अक्टूबर में,
हब पर काम करने के बारे में एक अद्भुत
लेख दिखाई दिया। इस विषय को जारी रखते हुए, मैं java.util.concurrent.ConcurrentHashMap के कार्यान्वयन के बारे में बात करने जा रहा हूं।
तो, समवर्ती हाशपा कैसे आया, इसके फायदे क्या हैं और इसे कैसे लागू किया गया।
समवर्ती हाशिए बनाने के लिए आवश्यक शर्तें
JDK 1.5 में ConcurrentHashMap की शुरुआत से पहले, हैश टेबल का वर्णन करने के कई तरीके थे।
मूल रूप से JDK 1.0 में, हैशटेबल वर्ग था। हैशटेबल हैश टेबल कार्यान्वयन का उपयोग करने के लिए एक थ्रेड सुरक्षित और आसान है। हैशटेबल के साथ समस्या यह थी कि सबसे पहले, तालिका के तत्वों को एक्सेस करते समय, यह पूरी तरह से बंद था। सभी हैशटेबल विधियों को सिंक्रनाइज़ किया गया था। यह बहु-थ्रेडेड वातावरण के लिए एक गंभीर सीमा थी, क्योंकि पूरी मेज पर ताला लगाने का शुल्क बहुत बड़ा था।
JDK 1.2 में, हैशटेबल हैशटेबल और इसके थ्रेड-सुरक्षित प्रेजेंटेशन, कलेक्शंस.सिन सिंक्रोनाइज़ेशन के बचाव में आया। इस अलगाव के कई कारण थे:
- प्रत्येक प्रोग्रामर या हर समाधान को थ्रेड-सुरक्षित हैश तालिका की आवश्यकता नहीं थी
- प्रोग्रामर को यह चुनने की जरूरत है कि उसका उपयोग करने के लिए कौन सा विकल्प सुविधाजनक है।
इस प्रकार, JDK 1.2 के साथ, जावा में हैश मानचित्रों को लागू करने के विकल्पों की सूची को दो और तरीकों से पूरक किया गया है। हालांकि, इन विधियों ने डेवलपर्स को अपने कोड में दौड़ की स्थिति की उपस्थिति से नहीं बचाया, जो कि एक समवर्ती मैलोडिमएक्स अपवाद के रूप में हो सकता है।
यह लेख कोड में उनकी घटना के संभावित कारणों का विवरण देता है।
और इसलिए, जेडीके 1.5 में अंत में एक अधिक उत्पादक और मापनीय विकल्प है।
ConcurrentHashMap
जब तक ConcurrentHashMap दिखाई दिया, तब तक जावा डेवलपर्स को निम्नलिखित हैश मानचित्र कार्यान्वयन की आवश्यकता थी:
- धागा सुरक्षा
- इसके उपयोग के दौरान पूरे टेबल पर ताले की अनुपस्थिति
- यह वांछनीय है कि रीड ऑपरेशन करते समय टेबल लॉक नहीं होते हैं
डग ली एक ऐसी डेटा संरचना के लिए एक कार्यान्वयन विकल्प प्रस्तुत करता है, जिसे JDK 1.5 में शामिल किया गया है।
ConcurrentHashMap को लागू करने के लिए मुख्य विचार क्या हैं?
1. मानचित्र तत्व
HashMap तत्वों के विपरीत, ConcurrentHashMap में प्रविष्टि को अस्थिर घोषित किया गया है। यह एक महत्वपूर्ण विशेषता है, जो झामुमो के परिवर्तनों से भी संबंधित है। अस्थिर और संभावित दौड़ की स्थिति का उपयोग करने की आवश्यकता पर डग ले का जवाब
यहां पढ़ा जा सकता
है ।
स्थिर अंतिम वर्ग हैशंट्री <के, वी> {
अंतिम K कुंजी;
अंतिम इंट हैश;
वाष्पशील वी मूल्य;
अंतिम हैशंट्री <के, वी> अगला;
HashEntry (K कुंजी, int हैश, HashEntry <K, V> अगला, V मान) {
यह .key = कुंजी;
यह .hash = हैश;
यह .next = अगला;
this .value = मान;
}
@SuppressWarnings ("अनियंत्रित")
स्थिर अंतिम <K, V> HashEntry <K, V> [] newArray (int i) {
नई HashEntry [i] लौटाएं;
}
}
2. हैश फंक्शन
ConcurrentHashMap भी एक बेहतर हैश फ़ंक्शन का उपयोग करता है।
मुझे याद दिलाएं कि JDK 1.2 से हैशपॉप में ऐसा क्या था:
स्थिर इंट हैश (इंट एच) {
एच ^ = (एच >>> 20) ^ (एच >>> 12);
वापसी h ^ (h >>> 7) ^ (h >>> 4);
}
समवर्ती हाशपा JDK 1.5 से संस्करण:
निजी स्थिर इंट हैश (इंट एच) {
h + = (h << 15) ^ 0xffffcd7d;
एच ^ = (एच >>> 10);
h + = (h << 3);
एच ^ = (एच >>> 6);
h + = (h << 2) + (h << 14);
वापसी h ^ (एच >>> 16);
}
हैश फ़ंक्शन को जटिल करने की क्या आवश्यकता है? हैश मैप में तालिकाओं की लंबाई दो की शक्ति से निर्धारित होती है। हैश कोड के लिए जिनके द्विआधारी प्रतिनिधित्व जूनियर और वरिष्ठ पदों में भिन्न नहीं होते हैं, हमारे पास टकराव होंगे। हैश फ़ंक्शन की जटिलता इस समस्या को हल करती है, जिससे नक्शे में टकराव की संभावना कम हो जाती है।
3. खंड
कार्ड को एन अलग-अलग खंडों में विभाजित किया गया है (डिफ़ॉल्ट रूप से 16, अधिकतम मूल्य 16-बिट हो सकता है और दो की शक्ति का प्रतिनिधित्व कर सकता है)। प्रत्येक खंड मानचित्र तत्वों की एक थ्रेड-सुरक्षित तालिका है।
बिट मास्क हैश कोड के उच्चतर बिट्स के अनुप्रयोग के आधार पर कुंजी हैश कोड और संबंधित सेगमेंट के बीच एक निर्भरता स्थापित की जाती है।
यहां बताया गया है कि तत्व नक्शे में कैसे संग्रहीत किए जाते हैं:
अंतिम सेगमेंट <के, वी> [] सेगमेंट;
क्षणिक सेट <के> कीसेट;
क्षणिक सेट <Map.Entry <K, V >> entrySet;
क्षणिक संग्रह <V> मान;
विचार करें कि एक खंड वर्ग क्या है:
स्थिर अंतिम वर्ग सेगमेंट <K, V> ReentrantLock लागू करता है
सीरियल करने योग्य {
निजी स्थिर अंतिम लंबा सीरियलवर्जनयूआईडी = 2249069246763182397L;
क्षणिक वाष्पशील इंट काउंट;
क्षणिक int modCount;
क्षणिक इंट थ्रेसहोल्ड;
क्षणिक वाष्पशील हैशंट्री <के, वी> [] टेबल;
अंतिम फ्लोट लोडफैक्टर;
खंड (int initialCapacity, फ्लोट lf) {
loadFactor = lf;
setTable (HashEntry। <K, V> newArray (initialCapacity));
}
...
}
तालिका के भीतर प्रमुख हैश के छद्म-यादृच्छिक वितरण को देखते हुए, यह समझा जा सकता है कि सेगमेंट की संख्या बढ़ने से संशोधन कार्य विभिन्न खंडों को प्रभावित करेगा, जिससे रनटाइम पर ताले की संभावना कम हो जाएगी।
4. कंसीलर लिवेल
यह पैरामीटर मेमोरी कार्ड के उपयोग और कार्ड में खंडों की संख्या को प्रभावित करता है।
आइए एक नक्शा बनाने के बारे में देखें और पैरामीटर के रूप में निर्दिष्ट कंसीलर लिवेल कंस्ट्रक्टर कैसे प्रभावित करता है:
सार्वजनिक समवर्ती हाशपा (प्रारंभिक आरंभिकता, फ़्लोट लोडफ़ैक्टर, int समरूपता)
if ((loadFactor> 0) || आरंभिक क्षमता <0
|| संक्षिप्त नाम <= 0)
नई IllegalArgumentException () फेंकें;
अगर (संक्षिप्त नाम> MAX_SEGMENTS)
संगामिति = MAX_SEGMENTS;
// पावर-ऑफ-टू साइज़ बेस्ट मैचिंग आर्ग्युमेंट्स खोजें
int sshift = 0;
int ssize = 1;
जबकि (ssize <concurrencyLevel) {
++ sshift;
ssize << = 1;
}
सेगशिफ्ट = 32 - sshift;
सेगमास्क = ssize - 1;
यह .segment = Segment.newArray (ssize);
यदि (आरंभिकता> MAXIMUM_CAPACITY)
initialCapacity = MAXIMUM_CAPACITY;
int c = initialCapacity / ssize;
अगर (c * ssize <initialCapacity)
++ सी;
int cap = 1;
जबकि (कैप <c)
टोपी << = 1;
for (int i = 0; मैं <यह .seolution.length; ++ i)
यह .segment [i] = नया सेगमेंट <K, V> (कैप, लोडफैक्टर);
}
सेगमेंट की संख्या को समरूपता से दो की निकटतम शक्ति के रूप में चुना जाएगा। प्रत्येक सेगमेंट की क्षमता, क्रमशः निर्धारित की गई संख्या के सेगमेंट में डिफ़ॉल्ट कार्ड क्षमता के अनुपात के रूप में निर्धारित की जाएगी जो कि अधिक से अधिक डिग्री से दो की संख्या में प्राप्त होगी।
निम्नलिखित दो बातों को समझना बहुत महत्वपूर्ण है। संगामिति के कम आंकलन के कारण यह तथ्य सामने आता है कि लेखन के दौरान मैप सेगमेंट की धाराएं लॉक होने की अधिक संभावना है। ओवरस्टेटिंग से स्मृति का अक्षम उपयोग होता है।
कैसे संगामिति चुनें?
यदि केवल एक धागा नक्शा बदल देगा, और बाकी पढ़ा जाएगा, तो मूल्य 1 का उपयोग करने की सिफारिश की जाती है।
यह याद रखना चाहिए कि मानचित्र के अंदर भंडारण के लिए तालिकाओं का आकार परिवर्तन एक ऐसा ऑपरेशन है जिसमें अतिरिक्त समय की आवश्यकता होती है (और, अक्सर, तेज नहीं है)। इसलिए, एक नक्शा बनाते समय, आपको संभावित पढ़ने और लिखने के संचालन के आंकड़ों के कुछ मोटे अनुमानों की आवश्यकता होती है।
स्केलेबिलिटी का अनुमान है
Javamex पर, आप सिंक्रोनाइज़ेशन और ConcurrentHashMap की मापनीयता की तुलना करने पर
एक लेख पा सकते हैं:
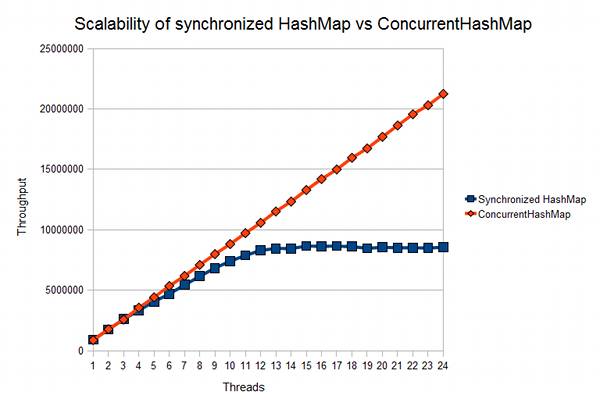
जैसा कि आप ग्राफ से देख सकते हैं, कार्ड में 5 और 10 मिलियन एक्सेस ऑपरेशन के बीच एक ध्यान देने योग्य गंभीर विसंगति है, जो उच्च मात्रा में संग्रहीत डेटा और उन तक पहुंच संचालन के मामले में कॉन्ट्रैक्ट हाशपैप का उपयोग करने की प्रभावशीलता निर्धारित करता है।
कुल मिलाकर
तो, समवर्ती हाशपा कार्यान्वयन के मुख्य लाभ और विशेषताएं:
- मैप में हैशमैप जैसा इंटरैक्शन इंटरफ़ेस है
- पढ़ें ऑपरेशन को ताले की आवश्यकता नहीं है और समानांतर में चलाते हैं
- लिखने के संचालन को अक्सर ताले के बिना समानांतर में भी किया जा सकता है।
- बनाते समय, आवश्यक संगोष्ठी निर्दिष्ट की जाती है, जिसे पढ़ने और लिखने के आंकड़ों द्वारा निर्धारित किया जाता है
- मानचित्र तत्वों में अस्थिरता के रूप में घोषित मूल्य होता है
अंत में, मैं यह कहना चाहूंगा कि कार्ड के पढ़ने और लिखने के अनुपात के प्रारंभिक आकलन के साथ, समवर्ती हाशप को सही ढंग से लागू किया जाना चाहिए। यह अभी भी उन कार्यक्रमों में हैशपॉप का उपयोग करने के लिए समझ में आता है जहां संग्रहीत धाराओं से कई धाराओं तक कोई बहु एक्सेस नहीं है।
आपका ध्यान के लिए धन्यवाद!
जावा और विशेष रूप से, समवर्ती हाशपा के काम पर समानांतर संग्रह पर उपयोगी संसाधन:
- www.ibm.com/developerworks/ru/library/j-jtp07233/index.html
- stas-blogspot.blogspot.com/2010/08/concurrenthashmap-revealed.html
- www.codercorp.com/blog/java/why-concurrenthashmap-is-better-than-hashtable-and-just-as-good-hashmap.html