डेटा की दृश्य प्रस्तुति के तरीके हमारे लिए उपयोगी हैं: हम अपने 10-आयामी डेटा सेट (टॉप -10 से पत्रिकाओं को पढ़ने वाले ब्लॉगर्स) को एक विमान में दो आयामी छवि में "निचोड़ने" की कोशिश करेंगे। इस मामले में, आदर्श रूप से, पढ़ने योग्य ब्लॉगों पर पाठकों के कुछ समूह प्राप्त करना अच्छा होगा। बहुत उलझन में नहीं?
पहला ग्रुपिंग विकल्प जी-मीन्स (क्लस्टर की संख्या के स्वत: निर्धारण के साथ क्लस्टरिंग) या के-मीन्स एल्गोरिदम (क्लस्टर की दी गई संख्या द्वारा क्लस्टरिंग) का उपयोग करके क्लस्टर करना है। सिद्धांत रूप में, विचार ध्वनि है, लेकिन यह दृष्टिकोण परिणामों को प्रदर्शित करने की समस्या को हल नहीं करता है और इसकी कमियां हमारे डेटा की संरचना को देखते हैं।
इसलिए, मैंने
बेसग्रुप लैब्स से
डेडेक्टर एनालिटिक सिस्टम (अकादमिक संस्करण) के कार्यान्वयन में अपने पसंदीदा क्लस्टरिंग टूल -
कोहेन के स्वयं-व्यवस्थित मानचित्रों का उपयोग करने की कोशिश की। एल्गोरिथ्म का विवरण प्रासंगिक प्रकाशनों में पढ़ा जा सकता है, मैं केवल यह कह सकता हूं कि इस समस्या में, प्रदर्शन विमान पर एक बहुआयामी डेटा राहत परियोजना की क्षमता महत्वपूर्ण है। क्या परिणाम और इसकी व्याख्या कैसे की जाती है यह प्रक्रिया के मापदंडों और डेटा की प्रकृति की समझ पर निर्भर करता है। इसलिए, आगे का विश्लेषण एक विशेष मामला है, पूर्ण सत्य का दावा नहीं करता है।
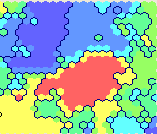
इसलिए, तंत्रिका नेटवर्क का एक नमूना खिलाने के बाद, जो कोहेनन मानचित्र है, हमें यह तस्वीर मिलती है। क्लस्टर्स की संख्या (निचले दाएं विंडो में बहु-रंगीन ज़ोन) मैन्युअल रूप से समायोजित की जाती है - परिणाम के बेहतर दृश्य टूटने के लिए 7 टुकड़े (नंबरिंग 0..6) सेट करें।
एक सुंदर और अतुलनीय तस्वीर पर थोड़ा ध्यान करने के बाद, हम कुछ सतही विश्लेषण के लिए आगे बढ़ सकते हैं।
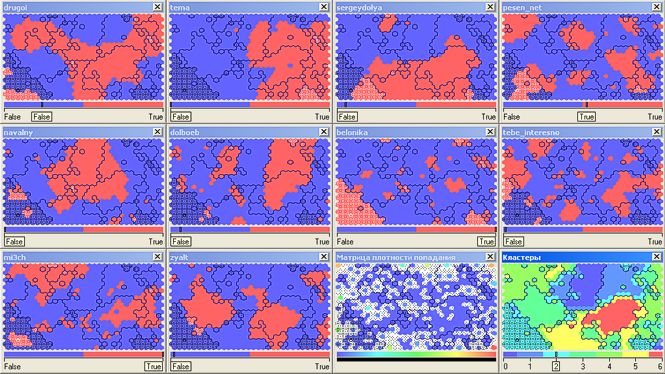
तो, Nika Belotserkovskaya (
बेलोनिका ) के प्रशंसकों का
एपोलिटिकल क्लस्टर (नंबर 2, लगभग 19 हजार प्रतिभागी), मुख्य रूप से पत्रिकाओं के पाठकों के साथ चौराहे हैं
ड्रगोई ,
सर्गेयडोल्या ,
pesen_net ,
mi3ch (चयनित क्लस्टर में एक मेष भरण है):
स्लाव से (
pesen_net ), दिमित्री
चेर्नशेव (
mi3ch ) को
पढ़ते हुए,
ड्रगोई और
टेबे_नरेस्नो पत्रिकाओं से सुंदर चित्रों को निहारते हुए और
आर्टीमी लेबेदेव (
टेम्पा ) द्वारा डिज़ाइन निष्कर्षों की चर्चा करते हुए क्रिएटिव इंटेलिजेंटिया को क्लस्टर संख्या 4 (54.5 हजार) में वर्गीकृत किया गया है:
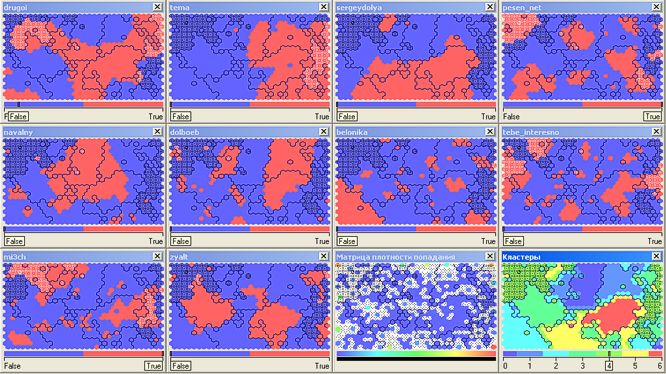
क्लस्टर संख्या 6 ने एक ही समय में लगभग सभी शीर्ष ब्लॉगर्स को पढ़ने वाले स्पष्ट व्यसनों के बिना पाठकों (8 हजार) को अवशोषित किया:
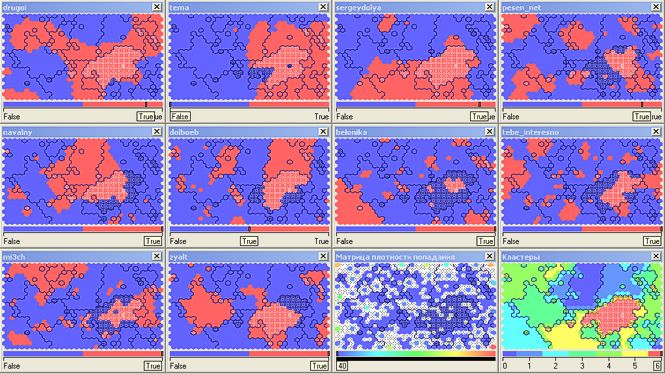
खैर, आज एलेक्सी
नवलनी (
नवलनी ) के बिना कहाँ
?! बॉट्स के आक्रमण के डर से, मैं इन पंक्तियों को लिखता हूं ... क्लस्टर नंबर 0 (ओह, बस मुझे संघों के लिए मत हराओ - टैरो कार्ड के डेक में शून्य कार्ड को "जस्टर" कहा जाता है) 33 हजार पाठकों को शामिल करता है (एक टिप्पणी होनी चाहिए, लेकिन यह जाएगी अंत)। इसे राजनैतिक रूप से सक्रिय शीर्ष ब्लॉगर्स (
ड्रगोई ,
डॉलबेब ,
जियाल्ट ) को कवर करते हुए क्लस्टर नंबर 1 (अन्य 16.5 हजार) के साथ जोड़ना सही होगा:
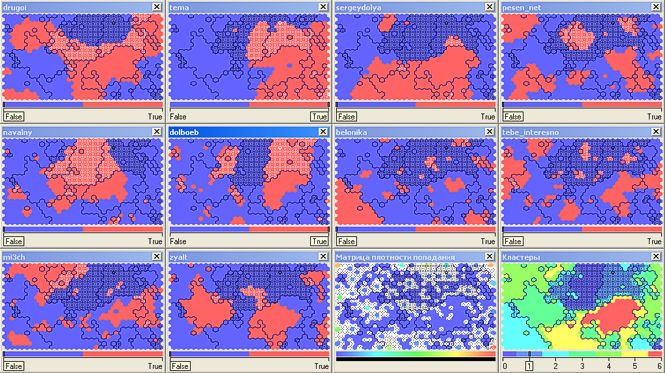
तकनीकी नोट
जैसा कि मैंने कहा, इस मामले में, प्रदर्शित समूहों की सामग्री और संरचना उनकी संख्या पर निर्भर करती है, जिसे कॉन्फ़िगर किया जा सकता है। उदाहरण के लिए, इस मॉडल के लिए "भौतिक" समूहों की संख्या जिसमें प्रसंस्करण के परिणामस्वरूप कई पाठक दुर्घटनाग्रस्त हो गए, लेकिन स्पष्टता के लिए, मैंने 7 "दृश्य" समूहों के साथ एक मोटा मॉडल बनाया। इस तरह के विभाजन की सटीकता (और यहां तक कि तंत्रिका नेटवर्क के माध्यम से क्लस्टरिंग की विधि) निरपेक्ष नहीं है, इसलिए ऐसा हो सकता है कि जो उपयोगकर्ता इसे नहीं पढ़ता है वह नौसेना के क्लस्टर में हो जाता है। लेकिन यह त्रुटि, सिद्धांत रूप में, सतही मूल्यांकन विश्लेषण के लिए महत्वपूर्ण नहीं है।
एक निष्कर्ष के बजाय
यह किए गए कार्य के प्रदर्शन को समाप्त करता है, और इसके लागू मूल्य पर (उदाहरण के लिए, TOP-30 या TOP-50 या एक विशेष रूप से गठित सूची का विश्लेषण) मेरा सुझाव है कि LJ का उपयोग करने वाले विज्ञापनदाता अपने माल और सेवाओं को बढ़ावा देने के बारे में सोचते हैं।
पुनश्च
LJ उपयोगकर्ता जो Habré पर पंजीकृत नहीं हैं, वे मेरे ब्लॉग infist-xxi.livejournal.com में प्रश्न पूछ सकते हैं