माइक्रोसॉफ्ट रिसर्च ने एक वैज्ञानिक पत्र और वीडियो प्रकाशित किया है जिसमें दिखाया गया है कि किनेक्ट में बॉडी ट्रैकिंग एल्गोरिदम कैसे काम करता है - यह लगभग उतना ही अद्भुत है जितना कि पहले से ही पाए गए कुछ एप्लिकेशन।
Kinect सफलता कई घटक प्रदान करती है। इसका लोहा अच्छी तरह से सोचा जाता है और एक सस्ती कीमत पर अपने कार्य करता है। हालांकि, लोहे के पास की गहराई को जल्दी से मापने के विस्मय के बाद, ध्यान अनिवार्य रूप से उस तरीके से आकर्षित होता है जिसमें वह (किनेक्ट) मानव शरीर को ट्रैक करता है। इस मामले में, नायक एक काफी क्लासिक पैटर्न मान्यता तकनीक है, लेकिन अनुग्रह के साथ लागू किया गया है।
शरीर की स्थिति को ट्रैक करने वाले उपकरण पहले से मौजूद हैं; लेकिन उनकी सबसे बड़ी समस्या उपयोगकर्ता के लिए एक संदर्भ स्थिति में बनने की आवश्यकता है जिसमें एल्गोरिथ्म एक साधारण तुलना के साथ उसे पहचानता है। उसके बाद, शरीर के आंदोलनों के बाद एक ट्रैकिंग एल्गोरिथ्म का उपयोग किया जाता है। मुख्य विचार: यदि पहले फ्रेम पर हमारे पास हाथ के रूप में पहचाना गया क्षेत्र है, तो अगले फ्रेम पर यह हाथ बहुत दूर नहीं जा सकता है, जिसका अर्थ है कि हम बस आस-पास के क्षेत्रों की पहचान करने की कोशिश कर रहे हैं।
ट्रैकिंग एल्गोरिदम सिद्धांत रूप में अच्छे हैं, लेकिन व्यवहार में वे विफल हो जाते हैं अगर शरीर की स्थिति किसी कारण से खो जाती है; और बहुत खराब तरीके से वे अन्य वस्तुओं के साथ सामना करते हैं जो ट्रैक किए गए व्यक्ति को ब्लॉक करते हैं, यहां तक कि थोड़े समय के लिए भी। इसके अलावा, कई लोगों को ट्रैक करना मुश्किल है; और इस तरह के "ट्रैक लॉस" के साथ, यह एक लंबे समय के बाद बहाल किया जा सकता है, अगर बिल्कुल भी।
तो Microsoft अनुसंधान के लोगों ने इस समस्या के साथ क्या किया कि Kinect बहुत बेहतर काम करता है?
वे अपने मूल सिद्धांतों पर लौट आए और एक बॉडी रिकग्निशन सिस्टम बनाने का फैसला किया जो ट्रैकिंग पर निर्भर नहीं करता है, बल्कि प्रत्येक पिक्सेल के स्थानीय विश्लेषण के आधार पर शरीर के कुछ हिस्सों को ढूंढता है। पारंपरिक पैटर्न मान्यता कई पैटर्न पर प्रशिक्षित निर्णय लेने की संरचना के साथ काम करती है। इसे काम करने के लिए, आप आमतौर पर एक बड़ी संख्या में विशेषता मान प्रदान करते हैं, जो, जैसा कि आप मानते हैं, किसी वस्तु को पहचानने के लिए आवश्यक जानकारी होती है। कई मामलों में, सूचनात्मक सुविधाओं को चुनने का कार्य सबसे मुश्किल काम है।
चुने गए संकेत आश्चर्यचकित कर सकते हैं, क्योंकि वे शरीर के कुछ हिस्सों की पहचान करने के लिए अनौपचारिकता के अर्थ में स्पष्ट और सरल हैं। सभी संकेत एक सरल सूत्र से प्राप्त होते हैं
f = d (x + u / d (x)) - d (x + v / d (x))जहाँ
u, v विस्थापन वैक्टर की एक जोड़ी है, और
d (x) पिक्सेल की गहराई है, अर्थात, Kinect से बिंदु
x पर प्रोजेक्ट करने की दूरी। यह एक बहुत ही सरल संकेत है, वास्तव में यह केवल दो पिक्सल की गहराई में अंतर है, मूल से यू और वी से ऑफसेट है।
(यू और वी अलग-अलग होने से, हमें सुविधाओं का एक सेट मिलता है। काम में ही (नीचे लिंक), सब कुछ बहुत अधिक स्पष्ट है। - नोट अनुवाद।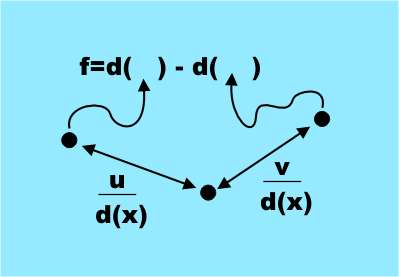
एकमात्र जटिलता यह है कि मूल पिक्सेल की गहराई से ऑफसेट सामान्यीकृत होता है, अर्थात डी (एक्स) द्वारा विभाजित किया जाता है। यह विस्थापन को गहराई से स्वतंत्र बनाता है और शरीर के दृश्य आयामों के साथ उन्हें संबद्ध करता है।
स्पष्ट रूप से, ये विशेषताएं पिक्सेल के आसपास के क्षेत्र के त्रि-आयामी आकार से संबंधित कुछ को मापती हैं; लेकिन क्या वे अंतर करने के लिए पर्याप्त हैं, कहने दो, हाथ से एक पैर एक और सवाल है।
टीम द्वारा किया जाने वाला अगला चरण, एक प्रकार के क्लासिफायरियर का प्रशिक्षण है, जिसे "निर्णय वन" कहा जाता है, अर्थात निर्णय पेड़ों का एक सेट। प्रत्येक पेड़ को गहरी छवियों में सुविधाओं के एक सेट पर प्रशिक्षित किया गया था जो पहले शरीर के संबंधित भागों से बंधा हुआ था। यही है, जब तक वे छवियों के परीक्षण सेट पर शरीर के एक निश्चित हिस्से के लिए सही वर्गीकरण का उत्पादन शुरू नहीं करते, तब तक पेड़ों का पुनर्निर्माण किया गया था। 1000-कोर क्लस्टर पर प्रति 1 मिलियन छवियों में केवल तीन पेड़ों को सीखना एक दिन के बारे में लिया गया।
प्रशिक्षित क्लासीफायर शरीर के किसी विशेष हिस्से से संबंधित पिक्सेल की संभावना देते हैं; और एल्गोरिथ्म का अगला चरण बस प्रत्येक प्रकार के भागों के लिए अधिकतम संभावना वाले क्षेत्रों का चयन करता है। उदाहरण के लिए, यदि एक क्षेत्र को 'पैर' के रूप में वर्गीकृत किया जाता है, तो "फुट" क्लासिफायर ने इस क्षेत्र में अधिकतम संभावना दी है। अंतिम चरण शरीर के विशिष्ट भागों के रूप में पहचाने जाने वाले क्षेत्रों के सापेक्ष जोड़ों के अनुमानित स्थान की गणना है। इस आरेख में, रंगीन क्षेत्रों द्वारा शरीर के विभिन्न भागों के लिए संभाव्यता के अधिकतम संकेत दिए गए हैं:
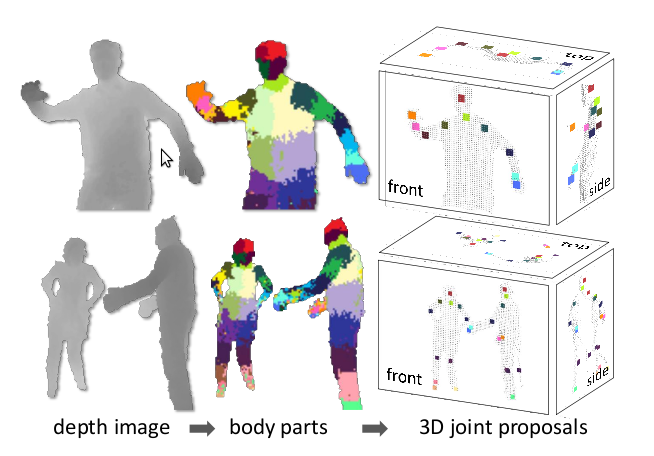
ध्यान दें कि यह सब गणना करने के लिए काफी सरल है, कम से कम तीन पिक्सेल के लिए गहराई मान, और यहां आप GPU का उपयोग कर सकते हैं। इसलिए, सिस्टम 200 फ्रेम प्रति सेकंड की प्रक्रिया कर सकता है और इसके लिए प्रारंभिक संदर्भ मुद्रा की आवश्यकता नहीं होती है। चूंकि प्रत्येक फ्रेम का स्वतंत्र रूप से विश्लेषण किया जाता है, और इस तरह की कोई ट्रैकिंग नहीं है, इसलिए शरीर की छवि के नुकसान के साथ कोई समस्या नहीं है; और आप एक ही समय में कई निकायों को संसाधित कर सकते हैं।
अब आपको यह समझने की थोड़ी समझ है कि यह सब कैसे काम करता है, Microsoft अनुसंधान से एक वीडियो देखें:
(वैकल्पिक
स्रोत )
Kinect एक महत्वपूर्ण उपलब्धि है और यह काफी मानक, क्लासिक पैटर्न मान्यता पर आधारित है, लेकिन सही तरीके से लागू किया गया है। आपको बड़ी मल्टी-कोर कंप्यूटिंग शक्ति की उपलब्धता को भी ध्यान में रखना होगा, जिसने हमें प्रशिक्षण सेट को काफी बड़ा बनाने की अनुमति दी। यह मान्यता के तरीकों में से एक है जिसे आप सदियों से सीख सकते हैं, लेकिन फिर वर्गीकरण को बहुत तेज़ी से किया जा सकता है। शायद हम एक "स्वर्ण युग" में प्रवेश कर रहे हैं जब पैटर्न मान्यता और मशीन सीखने के अच्छे काम के लिए आवश्यक कंप्यूटिंग शक्ति अंत में उन्हें व्यावहारिक बनाएगी।
वास्तव में प्रकाशन (पीडीएफ, 4.6 एमबी)
पुनश्च
1. यह एक अनुवाद है। चूंकि हैबर की व्यापक बुद्धि इस तरह के एक ट्रिफ़ल को प्रदान नहीं करती है जैसे कि सैंडबॉक्स में पहली बार प्रकाशित होने पर विषय के प्रकार को बदलना, यह ठीक से डिज़ाइन नहीं किया गया है।
आई प्रोग्रामर के साथ हैरी फेयरहेड से मूल ।
2. जैसा कि हैबर का व्यापक ज्ञान भी जल्दबाजी नहीं करता है, मैंने पहले ही तय कर लिया था कि विषय पूर्व-मॉडरेशन पास नहीं किया और इसे दूसरी जगह प्रकाशित किया। इसलिए यदि किसी ने उसे वहां देखा है, तो किसी को नहीं बताएगा। लेकिन यह जान लें कि इसका उद्देश्य हैबर था। :)