मैं हाल ही में
rgen3 द्वारा प्रकाशित एक दिलचस्प
लेख पर ठोकर खाई है जो DTW भाषण मान्यता एल्गोरिथ्म का वर्णन करता है। सामान्य शब्दों में, यह गतिशील प्रोग्रामिंग का उपयोग करते हुए भाषण अनुक्रमों की तुलना है।
विषय में रुचि रखते हुए, मैंने इस एल्गोरिथम को अभ्यास में लाने की कोशिश की, लेकिन रास्ते में कई रेक ने मेरा इंतजार किया। सबसे पहले, वास्तव में क्या तुलना करने की आवश्यकता है? समय डोमेन में सीधे ध्वनि संकेत लंबे और बहुत प्रभावी नहीं हैं। स्पेक्ट्रोग्राम पहले से ही तेज हैं, लेकिन बहुत अधिक कुशल नहीं हैं। सबसे तर्कसंगत प्रतिनिधित्व की खोज ने मुझे
एमएफसीसी या मेल-फ़्रीक्वेंसी
सेफस्ट्राल गुणांक के लिए प्रेरित किया, जो अक्सर भाषण संकेतों की विशेषताओं के रूप में उपयोग किया जाता है। यहाँ मैं समझाने की कोशिश करूँगा कि वे क्या हैं।
मूल अवधारणाएँ
स्पष्टीकरण शीर्षक में पहले शब्द से शुरू होगा। चाक क्या है?
विकिपीडिया हमें बताता है कि चाक हमारे श्रवण अंगों द्वारा इस ध्वनि की धारणा पर आधारित पिच की एक इकाई है। जैसा कि आप जानते हैं, मानव कान की आवृत्ति प्रतिक्रिया दूरस्थ रूप से एक प्रत्यक्ष से मेल नहीं खाती है, और आयाम ध्वनि की मात्रा का सटीक माप नहीं है। इसलिए, उन्होंने समान रूप से वॉल्यूम की इकाइयों को चुना, उदाहरण के लिए,
पृष्ठभूमि ।
इसी तरह, मानव श्रवण द्वारा मानी जाने वाली ध्वनि की पिच काफी रैखिक रूप से इसकी आवृत्ति पर निर्भर नहीं करती है।
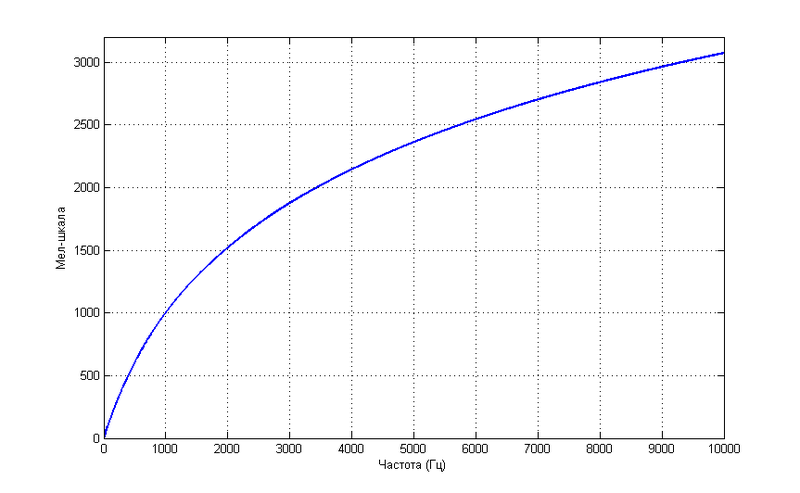
इस तरह की निर्भरता अधिक सटीक होने का दिखावा नहीं करती है, लेकिन एक सरल सूत्र द्वारा वर्णित है

माप की ऐसी इकाइयों को अक्सर मान्यता समस्याओं को हल करने में उपयोग किया जाता है, क्योंकि वे आपको मानवीय धारणा के तंत्र के करीब लाने की अनुमति देते हैं, जो अब तक ज्ञात भाषण मान्यता प्रणालियों में से एक है।
आपको नाम के दूसरे शब्द के बारे में थोड़ा बताने की जरूरत है -
सेप्रस्ट्रम ।
भाषण गठन के सिद्धांत के अनुसार, भाषण एक ध्वनिक लहर है जो अंगों की एक प्रणाली द्वारा उत्सर्जित होती है: फेफड़े, ब्रांकाई और श्वासनली, और फिर मुखर पथ में परिवर्तित हो जाती है। यदि हम मानते हैं कि उत्तेजना के स्रोत और स्वर तंत्र के रूप अपेक्षाकृत स्वतंत्र हैं, तो मानव भाषण तंत्र को टोन और शोर जनरेटर के संयोजन के साथ-साथ फिल्टर के रूप में दर्शाया जा सकता है। योजनाबद्ध रूप से, इसे निम्नानुसार दर्शाया जा सकता है:

1. पल्स अनुक्रम जनरेटर (टन)
2. यादृच्छिक संख्या जनरेटर (शोर)
3. डिजिटल फिल्टर गुणांक (आवाज पथ पैरामीटर)
4. गैर-स्थिर डिजिटल फ़िल्टर
फ़िल्टर (4) के आउटपुट पर सिग्नल को एक कनवल्शन के रूप में दर्शाया जा सकता है

जहां एस (टी) ध्वनिक लहर का प्रारंभिक रूप है, और एच (टी) फिल्टर विशेषता है (मुखर पथ के मापदंडों पर निर्भर करता है)
फ़्रीक्वेंसी डोमेन में, यह ऐसा दिखता है

इसके बदले राशि प्राप्त करने के लिए उत्पाद की घोषणा की जा सकती है

अब हमें इस राशि को बदलने की आवश्यकता है ताकि हमें मूल सिग्नल और फ़िल्टर की विशेषताओं के असंतुष्ट सेट मिलें। इसके लिए कई विकल्प हैं, उदाहरण के लिए, उलटा
फूरियर रूपांतरण हमें यह देगा

इसके अलावा, लक्ष्यों के आधार पर, आप प्रत्यक्ष फूरियर रूपांतरण या
असतत कोसाइन रूपांतरण का उपयोग कर सकते हैं
मुझे उम्मीद है कि मैंने बुनियादी अवधारणाओं को थोड़ा स्पष्ट किया है। यह समझना बाकी है कि एमएफसीसी गुणांकों के एक सेट में भाषण संकेत को कैसे बदलना है।
उदाहरण
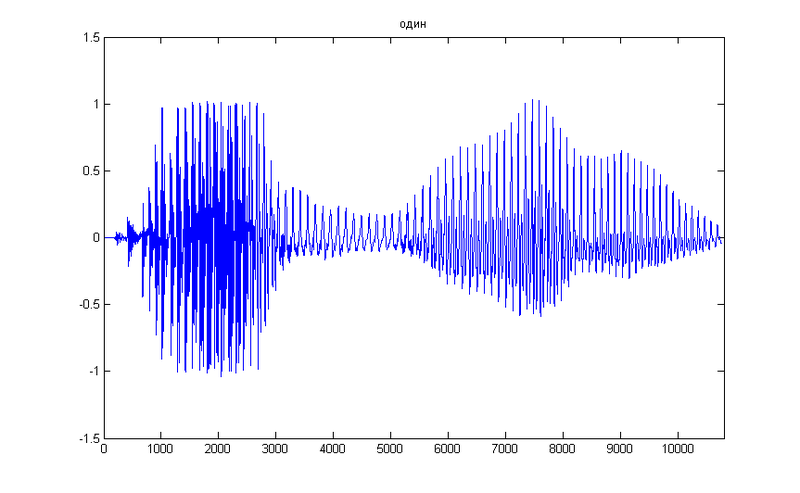
परीक्षण के रूप में, हम एक साधारण संख्या 1 लेते हैं, यहाँ इसका अस्थायी प्रतिनिधित्व है
सबसे पहले, हमें मूल सिग्नल के स्पेक्ट्रम की आवश्यकता है, जिसे हम
फूरियर ट्रांसफॉर्म का उपयोग करके प्राप्त करते हैं। उदाहरण की सादगी के लिए, हम सिग्नल को भागों में विभाजित नहीं करेंगे, इसलिए हम पूरे समय के अक्ष के साथ स्पेक्ट्रम लेते हैं

अब मज़ा शुरू होता है, हमें परिणामस्वरूप स्केल को चाक पैमाने पर रखने की आवश्यकता है। ऐसा करने के लिए, हम चाक की धुरी पर समान रूप से उभरी हुई खिड़कियों का उपयोग करते हैं।

यदि आप इस ग्राफ़ को फ़्रीक्वेंसी स्केल में ट्रांसलेट करते हैं, तो आप ऐसी तस्वीर देख सकते हैं

इस ग्राफ पर, यह ध्यान देने योग्य है कि विंडोज़ कम-आवृत्ति क्षेत्र में "इकट्ठा" करती हैं, एक उच्च "रिज़ॉल्यूशन" प्रदान करती है जहां यह मान्यता के लिए आवश्यक है।
बस सिग्नल स्पेक्ट्रम और विंडो फ़ंक्शन के वैक्टर को गुणा करके, हम सिग्नल ऊर्जा पाते हैं जो विश्लेषण खिड़कियों में से प्रत्येक में आती है। हमें गुणांक के कुछ सेट मिले, लेकिन ये वो MFCC नहीं हैं जिनकी हम तलाश कर रहे हैं। अब तक, उन्हें मेल-फ़्रीक्वेंसी
स्पेक्ट्रल गुणांक कहा जा सकता है। हम उन्हें और लघुगणक वर्ग। हमारे लिए जो कुछ भी रहता है, वह है कि वे उनसे एक cepstral, या "स्पेक्ट्रम स्पेक्ट्रम" प्राप्त करें। इसके लिए, हम एक बार फिर फूरियर रूपांतरण को लागू कर सकते हैं, लेकिन
असतत कोसाइन रूपांतरण का उपयोग करना बेहतर है।
परिणामस्वरूप, हमें निम्न प्रकार का एक क्रम प्राप्त होता है:

निष्कर्ष
इस प्रकार, हमारे पास मूल्यों का एक बहुत छोटा समूह है, जिसे पहचाने जाने पर, भाषण संकेत के हजारों नमूनों को सफलतापूर्वक प्रतिस्थापित करता है। किताबें लिखती हैं कि शब्द पहचान की समस्या के लिए पहले 24 में से 13 गणना गुणांक लेना संभव है, लेकिन मेरे मामले में कोई भी उपयुक्त परिणाम 16 से शुरू हुआ। किसी भी मामले में, यह एक स्पेक्ट्रोग्राम या सिग्नल के अस्थायी प्रतिनिधित्व की तुलना में बहुत कम मात्रा में डेटा है।
बेहतर परिणाम के लिए, आप स्रोत शब्द को छोटी अवधि के खंडों में विभाजित कर सकते हैं, और उनमें से प्रत्येक के लिए गुणांक की गणना कर सकते हैं। वेटिंग विंडो फ़ंक्शंस भी मदद कर सकते हैं। यह सब मान्यता एल्गोरिथ्म पर निर्भर करता है जिससे आप परिणाम को खिलाते हैं।
सूत्र
मैं बड़ी संख्या में फ़ार्मुलों के साथ लेख के मुख्य भाग को लोड नहीं करना चाहता, लेकिन अचानक वे किसी के हित में होंगे। इसलिए, मैं उन्हें यहां लाऊंगा।
मूल भाषण संकेत असतत रूप में लिखा गया है
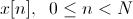
इसमें फूरियर ट्रांसफॉर्म लागू करें
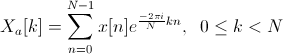
विंडो फ़ंक्शन का उपयोग करके एक फिल्टर कंघी बनाना

जिसके लिए आवृत्तियों f [m] हम समानता से प्राप्त करते हैं

बी (बी) - क्रमशः चाक पैमाने पर आवृत्ति मूल्य का रूपांतरण,

प्रत्येक विंडो के लिए ऊर्जा की गणना करें

डीसीटी लागू करें

एमएफसीसी किट प्राप्त करें
सूत्रों का कहना है
[१] विकिपीडिया
[२] ज़ेइदोंग हुआंग, एलेक्स एकेरो, हिसिओ-वूएन मान, स्पोकन लैंग्वेज प्रोसेसिंग: ए गाइड टू थ्योरी, एलगोरिदम, एंड सिस्टम डेवलपमेंट, प्रेंटिस हॉल, २००१, आईएसबीएन: ०१३०२२६१६५