SqlBulkCopy Microsoft SQL Server तालिकाओं में बड़े पैमाने पर लोडिंग डेटा के लिए एक प्रभावी समाधान है। डेटा स्रोत कोई भी हो सकता है, यह एक एक्सएमएल-फाइल, सीएसवी-फाइल या एक अन्य डीबीएमएस हो, उदाहरण के लिए MySQL। यह डेटाटेबल के रूप में स्रोत से डेटा प्राप्त करने या डेटा एक्सेस विधियों के शीर्ष पर IDataReader इंटरफ़ेस को लागू करने के लिए पर्याप्त है।
आपको
BCP उपयोगिता का उपयोग करके आगे डाउनलोड करने के लिए डिस्क पर फ़ाइलें बनाने की आवश्यकता नहीं है, आपको कई
INSERT अनुरोधों को बनाने के लिए कोड लिखने की आवश्यकता नहीं है। डेटा लोड करते समय, SqlBulkCopy निचले स्तर पर काम करता है, जिससे आपको कम से कम समय में लाखों रिकॉर्ड सम्मिलित करने की अनुमति मिलती है।
समस्या
सब ठीक है,
SqlBulkCopy इतनी तेज और पागल है कि यह डेटा को सम्मिलित करते समय किसी भी ट्रिगर, विदेशी कुंजी और अन्य प्रतिबंधों और घटनाओं को अनदेखा करता है (यदि आप चाहें तो इसे सक्षम कर सकते हैं)। वह यह भी जानता है कि कई ब्लॉकों में लेनदेन में डेटा कैसे डाला जाए।
लेकिन
SqlBulkCopy डेटा आयात करते समय होने वाले अपवादों को संभालने में सक्षम नहीं है। यदि कम से कम एक त्रुटि होती है (कुंजियों का दोहराव, NULL मानों की अयोग्यता, कास्ट करने में असमर्थता), तो वह बिना कुछ जोड़े जल्दी से काम पूरा कर लेगा।
हम दो कार्यों और उनके समाधानों पर विचार करेंगे:
1) एक मनमाना डेटा स्रोत के साथ SqlBulkCopy का उपयोग कैसे करें।
2) SqlBulkCopy के साथ काम करते समय होने वाले अपवादों से कैसे बचें।
कहाँ से शुरू करें?
डेस्टिनेशनटेबलनेम प्रॉपर्टी के अलावा, SqlBulkCopy क्लास की एक ऑब्जेक्ट में महत्वपूर्ण
BatchSize प्रॉपर्टी (सर्वर पर एक समय में लोड की गई पंक्तियों की संख्या, डिफ़ॉल्ट रूप से यह 0 है और सभी डेटा एक पैकेज में लोड किया गया है), इसके बारे में
यहां और पढ़ें।
दूसरे पैरामीटर के रूप में, SqlBulkCopy कंस्ट्रक्टर
SqlBulkCopyOptions प्रकार के एक चर को स्वीकार कर सकता है, इस पर ध्यान दें यदि आपको ट्रिगर्स, प्रतिबंधों को सक्षम करने की आवश्यकता है, या सम्मिलित करते समय NULL मानों को बाध्य करने की आवश्यकता है। डिफ़ॉल्ट रूप से, इसमें से कोई भी मौजूद नहीं है। इस पैरामीटर के संभावित मानों के बारे में
यहाँ पढ़ें।
IDataReader इंटरफ़ेस को लागू करना
अब एक और अधिक व्यावहारिक उदाहरण पर विचार करें कि एक मनमाने डेटा स्रोत के लिए
IDataReader इंटरफ़ेस को कैसे लागू किया जाए। हमारे उदाहरण में, एक csv फ़ाइल डेटा स्रोत के रूप में कार्य करेगी। हमारा कार्य SQL सर्वर तालिका से डेटा कॉपी करना है।
हम csv फ़ाइल से ग्राहकों को आयात करेंगे, इसलिए SQL सर्वर में हमारी तालिका इस तरह दिखती है:
टी-एसक्यूएल में ग्राहक तालिका की संरचना। CREATE TABLE [Customers]( [ID] [int] IDENTITY(1,1) NOT NULL, [FirstName] [nvarchar](50) NOT NULL, [SecondName] [nvarchar](50) NOT NULL, [Birthday] [smalldatetime] NULL, [PromoCode] [int] NULL ) ON [PRIMARY]
हमारी सीएसवी फ़ाइल कुछ इस तरह दिखती है: ;;04.10.1974;65125 ;;12.12.1962;54671 ;; ; ;;10.12.1981;4FS2FGA
अब यह अंत में स्पष्ट है कि डेटा आयात करते समय हमें निम्नलिखित समस्याओं को हल करना होगा:
- सही डेटा मैपिंग सुनिश्चित करें। इसलिए, उदाहरण के लिए, CSV दस्तावेज़ में अंतिम नाम SQL सर्वर तालिका के विपरीत पहले सूचीबद्ध किया गया है। सीएसवी डेटा में भी आईडी के लिए कोई मूल्य नहीं है, जो प्राथमिक स्वचालित रूप से अपडेट की गई कुंजी है।
- SQL सर्वर प्रारूप में डेटा लाओ और अमान्य रिकॉर्ड संसाधित करें। सीएसवी दस्तावेज़ की अंतिम पंक्ति को देखें, इसमें कोई नाम नहीं है, जबकि एसक्यूएल तालिका में इस क्षेत्र की आवश्यकता होती है, या मूल्य तीसरी पंक्ति में निर्दिष्ट नहीं होता है, जिससे स्मालेडटाइमटाइम प्रकार नहीं होता है।
कैसे SqlBulkCopy काम करता है
- यह SQL सर्वर डेटाबेस से जोड़ता है और निर्दिष्ट तालिका के मेटाडेटा का अनुरोध करता है।
- IDadaReader इंटरफ़ेस के फ़ील्डकाउंट गुण का उपयोग करके स्तंभों की संख्या हो जाती है।
- गणना करता है कि यह कहां से लोड होगा (डेटा स्रोत के किस कॉलम से SQL सर्वर टेबल के किस कॉलम तक)।
- यह रीड () विधि को कॉल करता है और क्रमिक रूप से GetValue (int i) विधि का उपयोग करके ऑब्जेक्ट के रूप में मान प्राप्त करता है - फिर से IDadaReader इंटरफ़ेस।
- रूपांतरण विधियों में से एक को कॉल करें, उदाहरण के लिए Convert.ToInt32 (ऑब्जेक्ट मान) , Convert.ToDateTime (ऑब्जेक्ट), और इसी तरह। कॉल करने के लिए कौन सी विधि - SqlBulkCopy तालिका मेटाडेटा द्वारा निर्धारित की जाएगी। स्रोत डेटा प्रकार उसे बिल्कुल भी रुचि नहीं देता है, यदि रूपांतरण विधि एक अपवाद फेंकता है, तो डाउनलोड बाधित हो जाएगा।
इस प्रकार, यदि आप जो डेटा आयात करना चाहते हैं, वह आदर्श (हमारे उदाहरण में) से बहुत दूर है, तो आपको कम से कम कुछ डेटा लोड करने के लिए थोड़ा और काम करना होगा।
काम करने के लिए!
SqlBulkCopy के लिए IDataReader इंटरफ़ेस को लागू करना काफी सरल है, आपको केवल 3 विधियों और एक संपत्ति को लागू करने की आवश्यकता है, बाकी की जरूरत नहीं है, क्योंकि उन्हें SqlBulkCopy ऑब्जेक्ट द्वारा नहीं बुलाया जाता है। और इसलिए यह है:
सार्वजनिक int FieldCountडेटा स्रोत (csv फ़ाइल) में स्तंभों की संख्या लौटाता है। रीड () कॉल करने से पहले पहले कॉल किया जाता है।
सार्वजनिक बूल पढ़ें ()अगली पंक्ति पढ़ता है। सच लौटाता है - यदि फ़ाइल / स्रोत का अंत नहीं हुआ है, अन्यथा गलत है।
सार्वजनिक वस्तु GetValue (int i)वर्तमान पंक्ति के लिए निर्दिष्ट सूचकांक के साथ मान लौटाता है। रीड () विधि के बाद हमेशा कॉल किया जाता है।
सार्वजनिक शून्य निपटान ()संसाधन जारी करना, SqlBulkCopy इस पद्धति को नहीं कहता है, लेकिन हमेशा काम में आएगा।
Csv फ़ाइलें पढ़ने के लिए एक वर्ग का एक सरल कार्यान्वयन जो IDataReader इंटरफ़ेस का समर्थन करता है। using System.Data; using System.IO; namespace SqlBulkCopyExample { public class CSVReader : IDataReader { readonly StreamReader _streamReader; readonly Func<string, object>[] _convertTable; readonly Func<string, bool>[] _constraintsTable; string[] _currentLineValues; string _currentLine;
विवश करने योग्य बाधा तालिका
दूसरा पैरामीटर कंस्ट्रक्टर के लिए
विवश करता है, हमने उन तरीकों के संदर्भों को पास किया है जो जल्दी से अग्रिम में निर्धारित करने के लिए उपयोग किए जाते हैं कि SqlBulkCopy सही ढंग से रिकॉर्ड की प्रक्रिया कर सकता है या नहीं। प्रत्येक विधि संगत कॉलम का मान लेती है और सही या गलत के निष्कर्ष का निर्माण करती है। यदि कम से कम एक तरीका गलत है, तो लाइन छोड़ दी जाती है। आइए विचार करें कि समान फ़ंक्शन की एक सरणी कैसे बनाएं।
var constraintsTable = new Func<string, bool>[4]; constraintsTable[0] = x => !string.IsNullOrEmpty(x); constraintsTable[1] = constraintsTable[0]; constraintsTable[2] = x => true; constraintsTable[3] = x => true;
हमारे चार स्तंभ हैं, इसलिए चार विधियाँ हैं। हमने उन्हें लंबोदर भावों के माध्यम से सेट किया, यह अधिक सुविधाजनक है पहला तरीका यह जाँचता है कि यदि अंतिम नाम वैध है (खाली नहीं होना चाहिए या NULL होना चाहिए), दूसरा वही करता है। SQl सर्वर में हमारी तालिका के स्कीमा को याद रखें, पहला और अंतिम नाम NULL नहीं हो सकता है। अन्य विधियां हमेशा सही होती हैं, क्योंकि ये वैकल्पिक क्षेत्र हैं।
नोट। आप बाधा तालिकाओं के उपयोग से बच सकते हैं, इसके बजाय, SQL सर्वर तालिका के सभी स्तंभों को NULL मान संग्रहीत करने में सक्षम बनाते हैं। इससे डेटा को तेज़ी से डाला जा सकेगा।
परिवर्तनीय रूपांतरण तालिका
कंस्ट्रक्टर के लिए परिवर्तनीय के तीसरे पैरामीटर, हमने उन तरीकों के संदर्भ में एक सरणी पारित की है जो कि csv से प्राप्त मूल्यों को उन SQL सर्वर को समझने के लिए उपयोग किए जाते हैं। हमारे मामले में, SqlBulkCopy खुद भी वही काम कर सकता है, लेकिन यह अपवादों को नहीं संभालता है और रूपांतरण विफल होने पर NULL मान नहीं डाल सकता है। हम उनके काम को आसान बनाएंगे।
var convertTable = new Func<object, object>[4];
उपनाम और पहले नाम को किसी भी रूपांतरण की आवश्यकता नहीं है। वे वैसे भी कड़े मूल्य हैं और उनकी शुद्धता को तालमेल तालिकाओं में जांचा जाता है। हम दिनांक और संख्या को परिवर्तित करने का प्रयास कर रहे हैं। यदि कोई अपवाद होता है, तो इसे
GetValue () विधि में पकड़ा जाएगा।
डेटा मैपिंग
एक विस्तार बाकी है। डिफ़ॉल्ट रूप से, SqlBulkInsert डेटा सम्मिलित करेगा, अर्थात, स्रोत के पहले कॉलम से SQL सर्वर तालिका के पहले कॉलम तक। हमें इस व्यवहार की आवश्यकता नहीं है, इसलिए हम प्रविष्टि आदेश सेट करने के लिए
ColumnMappings संपत्ति का उपयोग करते हैं।
अब देखते हैं कि हमारे कार्यक्रम की चुनौती पूरी तरह से कैसे दिखाई देगी।
using System; using System.Data; using System.Data.SqlClient; using System.Globalization; namespace SqlBulkCopyExample { class Program { static void Main(string[] args) {
परिणामस्वरूप, हमारे ग्राहक तालिका में हमें निम्नलिखित परिणाम मिले:
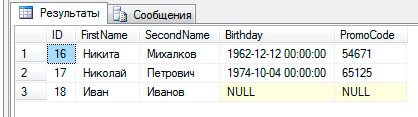
एक अमान्य प्रविष्टि नहीं जोड़ी गई थी, और आवश्यक प्रकार में डाली नहीं जा सकने वाले मान NULL के रूप में डाले गए थे।
निष्कर्ष
हमने
सोचा कि कैसे प्रोग्रामलीक रूप से
SqlBulkCopy का उपयोग करके आप
IDataReader इंटरफ़ेस के साथ एक डेकोरेटर को लागू करके एक SQL सर्वर तालिका के उदाहरण का उपयोग करके जल्दी से SQL सर्वर तालिका में डेटा सम्मिलित कर सकते हैं, जो डेटा को
लेते समय होने वाली समस्याओं को संभालती है। वास्तविक कार्यों में, डेटा की मात्रा निश्चित रूप से अधिक है, लेकिन इन मामलों में, SqlBulkCopy बस के रूप में अच्छी तरह से काम करेगी।
अतिरिक्त सामग्री
Microsoft से बड़ी मात्रा में डेटा डाउनलोड
करने के लिए
Microsoft की
सर्वोत्तम प्रथाओं के बारे में जानें।
आप एक सूची में पूरा कोड यहाँ देख सकते हैं।