अब हेबर छँटाई और रेटिंग इकाइयों (रिकॉर्ड्स, पोस्ट, टिप्पणियां) पर चर्चा करना जारी रखता है, इसलिए मैं खुद इसमें रुचि रखता था और, बस reddit पर होने के कारण, यह पता लगाने का फैसला किया कि कैसे छँटाई वहाँ काम करती है, और एक उत्कृष्ट और संक्षिप्त लेख आया।
यह पोस्ट सॉर्टिंग एल्गोरिदम के विश्लेषण का एक सिलसिला है (पिछली बार
हैकर न्यूज़ था)। इस बार, हम
Reddit पर पोस्ट और टिप्पणियों को कैसे सॉर्ट करते हैं, इस पर ध्यान देंगे। Reddit के एल्गोरिदम समझने और लागू करने के लिए पर्याप्त सरल हैं।
इस पोस्ट का पहला भाग सॉर्टिंग पोस्टों पर और दूसरा सॉर्टिंग टिप्पणियों पर केंद्रित होगा। वे काफी भिन्न होते हैं, और रान्डेल मुनरो (xkcd) टिप्पणियों को छांटने के तरीके के पीछे है।
हम पदों की छँटाई करते हैं
रेडिट एक ओपन-सोर्स प्रोजेक्ट है और इसका कोड जीथब पर पूरी तरह से उपलब्ध है। यह अजगर में लिखा है, आप
यहां स्रोत कोड देख सकते हैं। सी-कोड में आगे संकलन (अनुवाद) के लिए उनकी छँटाई एल्गोरिदम पाइरेक्स के तहत लिखी गई है। प्रदर्शन के कारण Pyrex को चुना गया था। मैं शुद्ध अजगर में उनके कार्यान्वयन को फिर से लिखता हूं ताकि उन्हें पढ़ने में आसानी हो।
"हॉट रैंकिंग" नामक डिफ़ॉल्ट सॉर्टिंग एल्गोरिथ्म को निम्नानुसार लागू किया गया है:
गणितीय संकेतन में, यह एल्गोरिथम इस तरह दिखता है:

एजिंग रिकॉर्ड्स
यहाँ पर छँटाई के संबंध में अप्रचलन के बारे में क्या कहना है (बाद में बस मूल्यांकन) और छँटाई:
- लेख की आयु का उसकी रेटिंग पर बहुत प्रभाव पड़ता है, नया - वह रेटिंग जितनी अधिक होगी
- अप्रचलित लेखों के साथ रेटिंग घटती नहीं है, बल्कि नए लेखों के साथ बढ़ती है
यहां इस बात का एक दृश्य है कि लेखों की रेटिंग समान संख्या और प्लसस के साथ कैसे दिखती है, लेकिन अलग-अलग प्रकाशन समय के साथ:

लघुगणक पैमाने
हॉट रैंकिंग लॉगरिदम का उपयोग करता है ताकि पहले n वोटों का वजन भविष्य के n + r वोटों से अधिक हो। नतीजतन, यह पता चलता है कि पहले 10 प्लस का वजन अगले 100 के समान है, जिनका वजन अगले 1000 के बराबर है, आदि।
यहाँ यह कैसा दिखता है:

और यहाँ एक लघुगणक के बिना की तरह दिखेगा:

"विपक्ष" का प्रभाव
Reddit उन साइटों में से एक है जहाँ आप ऋण कर सकते हैं। जैसा कि आपने कोड में देखा, पोस्ट का "स्कोर" पेशेवरों और विपक्षों के बीच अंतर के बराबर है।
अंत में, यह इस तरह दिखता है:

इससे उन पदों पर बड़ा प्रभाव पड़ता है जो बहुत सारे पेशेवरों और विपक्षों (तथाकथित विवादास्पद पदों) को प्राप्त करते हैं, उन्हें केवल प्लसस वाले पदों की तुलना में कम रेटिंग मिलती है। शायद यही कारण है कि बिल्ली के बच्चे मुख्य एक पर अक्सर होते हैं :) (लगभग प्रति। - वास्तव में, यह इसलिए है क्योंकि आपने / r / aww से सदस्यता समाप्त नहीं की थी)
पोस्ट सॉर्टिंग निष्कर्ष
- Add time एक बहुत महत्वपूर्ण पैरामीटर है, नए पोस्ट को उच्च रेटिंग मिलेगी
- रेटिंग वक्र दस के लघुगणक पर बनाया गया है। पहले 10 प्लस अगले 100 के बराबर हैं
- विवादास्पद पोस्ट जो पेशेवरों और विपक्ष दोनों को मिली हैं, वे सिर्फ "प्लस" पदों से कम होंगे
टिप्पणी कैसे काम करती है
रेडिट के सर्वश्रेष्ठ रैंकिंग के विचार के पीछे Xkcd के रान्डेल मुनरो है। उन्होंने इस बारे में एक उत्कृष्ट लेख लिखा:
रेडिट की नई टिप्पणी छँटाई प्रणालीआपको इस लेख को पढ़ना चाहिए, इसमें यह बहुत स्पष्ट रूप से एल्गोरिथ्म के सिद्धांत की व्याख्या करता है। इसे संक्षेप में, हम कह सकते हैं:
- हॉट रैंकिंग एल्गोरिदम रेटिंग टिप्पणियों के लिए उपयुक्त नहीं है, क्योंकि यह पोस्ट की उम्र पर बहुत निर्भर करता है।
- टिप्पणियों में, आपको सबसे अच्छी टिप्पणियों को ऊपर रखने की आवश्यकता है, भले ही वे कब भेजे गए हों
- इसका समाधान 1927 में एडविन विल्सन द्वारा पाया गया और इसे "विल्सन स्कोर अंतराल" कहा गया, विल्सन अंतराल का उपयोग "विश्वास द्वारा छँटाई" के लिए किया जा सकता है।
- जब विश्वास द्वारा हल किया जाता है, तो कुल मतों को प्रत्येक से एक काल्पनिक पूर्ण मत के सांख्यिकीय नमूने के रूप में प्रस्तुत किया जाता है - जैसे कि एक जनमत सर्वेक्षण में
- औसत रेटिंग के आधार पर छाँटने का तरीका नहीं - आत्मविश्वास रेटिंग एल्गोरिथ्म को अच्छी तरह से वर्णन करता है, मैं इसे पढ़ने की सलाह देता हूँ! (लगभग प्रति। - यह भी एक अच्छा लेख है )
टिप्पणी छँटाई कोड का अन्वेषण करें
विश्वास सॉर्टिंग एल्गोरिथ्म
_sorts.pyx में कार्यान्वित किया
जाता है , मैंने इसे शुद्ध अजगर (और कुछ कैशिंग ऑप्टिमाइज़ेशन को हटा दिया) में फिर से लिखा है:
ट्रस्ट छांटना विल्सन अंतराल का उपयोग करता है और गणितीय अंकन इस तरह दिखता है:
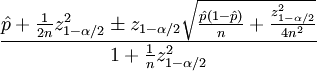
इस सूत्र के मापदंडों की सूची:
- पी - सकारात्मक रेटिंग का हिस्सा
- n - वोटों की कुल संख्या
- z α / 2 मानक सामान्य वितरण का (1-α / 2) मात्रात्मक है
चलो ऊपर संक्षेप में बताएं:
- कॉन्फिडेंस सॉर्ट प्रत्येक के काल्पनिक पूर्ण वोट के सांख्यिकीय नमूने के रूप में वोटों की संख्या का प्रतिनिधित्व करता है
- गोपनीयता छँटाई, टिप्पणी के लिए एक पूर्वानुमानित रेटिंग देती है, जिसे वह 85% संभावना के साथ प्राप्त करेगा
- अधिक वोट, अनुमानित रेटिंग के करीब वास्तविक पहुंचता है
- विल्सन का अंतराल वोटों की एक छोटी संख्या और अत्यधिक संभावना के मामलों में भी अच्छा है
रान्डेल का एक बेहतरीन उदाहरण है कि कैसे टिप्पणियों को रेट किया जाता है:
यदि किसी टिप्पणी में एक से अधिक और शून्य minuses हैं, तो इसकी 100% रेटिंग है, लेकिन चूंकि हमारे पास बहुत कम डेटा है, सिस्टम इसे नीचे रखेगा। लेकिन, अगर उसके पास 10 प्लस और केवल एक माइनस हैं, तो सिस्टम को 40 प्लस और 20 मिनट के साथ किसी भी टिप्पणी के ऊपर रखने के लिए पर्याप्त भरोसा (विश्वास) हो सकता है, यह मानते हुए कि जब वह 40 प्लस हो जाता है, तो उसके पास कम होगा 20 विपक्ष। और सबसे अच्छी बात यह है कि भले ही यह गलत हो (जो कि 15% मामलों में होता है), सिस्टम जल्दी से अधिक डेटा प्राप्त करेगा (क्योंकि एक बुरा टिप्पणी शीर्ष पर है, इसे देखा जाएगा और ज़िन्नुषेनी) और टिप्पणी जहां यह होनी चाहिए।
जैसा कि हम देख सकते हैं, यह एल्गोरिदम किसी भी तरह से रिकॉर्ड की अप्रचलन से प्रभावित नहीं है।
आइए देखें कि यह कैसा दिखता है:

जैसा कि आप देख सकते हैं, यह छंटाई इस बारे में चिंतित नहीं है कि एक टिप्पणी को कितने वोट मिले, लेकिन कुल वोटों और नमूने के आकार के संबंध में कितने प्लस।
जैसा कि इवान मिलर ने कहा, विल्सन अंतराल का उपयोग न केवल रेटिंग के लिए किया जा सकता है।
यहाँ तीन उदाहरण दिए गए हैं:
- स्पैम का पता लगाएं: जो लोग इस चिह्न को स्पैम के रूप में देखते हैं उनका कितना प्रतिशत है?
- "सर्वश्रेष्ठ" सूची बनाना: इसे देखने वाले कितने प्रतिशत लोगों को "सर्वश्रेष्ठ" के रूप में चिह्नित किया जाता है?
- "सर्वाधिक ईमेल" सूची बनाना: इस पृष्ठ को देखने वाले कितने प्रतिशत लोग "ईमेल" पर क्लिक करेंगे?