X86 आर्किटेक्चर प्रोसेसर आर्किटेक्ट्स ने ऐतिहासिक रूप से प्रोग्रामर को सीधे कैश का प्रबंधन करने की क्षमता देने का विरोध किया है। एक बार 2009 में मुझे बताया गया था - "हम ऐसा कभी नहीं करेंगे, कैश हमेशा प्रोग्रामर के लिए पारदर्शी होना चाहिए।" कुछ RISC प्रोसेसर आर्किटेक्चर डेटा / कोड प्रबंधन क्षमताएं प्रदान करते हैं जो कैश में समाप्त होती हैं। और अंत में, x86 आर्किटेक्चर (ब्रॉडवेल * से शुरू) में भी कुछ ऐसा ही दिखाई दिया।
दो साल पहले, मैंने एक
पोस्ट लिखा था कि पहले और दूसरे स्तर के कैश प्रत्येक कोर के लिए विशेष रूप से नहीं होते हैं, और यह कि सबसे पुराने उपयोग (छद्म-LRU) के सिद्धांत के बारे में L3 कैश में कैश लाइनों को बदलने की नीति प्राथमिकता उलटा (प्राथमिकता) का एक सीधा रास्ता है उलट)। पाठकों ने पूछा कि क्या कोई ऐसी हार्डवेयर सुविधा है जो प्राथमिकता के उलट को दूर करने की अनुमति देगी, कम प्राथमिकता वाली प्रक्रियाओं को पहले और दूसरे स्तर के अन्य लोगों के कैश से डेटा को धक्का देने की अनुमति नहीं देगा, और तीसरे स्तर में अधिकांश कैश को पकड़ने की अनुमति नहीं देगा।
ऐसी सुविधा अब मौजूद है, और इसे कैट - कैशे आवंटन प्रौद्योगिकी कहा जाता है। तब मुझे हब पर इस सुविधा का वर्णन करने का अधिकार नहीं था, क्योंकि आधिकारिक तौर पर यह अभी तक जारी नहीं किया गया है। इसका वर्णन Intel® 64 और IA-32 आर्किटेक्चर सॉफ्टवेयर डेवलपर के मैनुअल, खंड 3, अध्याय 17 भाग 15 में दिखाई दिया, यह सैन फ्रांसिस्को में IDF'15 में दिखाया गया था, और lkml लंबे समय से
चर्चा कर रहा है कि कैट को कौन सा इंटरफ़ेस लिनक्स कर्नेल में शामिल किया जाएगा। सबसे अधिक संभावना है कि इंटरफ़ेस cgroups के माध्यम से कार्यान्वित किया जाएगा। इस प्रकार, कार्य अनुसूचक यह सुनिश्चित करेगा कि उपयोगकर्ता एक निश्चित प्राथमिकता वाले कार्यों को कैश का एक निश्चित हिस्सा प्राप्त करें।
जबकि कैट समर्थन अभी तक कर्नेल में शामिल नहीं है, आप इसे सीधे उपयोग कर सकते हैं। लिनक्स में, सब कुछ सरल है - आपको
msr-tools या एक एनालॉग स्थापित करने की आवश्यकता होगी, और फिर # rdmsr, # wrmsr - हाँ का उपयोग करके दो MSR (मॉडल विशिष्ट रजिस्टर) को पढ़ना और लिखना होगा, आपको रूट होना चाहिए। अधिक सुविधाजनक
इंटरफ़ेस है । विंडोज थोड़ा अधिक जटिल है, आप विंडबग का उपयोग कर सकते हैं, या rdmsr / wrmsr के लिए ड्राइवर ढूंढ / लिख सकते हैं।
इसके बाद, मैं Xeon सर्वर के साथ सोलह कोर, एक 20-तरफ़ा L3 कैश, 2.5 मेगाबाइट प्रति कोर के बारे में बताऊंगा। इंटरफ़ेस बहुत सरल है। MSR के 2 प्रकार हैं:
IA32_L3_MASKn: सेवा की श्रेणी। यह एक बिटमास्क है, जहां प्रत्येक बिट तीसरे स्तर के एक तरीके (सेट नहीं!) के अनुरूप है। ये MSRs 0xc90, 0xc91 आदि हैं। उन्हें किसी भी कोर से लिखा और पढ़ा जा सकता है, वे प्रत्येक प्रोसेसर के सभी कोर के लिए सामान्य हैं।
और IA32_PQR_ASSOC (0xc8f): प्रत्येक कोर के लिए वर्तमान सक्रिय वर्ग को परिभाषित करता है। यह MSR प्रत्येक कोर के लिए अद्वितीय है।
डिफ़ॉल्ट रूप से, प्रत्येक प्रोसेसर पर सभी बिटमास्क 1 (यानी मेरे उदाहरण में 0xfffff) पर सेट होते हैं, और प्रत्येक यार्ड के लिए IA32_PQR_ASSOC 0 है, इसलिए यह सुविधा निष्क्रिय है।
जैसा कि आप देख सकते हैं, यदि आप ऑपरेटिंग सिस्टम का समर्थन किए बिना कैट का उपयोग करते हैं, तो आपको प्रत्येक कोर के लिए IA32_PQR_ASSOC के बीच पत्राचार को मैन्युअल रूप से मॉनिटर करना होगा और उस पर क्या प्रक्रियाएं / सूत्र काम करते हैं।
एक दिलचस्प "हैक" भी संभव है: आप किसी तरह कैश में डेटा (और / या कोड) को लॉक कर सकते हैं, यदि आप पहली बार कई तरीके शामिल करते हैं, तो डेटा को वहां रखें, और फिर कैश के इस हिस्से को सभी सक्रिय बिट मास्क से बाहर कर दें। फिर यह डेटा कैश में रहेगा (निश्चित रूप से, आप इसे बदल सकते हैं), और कोई भी इसे दबाने में सक्षम नहीं होगा।
साइड चैनल
हमलों का एक दिलचस्प एलएलसी वर्ग है। चूंकि ये हमले उस माप का फायदा उठाते हैं जिस तरह से डेटा स्थित है, कैट का उपयोग किए बिना चौराहों के बिना आभासी मशीनों के बीच कैश को साझा करके, हम इन हमले वर्गों से पूरी तरह से सुरक्षित हैं।
कैश, जैसा कि आप जानते हैं, अच्छे कारण के लिए साहचर्य बनाया गया है। कैट का उपयोग करके, हम सहानुभूति कम करते हैं। यदि आप कुछ कर्नेल को 1/10 कैश देते हैं, तो यह पता चलता है कि इसमें 4 मेगाबाइट का 2-रास्ता "अपना" L3 कैश है। 4 मेगाबाइट बुरा नहीं है, लेकिन 2-वे बहुत छोटा है। जाहिर है, सहानुभूति की कमी के कारण कई कैश मिस होंगे। इस आशय को मापा जा सकता है। कुछ साल पहले मैंने एक
पोस्ट लिखी थी जिसमें मैंने विस्तार से वर्णन किया था कि कैश को एल 3 के निराशाजनक भागों में विभाजित करने के लिए कैशे कलरिंग का उपयोग कैसे करें। इस तकनीक में कई कमियां हैं, इसलिए इस उद्देश्य के लिए सामान्य ओएस और हाइपरवेयर्स में इसका उपयोग नहीं किया जाता है (कई विशिष्ट हाइपरविजर हैं जहां इसका उपयोग किया जाता है, लेकिन मैं उन्हें लेख में नाम नहीं दे सकता हूं।)
तो, एक छोटा माइक्रोबेनमार्क। एक कोर ड्राइव ड्राइव, दूसरा कैश लाइनों के लिए उपयोग के समय को मापता है। कैट और कैश कलरिंग का उपयोग करते हुए, हम उनके बीच कैश को गैर-प्रतिच्छेदन क्षेत्रों के विभिन्न आकारों में विभाजित करते हैं, और दूसरे परीक्षण में हम डेटा क्षेत्र के आकार को आनुपातिक रूप से बदलते हैं।
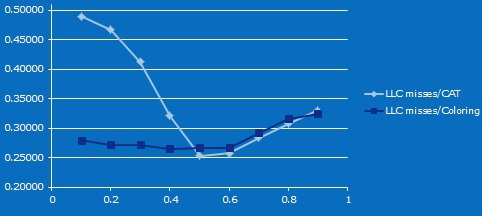
यहाँ परिणाम है। (एक्स के लिए - दूसरे कोर के एल 3 का प्रतिशत, वाई के लिए - दूसरे कोर पर कैश में मिसाइलों का प्रतिशत)। मैं स्वीकार करता हूं कि मुझे ठीक से पता नहीं है कि जब कैश कम हो जाता है, तो मिस की संख्या पहले कम हो जाती है (मैं मान सकता हूं कि यह इस
लेख में वर्णित प्रभाव है)। लेकिन 10-मेगा कैश के 20 मेगाबाइट से शुरू, और 2-वे के 4 मेगाबाइट तक, यह स्पष्ट है कि कैट का उपयोग करते समय कैश मिस के अनुपात में अंतर सहानुभूति में कमी से होता है।
यह जांचने के लिए कि कैट एक विशिष्ट प्रोसेसर मॉडल पर उपलब्ध है, एक अलग सीपीयू ध्वज है। कुछ मॉडलों में, इसे बंद कर दिया जाता है, भले ही कैट इस परिवार में समर्थित हो। लेकिन मुझे लगता है कि एक हैकर हो सकता है जो यह जानता हो कि इसे किसी भी प्रोसेसर पर कैसे चालू किया जाए, जो हसवेल से शुरू होता है।
यह सब, संक्षेप में, कैट का उपयोग करने के लिए आपको क्या जानने की आवश्यकता है। इसके अलावा, कैट सेवा की गुणवत्ता की प्लेटफ़ॉर्म गुणवत्ता के एक नए परिवार का हिस्सा है जिसे एक अलग पोस्ट में वर्णित किया जा सकता है, यदि रुचि हो। कैट के अलावा, इनमें सीएमटी (कैश मॉनिटरिंग टेक्नोलॉजी) शामिल है, जो आपको साझा कैश पृथक्करण दक्षता, एमबीएम (मेमोरी बैंडविड्थ मॉनिटरिंग) को मापने की अनुमति देता है, जो मेमोरी और सीडीपी (कोड और डेटा प्राथमिकता) के साथ भी ऐसा ही करता है।