लंबे समय तक, मुझे इंटरनेट पर लेखों से परेशान किया गया था जिसमें स्टैटिक कोड एनालाइज़र का उपयोग करने के लाभों का न्याय करने के लिए छोटी परियोजनाओं की जांच के आधार पर प्रयास किया गया था।
मेरे द्वारा पढ़े गए कई लेख इस धारणा को बनाते हैं। यदि कोड की एन लाइनों की एक परियोजना में 2 त्रुटियां पाई गईं, तो एन * 100 लाइनों की एक पूर्ण परियोजना में, आप केवल 200 त्रुटियां पा सकते हैं। और इससे यह निष्कर्ष निकाला गया है कि स्थैतिक विश्लेषण निश्चित रूप से अच्छा है, लेकिन महान नहीं है। बहुत कम त्रुटियाँ। अन्य दोष खोज तकनीकों को विकसित करना बेहतर है।
दो मुख्य कारण हैं कि लोग छोटी परियोजनाओं पर विश्लेषक की कोशिश क्यों करते हैं। सबसे पहले, एक बड़े कामकाजी मसौदे को सत्यापित करना इतना आसान नहीं है। आपको कुछ कॉन्फ़िगर करने, कहीं कुछ लिखने, कुछ पुस्तकालयों को स्कैन से बाहर करने की आवश्यकता है, और इसी तरह। स्वाभाविक रूप से, मैं यह सब नहीं करना चाहता। जल्दी से कुछ जांचने की इच्छा है, और सेटिंग्स के साथ गड़बड़ नहीं है। दूसरे, एक बड़ी परियोजना को बड़ी संख्या में नैदानिक संदेश प्राप्त होंगे। और फिर से मैं उनका विश्लेषण करने में बहुत समय खर्च नहीं करना चाहता। एक छोटी परियोजना लेना सीखना बहुत आसान है।
नतीजतन, एक व्यक्ति एक बड़े प्रोजेक्ट को नहीं छूता है जिस पर वह काम कर रहा है, लेकिन कुछ छोटा लेता है। उदाहरण के लिए, यह उनका पुराना कोर्स प्रोजेक्ट या गिटहब के साथ एक छोटा सा ओपन सोर्स प्रोजेक्ट हो सकता है।
वह इस परियोजना की जाँच करता है और एक रैखिक प्रक्षेप करता है कि वह अपनी बड़ी परियोजना में कितनी त्रुटियाँ पा सकता है। और फिर वह शोध के बारे में एक लेख लिखता है।
पहली नज़र में, ऐसे अध्ययन सही और उपयोगी लगते हैं। लेकिन मुझे यकीन था कि ऐसा नहीं था।
इन सभी अध्ययनों का पहला दोष स्पष्ट है। वे यह भूल जाते हैं कि किसी प्रोजेक्ट का डिबगिंग वर्जन लिया जाता है। स्थैतिक विश्लेषण द्वारा जल्दी से पाया जा सकने वाली कई त्रुटियां धीरे-धीरे और दुख से खोजी गईं। उन्हें परीक्षण के दौरान या उपयोगकर्ता की शिकायतों के बाद पता चला था। यही है, यह भूल गया है कि स्थैतिक विश्लेषण निरंतर का एक उपकरण है, लेकिन एकल उपयोग नहीं है। आखिरकार, प्रोग्रामर नियमित रूप से वार्निंग को देखते हैं, संकलक द्वारा जारी किए गए, और वर्ष में एक बार नहीं।
शोध में दूसरे दोष के साथ, चीजें अधिक जटिल और दिलचस्प हैं। मेरी स्पष्ट भावना थी कि छोटी और बड़ी परियोजनाओं का समान रूप से मूल्यांकन करना असंभव है। कोड के 1000 लाइनों वाले टर्म पेपर के लिए छात्र को 5 दिनों में एक अच्छा प्रोजेक्ट लिखने दें। मुझे यकीन है कि 500 दिनों में वह कोड की 100,000 लाइनों की मात्रा के साथ एक अच्छा वाणिज्यिक आवेदन नहीं लिख पाएगा। यह जटिलता के विकास में बाधा होगी। कार्यक्रम जितना बड़ा हो जाता है, उतना ही मुश्किल होता है कि उसमें नई कार्यक्षमता जोड़ना, जितना अधिक उसे परखना और त्रुटियों के साथ अधिक गड़बड़ करना होता है।
सामान्य तौर पर, एक सनसनी थी, लेकिन मैं इसे किसी भी तरह से तैयार नहीं कर सका। अचानक, एक कर्मचारी मेरी सहायता के लिए आया। जैसा कि उन्होंने स्टीव मैककोनेल की किताब, द परफेक्ट कोड का अध्ययन किया, उन्होंने इसमें एक दिलचस्प टैबलेट देखा। और मैं उसके बारे में भूल गया। यह टैबलेट अपने स्थान पर सब कुछ तुरंत डाल देता है!
बेशक, छोटी परियोजनाओं पर विचार करते हुए, बड़ी संख्या में त्रुटियों की संख्या का अनुमान लगाना गलत है! उनके पास त्रुटियों का एक अलग घनत्व है!
बड़ी परियोजना, कोड की प्रति 1000 लाइनों में अधिक त्रुटियां। इस अद्भुत तालिका पर एक नज़र डालें:

तालिका 1. परियोजना का आकार और विशिष्ट त्रुटि घनत्व। पुस्तक डेटा स्रोतों को इंगित करती है: "प्रोग्राम गुणवत्ता और प्रोग्रामर उत्पादकता" (जोन्स, 1977), "सॉफ़्टवेयर लागत का अनुमान लगाना" (जोन्स, 1998)।
डेटा को समझना आसान बनाने के लिए, हम ग्राफ़ बनाएंगे।
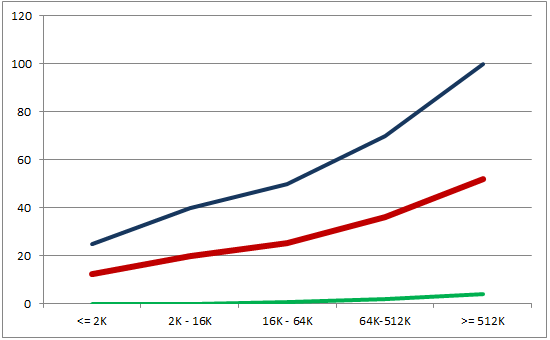
चार्ट 1. परियोजना में विशिष्ट त्रुटि घनत्व। ब्लू अधिकतम राशि है। लाल औसत राशि है। हरा कम से कम है।
मुझे लगता है, इन रेखांकन को देखते हुए, यह स्पष्ट हो जाता है कि निर्भरता रैखिक नहीं है। जितना बड़ा प्रोजेक्ट होगा, गलती करना उतना ही आसान होगा।
बेशक, सभी त्रुटियों का स्थैतिक विश्लेषक द्वारा पता नहीं लगाया जाता है। हालांकि, यह परियोजना जितनी बड़ी है, उतनी ही प्रभावी है। और भी अधिक प्रभावी अगर नियमित रूप से उपयोग किया जाता है।
वैसे, एक छोटी परियोजना में, त्रुटियां बिल्कुल भी नहीं मिल सकती हैं। या उनमें से केवल एक जोड़ा होगा। इस मामले में, हम पूरी तरह से गलत निष्कर्ष पर आ सकते हैं। इसलिए, मैं वास्तविक कार्य परियोजनाओं पर त्रुटियों को खोजने के लिए विभिन्न उपकरणों की कोशिश करने की अत्यधिक अनुशंसा करता हूं।
हां, यह अधिक कठिन है, लेकिन आपको संभावनाओं के बारे में सही विचार मिलेगा। उदाहरण के लिए,
पीवीएस-स्टूडियो के लेखकों में से एक के रूप में, मैं वादा कर सकता हूं कि हम उन सभी की मदद करने की कोशिश करेंगे जो हमसे संपर्क करते हैं। यदि पीवीएस-स्टूडियो सीखने की प्रक्रिया में कुछ विफल हो जाता है, तो हमें
लिखें । अक्सर, टूल को ठीक से ट्यून करके कई समस्याओं को हल किया जा सकता है।
पुनश्चमैं आपको Reddit साइट पर अपने Twitter
@Code_Analysis या
समुदाय से जुड़ने के लिए आमंत्रित करता हूं। उनमें मैं नियमित रूप से विषयों पर दिलचस्प लेखों के लिंक प्रकाशित करता हूं: सी / सी ++, स्थिर कोड विश्लेषण, अनुकूलन, और प्रोग्रामिंग के बारे में अन्य रोचक बातें। लेख हमारे और अन्य दोनों। और फिर मुझे "आई एम पीआर" को छोड़कर हर जगह बाहर रखा गया था।