अनुकूलन स्पष्ट रूप से एक MySQL सर्वर की रीढ़ नहीं है। इस लेख का उद्देश्य उन डेवलपर्स को समझाना है जो डेटाबेस के साथ कसकर काम नहीं करते हैं और कभी-कभी समझ में नहीं आता है कि MySQL में अन्य DBMS में सफलतापूर्वक प्रक्रिया करने वाली क्वेरी क्यों बेशर्मी से धीमा कर देती है कि MySQL में निर्माण के बीच का निर्माण कैसे अनुकूलित है।
MySQL एक नियम आधारित ऑप्टिमाइज़र का उपयोग करता है। लागत आधारित अनुकूलन की अशिष्टता निश्चित रूप से इसमें मौजूद है, लेकिन इस हद तक नहीं कि मैं उन्हें देखना चाहूंगा। इस कारण से, अक्सर फ़िल्टर लागू करने के बाद प्राप्त सेट की शक्तियों की गणना गलत तरीके से की जाती है। यह ऑप्टिमाइज़र त्रुटियों और गलत निष्पादन योजना के चयन की ओर जाता है। इसके अलावा, अनुकूलन के बीच प्राप्त अनुकूलन को स्पष्ट रूप से नहीं बदला जा सकता है: क्वेरी निष्पादन के लिए सूचकांक और तालिका में शामिल होने का आदेश।
सबसे पहले, बग पर विचार करें: bugs.mysql.com/bug.php?id=5982 और इसे हल करने के संभावित तरीके
बग के सार को समझने के लिए, हम 125 मिलियन रिकॉर्ड का एक परीक्षण डेटा सेट बनाएंगे।
drop table if exists pivot; drop table if exists big_table; drop table if exists attributes; create table pivot ( row_number int(4) unsigned auto_increment, primary key pk_pivot (row_number) ) engine = innodb; insert into pivot(row_number) select null from information_schema.global_status g1, information_schema.global_status g2 limit 500; create table attributes(attr_id int(10) unsigned auto_increment, attribute_name varchar(32) not null, start_date datetime, end_date datetime, constraint pk_attributes primary key(attr_id) ) engine = innodb; create table big_table(btbl_id int(10) unsigned auto_increment, attr_attr_id int(10) unsigned, record_date datetime, record_value varchar(128) not null, constraint pk_big_table primary key(btbl_id) ) engine = innodb; insert into attributes(attribute_name, start_date, end_date) select row_number, str_to_date("20000101", "%Y%m%d"), str_to_date("20000201", "%Y%m%d") from pivot; insert into big_table(attr_attr_id, record_date, record_value) select p1.row_number, date_add(str_to_date("20000101", "%Y%m%d"), interval p2.row_number + p3.row_number day), p2.row_number * 1000 + p3.row_number from pivot p1, pivot p2, pivot p3; create index idx_big_table_attr_date on big_table(attr_attr_id, record_date);
विशेषताएँ तालिका अनिवार्य रूप से एक संदर्भ है,
big_table के लिए और इसमें दो कॉलम भी शामिल हैं जो एक महीने के लिए तिथि सीमा को सीमित करते हैं।
| attr_id | ATTRIBUTE_NAME | प्रारंभ_तिथि | end_date |
| 1 | 1 | 1/1/2000 12:00:00 पूर्वाह्न | 2/1/2000 12:00:00 पूर्वाह्न |
| 2 | 2 | 1/1/2000 12:00:00 पूर्वाह्न | 2/1/2000 12:00:00 पूर्वाह्न |
| 3 | 3 | 1/1/2000 12:00:00 पूर्वाह्न | 2/1/2000 12:00:00 पूर्वाह्न |
प्रत्येक
attr_id के लिए , बड़ी तालिका में 250,000 प्रविष्टियाँ हैं। आइए यह पता लगाने की कोशिश करें कि कितने रिकॉर्ड
big_table में
सम्मिलित हैं , विशेषता एक के लिए
विशेषता तालिका द्वारा निर्दिष्ट तिथियों को ध्यान में रखते हुए।
select attr_attr_id, max(record_date), min(record_date), max(record_value), count(1) from big_table where attr_attr_id = 1 and record_date between str_to_date("20000101", "%Y%m%d") and str_to_date("20000201", "%Y%m%d") group by attr_attr_id;
| attr_attr_id | अधिकतम (रिकॉर्ड_डेट) | मिनट (रिकॉर्ड_डेट) | गिनती (1) |
| 1 | 2/1/2000 12:00:00 पूर्वाह्न | 1/3/2000 12:00:00 पूर्वाह्न | 465 |
हम लगभग 500 रिकॉर्ड प्राप्त करते हैं (क्वेरी निष्पादन समय नगण्य है और 00.050 सेकंड की राशि है)। यह मानना तर्कसंगत है कि चूंकि डेटा सभी विशेषता मूल्यों के लिए समान रूप से वितरित किया जाता है, जब बाइंड चर को निर्दिष्ट करने के बजाय
विशेषता तालिका से कनेक्ट करते हैं, तो क्वेरी समय थोड़ा बढ़ जाना चाहिए, और 25 सेकंड से अधिक नहीं होना चाहिए। अच्छी तरह से जाँच करें:
select b.attr_attr_id, max(b.record_date), min(b.record_date), max(b.record_value), count(1) from attributes a join big_table b on b.attr_attr_id = a.attr_id and b.record_date between a.start_date and a.end_date group by b.attr_attr_id;
निष्पादन का समय: 15 मिनट से अधिक (इस बिंदु पर मैंने अनुरोध को बाधित किया है)। ऐसा क्यों है? बात यह है कि MySQL गतिशील रैंकिंग का समर्थन नहीं करता है, जिसके बारे में हम बात कर रहे हैं और कहते हैं कि बग
# 5982, 2004 में वापस बनाया गया। आइए देखें निष्पादन योजना:
| आईडी | SELECT_TYPE | तालिका | टाइप | possible_keys | कुंजी | key_len | रेफरी | पंक्तियों | अतिरिक्त |
| 1 | सरल | ख | सभी | idx_big_table_attr_date | | | | 125443538 | अस्थायी का उपयोग करना; फाइलसर्ट का उपयोग करना |
| 1 | सरल | एक | eq_ref | प्राथमिक | प्राथमिक | 4 | test.b.attr_attr_id | 1 | जहाँ का उपयोग करना |
योजना स्पष्ट रूप से दर्शाती है कि 125 मिलियन रिकॉर्ड का एक पूर्ण टेबल स्कैन प्रगति पर है। अजीब फैसला। यह स्थिति को ठीक करने में मदद नहीं करेगा और सीधे_जोन को जोड़ के क्रम को बदलने के लिए और न ही
सूचकांक को स्पष्ट रूप से
सूचकांक के उपयोग को इंगित करने के लिए
मजबूर नहीं करेगा। बात यह है कि सबसे अच्छे रूप में हमें एक योजना मिलती है:
| प्राथमिक | ख | रेफरी | idx_big_table_attr_date | idx_big_table_attr_date | 5 | a.attr_id | 6949780 | जहाँ का उपयोग करना |
जो हमें बताता है कि
big_table को वांछित सूचकांक में स्कैन किया जाएगा, लेकिन सूचकांक पूरी तरह से शामिल नहीं होगा, अर्थात इसमें से केवल पहले कॉलम का उपयोग किया जाएगा । कुछ पतित मामलों में, हम अपनी ज़रूरत की योजना को प्राप्त कर सकते हैं और सूचकांक का पूरा उपयोग कर सकते हैं, हालाँकि, ऑप्टिमाइज़र की असंगतता और इस समाधान को लागू करने की असंभवता के कारण (मैं इसका कोड यहाँ नहीं दूंगा, यह 90% मामलों में काम नहीं करता है), सभी 100% मामलों में, हमें ज़रूरत है एक अलग दृष्टिकोण।
यह बढ़ोतरी हमें MySQL खुद प्रदान करती है। हम स्पष्ट रूप से
बाइंड चर को स्पष्ट रूप से निर्दिष्ट करेंगे। बेशक, यह कई कार्यों के लिए हमेशा प्रभावी नहीं होता है, क्योंकि ऐसा होता है कि एक पूर्ण स्कैन एक इंडेक्स स्कैन की तुलना में तेज होता है, लेकिन जाहिर है कि हमारे मामले में नहीं जब आपको 250,000 से 500 प्रविष्टियों का चयन करने की आवश्यकता होती है। समस्या को हल करने के लिए, हमें निम्नलिखित प्रक्रिया बनाने की आवश्यकता है।
drop procedure if exists get_big_table_data;
delimiter $$
create procedure get_big_table_data(i_attr_from int (10))
main_sql:
begin
declare v_attr_id int (10);
declare v_start_date datetime;
declare v_end_date datetime;
declare ex_no_records_found int (10) default 0;
declare
attr cursor for
select attr_id, start_date, end_date
from attributes
where attr_id > i_attr_from;
declare continue handler for not found set ex_no_records_found = 1;
declare continue handler for sqlstate '42S01' begin
end ;
create temporary table if not exists temp_big_table_results(
attr_attr_id int (10) unsigned,
max_record_date datetime,
min_record_date datetime,
max_record_value varchar (128),
cnt int (10)
)
engine = innodb;
truncate table temp_big_table_results;
open attr;
repeat
fetch attr
into v_attr_id, v_start_date, v_end_date;
if not ex_no_records_found then
insert into temp_big_table_results(attr_attr_id,
max_record_date,
min_record_date,
max_record_value,
cnt
)
select attr_attr_id,
max (record_date) max_record_date,
min (record_date) min_record_date,
max (record_value) max_record_value,
count (1) cnt
from big_table b
where attr_attr_id = v_attr_id and record_date between v_start_date and v_end_date
group by attr_attr_id;
end if ;
until ex_no_records_found
end repeat;
close attr;
select attr_attr_id,
max_record_date,
min_record_date,
max_record_value,
cnt
from temp_big_table_results;
end
$$
delimiter ;
* This source code was highlighted with Source Code Highlighter .
यानी शुरुआत में हम विशेषता तालिका के पाँच सौ रिकॉर्ड पर कर्सर खोलते हैं, और इस तालिका की प्रत्येक पंक्ति के लिए हम
big_table से एक अनुरोध
करते हैं । आइए देखें परिणाम:
call get_big_table_data(0);
* This source code was highlighted with Source Code Highlighter .
रनटाइम:
0: 00: 05.017 IMHO परिणाम बहुत बेहतर है। सही नहीं है, लेकिन यह काम करता है।
अब हम विपरीत उदाहरण पर विचार कर सकते हैं, जब खोज "लेनदेन" तालिका में नहीं, बल्कि तथ्य तालिका में की जाती है।
यह बग दिखाई देता है यदि आप:
- जियोआईपी डेटाबेस के साथ काम करें
- अनुसूची का विश्लेषण करने की कोशिश कर रहा है
- विदेशी मुद्रा पर मुद्रा दरों को ठीक करें
- ऑपरेटर की संख्या क्षमता द्वारा शहर की गणना करें
आदि
सबसे पहले, 25 मिलियन पंक्तियों का एक परीक्षण डेटा सेट बनाएं।
drop table if exists big_range_table; create table big_range_table(rtbl_id int(10) unsigned auto_increment, value_from int(10) unsigned, value_to int(10) unsigned, range_value varchar(128), constraint pk_big_range_table primary key(rtbl_id) ) engine = innodb; insert into big_range_table(value_from, value_to, range_value) select @row_number := @row_number + 1, @row_number + 1, p1.row_number + p2.row_number + p3.row_number from (select * from pivot where row_number <= 100) p1, pivot p2, pivot p3, (select @row_number := 0) counter; create index idx_big_range_table_from_to on big_range_table(value_from, value_to); create index idx_big_range_table_from on big_range_table(value_from);
फॉर्म की एक तालिका प्राप्त करें
| rtbl_id | value_from | value_to | range_value |
| 1 | 1 | 2 | 3 |
| 2 | 2 | 3 | 4 |
| 3 | 3 | 4 | 5 |
और आगे बढ़ने पर, एक क्वेरी को निष्पादित करने का प्रयास करें जो MySQL को छोड़कर सभी DBMS द्वारा सफलतापूर्वक अनुकूलित किया गया है:
select range_value from big_range_table where 10000000.5 >= value_from and 10000000.5 < value_to;
लीड समय:
0: 00: 22.412 । सामान्य तौर पर, यह एक विकल्प नहीं है, यह देखते हुए कि हम जानते हैं कि इस तरह के अनुरोध को एक अद्वितीय पंक्ति वापस करना चाहिए। और आपके द्वारा चुने गए चर का मूल्य जितना अधिक होगा - उतना अधिक रिकॉर्ड स्कैन किया जाएगा, क्वेरी रन समय तेजी से बढ़ता है।
MySQL स्वयं इस समस्या को हल करने के लिए निम्न समाधान प्रस्तुत करता है:
select range_value from big_range_table where value_from <= 25000000 order by value_from desc limit 1;
लीड समय:
0: 00: 00.350 । बुरा नहीं है। लेकिन इस समाधान में कई कमियां हैं, विशेष रूप से, आप अन्य तालिकाओं के साथ शामिल नहीं हो पाएंगे। यानी यह अनुरोध विशेष रूप से परमाणु में मौजूद हो सकता है। जुड़ने की संभावना के लिए, हम मानक RTree सूचकांक समाधान का उपयोग करेंगे (जब तक कि आपकी निर्देशिका को लेनदेन की आवश्यकता न हो या आप ट्रिगर के साथ इसकी अखंडता सुनिश्चित करते हैं, क्योंकि इस प्रकार का सूचकांक अभी भी केवल MyISAM के लिए काम करता है)। उन लोगों के लिए जो MySQL में ज्यामितीय वस्तुओं के बारे में नहीं जानते हैं, मैं इस बात का दृष्टांत दूंगा कि वे आमतौर पर ऐसे मामलों में क्या करते हैं:
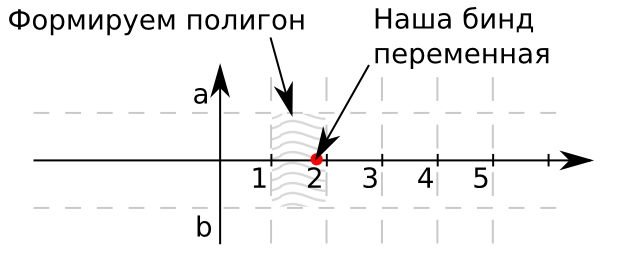
एक विमान की कल्पना करो। खोज के लिए abscissa अक्ष पर हमारे मूल्य होंगे। आपकी बात का समन्वय शून्य है, क्योंकि इस विशेष मामले में, सरलीकरण के लिए, हम केवल एक मानदंड के
बीच खोज करेंगे। यदि बहुआयामी वस्तुओं का उपयोग करने के लिए मानदंड अधिक आवश्यक हैं। आयत a और b की सीमाएँ क्रमशः 1 और -1 हैं। इस प्रकार, हमारी संदर्भ पुस्तक के मान 0. से बाहर निकलने वाली किरण को कवर करेंगे। इसके अलावा, वे छायांकित आयतों के सेट द्वारा सीमित होंगे। यदि बिंदु इस आयत का है, तो इस आयत का पहचानकर्ता हमें तालिका में रिकॉर्ड का वांछित पहचानकर्ता देता है। हम रूपांतरण शुरू करते हैं:
alter table big_range_table engine = myisam, add column polygon_value polygon not null; update big_range_table set polygon_value = geomfromwkb(polygon(linestring( point(value_from, -1), point(value_to, -1), point(value_to, 1), point(value_from, 1), point(value_from, -1) )));
उन लोगों के लिए जिन्होंने मेरे साथ इस ऑपरेशन को करने की हिम्मत की, हम
अपडेट के अंतिम समय की निगरानी करते हैं।
select (select @first_value := variable_value from information_schema.global_status where variable_name = 'HANDLER_UPDATE') updated, sleep(10) lets_sleep, (select @second_value := variable_value from information_schema.global_status where variable_name = 'HANDLER_UPDATE') updated_in_a_ten_second, @second_value - @first_value myisam_updated_records, 25000000 / (@second_value - @first_value) / 6 estimate_for_update_in_minutes, (select 25000000 / (@second_value - @first_value) / 6 - time / 60 from information_schema.processlist where info like 'update big_range_table%') estimate_time_left_in_minutes;
यदि आप इस चरण पर पहुंच गए हैं, तो मैं आपको सलाह देता हूं कि ऐसा न करें, क्योंकि गलत डेटाबेस सेटिंग्स के साथ इस सूचकांक के निर्माण में एक सप्ताह लग सकता है।
create spatial index idx_big_range_table_polygon_value on big_range_table(polygon_value);
खैर अब आप काम की गति की तुलना कर सकते हैं। पहले, आइए अनुरोध के प्रारंभिक संस्करण के निष्पादन की गति और "ज्यामितीय" को देखें, धीरे-धीरे
सीमा मूल्य को 10 से बढ़ाकर 100 किया जाए।
select * from (select row_number * 5000 row_number from pivot order by row_number limit 10) p, big_range_table where mbrcontains(polygon_value, pointfromwkb(point(row_number, 0))) and row_number < value_to; select * from (select row_number * 5000 row_number from pivot order by row_number limit 10) p, big_range_table where value_from <= row_number and row_number < value_to;

बाईं ओर समय है, नीचे सीमा का मूल्य है। जैसा कि आप आंकड़ा से देख सकते हैं, (नीला) के बीच का समय तेजी से बढ़ता है, यह इस बात पर निर्भर करता है कि हम शुरुआत में हैं या अंत के करीब हैं, क्योंकि बाइंड चर के प्रत्येक अगले मूल्य के लिए हमें अधिक से अधिक लाइनों को स्कैन करने की आवश्यकता होती है। ऐसे छोटे मूल्यों पर "ज्यामितीय" समाधान (गुलाबी) बस एक स्थिर है।
आइए बड़े मानों के लिए
सीमा 1 और
ज्यामिति द्वारा आदेश की तुलना
करने का प्रयास करें। ऐसा करने के लिए, हम एक स्तर का खेल मैदान बनाने और यादृच्छिक नमूने का संचालन करने के लिए प्रक्रियाओं का उपयोग करते हैं।
drop procedure if exists pbenchmark_mbrcontains;
delimiter $$
create procedure pbenchmark_mbrcontains(i_repeat_count int (10))
main_sql:
begin
declare v_random int (10);
declare v_range_value int (10);
declare v_loop_counter int (10) unsigned default 0;
begin_loop:
loop
set v_loop_counter = v_loop_counter + 1;
if v_loop_counter < i_repeat_count then
set v_random = round(2500000 * rand());
select range_value
into v_range_value
from big_range_table
where mbrcontains(polygon_value, pointfromwkb(point(v_random, 0))) and v_random < value_to;
iterate begin_loop;
end if ;
leave begin_loop;
end loop begin_loop;
select v_loop_counter;
end
$$
delimiter ;
drop procedure if exists pbenchmark_limit;
delimiter $$
create procedure pbenchmark_limit(i_repeat_count int (10))
main_sql:
begin
declare v_random int (10);
declare v_range_value int (10);
declare v_loop_counter int (10) unsigned default 0;
begin_loop:
loop
set v_loop_counter = v_loop_counter + 1;
if v_loop_counter < i_repeat_count then
set v_random = round(2500000 * rand());
select range_value
into v_range_value
from big_range_table
where value_from <= v_random order by value_from desc limit 1;
iterate begin_loop;
end if ;
leave begin_loop;
end loop begin_loop;
select v_loop_counter;
end
$$
delimiter ;
* This source code was highlighted with Source Code Highlighter .
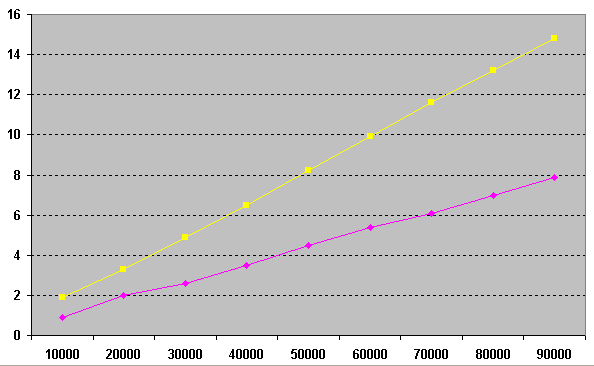
ग्राफ पर हम देखते हैं कि प्रक्रिया की संख्या में क्रमिक वृद्धि का परिणाम 10,000 से 90,000 से शुरू होता है और इसी ऑपरेशन पर खर्च होने वाले सेकंड की संख्या। जैसा कि आप देख सकते हैं, "ज्यामितीय" समाधान (गुलाबी)
सीमा 1 (पीला)
द्वारा आदेश का उपयोग कर समाधान की तुलना में 2 गुना तेज है, और इसके अलावा, यह समाधान मानक SQL में लागू किया जा सकता है।
मैंने इस विषय को पूरी तरह से कवर किया क्योंकि डेटा जाम कम मात्रा में डेटा पर दिखाई नहीं देता है, लेकिन जब डेटाबेस बढ़ता है और 10 से अधिक उपयोगकर्ता उस पर रहना शुरू करते हैं, तो प्रदर्शन में गिरावट केवल राक्षसी हो जाती है, और इस प्रकार के प्रश्न लगभग हर में पाए जा सकते हैं। औद्योगिक डेटाबेस।
अपनी आशाओं के साथ शुभकामनाएँ। यदि यह लेख अगली बार दिलचस्प है, तो मैं आपको उन बगों के बारे में बताऊंगा जो न केवल जीवन में हस्तक्षेप करते हैं, बल्कि इसके विपरीत भी - वे सही तरीके से उपयोग किए जाने पर प्रश्नों के प्रदर्शन को बढ़ाते हैं।
ZY
MySQL संस्करण 5.5.11
परिणाम प्राप्त करने से कैश को रोकने के लिए MySQL रिबूट के बाद सभी प्रश्न किए गए थे।
MySQL सेटिंग्स मानक से बहुत दूर हैं, लेकिन निर्दोष बफ़र्स का आकार 300 एमबी से अधिक नहीं है, MyISAM बफ़र्स का आकार (सूचकांक बनाए जाने के क्षण के अपवाद के साथ) 100Mb से अधिक नहीं है।
फ़ाइल आकार का उपयोग:
big_range_table.ibd 1740M
big_table.ibd 5520M - कोई अनुक्रमणिका नहीं
big_table.ibd 8268M - सूचकांकों के साथ
यानी क्वेरी की शुरुआत से पहले डेटाबेस कैश में ऑब्जेक्ट प्राप्त करना पूरी तरह से बाहर रखा गया है।