बिग सर्च इंजन डेटा तैयारी आर्किटेक्चर का अवलोकन
पिछली बार हमने
याद किया था कि Go.Mail.Ru की शुरुआत 2010 में कैसे हुई थी, और खोज इससे पहले कैसे हुई थी। इस पोस्ट में हम एक बड़ी तस्वीर खींचने की कोशिश करेंगे - हम दूसरों के काम करने के तरीके पर ध्यान देंगे, लेकिन पहले हम खोज वितरण के बारे में बात करेंगे।
सर्च इंजन कैसे वितरित होते हैं
जैसा कि आपने अनुरोध किया था, हमने सबसे लोकप्रिय खोज इंजनों की वितरण रणनीतियों की मूल बातों पर ध्यान केंद्रित करने का निर्णय लिया।
एक राय है कि इंटरनेट खोज उन सेवाओं में से एक है जो अधिकांश उपयोगकर्ता अपने दम पर चुनते हैं, और सबसे मजबूत को इस लड़ाई को जीतना चाहिए। यह स्थिति हमारे लिए बेहद आकर्षक है - यह इस कारण से है कि हम अपनी खोज तकनीकों में लगातार सुधार कर रहे हैं। लेकिन बाजार की स्थिति अपनी सुधार कर रही है, और तथाकथित "ब्राउज़र वार्स" पहले स्थान पर हस्तक्षेप करते हैं।
एक समय था जब खोज ब्राउज़र से संबंधित नहीं थी। तब खोज इंजन केवल एक और साइट थी जिसे उपयोगकर्ता अपने विवेक पर देखता था। कल्पना करें - 7 वें संस्करण तक इंटरनेट एक्सप्लोरर, जो 2006 में दिखाई दिया, एक खोज बार नहीं था; फ़ायरफ़ॉक्स के पहले संस्करण से एक खोज बार था, लेकिन वह स्वयं केवल 2004 में दिखाई दिया।
खोज स्ट्रिंग कहां से आया? यह ब्राउज़र के लेखकों द्वारा आविष्कार नहीं किया गया था - पहली बार यह 2001 में जारी Google टूलबार में दिखाई दिया। Google टूलबार ने ब्राउज़र में "Google खोज में त्वरित पहुंच" कार्यक्षमता को जोड़ा - अर्थात्, इसके पैनल में खोज लाइन:
Google ने अपना टूलबार क्यों जारी किया? यह है कि उस समय Google के ब्रांड प्रबंधक डगलस एडवर्ड्स ने अपनी पुस्तक "आई एम फीलिंग लकी: द कन्फेशन ऑफ गूगल एम्प्लॉयी नंबर 59" में अपने मिशन का वर्णन किया है:
"Microsoft के खिलाफ हमारे युद्ध में टूलबार एक गुप्त हथियार था। ब्राउज़र में टूलबार को एम्बेड करके, Google ने उपयोगकर्ताओं के लिए अनफ़िल्टर्ड पहुंच की लड़ाई में एक और मोर्चा खोल दिया। बिल गेट्स पीसी के अनुभव पर पूर्ण नियंत्रण चाहते थे, और अफवाहों ने कहा कि विंडोज़ के अगले संस्करण में डेस्कटॉप पर एक खोज बॉक्स शामिल होगा। हमें यह सुनिश्चित करने की आवश्यकता थी कि Google का खोज बॉक्स अप्रचलित अवशेष न बने। "
“टूलबार Microsoft के खिलाफ युद्ध में गुप्त हथियार था। टूलबार को ब्राउज़र में एकीकृत करके, Google ने उपयोगकर्ताओं के लिए सीधी पहुंच की लड़ाई में एक और मोर्चा खोल दिया। बिल गेट्स इस बात पर पूरा नियंत्रण रखना चाहते थे कि उपयोगकर्ता पीसी के साथ कैसे बातचीत करते हैं: अफवाहें चल रही थीं कि विंडोज के अगले संस्करण में, खोज पट्टी सीधे डेस्कटॉप पर स्थापित की जाएगी। Google खोज बार को अतीत का अवशेष बनने से रोकने के लिए उपाय करना आवश्यक था। "
टूलबार कैसे वितरित किया गया था? हाँ, सभी समान, लोकप्रिय सॉफ्टवेयर के साथ:
RealPlayer , Adobe
Macromedia Shockwave Player , आदि।
यह स्पष्ट है कि अन्य खोज इंजनों ने अपने टूलबार (उदाहरण के लिए याहू टूलबार) वितरित करना शुरू कर दिया, और ब्राउज़र निर्माताओं ने इस अवसर को खोज इंजन से आय का एक अतिरिक्त स्रोत प्राप्त करने में संकोच नहीं किया और "डिफ़ॉल्ट खोज इंजन" की अवधारणा को पेश करके खोज लाइन में खुद को बनाया।
ब्राउज़र निर्माताओं के व्यापार विभागों ने एक स्पष्ट रणनीति चुनी है: ब्राउज़र इंटरनेट के लिए उपयोगकर्ता का प्रवेश बिंदु है, डिफ़ॉल्ट खोज सेटिंग्स ब्राउज़र दर्शकों द्वारा उपयोग किए जाने की संभावना है - तो क्यों न इन सेटिंग्स को बेचा जाए? और वे अपने तरीके से सही थे, क्योंकि इंटरनेट खोज लगभग शून्य "चिपचिपाहट" वाला एक उत्पाद है।
इस बिंदु पर यह अधिक विस्तार से रहने योग्य है। कई लोग नाराज हैं: "नहीं, एक व्यक्ति को केवल उस प्रणाली की खोज करने और उपयोग करने की आदत है, जिस पर वह भरोसा करता है," लेकिन अभ्यास विपरीत साबित होता है। यदि, आपका इनबॉक्स या सोशल अकाउंट कहा जाता है। किसी कारण से, नेटवर्क अनुपलब्ध है, तो आप तुरंत किसी अन्य ईमेल सेवा या अन्य सामाजिक नेटवर्क पर नहीं जाते हैं, क्योंकि आप अपने खातों से "अटक" जाते हैं: आपके मित्र, सहकर्मी, परिवार उन्हें जानते हैं। एक खाता बदलना एक लंबी और दर्दनाक प्रक्रिया है। खोज इंजन के साथ, सब कुछ पूरी तरह से अलग है: उपयोगकर्ता किसी विशेष सिस्टम से बंधा नहीं है। यदि खोज इंजन किसी कारण से अनुपलब्ध है, तो उपयोगकर्ता अंत में काम करने के लिए बैठते हैं और इसके लिए प्रतीक्षा नहीं करते हैं - वे सिर्फ अन्य प्रणालियों पर जाते हैं (उदाहरण के लिए, हमने स्पष्ट रूप से LiveInternet काउंटर पर एक साल पहले, हमारे एक प्रतियोगी में एक दुर्घटना के दौरान देखा था। )। इसी समय, उपयोगकर्ता दुर्घटना से बहुत पीड़ित नहीं होते हैं, क्योंकि सभी खोज इंजनों को लगभग एक ही (खोज पंक्ति, क्वेरी, परिणाम पृष्ठ) व्यवस्थित किया जाता है और यहां तक कि किसी भी के साथ काम करते समय एक अनुभवहीन उपयोगकर्ता भी नहीं खोया जाता है। इसके अलावा, लगभग 90% मामलों में, उपयोगकर्ता को अपने प्रश्न का उत्तर मिलेगा, चाहे वह कोई भी प्रणाली खोजे।
तो, खोज, एक ओर, व्यावहारिक रूप से शून्य "चिपचिपाहट" है (अंग्रेजी में एक विशेष शब्द "चिपचिपाहट" है)। दूसरी ओर, कुछ प्रकार की खोज पहले से ही डिफ़ॉल्ट रूप से ब्राउज़र में पहले से इंस्टॉल है, और काफी बड़ी संख्या में लोग इसका उपयोग केवल इस कारण से करेंगे कि यह उनके लिए वहां से उपयोग करने के लिए सुविधाजनक है। और अगर खोज पंक्ति के पीछे की खोज उपयोगकर्ता के कार्यों को संतुष्ट करती है, तो वह इसका उपयोग करना जारी रख सकता है।
हम क्या करने आ रहे हैं? अग्रणी खोज इंजन के पास ब्राउज़रों के खोज तंत्रों के लिए लड़ने के अलावा कोई विकल्प नहीं था, अपने डेस्कटॉप खोज उत्पादों - टूलबार को वितरित करना, जो स्थापना प्रक्रिया के दौरान उपयोगकर्ता के ब्राउज़र में डिफ़ॉल्ट खोज को बदल देते हैं। इस संघर्ष के आरंभकर्ता Google थे, बाकी को अपना बचाव करना था। उदाहरण के लिए,
आप अपने साक्षात्कार में यैंडेक्स के निर्माता और मालिक अर्कडी वोल्ज़ो द्वारा ऐसे शब्दों को पढ़ सकते हैं:
“जब 2006-2007 में रूसी खोज बाजार में Google का हिस्सा बढ़ना शुरू हुआ, सबसे पहले हम यह नहीं समझ सके कि क्यों। फिर यह स्पष्ट हो गया कि Google इसे ब्राउज़र (ओपेरा, फ़ायरफ़ॉक्स) में एम्बेड करके खुद को बढ़ावा दे रहा है। और अपने स्वयं के ब्राउज़र और मोबाइल ऑपरेटिंग सिस्टम की रिहाई के साथ, Google ने प्रासंगिक बाजारों को पूरी तरह से नष्ट करना शुरू कर दिया। "
चूंकि Mail.Ru भी एक खोज है, यह "ब्राउज़र युद्धों" से अलग नहीं रह सकता है। हम बस दूसरों की तुलना में थोड़ी देर बाद बाजार में दाखिल हुए। अब हमारी खोज की गुणवत्ता स्पष्ट रूप से बढ़ गई है, और हमारा वितरण टूलबार के बहुत संघर्ष की प्रतिक्रिया है जो बाजार पर छाई हुई है। इसके अलावा, यह हमारे लिए वास्तव में महत्वपूर्ण है कि हमारी खोज का उपयोग करने की कोशिश कर रहे लोगों की बढ़ती संख्या परिणामों से संतुष्ट है।
वैसे, हमारी वितरण नीति निकटतम प्रतिद्वंद्वी की तुलना में कई गुना कम सक्रिय है। हम इसे काउंटर top.mail.ru पर देखते हैं, जो कि Runet की अधिकांश वेबसाइटों पर स्थापित है। यदि उपयोगकर्ता वितरण उत्पादों (टूलबार, स्वयं ब्राउज़र, पार्टनर ब्राउज़र का ब्राउज़र बॉक्स) में से एक के माध्यम से साइट पर जाता है, तो पैरामीटर क्लिड = URL में मौजूद है ... इस प्रकार, हम वितरण अनुरोधों की क्षमता का अनुमान लगा सकते हैं: प्रतियोगी लगभग 4 गुना अधिक है हमारे मुकाबले।
लेकिन आइए वितरण से आगे बढ़ते हैं कि अन्य खोज इंजन कैसे काम करते हैं। आखिरकार, हमने स्वाभाविक रूप से अन्य खोज इंजनों के वास्तु समाधानों के अध्ययन के साथ वास्तुकला की हमारी आंतरिक चर्चा शुरू की। मैं उनके आर्किटेक्चर का विस्तार से वर्णन नहीं करूंगा - इसके बजाय, मैं खुली सामग्रियों के लिंक दूंगा और उनके समाधान की उन विशेषताओं को उजागर करूंगा जो मेरे लिए महत्वपूर्ण लगते हैं।
बड़े खोज इंजन में डेटा की तैयारी
विचरनेवाला
अब बंद किए गए रैम्बलर सर्च इंजन में कई दिलचस्प वास्तुशिल्प विचार थे। उदाहरण के लिए, यह उनके अपने डेटा स्टोरेज सिस्टम (NoSQL के बारे में जाना जाता था, क्योंकि यह अब इस तरह के सिस्टम को कॉल करने के लिए फैशनेबल है) और कंप्यूटिंग हाइक्स (
या एचसीएस) को वितरित किया गया था, जिसका उपयोग विशेष रूप से लिंक ग्राफ पर गणना के लिए किया गया था। HICS ने एकल, सार्वभौमिक प्रारूप में खोज के भीतर डेटा की प्रस्तुति को मानकीकृत करने की अनुमति दी।
मकड़ी के संगठन में रामबलर की वास्तुकला हमारे से काफी अलग थी। हमारे मकड़ी को एक अलग सर्वर के रूप में निष्पादित किया गया था, अपने स्वयं के, स्व-लिखित, डाउनलोड किए गए पृष्ठों के पते के आधार के साथ। प्रत्येक साइट को डाउनलोड करने के लिए, एक अलग प्रक्रिया शुरू की गई थी, जिसने एक साथ पृष्ठों को डाउनलोड किया, उन्हें पार्स किया, नए लिंक पर प्रकाश डाला और तुरंत उनका अनुसरण किया। रामबलर की मकड़ी को बहुत सरल बना दिया गया था।
एक सर्वर पर, एक बड़ी पाठ फ़ाइल सभी दस्तावेजों के पते के साथ स्थित थी, जो एक पंक्ति में रामबेलर को ज्ञात थी, जो कि लेक्सोग्राफिक क्रम में क्रमबद्ध थी। दिन में एक बार, इस फाइल को बाईपास किया गया और पंपिंग के लिए अन्य टेक्स्ट फाइल-कार्य उत्पन्न किए गए, जो विशेष कार्यक्रमों द्वारा किए गए जो केवल पते की सूची से दस्तावेज़ डाउनलोड कर सकते थे। फिर दस्तावेजों को पार्स किया गया, लिंक निकाले गए और सभी ज्ञात दस्तावेजों की इस बड़ी फ़ाइल-सूची के बगल में रखा गया, सॉर्ट किया गया, जिसके बाद सूचियों को एक नई बड़ी फ़ाइल में मिला दिया गया, और चक्र फिर से दोहराया गया।
इस दृष्टिकोण के फायदे सादगी थे, सभी ज्ञात दस्तावेजों की एक रजिस्ट्री की उपस्थिति। नुकसान ताजे निकाले गए दस्तावेज़ के पते पर तुरंत जाने में असमर्थता थी, क्योंकि नए दस्तावेज़ डाउनलोड करने से मकड़ी के अगले चलना पर ही हो सकता है। इसके अलावा, डेटाबेस का आकार और इसकी प्रसंस्करण गति एक सर्वर तक सीमित थी।
हमारा मकड़ी, इसके विपरीत, साइट से सभी नए लिंक का तेज़ी से पालन कर सकता है, लेकिन यह बाहर से बहुत खराब तरीके से प्रबंधित किया गया था। पते में अतिरिक्त डेटा "डालना" (साइट के भीतर दस्तावेजों की रैंकिंग के लिए आवश्यक, पंपिंग की प्राथमिकता निर्धारित करना) मुश्किल था, डेटाबेस को डंप करना मुश्किल था।
Yandex
यैंडेक्स के आंतरिक खोज इंजन के बारे में बहुत कुछ नहीं पता था, जब तक कि डेन रास्कोलोव ने
अपने व्याख्यान पाठ्यक्रम में इसके बारे
में बात नहीं की।
वहां से, आप पता लगा सकते हैं कि यांडेक्स खोज में दो अलग-अलग क्लस्टर हैं:
- बैच प्रसंस्करण
- वास्तविक समय डेटा प्रोसेसिंग (यह वास्तव में "वास्तविक समय" नहीं है, इस अर्थ में यह शब्द नियंत्रण प्रणालियों में उपयोग किया जाता है जहां कार्यों के निष्पादन में देरी महत्वपूर्ण हो सकती है। बल्कि, यह दस्तावेज़ के सूचकांक में जितनी जल्दी हो सके और दूसरों के स्वतंत्र रूप से होने की संभावना है। दस्तावेज़ या कार्य; वास्तविक समय के "नरम" संस्करण का एक प्रकार)
पहले का उपयोग नियमित इंटरनेट डाउनलोड के लिए किया जाता है, दूसरा - सबसे अच्छे और सबसे दिलचस्प दस्तावेजों के सूचकांक में वितरण के लिए जो अभी-अभी सामने आए हैं। हम अब तक केवल बैच प्रसंस्करण पर विचार करेंगे, क्योंकि इससे पहले कि सूचकांक वास्तविक समय में अपडेट किया गया था, तब हम काफी दूर थे, हम हर दो दिनों में एक बार सूचकांक को अपडेट करने के लिए बाहर जाना चाहते थे।
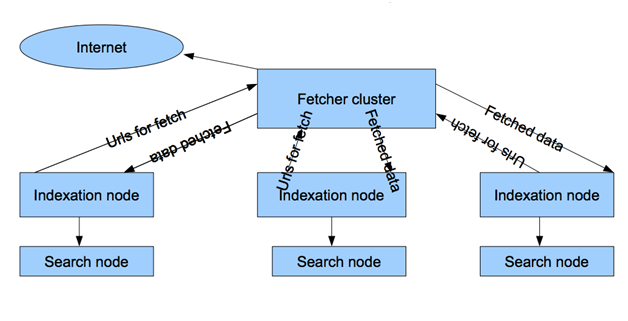
उसी समय, इस तथ्य के बावजूद कि बाहरी रूप से यैंडेक्स बैच प्रोसेसिंग क्लस्टर कुछ हद तक हमारे स्विंग और इंडेक्स क्लस्टर की जोड़ी के समान था, इसमें कई गंभीर अंतर थे:
- पृष्ठ के पते का आधार एक है, जो अनुक्रमण नोड्स पर संग्रहीत है। नतीजतन, दो डेटाबेस के सिंक्रनाइज़ेशन के साथ कोई समस्या नहीं है।
- पम्पिंग लॉजिक कंट्रोल को इंडेक्सिंग नोड्स में स्थानांतरित किया जाता है, अर्थात। स्पाइडर नोड्स बहुत सरल हैं, डाउनलोड करें जो इंडेक्स उन्हें इंगित करते हैं। हमारे मकड़ी ने खुद निर्धारित किया कि उसे क्या और कब डाउनलोड करना है।
- और, एक बहुत ही महत्वपूर्ण अंतर - अंदर, सभी डेटा दस्तावेजों, साइटों, लिंक के संबंधपरक तालिकाओं के रूप में प्रस्तुत किया जाता है। हमारे साथ, सभी डेटा अलग-अलग होस्ट को वितरित किए गए थे, विभिन्न स्वरूपों में संग्रहीत किए गए थे। डेटा की सारणीबद्ध प्रस्तुति उनके लिए उपयोग को सरल बनाती है, जिससे आप विभिन्न नमूने बना सकते हैं और सूचकांक के सबसे विविध विश्लेषण प्राप्त कर सकते हैं। हम इस सब से वंचित थे, और उस समय केवल हमारे दो दस्तावेज़ ठिकानों (स्पाइडर और इंडेक्सर) के सिंक्रोनाइज़ेशन को एक सप्ताह हो गया था, और हमें इस समय के लिए दोनों समूहों को रोकना था।
गूगल
गूगल, एक शक के बिना, एक विश्व प्रौद्योगिकी नेता है, इसलिए वे हमेशा इस पर ध्यान देते हैं, विश्लेषण करें कि उसने क्या किया है, कब और क्यों किया है। और, Google खोज वास्तुकला, निश्चित रूप से, हमारे लिए सबसे दिलचस्प था। दुर्भाग्य से, Google शायद ही कभी अपनी स्थापत्य सुविधाओं का खुलासा करता है, प्रत्येक लेख एक बड़ी घटना है और लगभग तुरंत एक समानांतर OpenSource परियोजना (कभी-कभी एक नहीं) उत्पन्न करता है जो वर्णित तकनीकों को लागू करता है।
जो लोग Google खोज की सुविधाओं में रुचि रखते हैं, उन्हें आत्मविश्वास से आंतरिक बुनियादी ढांचे के लिए कंपनी के सबसे महत्वपूर्ण विशेषज्ञों में से एक की सभी प्रस्तुतियों और भाषणों का अध्ययन करने की सलाह दी जा सकती है -
जेफरी डीन (जेफरी डीन) , उदाहरण के लिए:
इन प्रस्तुतियों के आधार पर, हम Google खोज वास्तुकला की निम्न विशेषताओं पर प्रकाश डाल सकते हैं:
- डेटा की तैयारी के लिए सारणीबद्ध संरचना। संपूर्ण खोज डेटाबेस एक विशाल तालिका में संग्रहीत किया जाता है, जहां कुंजी दस्तावेज़ का पता है, और मेटा-जानकारी को अलग-अलग कॉलम में संग्रहीत किया जाता है, जो परिवारों में एकजुट होते हैं। इसके अलावा, तालिका को मूल रूप से इस तरह से बनाया गया था कि विरल डेटा के साथ प्रभावी रूप से काम करने के लिए (यानी जब तक कि सभी दस्तावेजों में कॉलम में मान हों)।
- एकीकृत वितरित कंप्यूटिंग प्रणाली MapReduce। डेटा तैयारी (एक खोज सूचकांक बनाने सहित) बिगटेबल टेबल या वितरित जीएफएस फ़ाइल सिस्टम में फ़ाइलों पर किए गए मैप्रेडिक कार्यों का एक अनुक्रम है।
यह सब बहुत उचित लगता है: सभी ज्ञात दस्तावेज़ पते एक बड़ी तालिका में संग्रहीत किए जाते हैं, उन्हें प्राथमिकता दी जाती है, लिंक ग्राफ पर गणना की जाती है, आदि, खोज मकड़ी पंप किए गए पृष्ठों की सामग्री को इसमें लाती है, और इसके परिणामस्वरूप, एक सूचकांक इसके ऊपर बनाया गया है।
बिगटेबल में नवाचारों के बारे में एक अन्य Google विशेषज्ञ, डैनियल पेंग (डैनियल पेंग) द्वारा एक और दिलचस्प प्रस्तुति है, जिसने कुछ ही मिनटों में सूचकांक में नए दस्तावेजों को जोड़ने के लिए त्वरित एहसास करने की अनुमति दी। यह तकनीक "बाहर" Google को
कैफीन नाम से विज्ञापित
किया गया था, और प्रकाशनों में पेरकोलेटर कहा जाता था। OSDI'2010 में प्रदर्शन का एक वीडियो
यहाँ देखा जा सकता
है ।
बहुत अशिष्टता से बोलते हुए, यह वही बिगटेबल है, लेकिन जिसमें तथाकथित है ट्रिगर्स, - आपके कोड के टुकड़ों को लोड करने की क्षमता जो तालिका के अंदर परिवर्तन पर काम करती है। यदि अब तक मैंने डेटा के बैच प्रसंस्करण का वर्णन किया है, अर्थात। जब डेटा को संयुक्त किया जाता है और यदि संभव हो तो एक साथ संसाधित किया जाता है, ट्रिगर्स पर उसी का कार्यान्वयन पूरी तरह से अलग है। मान लीजिए कि एक मकड़ी ने कुछ डाउनलोड किया है, एक तालिका में नई सामग्री रखी है; ट्रिगर ट्रिगर, संकेत "नई सामग्री दिखाई दी है, इसे अनुक्रमित करने की आवश्यकता है।" अनुक्रमण प्रक्रिया तुरंत शुरू हुई। यह पता चला है कि परिणामस्वरूप खोज इंजन के सभी कार्यों को उप-प्रकारों में विभाजित किया जा सकता है, जिनमें से प्रत्येक को अपने स्वयं के क्लिक द्वारा लॉन्च किया गया है। बड़ी मात्रा में उपकरण, संसाधन और डीबग किए गए कोड के साथ, आप नए दस्तावेज़ों को जोड़ने की समस्या का हल केवल एक मिनट में कर सकते हैं - Google द्वारा प्रदर्शित।
Google आर्किटेक्चर और यैंडेक्स आर्किटेक्चर के बीच का अंतर, जहां वास्तविक समय इंडेक्स अपडेटिंग सिस्टम भी संकेत दिया गया था, यह है कि Google, जैसा कि दावा किया गया है, इंडेक्स के निर्माण की पूरी प्रक्रिया ट्रिगर्स पर निष्पादित की जाती है, जबकि यैंडेक्स के पास केवल सबसे छोटे, सबसे छोटे उपसमुच्चय के लिए है मूल्यवान दस्तावेज।
Lucene
यह एक और खोज इंजन - ल्यूसीन का उल्लेख करने योग्य है। यह जावा में लिखा गया एक फ्रीवेयर सर्च इंजन है। एक अर्थ में, ल्यूसिन खोज इंजन बनाने के लिए एक मंच है, उदाहरण के लिए, नच नामक एक वेब खोज इंजन ने इससे नवोदित किया है। वास्तव में, Lucene सूचकांक और खोज इंजन बनाने के लिए खोज इंजन है, और Nutch एक ही प्लस मकड़ी है जो पृष्ठों को पंप करती है, क्योंकि खोज इंजन आवश्यक रूप से वेब पर मौजूद दस्तावेजों की खोज नहीं करता है।
वास्तव में, ल्यूसीन के पास कई दिलचस्प समाधान नहीं हैं, जिन्हें अरबों दस्तावेजों के साथ एक बड़े वेब खोज इंजन द्वारा उधार लिया जा सकता है। दूसरी ओर, यह मत भूलो कि यह ल्यूसीन डेवलपर्स थे जिन्होंने हडोप और HBase प्रोजेक्ट लॉन्च किए थे (हर बार जब Google से एक नया दिलचस्प लेख दिखाई दिया, तो ल्यूसीन लेखक घर पर अपने आवाज वाले समाधान को लागू करने की कोशिश करते थे। उदाहरण के लिए, HBase, जो एक BigTable क्लोन है, दिखाई दिया)। । हालाँकि, ये परियोजनाएँ लंबे समय से अपने अस्तित्व में हैं।
मेरे लिए ल्यूसिन / नच में, यह दिलचस्प था कि वे कैसे हडोप का इस्तेमाल करते थे। उदाहरण के लिए, नच में, वेब को पंप करने के लिए एक विशेष मकड़ी लिखी गई थी, जिसे पूरी तरह से हडोप के कार्यों के रूप में प्रदर्शन किया गया था। यानी पूरी मकड़ी बस प्रक्रियाओं है कि MapReduce प्रतिमान में Hadoop में चला रहे हैं। यह एक बल्कि असामान्य समाधान है जो कि Hadoop का उपयोग करने के तरीके से परे है। आखिरकार, यह बड़ी मात्रा में डेटा को संसाधित करने के लिए एक मंच है, और यह मानता है कि डेटा पहले से ही उपलब्ध है। लेकिन यहां यह कार्य कुछ भी गणना या प्रक्रिया नहीं करता है, बल्कि, इसके विपरीत, इसे डाउनलोड करता है।
एक ओर, यह समाधान अपनी सादगी के साथ लुभाता है। आखिरकार, मकड़ी को पंप करने के लिए एक साइट के सभी पते प्राप्त करने की आवश्यकता होती है, उनके चारों ओर एक के बाद एक, मकड़ी खुद को भी वितरित करना चाहिए और कई सर्वरों पर चलना चाहिए। इसलिए हम साइटों के लिए पतों के विभाजक के रूप में एक मैपर बनाते हैं, और हम एक रिड्यूसर के रूप में प्रत्येक व्यक्तिगत पंपिंग प्रक्रिया को लागू करते हैं।
दूसरी ओर, यह एक अधिक साहसिक निर्णय है, क्योंकि यह साइटों को पंप करने के लिए कठिन है - हर साइट की गारंटी समय के लिए जिम्मेदार नहीं है, और क्लस्टर के कंप्यूटिंग संसाधनों को उस पर खर्च किया जाता है जो किसी और के वेब सर्वर से जवाब का इंतजार कर रहा है। इसके अलावा, "धीमी" साइटों की समस्या हमेशा होती है जब पर्याप्त रूप से बड़ी संख्या में पंपिंग पते होते हैं। 20% समय के लिए, मकड़ी तेजी से वेबसाइटों से 80% दस्तावेजों को पंप करता है, फिर 80% समय धीमी वेबसाइटों को डाउनलोड करने की कोशिश करता है - और लगभग कभी भी उन्हें पूरी तरह से पंप नहीं कर सकता है, आपको हमेशा कुछ छोड़ना होगा और इसे "अगली बार" छोड़ना होगा।
, . , , , « ».
, , , .