"हमारी अपनी खोज है!"
दो वर्षों के लिए, मैंने इस वाक्यांश के साथ सम्मेलनों में अपने सभी भाषण शुरू किए, क्योंकि सभी खोज विशेषज्ञों को यह नहीं पता था कि Mail.Ru खोज लाइन में सेट किए गए उनके प्रश्न लाइसेंस प्राप्त तृतीय-पक्ष इंजन द्वारा नहीं, बल्कि कंपनी के आंतरिक विकास द्वारा संसाधित किए गए थे।
अब मैं देखता हूं कि स्थिति बदल गई है: कई लोग हमारे खोज इंजन को जानते हैं और स्वीकार करते हैं। हालांकि, सवाल या संदेह अभी भी बना हुआ है - यह कैसे है। मेल.यू ग्रुप अपनी खोज लिखता है? Mail.Ru Group मेल है, यह सोशल नेटवर्क, मनोरंजन है ... वे किस तरह का सर्च इंजन लिख सकते हैं? इसलिए इन शंकाओं को दूर करने के लिए, हम अपनी खोज के बारे में बात करना चाहते हैं कि हम इसे कैसे करते हैं, हम किन तकनीकों का उपयोग करते हैं, जिसके परिणामस्वरूप हम क्या प्राप्त करना चाहते हैं। मुझे उम्मीद है कि प्रस्तावित लेख जानकारीपूर्ण और दिलचस्प होगा; इसके अलावा, हम अपनी तकनीकों के बारे में कहानी को और अधिक विस्तार से जारी रखने जा रहे हैं, और अगली पोस्ट में मशीन लर्निंग, स्पाइडर, एंटीस्पैम, आदि के बारे में बात करेंगे।
GoGo.Ru
Mail.Ru सर्च इंजन को 2004 में aport.ru सर्च इंजन के पूर्व प्रमुख मिखाइल कोस्टिन द्वारा विकसित किया जाना शुरू हुआ। 2007 में, सर्च इंजन को goGo नाम से डोमेन gogo.ru पर प्रस्तुत किया गया था।

GoGo के पास पहले से ही काफी दिलचस्प गुण हैं: यह खोज को वाणिज्यिक और सूचनात्मक साइटों, साथ ही मंचों और ब्लॉगों तक सीमित कर सकता है। कुछ समय बाद, इसमें एक चित्र खोज दिखाई दी और RuNet में पहली वीडियो खोज।
खोज क्वेरी निष्पादन समय की रैंकिंग और अनुकूलन पर बहुत ध्यान दिया गया था। उदाहरण के लिए, GoGo पाठ रैंकिंग सूत्र ने ROMIP (सूचना खोज विधियों के मूल्यांकन पर रूसी संगोष्ठी) में भाग लिया, जहां इसने सभी प्रतिभागियों के बीच सर्वोत्तम परिणाम दिखाए (देखें
www.romip.ru/romip2005/09_mailru.pdf )।
GoGo से Go.Mail.Ru तक
इस बार, Mail.Ru पोर्टल के मुख्य पृष्ठ पर दर्ज किए गए प्रश्नों को लाइसेंस प्राप्त खोज इंजन द्वारा किया गया था; पहले यह एक Google इंजन था, उसके बाद Yandex। लेकिन 2009 में, यैंडेक्स के साथ अनुबंध समाप्त हो गया, और 1 जनवरी, 2010 से अपने स्वयं के खोज इंजन की कोशिश करने का निर्णय लिया गया।
बाद में हमने निम्नलिखित शर्तों पर Google खोज इंजन के साथ एक साझेदारी की: कुछ अनुरोध Google द्वारा संसाधित किए गए, दूसरा हमारे द्वारा है। लेकिन यह केवल अगस्त 2010 में हुआ, और आठ महीने तक सर्च ने पूरी तरह से अपने इंजन पर काम किया।
डेवलपर्स के दृष्टिकोण से, इसका मतलब पूरी तरह से अलग खोज आवश्यकताओं से था: यदि पहले gogo.ru प्रति दिन सैकड़ों हजारों अनुरोधों की सेवा देता था, तो अब इसे लाखों लोगों की सेवा करने की आवश्यकता थी। परिमाण के दो आदेशों द्वारा भार में अपेक्षित वृद्धि के लिए नए वास्तुशिल्प समाधानों की आवश्यकता थी। सबसे महत्वपूर्ण परिवर्तन रैम में रिवर्स इंडेक्स का उदय था: यह हार्ड ड्राइव पर झूठ बोलता था, जो हमें प्रति अनुरोध 300 मिलीसेकंड तक आवश्यक प्रतिक्रिया समय को पूरा करने की अनुमति नहीं देता था। और सभी परिवर्तनों के लिए, विकास टीम के पास केवल कुछ महीने थे, 1 जनवरी, 2010 को, नए खोज इंजन को काम करना था और Mail.Ru पोर्टल के उपयोगकर्ताओं के अनुरोधों की सेवा करना था।
यह कार्य "मिशन असंभव" वर्ग का है, लेकिन डेवलपर्स ने श्रम की उपलब्धि पूरी की और सफलतापूर्वक इससे निपटा: 1 जनवरी, 2010 को 0:00 पर नए खोज इंजन पर स्विच हुआ। नए खोजे गए समस्याओं में से किसी एक को सुधारते हुए, सर्च रिपॉजिटरी के लिए पहली प्रतिबद्धता नए साल की पूर्व संध्या पर तीन बजे हुई। और उसके बाद, जबकि देश के अधिकांश लोग नए साल की छुट्टियों पर थे, खोज टीम, जैसा कि वे कहते हैं, "आकाश आयोजित", लगातार विभिन्न प्रकार के कीड़े ढूंढना और ठीक करना।
खोज की स्थिरता के साथ समस्याएं पैदा हुईं और पूरे वर्ष हल हो गईं, लेकिन पहले तीन महीने सबसे अधिक तनावपूर्ण थे और सभी खोज इंजन डेवलपर्स से अधिकतम रिटर्न की आवश्यकता थी। उसी समय, वे संभवतः अगस्त 2010 तक केवल आग बुझाने में सक्षम थे। उसके बाद, खोज ने अंततः एक सामान्य जीवन जीना शुरू कर दिया, और डेवलपर्स एक अन्य महत्वपूर्ण समस्या को ठीक करने की तुलना में दीर्घकालिक कार्यों पर स्विच करने में सक्षम थे। विशेष रूप से, कोई यह सोच सकता है कि आम तौर पर खोज की वर्तमान वास्तुकला हमारे सामने कार्यों से कैसे मेल खाती है।
हमारे पास क्या था: 2010 के लिए ऐतिहासिक पृष्ठभूमि
2010 में, खोज वास्तुकला के बारे में एक आंतरिक प्रस्तुति योजनाबद्ध तरीके से इसे लगभग इस तरह से दिखाया गया है:
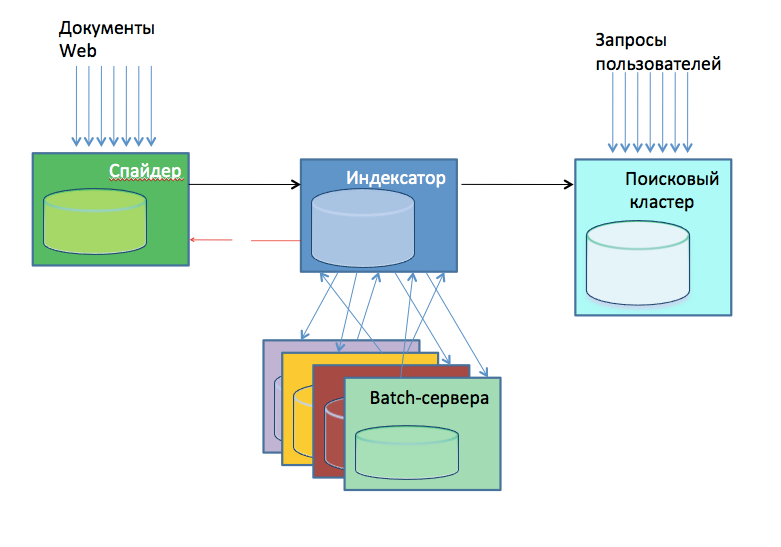
- स्पाइडर, वेब डाउनलोड करता है। ये 24 सर्वर हैं जो वेब के प्रत्येक भाग को पंप करते हैं। पंप को कौन सा हिस्सा डोमेन की ओर से हैश द्वारा निर्धारित किया गया था। मकड़ियों ने खुद को डाउनलोड किए गए पन्नों का एक डेटाबेस शामिल किया, और उन्होंने खुद निर्धारित किया कि क्या डाउनलोड करना है और क्या नहीं।
- इंडेक्सर्स, रेडी-मेड डेटाबेस इंडेक्स बनाते हैं। 2010 के अंत में उनमें से लगभग 30 भी थे। खुद को अनुक्रमित करने के अलावा, उन्होंने स्पैम, पोर्नोग्राफ़ी, आदि के लिए आने वाले पृष्ठों का विश्लेषण किया, गणना के लिए ब्याज के डेटा पर प्रकाश डाला, उदाहरण के लिए, एक प्रशस्ति पत्र के बाद के निर्माण के लिए लिंक।
- बैच-सर्वर (लगभग 20 टुकड़े) एक ही आईसी के बाहरी डेटा की गणना करते हैं। गणना सबसे विविध थे: कुछ तेज थे, कुछ धीमे थे।
- खोज क्लस्टर, डेढ़ सौ सर्वर। हमने इंडेक्सरों से डेटाबेस लिया और सीधे उपयोगकर्ता खोजों का प्रदर्शन किया।
2010 में, यह स्पष्ट हो गया कि डेटा भंडारण और प्रसंस्करण के संगठन में काफी कुछ वास्तु दोष हैं: "कई सौ सर्वर" से "कई सौ सर्वर" की स्थिति में तेजी से विकसित, संसाधित डेटा की मात्रा और उनके प्रसंस्करण की गति के लिए आवश्यकताएं बढ़ने लगीं, और पुराने वाले विधियां अब गुणवत्ता के काम के लिए तत्काल आवश्यकताओं को पूरा नहीं करती हैं। उदाहरण के लिए, उद्धरण सूचकांक की गणना एक सर्वर पर की जाती है और अब एक महीने के लिए काम किया जाता है। यदि सर्वर इस दौरान रिबूट हो गया या प्रक्रिया मेमोरी से बाहर हो गई, तो आपको फिर से शुरू करना होगा; इस प्रकार, कुछ समय पर उद्धरण सूचकांक ने अपडेट करना बंद कर दिया।
सूचकांक में रखे गए बहुत से प्रारंभिक डेटा की गणना अलग-अलग उपयोगकर्ताओं के तहत, अलग-अलग सर्वरों पर की जाती थी, और इस प्रकार के डेटा के लिए कुछ अनूठे तरीकों का उपयोग करके सूचकांक को वितरित किया जाता था। नतीजतन, डेवलपर्स उलझन में थे कि यह कहां से आता है: कई बार हमें पता चला कि कुछ कारणों से कुछ महीने पहले सूचकांक गिर गया था और किसी ने अभी तक इस पर ध्यान नहीं दिया था।
डेवलपर्स अक्सर एक ही कार्य को हल करते हैं: इनपुट डेटा को "कैसे" के माध्यम से देखा जाए ताकि कई डिस्क पर और फिर कई सर्वरों में उनकी गणना को समानांतर करना संभव हो सके। सभी समाधान कुछ समान थे, लेकिन एक-दूसरे से कुछ अलग थे, और इसके अलावा, अक्सर डेवलपर्स ने खरोंच से वितरित कंप्यूटिंग सिस्टम बनाने के लिए उसी कांटेदार तरीके को दोहराया, जो स्पष्ट रूप से प्रभावी विकास में योगदान नहीं देता था।
बड़ी समस्या दो दस्तावेज आधारों की उपस्थिति थी: एक मकड़ी के लिए, दूसरी इंडेक्सर के लिए। इससे एक ही दस्तावेज़ के भाग्य के बारे में निर्णय का एक धुंधला हो गया - उदाहरण के लिए, अनुक्रमणिका पर स्पैम का विश्लेषण दस्तावेज़ को सूचकांक से बाहर फेंकने का निर्णय ले सकता है, और मकड़ी इसे डाउनलोड करना जारी रखेगी। या, इसके विपरीत, किसी कारण से मकड़ी अपने डेटाबेस से दस्तावेज़ को बाहर फेंक सकती है, लेकिन सूचकांक से दस्तावेज़ को हटाने की आज्ञा तकनीकी खराबी के कारण सूचकांक तक नहीं पहुंच सकती है, इसलिए दस्तावेज़ लंबे समय तक सूचकांक में रहता है, जब तक कि अगला कचरा सफाई न हो।
यह स्पष्ट हो गया कि खोज के विकास को जारी रखने के लिए, हमें एक अलग, नए दृष्टिकोण की आवश्यकता थी: हमारे पास वितरित कार्य निष्पादन के लिए एक एकल मंच, एक उच्च-प्रदर्शन डेटाबेस का अभाव था। स्वतंत्र विकास और एक तैयार समाधान के बीच एक विकल्प बनाना आवश्यक था, और दूसरे मामले में, एक विकल्प खोजने के लिए जो हमें स्थिरता के संदर्भ में सूट करेगा और हमारे भार पर जल्दी से काम करेगा।
निम्नलिखित पोस्ट में मैं इस बारे में बात करूंगा कि हमने इस दृष्टिकोण को कैसे विकसित और कार्यान्वित किया, साथ ही साथ अन्य खोज इंजन कैसे काम करते हैं।
एंड्रे कालिनिन,
खोज मेल के प्रमुख