एक शौक के रूप में, पिछले कुछ महीनों से मैं
ANTLR का उपयोग करके PHP पार्सर विकसित कर रहा हूं। मेरे लिए यह
परियोजना सिर्फ और सिर्फ मज़े की संभावना है, लेकिन इसके कार्यान्वयन के दौरान, निश्चित रूप से, मुझे मुश्किलें आईं। यह PHP भाषा की विशिष्टताओं को पूरी तरह से विनिर्देशों की कमी, और LL (k) एल्गोरिदम की सीमाओं को प्रभावित करता है।
इस लेख में, मैं पार्सर और इसके परीक्षण प्रक्रियाओं को लागू करने में तकनीकी समाधान और कुछ तरकीबें साझा करना चाहूंगा। यह लेख उन लोगों के लिए उपयोगी होगा जो ANTLR v2 के उपयोग को और अधिक विस्तार से समझना चाहते हैं।
समस्याओं
यहां मैं आपको यह बताने की कोशिश करूंगा कि यह कार्य क्यों दिलचस्प है और किन कठिनाइयों को हल करना है।
1. औपचारिक भाषा विनिर्देशन का अभाव
यह शायद पार्सर के विकास में मुख्य बाधा है, क्योंकि इस मामले में, विकास के अलावा, व्याकरण के रिवर्स इंजीनियरिंग को एक अर्थ में आवश्यक है।
2. PHP व्याकरण संदर्भ मुक्त नहीं है
इसका मतलब है कि उनके शुद्ध रूप में, मौजूदा पार्सिंग एल्गोरिदम (एल्गोरिदम एलएल (के) और एलआर (के) के समूह) सिद्धांत रूप में लागू नहीं हैं। कारण इस प्रकार हैं:
- एक मनमाना पाठ स्ट्रीम के साथ निष्पादन योग्य कोड को इंटरलेय करना।
- HEREDOC अंकन - एक उद्धरण वर्णों का एक मनमाना अनुक्रम है
- कई भाषा कीवर्ड नियमित पहचानकर्ता के रूप में काम कर सकते हैं।
विशुद्ध रूप से तकनीकी कठिनाइयों की सूची को सुरक्षित रूप से नियंत्रण संरचनाओं के वैकल्पिक सिंटैक्स और आधिकारिक दस्तावेज की अपूर्णता के लिए जिम्मेदार ठहराया जा सकता है।
कार्यान्वयन
टेक्स्ट कचरा से अलग कोड
जब मैंने यह काम शुरू किया, तो मुझे लगा कि मैं php को जानता हूं। दरअसल, इसीलिए पहले तो विनिर्देशों की कमी के तथ्य ने मुझे बिल्कुल परेशान नहीं किया। प्रारंभ में, सबसे गंभीर प्रश्न यह प्रतीत होता था कि औपचारिक भाषा में इस तथ्य का वर्णन कैसे किया जाए कि जिस स्रोत कोड को मान्यता दी जानी चाहिए उसे केवल उसी खंड में माना जाए
<?php … ?>
यहाँ सबसे संक्षिप्त
टोकन के
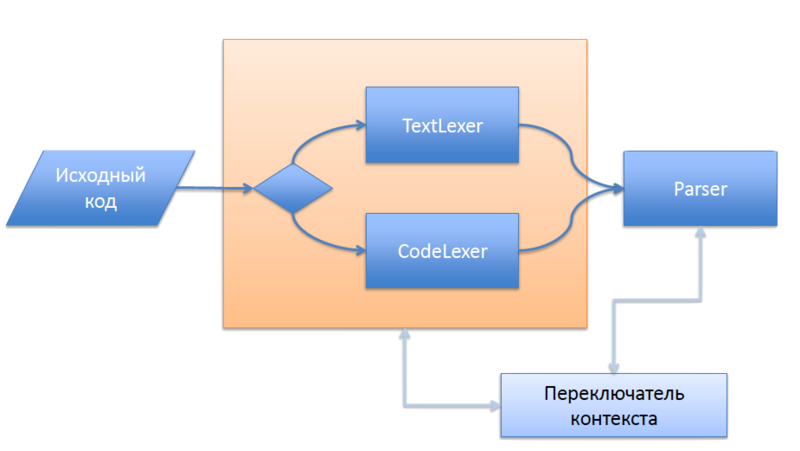
बहुसंकेतन और लेकर्स के ढेर के उपयोग पर आधारित एक समाधान था। इस उद्देश्य के लिए, मुझे पहले से ही एक अतिरिक्त इकाई की आवश्यकता थी जो पूरे पार्सर की वर्तमान स्थिति को संग्रहीत करता है (कम से कम राज्य "कोड अब अपेक्षित है" या "अब किसी भी पाठ को अग्रेषित करें,"
ParsingState.java देखें)।
और, ज़ाहिर है, दो अलग-अलग
लेक्सर व्याकरण:
phpLexer और
phpOutTheCode । संदर्भों को बदलने के लिए संकेत सीधे टोकन
<?php ,
<?= और
?> ।
योजनाबद्ध रूप से, इस विचार को नीचे दर्शाया गया है।
HEREDOC तार
HEREDOC अंकन एक बहु-पंक्ति स्ट्रिंग शाब्दिक है, कोई भी पहचानकर्ता उद्धरण चिह्न के रूप में कार्य कर सकता है। इस तरह के शाब्दिक को एम्बेडेड कोड द्वारा मान्यता प्राप्त है, जिसे HEREDOC की शुरुआत के बाद टोकन <<< के रूप में निष्पादित किया जाता है। सीधे तौर पर लेक्सर व्याकरण के इस टुकड़े को
यहाँ देखा जा सकता
है ।
पहचानकर्ता के रूप में कीवर्ड
ANTLR में कीवर्ड पहचानकर्ता नहीं हैं। यदि आप ऐसे मामलों में ANTLR द्वारा उत्पन्न कोड को देखते हैं, तो कीवर्ड को हमेशा एक नियमित पहचानकर्ता के रूप में पहचाना जाता है, और फिर छवि (स्ट्रिंग प्रतिनिधित्व) को कीवर्ड के शब्दकोश के खिलाफ जांचा जाता है। इस ऑपरेशन को लेक्सर वर्ग के अंदर किया जाता है, जिसे मान्यता के समय निम्न कारणों से पार्सर वर्ग का संदर्भ नहीं पता (और पता नहीं चल सकता है):
- पार्सर अगला टोकन लेसर से नहीं, बल्कि एक विशेष बफर से लेता है। बफर समय के आगे भर जाता है, केके टोकन पर आगे देखने में सक्षम होने के लिए, एलएल (के) एल्गोरिथ्म द्वारा आवश्यक है। इसका मतलब है कि जिस समय लेक्सेम को मान्यता दी गई है, उस समय पार्सर को अभी भी नहीं पता है कि इस स्थान पर एक पहचानकर्ता की उम्मीद है या नहीं: लेक्सर अनुसूची से आगे है।
- सिंटैक्टिक प्रेडिकेट्स (तथाकथित प्रबंधित बैकट्रैकिंग) के प्रसंस्करण के मामले में, पार्कर टोकन प्रवाह के साथ "रोलबैक" कर सकता है, और बाहर से विधेय करके रोलबैक / डॉक की स्थिति को पकड़ना मुश्किल है।
सौभाग्य से, समाधान भी काफी सरल है: पार्सर स्तर पर एक पहचानकर्ता के रूप में एक नियम घोषित करें और "ईमानदार" पहचानकर्ताओं के अलावा कीवर्ड टोकन सूची दें। यहां, हालांकि, एक और खतरा है: पार्सर नियमों के स्तर पर अस्पष्टता होगी, उदाहरण के लिए, एक कास्ट ऑपरेशन
(typeName) expressionके रूप में व्याख्या की जा सकती है
(expression) expression , क्योंकि, उदाहरण के लिए,
int कीवर्ड,
int वर्णित कारण के लिए
int expression में एक इनपुट टोकन बन जाता है (क्योंकि यह एक पहचानकर्ता होगा)। डिजाइन का कोई मतलब नहीं है और यह एक मान्यता त्रुटि का कारण बनेगा।
यह समस्या एक अतिरिक्त वाक्यविन्यास विधेय (
php.g देखें) का उपयोग करके हल की गई थी।
typeCastExpression[boolean allowComma]: (LPAREN typeName RPAREN expression[false, false]) => (LPAREN^ typeName RPAREN { #LPAREN.setType(TYPE_CAST) ;} typeCastExpression[allowComma] ) | (LNOT^ typeCastExpression[allowComma]) | (DOG^ typeCastExpression[allowComma]) | (BW_NOT^ typeCastExpression[allowComma] ) | (MINUS^ {#MINUS.setType(UNARY_MINUS);} typeCastExpression[allowComma]) | (PLUS^ {#PLUS.setType(UNARY_PLUS);} typeCastExpression[allowComma]) | incrementExpression[allowComma] ;
प्राथमिकता संचालन और अन्य तकनीकी कठिनाइयाँ
बहुत से प्रयासों को खर्च करने और संचालन की प्राथमिकता को "मिलाते हुए" खर्च किया गया था। आधिकारिक
दस्तावेज अधूरा है। तो, ऑपरेटरों के बीच एक अल्पविराम है, जो कि PHP में नहीं है।
दिलचस्प है, PHP में, असाइनमेंट के उपयोग को टर्नरी ऑपरेटर (
स्पष्टीकरण के लिए धन्यवाद
mark_ablov ) के अंदर अनुमति दी जाती है। वह है, फॉर्म का निर्माण
a = test() ? b = c : d = e;
यह C / C ++ में संकलित नहीं है, लेकिन PHP में संकलन करता है (ऐसा उदाहरण phpBB3 कोड में पाया गया था)।
एक और दिलचस्प बात: अभिव्यक्ति
echo (यह एक फ़ंक्शन नहीं है, अर्थात् अभिव्यक्ति) अल्पविराम द्वारा अलग किए गए ऑपरेंड की गणना की अनुमति देता है। यह आउटपुट पर कॉन्सेप्टेशन की तरह काम करता है, लेकिन phpMyAdmin स्रोत कोड के लिए धन्यवाद, एक और समान निर्माण पाया गया - प्रिंट, जो कि गूंज के समान है, लेकिन यह अब कॉमा की अनुमति नहीं देता है।
टोकन
?> एक अर्धविराम के बराबर निकला।
<?= ऑपरेटर
echo बराबर है (ऊपर कॉमा टिप्पणी सहित)।
डॉलर का प्रतीक अक्सर एक ऑपरेटर की तरह दिखता है (मैंने पहले इस विषय पर
एक प्रश्न
पूछा था), लेकिन यह नहीं है: एक पंक्ति में कई डॉलर के "आवेदन" की संभावना को लेक्सर द्वारा मान्यता प्राप्त है और फिर यह अभी भी एक लेक्सेम जैसा दिखता है - यह आधिकारिक संकलक में किया जाता है।
परीक्षण
परीक्षण के दौरान, भाषा के इन सभी सूक्ष्मताओं को एक नियम के रूप में, पता चला था। इस मामले में, वास्तविक परियोजनाओं के स्रोतों पर परीक्षण ने यह सुनिश्चित करना संभव बना दिया कि व्याकरण भाषा का सबसे पूरी तरह से कवर करता है। इसके अलावा, प्रतिगमन को ट्रैक करना बेहद महत्वपूर्ण है: व्याकरण में एक छोटा सा संपादन बिल्कुल सब कुछ तोड़ सकता है।
इन उद्देश्यों के लिए मेरे द्वारा उपयोग किए जाने वाले परीक्षणों का अर्थ अत्यंत सरल है: लाइब्रेरी के चारों ओर एक साधारण कंसोल आवरण बना है, जो एक इनपुट के रूप में php फ़ाइल प्राप्त करता है। यदि पार्सर समस्याओं के बिना फ़ाइल को पहचानता है, तो आवरण कुछ भी नहीं करता है, एक समस्या है - हम प्रासंगिक जानकारी प्रिंट करते हैं।
आवरण प्रोग्राम को फ़ाइल के आउटपुट के साथ खोज कमांड द्वारा लॉन्च किया जाता है।
कुछ इस तरह:
$ (find ~/Documents/distr/phpBB3/ -name '*.php' -print -exec java -jar bin/jar/parse-php-test.jar -f {} \; ) &>./out-phpbb.txtआउटपुट फ़ाइलों (इस मामले में आउट-phpbb.txt) को नए परिणाम के साथ सहेजा और तुलना की जा सकती है। परिणाम बेहतर या खराब हो गया है - आप फ़ाइल में लाइनों की संख्या से समझ सकते हैं:
$ wc -l ./out-koh.txt* 498 ./out-koh.txt 502 ./out-koh.txt.old
निष्कर्ष
पार्सर परियोजना वर्तमान में अकादमिक हित की अधिक संभावना है। इसका उपयोग एक आधार के रूप में किया जा सकता है, उदाहरण के लिए,
चेक स्टाइल की कार्यक्षमता को
बढ़ाने या अपने स्वयं के php
ब्यूटिफायर को लागू करने के लिए।
जैसा कि आप देख सकते हैं, पार्सर अब भाषा के संस्करण 5.2 के लिए डिज़ाइन किया गया है, हालांकि मेरी राय में व्याकरण को स्तर 5.3 पर लाने में कोई मौलिक समस्याएं नहीं हैं (संस्करण 5.4 अधिक जटिल है: व्याकरण मान्यता के लिए व्यावहारिक रूप से कोई परीक्षण आधार नहीं है)। फिलहाल, पार्सर सफलतापूर्वक ZF 1.11, Yii फ्रेमवर्क 1.1.10 और phpBB 3.0.10 स्रोतों के पूरे सेट को पार्स कर रहा है।
मुझे खुशी होगी अगर यह काम किसी को दिलचस्प और / या उपयोगी लगे। आपकी टिप्पणी और आलोचना भी उपयोगी होगी।
आपका ध्यान के लिए धन्यवाद!