
मैं
संपीड़न एल्गोरिदम के बारे में अपने पिछले विषय को जारी रखना चाहूंगा। इस बार मैं LZW एल्गोरिथ्म के बारे में और इसके रिश्तेदारों, LZ77 और LZ78 एल्गोरिदम के बारे में थोड़ा बात करूंगा।
एलजेडडब्ल्यू एल्गोरिदम
Lempel-Ziv-Welch (LZW) एल्गोरिथ्म एक सार्वभौमिक दोषरहित डेटा संपीड़न एल्गोरिथ्म है।LZW के तत्काल पूर्ववर्ती LZ78 एल्गोरिथ्म थे, जो अब्राहम लेम्पेल और जैकब ज़िव द्वारा 1978 में प्रकाशित किया गया था। इस एल्गोरिथ्म को 1984 तक गणितीय अमूर्त माना जाता था, जब टेरी ए वेल्च ने अपने काम को संशोधित के साथ प्रकाशित किया था। एल्गोरिथ्म, जिसे बाद में LZW (लेम्पेल-ज़िव-वेल्च) कहा जाता है।
विवरण
संपीड़न प्रक्रिया इस प्रकार है। इनपुट स्ट्रीम के पात्रों को क्रमिक रूप से पढ़ा जाता है और यह देखने के लिए एक चेक बनाया जाता है कि क्या इस तरह की लाइन बनाई गई पंक्ति तालिका में मौजूद है। यदि ऐसी रेखा मौजूद है, तो अगला वर्ण पढ़ा जाता है, और यदि रेखा मौजूद नहीं है, तो पिछली पाया गई पंक्ति के लिए कोड को स्ट्रीम में दर्ज किया जाता है, लाइन को तालिका में दर्ज किया जाता है, और फिर से खोज शुरू होती है।
उदाहरण के लिए, यदि बाइट डेटा (पाठ) संपीड़ित है, तो तालिका में पंक्तियाँ 256 ("0" से "255" तक) होंगी। यदि 10-बिट कोड का उपयोग किया जाता है, तो पंक्तियों के लिए कोड के तहत, मान 256 से 1023 तक सीमा में रहते हैं। नई पंक्तियाँ क्रमिक रूप से तालिका बनाती हैं, अर्थात, पंक्ति सूचकांक को इसका कोड माना जा सकता है।
इनपुट डिकोडिंग एल्गोरिथ्म को केवल एन्कोडेड पाठ की आवश्यकता होती है, क्योंकि यह संबंधित रूपांतरण तालिका को सीधे एन्कोडेड पाठ से फिर से बना सकता है। एल्गोरिथ्म इस तथ्य के कारण एक विशिष्ट डिकोड कोड उत्पन्न करता है कि हर बार एक नया कोड उत्पन्न होने पर, पंक्ति तालिका में एक नई पंक्ति जोड़ी जाती है। LZW लगातार यह देखने के लिए जांचता है कि क्या स्ट्रिंग पहले से ही ज्ञात है, और, यदि हां, तो एक नया उत्पन्न किए बिना मौजूदा कोड प्रदर्शित करता है। इस प्रकार, प्रत्येक पंक्ति को एक ही प्रतिलिपि में संग्रहीत किया जाएगा और इसकी अपनी विशिष्ट संख्या होगी। इसलिए, डिक्रिप्ट करते समय, जब एक नया कोड प्राप्त होता है, तो एक नई लाइन उत्पन्न होती है, और जब यह पहले से ही ज्ञात होता है, तो शब्दकोश से एक लाइन निकाली जाती है।
एल्गोरिदम स्यूडोकोड
- सभी संभव एकल-वर्ण वाक्यांशों के साथ शब्दकोश की शुरुआत। संदेश के पहले चरित्र द्वारा इनपुट वाक्यांश ω का प्रारंभ।
- एन्कोडेड संदेश से अगला वर्ण K पढ़ें।
- यदि END MESSAGES, तो otherwise के लिए कोड जारी करें, अन्यथा:
- यदि वाक्यांश, (K) पहले से ही शब्दकोश में है, तो इनपुट वाक्यांश के लिए) (K) मान निर्दिष्ट करें और चरण 2 पर जाएं, अन्यथा कोड Step को आउटपुट करें, शब्दकोश में ω (K) जोड़ें, इनपुट वाक्यांश के लिए मान K असाइन करें और चरण 2 पर जाएं।
- अंत
उदाहरण
यह सिर्फ इतना है कि छद्म कोड का उपयोग करके एल्गोरिथ्म के संचालन को समझना बहुत आसान नहीं है, इसलिए इस पर ध्यान दें। छवि संपीड़न और डिकोडिंग के एक उदाहरण पर विचार करें।
सबसे पहले, एकल वर्णों का एक प्रारंभिक शब्दकोश बनाएं। मानक ASCII एन्कोडिंग में 256 विभिन्न वर्ण हैं, इसलिए, उन सभी को सही ढंग से एन्कोड करने के लिए (यदि हमें नहीं पता है कि स्रोत फ़ाइल में कौन से वर्ण मौजूद होंगे और जो नहीं होगा), तो प्रारंभिक कोड आकार 8 बिट्स होगा। यदि हम पहले से जानते हैं कि स्रोत फ़ाइल में कम भिन्न वर्ण होंगे, तो बिट्स की संख्या को कम करना काफी उचित है। तालिका को आरंभ करने के लिए, हम बिट कोड 00000000 के साथ संबंधित वर्ण के लिए कोड 0 के पत्राचार को स्थापित करेंगे, फिर 1 कोड 00000001, आदि के साथ वर्ण से मेल खाता है, कोड 255 तक। वास्तव में, हमने संकेत दिया था कि प्रत्येक कोड 0 से 255 तक जड़ है।
तालिका में अन्य गुण नहीं होंगे जिनमें यह गुण है।
जैसे ही शब्दकोश बढ़ता है, नए तत्वों को ध्यान में रखने के लिए समूहों का आकार बढ़ना चाहिए। 8-बिट समूह बिट्स के 256 संभावित संयोजन देते हैं, इसलिए जब शब्दकोश में 256 वां शब्द दिखाई देता है, तो एल्गोरिथ्म को 9-बिट समूहों में जाना चाहिए। जब 512 वां शब्द प्रकट होता है, तो 10-बिट समूहों में एक संक्रमण होगा, जो पहले से ही 1024 शब्दों को याद रखना संभव बनाता है, आदि।
हमारे उदाहरण में, एल्गोरिथ्म अग्रिम में जानता है कि केवल 5 अलग-अलग वर्णों का उपयोग किया जाएगा, इसलिए, उन्हें संग्रहीत करने के लिए न्यूनतम बिट्स का उपयोग किया जाएगा, जिससे हमें उन्हें याद रखने की अनुमति मिलती है, वह है 3 (8 विभिन्न संयोजन)।
कोडिंग
आइए हम "abacabadabacabae" अनुक्रम को संक्षिप्त करें।
- चरण 1: फिर, उपरोक्त एल्गोरिथ्म के अनुसार, हम "a" को शुरू में खाली पंक्ति में जोड़ देंगे और जाँचेंगे कि क्या पंक्ति "a" तालिका में है। चूंकि आरंभीकरण के दौरान हमने एक वर्ण की सभी पंक्तियों को तालिका में दर्ज किया था, इसलिए पंक्ति "a" तालिका में है।
- चरण 2: अगला, हम इनपुट स्ट्रीम से अगला वर्ण "बी" पढ़ते हैं और जांचते हैं कि क्या तालिका में एक स्ट्रिंग "एब" है। तालिका में अभी तक ऐसी कोई पंक्ति नहीं है।
- तालिका में जोड़ें <5> "अब"। स्ट्रीम करने के लिए: <0>;
- चरण 3: "बा" - नहीं। टेबल पर: <6> "बा"। स्ट्रीम करने के लिए: <1>;
- चरण 4: "एसी" नहीं है। टेबल पर: <7> "एसी"। स्ट्रीम करने के लिए: <0>;
- चरण 5: "सीए" - नहीं। टेबल पर: <8> "सीए"। स्ट्रीम करने के लिए: <2>;
- चरण 6: "अब" - तालिका में है; "अबा" नहीं है। टेबल पर: <9> "अबा"। स्ट्रीम करने के लिए: <5>;
- चरण 7: "विज्ञापन" - नहीं। टेबल पर: <10> "विज्ञापन"। स्ट्रीम करने के लिए: <0>;
- चरण 8: "दा" - नहीं। टेबल पर: <11> "दा"। स्ट्रीम करने के लिए: <3>;
- चरण 9: "अबा" - तालिका में है; "अबैक" नहीं है। टेबल पर: <12> "अबेक"। स्ट्रीम करने के लिए: <9>;
- चरण 10: "सीए" - तालिका में है; "टैक्सी" - नहीं। टेबल पर: <13> "कैब"। स्ट्रीम करने के लिए: <8>;
- चरण 11: "बा" - तालिका में है; "Bae" नहीं है। टेबल पर: <14> "बाए"। स्ट्रीम करने के लिए: <6>;
- चरण 12: और अंत में, अंतिम पंक्ति "ई", जिसके बाद संदेश समाप्त होता है, इसलिए हम बस स्ट्रीम करने के लिए आउटपुट करते हैं <4>।
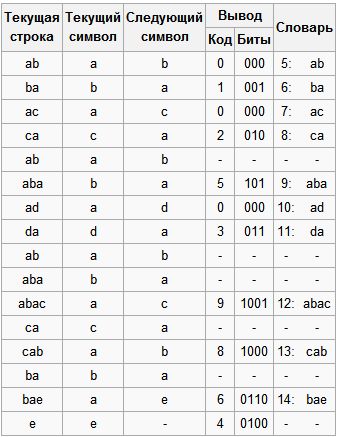
तो, हमें एन्कोडेड संदेश "0 1 0 2 5 0 3 9 8 6 4" मिलता है, जो कि 11 बिट्स छोटा है।
डिकोडिंग
एलजेडडब्ल्यू की ख़ासियत यह है कि विघटन के लिए हमें पैकेजिंग के लिए एक फ़ाइल में लाइनों की तालिका को बचाने की आवश्यकता नहीं है। एल्गोरिथ्म इस तरह से बनाया गया है कि हम केवल कोड की एक धारा का उपयोग करके पंक्तियों की तालिका को पुनर्स्थापित करने में सक्षम हैं।
अब कल्पना करें कि हमें ऊपर एन्कोडेड संदेश मिला है, और हमें इसे डिकोड करने की आवश्यकता है। सबसे पहले, हमें प्रारंभिक शब्दकोश को जानने की आवश्यकता है, और हम चलते-फिरते शब्दकोश में बाद की प्रविष्टियों को फिर से संगठित कर सकते हैं, क्योंकि वे पिछली प्रविष्टियों का एक संयोजन हैं।

इसके अलावा
इस विधि का उपयोग करके छवि संपीड़न की डिग्री बढ़ाने के लिए, इस एल्गोरिदम को लागू करने की एक "चाल" अक्सर उपयोग की जाती है। कुछ फाइलें जो LZW का उपयोग करके संपीड़ित होती हैं उनमें अक्सर समान वर्णों के तार होते हैं, उदाहरण के लिए आआआआ ... या 30, 30, 30 ... आदि। उनका सीधा संपीड़न आउटपुट कोड 0, 0, 5, आदि उत्पन्न करेगा। सवाल यह है कि क्या इस विशेष मामले में संपीड़न अनुपात को बढ़ाना संभव है?
यह पता चला है कि यह संभव है अगर हम कुछ कार्यों को निर्धारित करते हैं:
हम जानते हैं कि प्रत्येक कोड के लिए हमें टेबल पर एक पंक्ति जोड़ने की आवश्यकता है जिसमें पहले से ही मौजूद एक लाइन है और एक चरित्र जिसके साथ धारा में अगली पंक्ति शुरू होती है।
- तो, एनकोडर पहले "a" को स्ट्रिंग में डालता है, शब्दकोश में "a" खोजता है और खोजता है। निम्नलिखित "ए" को पंक्ति में जोड़ता है, पाता है कि "आ" शब्दकोष में नहीं है। फिर वह शब्दकोश में प्रविष्टि <5>: "आ" जोड़ता है और आउटपुट स्ट्रीम में लेबल <0> ("ए") प्रदर्शित करता है।
- इसके बाद, लाइन को दूसरे "a" द्वारा इनिशियलाइज़ किया जाता है, अर्थात, यह "a;" का रूप ले लेता है। तीसरी "a" दर्ज की जाती है, लाइन फिर से "aa" के बराबर होती है, जो अब डिक्शनरी में है।
- यदि चौथा “ए” प्रतीत होता है, तो लाइन “आ?” “आ” के बराबर है, जो शब्दकोश में नहीं है। इस पंक्ति के साथ शब्दकोश अपडेट किया गया है, और आउटपुट <5> ("आ") चिह्नित है।
- उसके बाद, लाइन को तीसरे "ए", आदि द्वारा प्रारंभ किया जाता है। आदि आगे की प्रक्रिया काफी स्पष्ट है।
- नतीजतन, हमें 0, 5, 6 ... का क्रम मिलता है, जो मानक LZW विधि का उपयोग करके सीधे कोडिंग से छोटा है।
यह दिखाया जा सकता है कि इस तरह के अनुक्रम को सही ढंग से बहाल किया जाएगा। डिकोडर पहले पहले कोड को पढ़ता है - यह <0> है, जो चरित्र "ए" से मेल खाता है। फिर यह कोड <5> पढ़ता है, लेकिन यह कोड इसकी तालिका में नहीं है। लेकिन हम पहले से ही जानते हैं कि इस तरह की स्थिति केवल तभी संभव है जब जोड़ा गया चरित्र केवल पढ़े गए अनुक्रम के पहले चरित्र के बराबर हो, यानी "ए"। इसलिए, वह अपनी मेज पर कोड <5> के साथ स्ट्रिंग "आ" जोड़ देगा, और आउटपुट स्ट्रीम में "आ" डाल देगा। और इसलिए कोडों की पूरी श्रृंखला को डिकोड किया जा सकता है।
इसके अलावा, हम सामान्य स्थिति में ऊपर वर्णित कोडिंग नियम को न केवल लगातार समान वर्णों पर लागू कर सकते हैं, बल्कि उन अनुक्रमों में भी जोड़ सकते हैं जिनमें अगला जोड़ा गया वर्ण श्रृंखला के पहले वर्ण के बराबर है।
फायदे और नुकसान
+ वर्ण या कोड की घटना की संभावनाओं की गणना की आवश्यकता नहीं है।
+ अपघटन के लिए यह आवश्यक नहीं है कि अनपैकिंग के लिए फ़ाइल में लाइनों की तालिका को बचाया जाए। एल्गोरिथ्म इस तरह से बनाया गया है कि हम केवल कोड की एक धारा का उपयोग करके पंक्तियों की तालिका को पुनर्स्थापित करने में सक्षम हैं।
+ इस प्रकार का संपीड़न मूल छवि फ़ाइल को विकृत नहीं करता है, और किसी भी प्रकार के रेखापुंज डेटा को संपीड़ित करने के लिए उपयुक्त है।
- एल्गोरिथ्म इनपुट डेटा का विश्लेषण नहीं करता है, इसलिए, इष्टतम नहीं है।
आवेदन
LZW एल्गोरिथ्म के प्रकाशन ने सभी सूचना संपीड़न विशेषज्ञों पर एक शानदार छाप छोड़ी। इसके बाद इस पद्धति के विभिन्न रूपों के साथ बड़ी संख्या में कार्यक्रम और अनुप्रयोग हुए।
यह विधि आपको ग्राफिक डेटा को संपीड़ित करने के लिए अन्य मौजूदा तरीकों में से एक सबसे अच्छा संपीड़न अनुपात प्राप्त करने की अनुमति देती है, स्रोत फ़ाइलों में नुकसान या विरूपण की पूर्ण अनुपस्थिति में। वर्तमान में इसका उपयोग TIFF, PDF, GIF, पोस्टस्क्रिप्ट और अन्य फ़ाइलों के साथ-साथ कई लोकप्रिय डेटा कम्प्रेशन प्रोग्राम (ZIP, ARJ, LHA) में किया जाता है।
एल्गोरिदम LZ77 और LZ78
LZ77 और LZ78 1977 और 1978 में अब्राहम लेम्पेल और जैकब ज़िव द्वारा प्रकाशित दोषरहित संपीड़न एल्गोरिदम हैं। ये एल्गोरिदम LZ * परिवार में सबसे अच्छी तरह से जाना जाता है, जिसमें LZW, LZSS, LZMA और अन्य एल्गोरिदम भी शामिल हैं। दोनों एल्गोरिदम शब्दावली-आधारित एल्गोरिदम से संबंधित हैं। LZ77 तथाकथित "स्लाइडिंग विंडो" का उपयोग करता है, जो पहले LZ78 में प्रस्तावित शब्दावली दृष्टिकोण के निहित उपयोग के बराबर है।ऑपरेशन LZ77 का सिद्धांत
एल्गोरिथ्म का मुख्य विचार स्ट्रिंग की बार-बार होने वाली घटना को पिछली प्रविष्टि स्थितियों में से एक लिंक के साथ बदलना है। ऐसा करने के लिए, स्लाइडिंग विंडो विधि का उपयोग करें। एक स्लाइडिंग विंडो को एक गतिशील डेटा संरचना के रूप में दर्शाया जा सकता है, जो इस तरह से "पहले" जानकारी को याद रखने और इसे एक्सेस प्रदान करने के लिए आयोजित की जाती है। इस प्रकार, LZ77 के अनुसार संपीड़न कोडिंग प्रक्रिया एक प्रोग्राम लिखने की याद दिलाती है, जिसके कमांड आपको स्लाइडिंग विंडो के तत्वों तक पहुंचने की अनुमति देते हैं, और संपीड़ित अनुक्रम के मूल्यों के बजाय, स्लाइडिंग विंडो में इन मूल्यों के लिंक डालें। मानक LZ77 एल्गोरिथ्म में, स्ट्रिंग मैच एक जोड़ी द्वारा एन्कोड किए गए हैं:
- मैच की लंबाई
- ऑफसेट या दूरी
एन्कोडेड जोड़ी को एक निश्चित स्थिति से एक स्लाइडिंग विंडो से वर्णों की प्रतिलिपि बनाने के लिए एक कमांड के रूप में, या शाब्दिक रूप से व्याख्या की जाती है: "ऑफ़सेट वर्णों के शब्दकोष पर लौटें और वर्तमान स्थिति से शुरू होकर वर्णों की लंबाई के मान की प्रतिलिपि बनाएँ"। इस संपीड़न एल्गोरिदम की एक विशेषता यह है कि एन्कोडेड लंबाई-ऑफसेट जोड़ी का उपयोग न केवल स्वीकार्य है, बल्कि उन मामलों में भी प्रभावी है जहां लंबाई मूल्य ऑफसेट मूल्य से अधिक है। कॉपी कमांड के साथ उदाहरण पूरी तरह से स्पष्ट नहीं है: "बफर में 1 वर्ण वापस जाएं और वर्तमान स्थिति से शुरू होने वाले 7 वर्णों को कॉपी करें।" मैं बफर से 7 वर्णों की प्रतिलिपि कैसे बना सकता हूं जब वर्तमान में केवल 1 वर्ण बफर में है? हालांकि, कोडिंग जोड़ी की निम्नलिखित व्याख्या स्थिति को स्पष्ट कर सकती है: प्रत्येक 7 बाद के अक्षर उनके सामने 1 वर्ण के साथ मेल खाते हैं (समतुल्य)। इसका मतलब है कि प्रत्येक चरित्र को बफर में वापस जाने से विशिष्ट रूप से निर्धारित किया जा सकता है, भले ही यह चरित्र वर्तमान लंबाई-ऑफसेट जोड़ी को डिकोड करने के समय बफर में नहीं है।
एल्गोरिथम विवरण
LZ77 एक संदेश-स्लाइडिंग विंडो का उपयोग करता है। मान लीजिए कि खिड़की वर्तमान पुनरावृत्ति पर बंद है। विंडो के दाईं ओर, हम प्रतिस्थापन का विस्तार करते हैं जबकि यह लाइन में है <स्लाइडिंग विंडो + एक्सपेंडेबल लाइन> और स्लाइडिंग विंडो में शुरू होता है। हम स्टैकेबल स्ट्रिंग बफर कहते हैं। निर्माण के बाद, एल्गोरिथ्म एक कोड बनाता है जिसमें तीन तत्व होते हैं:
- खिड़की में ऑफसेट;
- बफर लंबाई;
- बफर का अंतिम चरित्र।
पुनरावृत्ति के अंत में, एल्गोरिथ्म विंडो को बफर + 1 की लंबाई के बराबर लंबाई से बदलता है।
कबजबबज उदाहरण

एल्गोरिथ्म LZ78 का विवरण
LZ77 के विपरीत, जो पहले से प्राप्त डेटा के साथ काम करता है, LZ78 केवल प्राप्त होने वाले डेटा पर ध्यान केंद्रित करता है (LZ78 एक स्लाइडिंग विंडो का उपयोग नहीं करता है, यह पहले से ही देखे गए वाक्यांशों का एक शब्दकोश संग्रहीत करता है)। एल्गोरिथ्म संदेश पात्रों को तब तक पढ़ता है जब तक कि संचित विकल्प पूरी तरह से डिक्शनरी वाक्यांशों में से एक में शामिल न हो जाए। जैसे ही यह पंक्ति शब्दकोश में कम से कम एक वाक्यांश से मेल नहीं खाती है, एल्गोरिथ्म शब्दकोश में लाइन इंडेक्स से मिलकर एक कोड बनाता है, जो कि अंतिम वर्ण में इनपुट लाइन में प्रविष्ट होने तक, और मैच का उल्लंघन करने वाला वर्ण। इसके बाद, डिसप्ले किए गए विकल्प को शब्दकोश में जोड़ा जाता है। यदि शब्दकोश पहले से ही भरा हुआ है, तो तुलना में उपयोग किए जाने वाले वाक्यांश को पहले से हटा दिया गया है। यदि एल्गोरिथ्म के अंत में हमें मैचों का उल्लंघन करने वाला चरित्र नहीं मिलता है, तो हम कोड को फॉर्म में जारी करते हैं (अंतिम वर्ण के बिना शब्दकोश में पंक्ति का सूचकांक, अंतिम वर्ण)।
कबजबबज उदाहरण
