यदि आपका वेब प्रोजेक्ट किसी तरह से उपयोगकर्ताओं के लिए कुछ डेटा की खोज और प्रावधान से जुड़ा हुआ है, तो आपको संभवतः खोज स्ट्रिंग को लागू करने के कार्य के साथ सामना करना होगा। उसी समय, यदि किसी कारण से परियोजना में Google या यांडेक्स जैसी स्मार्ट सेवाओं की तकनीकों का उपयोग करना संभव नहीं है, तो खोज को आंशिक रूप से या पूरी तरह से स्वतंत्र रूप से लागू करना होगा। उप-कार्यों में से एक संभवतः फजी खोज का कार्यान्वयन होगा, क्योंकि उपयोगकर्ताओं को अक्सर गलत किया जाता है और कभी-कभी सटीक शब्द, नाम या नाम नहीं पता होता है।
यह आलेख फ़ज़ी खोज के संभावित कार्यान्वयन का वर्णन करता है, जिसका उपयोग साइट
edatuda.ru पर खोज करने के लिए किया गया था।
कार्यहमारे रेस्तरां, कैफे और बार खोज सेवा के निर्माण के हिस्से के रूप में, एक कार्य एक खोज पट्टी को लागू करने के लिए उत्पन्न हुआ जिसमें उपयोगकर्ता अपने संस्थानों के नामों का संकेत दे सकते हैं।
कार्य निम्नानुसार निर्धारित किया गया था:
- ड्रॉप-डाउन सूची में चयन प्रक्रिया में खोज परिणाम प्रदर्शित किए जाने चाहिए।
- खोज को उपयोगकर्ताओं की संभावित त्रुटियों और टाइपो को ध्यान में रखना चाहिए (उदाहरण के लिए, mcdonalds सिर्फ macdonalds टाइप करना चाहते हैं)।
- प्रत्येक संस्थान के लिए बहुत सारे समानार्थी शब्द सेट करने में सक्षम होना चाहिए (उदाहरण के लिए mcdonalds => makdak)।
आइटम 1-3 की दृश्य प्रस्तुति:
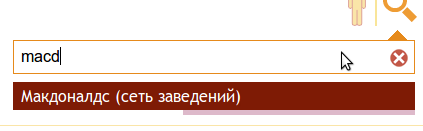

इस प्रकार, क्वेरी वाक्यांश प्राप्त करने की संभावना है, सबसे अधिक संभावना है, आपको पूर्व-संकलित शब्दकोश से लिखित में निकटतम प्रविष्टियों का चयन करने की आवश्यकता है। वास्तव में, कार्य टाइपोस को ठीक करना था जो आधुनिक खोज इंजन कर सकते हैं। इसे हल करने के सामान्य तरीकों में से एक:
- एन-ग्राम सूचकांक बनाने पर आधारित एक विधि।
अच्छी, त्वरित और आसान विधि। - दूरी आधारित संपादन विधि।
संभवतः सबसे सटीक तरीकों में से एक जो संदर्भ को ध्यान में नहीं रखता है। - दावा 1 और दावा 2 का मिलन।
बड़े शब्दकोशों में खोज को गति देने के लिए, यह पहली बार धारा 2 के आवेदन के साथ n- ग्राम सूचकांक के आधार पर शब्दों के एक समूह का चयन करने के लिए समझ में आता है ( ज़ोबेल और डार्थ के काम को देखें "बड़े अक्षरों में अनुमानित मिलान ढूँढना )
एक हब्र पर पाठ और शब्दकोश में फजी खोज के लिए समर्पित एक अच्छा
लेख था। यह अच्छी तरह से पैराग्राफ 1 और 2 का वर्णन करता है, विशेष रूप से, अच्छी तस्वीरों के साथ लेवेन्सहाइटिन और डेमेराउ-लेवेन्शिन की दूरी। इसलिए, यह आलेख इन विधियों का विस्तृत विवरण प्रदान नहीं करेगा।
कार्यान्वयन खोजेंहमारे मामले में, शब्दकोश कई हजार प्रविष्टियों के क्रम के रूप में बड़ा नहीं है (उदाहरण के लिए खोज इंजन के साथ), इसलिए हमने एन-ग्राम इंडेक्स का निर्माण किए बिना संपादन दूरी के आधार पर विधि का उपयोग करने का निर्णय लिया।
संपादन दूरी की गणना के लिए पारंपरिक एल्गोरिदम अच्छी तरह से लाइनों की निकटता का मूल्यांकन करते हैं, लेकिन पात्रों के बारे में किसी भी जानकारी का उपयोग नहीं करते हैं (उनकी समानता या असमानता को छोड़कर), जैसे कि कीबोर्ड पर पात्रों के बीच की दूरी या ध्वनि के निकटता के बीच की दूरी।
खाते में कुंजियों के बीच की दूरी को ध्यान में रखते हुए उपयोगी हो सकता है क्योंकि जब जल्दी से टाइप करते हैं, तो चूक के कारण बड़ी संख्या में त्रुटियां होती हैं, जबकि उपयोगकर्ता द्वारा गलती से अगली कुंजी दबाए जाने की संभावना अधिक दूरस्थ एक से अधिक है।
ध्वन्यात्मक नियमों को ध्यान में रखना भी महत्वपूर्ण है। उदाहरण के लिए, विदेशी नामों और शीर्षकों के मामले में, उपयोगकर्ता अक्सर शब्दों की सटीक वर्तनी नहीं जानते हैं, लेकिन उनकी ध्वनि याद रखते हैं।
ज़ॉबेल और डार्थ के
काम में, "फ़ोनेटिक स्ट्रिंग मिलान: सूचना पुनर्प्राप्ति से सबक" एक स्ट्रिंग तुलना विधि का वर्णन करता है जो कि ध्वन्यात्मक नियमों के एक सेट के साथ संपादन दूरी की गणना को जोड़ती है (वाक्यांश "ध्वन्यात्मक नियम" पूरी तरह से सही नहीं है)। लेखकों ने कई ध्वन्यात्मक समूहों की पहचान की जिसमें वर्ण शामिल थे जो एक समूह के पात्रों को बदलने की "लागत" जब संपादन दूरी की गणना करते थे तो एक ही समूह से संबंधित पात्रों की जगह की "लागत" से कम नहीं थी। हमने इस विचार का उपयोग किया।
बुनियादी एल्गोरिथ्म के रूप में, हमने वैगनर-फिशर एल्गोरिथ्म को कई संशोधनों के साथ दमरेउ-लेवेनशेटिन दूरी को खोजने के लिए अनुकूलित किया:
- बुनियादी एल्गोरिथ्म में, सभी ऑपरेशनों की "लागत" है। हम सम्मिलित करने और हटाने के ऑपरेशन की "लागत" को 2 पर सेट करते हैं, एक्सचेंज ऑपरेशन को 1, और दूसरे के साथ एक वर्ण को बदलने के संचालन की गणना निम्नानुसार की जाती है: यदि तुलना किए गए वर्णों के अनुरूप कुंजी एक दूसरे के बगल में स्थित हैं। कीबोर्ड या तुलना वर्ण एक ध्वन्यात्मक समूह के हैं, तो प्रतिस्थापन की "लागत" 1 है, अन्यथा 2।
- नतीजतन, उपसर्ग दूरी वापस आ गई है, अर्थात्। शब्दकोश से क्वेरी शब्द और शब्द के सभी उपसर्गों के बीच न्यूनतम दूरी। यह आवश्यक है क्योंकि क्वेरी शब्द जो हम शब्दकोश रूपों के साथ तुलना करेंगे, आमतौर पर काट दिया जाएगा। यानी हम "mcdonalds" डिक्शनरी के साथ "mcd" दर्ज किए गए उपयोगकर्ता की तुलना कर सकते हैं और एक बड़ी दूरी (7 इन्सर्ट ऑपरेशंस) प्राप्त कर सकते हैं, हालाँकि इस मामले में "mcdonalds" क्वेरी बहुत ही सटीक रूप से मेल खाता है।
हमने मामूली बदलावों के साथ उपर्युक्त कार्य से ध्वन्यात्मक समूहों को लिया:

मूल काम में, समूहों की रचना मूल अंग्रेजी शब्दों की ध्वनि के आधार पर की गई थी, इसलिए इसमें कोई गारंटी नहीं है कि वे अनुवादित रूसी पाठ में एक अच्छा परिणाम दिखाएंगे। हमने अपने स्वयं के अवलोकनों के आधार पर छोटे बदलाव किए (उदाहरण के लिए, मूल "fpv" समूह से 'p' को हटा दिया गया)।
सी ++ में परिणामी कार्यान्वयन:
{{{ class EditDistance { public: int DamerauLevenshtein(const std::string& user_str, const std::string& dict_str) { size_t user_sz = user_str.size(); size_t dict_sz = dict_str.size(); for (size_t i = 0; i <= user_sz; ++i) { trace_[i][0] = i << 1; } for (size_t j = 1; j <= dict_sz; ++j) { trace_[0][j] = j << 1; } for (size_t j = 1; j <= dict_sz; ++j) { for (size_t i = 1; i <= user_sz; ++i) {
ध्यान दें कि संक्षिप्त शब्दों में, उपयोगकर्ता, एक नियम के रूप में, ऐसे ब्लंडर को लंबे समय तक नहीं बनाते हैं। ऐसा करने के लिए, हम क्वेरी शब्द की लंबाई के लिए आनुपातिक शब्दों के बीच अधिकतम स्वीकार्य दूरी की दहलीज बनाते हैं।
{{{ const double kMaxDistGrad = 1 / 3.0; ... uint32_t dist = distance_.DamerauLevenshtein(word, dict_form); if (dist <= (word.size() * kMaxDistGrad)) {
सूचीबता दें कि संस्थानों के लिए स्रोत के रिकॉर्ड हैं:
<मेटा डेटा: आईडी, ...> <संस्थान का नाम> <पर्याय रूप का नाम>
फिर सूचकांक को निम्नानुसार दर्शाया जा सकता है:

- स्थानों - प्रतिष्ठानों के लिए मेटा डेटा जो एक खोज का परिणाम है।
- place_index - नाम और उनके पर्याय रूप, विशिष्ट संस्थानों का जिक्र; यह मूल रूप से स्थानों के लिंक की एक सरणी है।
- words_index - सभी रूपों से निकाले गए शब्द; यह फ़ॉर्म के उल्टे सूचकांक की तरह कुछ है: <word> <स्थानों_index0, Places_index1, ...>; एक छोटे से शब्दकोश के मामले में, इसे सरणी की एक सरणी के रूप में व्यवस्थित किया जा सकता है।
खोज के दौरान, आपको प्रत्येक उपयोगकर्ता क्वेरी शब्द के लिए संपूर्ण words_index सरणी से गुजरना होगा। यदि शब्दकोश बहुत बड़ा है, तो यह मानते हुए कि पहले अक्षर में त्रुटियां काफी दुर्लभ हैं, आप अपने आप को क्वेरी शब्द के समान अक्षर से शुरू होने वाले रूपों तक सीमित कर सकते हैं।
हम पूर्णता के लिए लड़ते हैं
पाया संस्थानों की पूर्णता बढ़ाने के लिए, हमने कुछ और विचारों को लागू किया।
- टाइप करते समय, उपयोगकर्ता अक्सर कीबोर्ड लेआउट को बदलना भूल जाते हैं, (आप अक्सर प्रश्न देख सकते हैं जैसे: "ghfqv", "vfrljy", ..)। इसलिए, यह विचार सामने आया, यदि सामान्य खोज के दौरान कोई भी साइट नहीं मिली, तो उसी खोज को करने के लिए मूल क्वेरी के विपरीत लेआउट के पात्रों से बनाई गई क्वेरी के साथ।
- कई संस्थानों में रूसी नाम नहीं हैं, लेकिन उपयोगकर्ताओं को सिरिलिक में उन्हें टाइप करने के लिए उपयोग किया जाता है। मैकडॉनल्ड्स, स्टारबक्स और अन्य जैसे संस्थानों के लिए। स्पष्ट रूप से नामों के सिरिलिक रूपों को शब्दकोष में पर्याय के रूप में दर्ज किया जा सकता है। लेकिन कुछ के लिए, जैसे कि GQ बार, यह "GQ बार" जैसे समानार्थक शब्द उत्पन्न करने के लिए उचित नहीं है, और साथ ही, यह आवश्यक है कि संस्थान क्वेरी "बार" से मेल खाता हो। इसलिए, सामान्य सिरिलिक प्रश्नों के अलावा, एक अतिरिक्त अनुवादित क्वेरी उत्पन्न होती है।
{{{
सामान्य कार्यान्वयन
सभी अनुक्रमण और खोज तर्क को c ++ डेमॉन में लागू किया गया था। डेटाबेस पर समय-समय पर डेटा को फिर से पढ़ा जाता है, जबकि सूचकांक पूरी तरह से फिर से बनाया जाता है। जीईटी अनुरोधों के माध्यम से HTTP के माध्यम से फ्रंट-एंड स्क्रिप्ट के साथ संचार किया जाता है, परिणाम प्रतिक्रिया शरीर में json प्रारूप में प्रेषित होते हैं। निम्नलिखित योजना निकली है:

नतीजतन, ~ 2.5 हजार अद्वितीय शब्दों पर, औसत खोज समय ~ 8 एमएस था।
संदर्भ
- परियोजना स्थल। edatuda.ru
- लेवेंसहिन दूरी। ru.wikipedia.org/wiki/_
- दूरी दमरेउ-लेवेंसाइटिन। en.wikipedia.org/wiki/Damerau%E2%80%93Levenshtein_distance
- ज़ोबेल और डार्थ का काम। "बड़े अक्षरों में अनुमानित मिलान का पता लगाना।" citeseerx.ist.psu.edu/viewdoc/download?doi=10.1.1.14.3856&rep=rep1&type=pdf
- ज़ोबेल और डार्थ का काम। "ध्वन्यात्मक स्ट्रिंग मिलान: सूचना पुनर्प्राप्ति से सबक" citeseerx.ist.psu.edu/viewdoc/download?doi=10.1.1.18.2138&rep=rep1&type=pdf