यदि आप लंबे समय से मल्टीथ्रेडेड एप्लिकेशन विकसित कर रहे हैं, तो आपको मौजूदा अनुक्रमिक कोड को समानांतर करने का सामना करना पड़ा होगा। या इसके विपरीत, आप समानांतर प्रोग्रामिंग के लिए नए हैं, और आपको परियोजना का अनुकूलन करने और स्केलेबिलिटी में सुधार करने के कार्य का सामना करना पड़ता है, जिसे कार्यक्रम के अलग-अलग वर्गों को समानांतर करके भी हल किया जा सकता है।
नया इंटेल एडवाइजर XE टूल आपको एप्लिकेशन को समानांतर करने में मदद करेगा, इस पर न्यूनतम प्रयास और समय खर्च करेगा।
सलाहकार XE को इस साल सितंबर में
Intel Parallel Studio XE 2013 के डेवलपर्स के पैकेज के हिस्से के रूप में जारी किया गया था। नाम का शाब्दिक अनुवाद - "सलाहकार" - काफी संक्षेप में इसके उद्देश्य का वर्णन करता है। उपकरण प्रोग्रामर को कोड को समानांतर बनाने की संभावनाओं का विश्लेषण करने में मदद करता है: इसके लिए सबसे उपयुक्त अनुभाग ढूंढें और अपेक्षित लाभकारी प्रभाव का मूल्यांकन करें - क्या यह बिल्कुल लेने के लायक है? इसके अलावा, सलाहकार एक्सई आपको बताएगा कि डेटा की दौड़ जैसे त्रुटियां कहां हो सकती हैं। और यह सब कार्यक्रम के एक वास्तविक संशोधन के बिना! लेकिन पहले बातें पहले।
सलाहकार XE विंडोज * और लिनक्स * के लिए उपलब्ध है और C ++, C #, और फोरट्रान के साथ काम करता है। इस पोस्ट में मैं विंडोज * के लिए संस्करण का उपयोग करूंगा - इसमें Microsoft Visual Studio * में सुविधाजनक एकीकरण है (जो लोग चाहते हैं कि एकीकरण के बिना एक कस्टम इंटरफ़ेस भी है)। एक उदाहरण के रूप में, मैंने टैचियन कार्यक्रम लिया, जो सलाहकार एक्सई नमूना सेट का हिस्सा है। यह 2D चित्रण और किरण अनुरेखण करता है, जो निम्न चित्र का निर्माण करता है:

विजुअल स्टूडियो एडवाइजर में XE अपना खुद का टूलबार जोड़ता है, जो अपने कार्यों के लिए त्वरित पहुँच प्रदान करता है। इसलिए, अपना प्रोजेक्ट खोलें, इसे रिलीज़ मोड में बनाएँ और "सलाहकार XE वर्कफ़्लो" खोलें:

सलाहकार XE वर्कफ़्लो एप्लिकेशन के मूल्यांकन के पांच चरणों के माध्यम से डेवलपर को निर्देशित करता है, जिसके बाद वह एक सूचित निर्णय ले सकेगा कि क्या इस कोड को समानांतर करना है और किस स्थान पर यह करना बेहतर है।
चरण 1. रूपरेखा (सर्वेक्षण लक्ष्य)
पहली चीज जो सलाहकार एक्सई करता है, वह आपके एप्लिकेशन को लॉन्च करता है और इसे प्रोफाइल करता है, अर्थात। "हॉट स्पॉट" के लिए प्रदर्शन और खोजों का मूल्यांकन करता है - फ़ंक्शन, लूप और व्यक्तिगत निर्देश जो प्रोसेसर के अधिकांश संसाधनों का उपभोग करते हैं। उत्पादकता के लिए सबसे महत्वपूर्ण क्षेत्रों पर प्रयासों को केंद्रित करने के लिए यह आवश्यक है, क्योंकि उनका समानांतर सबसे बड़ा प्रभाव लाएगा। प्रोफाइलिंग शुरू करने के लिए, एडवाइजर XE वर्कफ़्लो विंडो में "कलेक्ट सर्वे डेटा" बटन पर क्लिक करें:

सलाहकार XE ने एप्लिकेशन लॉन्च किया, काम की समाप्ति की प्रतीक्षा कर रहा है, और एकत्रित डेटा को "अंतिम रूप देता है"। उसके बाद, उपयोगकर्ता को एक पदानुक्रमित रूप में कोड में फ़ंक्शन और स्थानों की सूची के साथ प्रस्तुत किया जाता है, जिनमें से प्रत्येक के लिए सीपीयू समय सेकंड और प्रतिशत में प्रदर्शित होता है। अलग से दिखाया गया है एक फ़ंक्शन का आंतरिक समय और नेस्टेड फ़ंक्शन सहित समय:

वे स्थान जहां "हॉट स्पॉट" एक चक्र है, एक विशेष आइकन के साथ चिह्नित हैं। यह सुविधाजनक है क्योंकि लूप अक्सर समानांतरकरण का उद्देश्य बन जाते हैं यदि, उदाहरण के लिए, वे स्वतंत्र डेटा के बड़े संस्करणों को संसाधित करते हैं।
ये प्रोफाइलिंग प्रोग्रामर को एप्लिकेशन के भीतर लोड वितरण का पहला अनुमान देते हैं। यह आपको एक सार्थक बनाने की अनुमति देता है, जो संख्या के आधार पर अनुमान लगाता है कि कोड के कौन से सेक्शन समानांतर बनाने के लिए उपयोगी होंगे।
हमारे उदाहरण में, हम शीर्ष-सबसे कॉल स्टैक फ़ंक्शन पर चयन रोक देंगे जिसमें लूप शामिल है - समानांतर_थ्रेड। बिताए प्रोसेसर समय के 80.9% के लिए इसमें (एम्बेडेड फ़ंक्शन सहित) खाते हैं। वैसे, "हॉट" फ़ंक्शन पर एक डबल क्लिक आपको स्रोत को देखने के लिए ले जाएगा, जहां सीपीयू के उपयोग के बारे में भी जानकारी होगी, लेकिन कोड की विशिष्ट लाइनों के लिए।
स्टेज 2. एनोटेशन (एनोटेट सोर्स)
जब मल्टीथ्रेडिंग के भविष्य के कार्यान्वयन के बारे में पहली धारणा बनती है, तो आपको इस बारे में "सलाहकार" को सूचित करने की आवश्यकता है। इसके लिए, तथाकथित एनोटेशन का उपयोग किया जाता है - विशेष मैक्रोज़ (या भाषा के आधार पर फ़ंक्शन कॉल), जो सलाहकार समझता है, लेकिन आपके प्रोग्राम के कामकाज को प्रभावित नहीं करता है।
विज़ुअल स्टूडियो में, संदर्भ मेनू का उपयोग करके एनोटेशन जोड़े जाते हैं - बस आपको पसंद किए गए कोड के ब्लॉक का चयन करें और एनोटेशन विज़ार्ड लॉन्च करें:

सलाहकार XE एनोटेशन कई प्रकार के होते हैं। पाश के समानांतर मॉडलिंग के लिए, दो मुख्य हमारे लिए उपयोगी होंगे - "एनोटेट साइट" और "एनोटेट टास्क"।
एनोटेट साइट का उपयोग कोड में एक समानांतर क्षेत्र की सीमाओं को चिह्नित करने के लिए किया जाता है। C ++ के लिए, यह ANNOTATE_SITE_BEGIN और ANNOTATE_SITE_END मैक्रोज़ द्वारा दर्शाया गया है। हमारे उदाहरण में, हम लूप के लिए समानांतर करेंगे, पुनरावृत्ति स्थान को छोटे भागों में तोड़ देंगे, ताकि प्रत्येक ऐसे हिस्से को दूसरों के साथ समानांतर में निष्पादित किया जा सके।
"एनोटेट टास्क" का उपयोग मैक्रो ANNOTATE_TASK_BEGIN और ANNOTATE_TASK_END का उपयोग करके किसी एक कार्य की सीमाओं को चिह्नित करने के लिए किया जाता है। एक कार्य कोड का एक ब्लॉक है जिसे विभिन्न थ्रेड्स द्वारा कई बार निष्पादित किया जा सकता है। कार्यों को अन्य कार्यों के साथ समानांतर में और बाकी कोड समानांतर क्षेत्र में निष्पादित किए जाते हैं।
तो, हम मार्कअप शुरू करते हैं। हम एक समानांतर क्षेत्र में लूप के लिए संपूर्ण संलग्न करते हैं। और चक्र का शरीर एक कार्य के रूप में नामित है, क्योंकि इसे अलग-अलग पुनरावृत्तियों पर समानांतर (मॉडल में) निष्पादित किया जाएगा:
#include <advisor-annotate.h> ... static void parallel_thread (void) { ANNOTATE_SITE_BEGIN(allRows); for (int y = starty; y < stopy; y++) { ANNOTATE_TASK_BEGIN(eachRow); m_storage.serial = 1; m_storage.mboxsize = sizeof(unsigned int)*(max_objectid() + 20); m_storage.local_mbox = (unsigned int *) malloc(m_storage.mboxsize); memset(m_storage.local_mbox,0,m_storage.mboxsize); drawing_area drawing(startx, totaly-y, stopx-startx, 1); for (int x = startx; x < stopx; x++) { color_t c = render_one_pixel (x, y, m_storage.local_mbox, m_storage.serial, startx, stopx, starty, stopy); drawing.put_pixel(c); } if(!video->next_frame()) { free(m_storage.local_mbox); return; } free(m_storage.local_mbox); ANNOTATE_TASK_END(eachRow); } ANNOTATE_SITE_END(allRows); }
एन ++ के संकलन के लिए सी ++ प्रोग्राम के लिए, आपको हेडर फ़ाइल सलाहकार-एनोटेट.एच को शामिल करना होगा।
चरण 3. उपयुक्तता की जांच करें
तीसरे चरण में, सलाहकार एक्सई ने फिर से प्रोफाइलिंग की। पहले प्रोफाइलिंग से अंतर यह है कि अब यह "हॉट फ़ंक्शंस" के बारे में जानकारी नहीं है जिसे एकत्र किया जा रहा है, लेकिन एप्लिकेशन के समानांतर निष्पादन को मॉडलिंग किया जाता है और इसकी संभावित गति का मूल्यांकन किया जाता है।
कार्यक्रम को एनोटेशन के बिना उसी तरह निष्पादित किया जाता है - एकल-थ्रेडेड मोड में। काम की गति और परिणामों की शुद्धता को नुकसान नहीं होता है। हालाँकि, एनोटेशन उपकरण को एनोटेट कोड के बहुस्तरीय निष्पादन का अनुकरण करने में सक्षम बनाता है और एक प्रोग्रामर के न्यायालय को संख्या में एक प्रदर्शन अनुमान जारी करता है:

एक प्रभावशीलता मूल्यांकन (या उपयुक्तता विश्लेषण) का परिणाम हमें बहुत सारी रोचक जानकारी देता है:
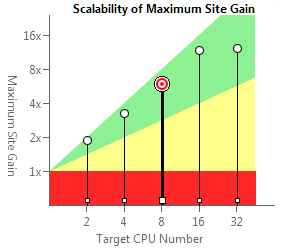
- अनुक्रमिक निष्पादन की तुलना में पूरे कार्यक्रम का त्वरण (हमारे उदाहरण में, 1.48x)
- एक अलग समानांतर क्षेत्र का त्वरण (8 कोर पर 7.88 के उदाहरण में)
- 2-32 प्रोसेसर कोर के लिए स्केलेबिलिटी रेटिंग
- समानांतर क्षेत्रों और कार्यों (निष्पादन समय, कार्यों की संख्या, आदि) के बारे में विवरण
यह जानकारी संबंधित ध्वज को स्विच करके कोर की एक अलग संख्या के लिए प्राप्त की जा सकती है। यानी यहां तक कि एक दोहरे कोर लैपटॉप पर काम करते हुए, आप सराहना कर सकते हैं कि प्रोग्राम मल्टी-कोर सर्वर पर कैसे स्केल करेगा।
निष्पक्षता में, मुझे यह कहना होगा कि परिणाम हमेशा इतने रसीले नहीं होंगे। यह पता चल सकता है कि समानांतरकरण का अनुमानित सकारात्मक प्रभाव इतना अधिक या शून्य बिल्कुल भी नहीं है। लेकिन यह परिणाम भी उपयोगी होगा, क्योंकि आप चुने हुए दृष्टिकोण की अक्षमता के बारे में आश्वस्त होंगे, और अन्य तरीकों की तलाश करेंगे। यह सलाहकार एक्सई का उद्देश्य है - आपको समानांतर में कई दृष्टिकोणों का प्रयास करने, न्यूनतम प्रयास और समय बिताने, और सर्वश्रेष्ठ चुनने का अवसर प्रदान करना है।
ऐसा हो सकता है कि सभी आजमाए गए दृष्टिकोण स्वीकार्य परिणाम न दें। यह आपको कोड की संरचना को बदलने का विचार दे सकता है ताकि इसे समानांतर करना आसान हो। सलाहकार एक्सई निश्चित रूप से इस विषय पर व्यापक परामर्श प्रदान नहीं करेगा, लेकिन आपको युक्तियों की सूची पर ध्यान देना चाहिए - शायद कुछ जानकारी आपको सही विचारों तक ले जाएगी।
चरण 4. सुधार की जाँच करें
एकल-थ्रेडेड प्रोग्राम को बहु-थ्रेडेड प्रोग्राम में बदलने से नए बग हो सकते हैं - जैसे डेटा रेस। "लाइव" प्रोग्राम में सत्यापन और डिबगिंग की सुविधा के लिए, सलाहकार एक्सई आपको प्रोग्रामर द्वारा सिम्युलेटेड समाधान की शुद्धता का मूल्यांकन करने की अनुमति देता है। ऐसा करने के लिए, प्रोग्राम को "डीबग" मोड में फिर से जोड़ें और सलाहकार एक्सई "चेक करेक्शन" चेक चलाएं।
सत्यापन कार्यक्रम के निष्पादन को धीमा कर देगा, क्योंकि निष्पादन योग्य फ़ाइल द्विआधारी इंस्ट्रूमेंटेशन से गुजरती है, जो सलाहकार एक्सई को त्रुटियों के लिए कार्यक्रम को ट्रैक करने में मदद करती है। इसलिए, एप्लिकेशन पर लोड को कम करने के लिए यह समझ में आता है, यदि संभव हो तो, इनपुट डेटा के आकार को कम करें, फ़्रेम को अपडेट करने की आवृत्ति कम करें आदि।

सत्यापन के परिणामस्वरूप, एक सुधार रिपोर्ट दिखाई देती है - एक त्रुटि रिपोर्ट। इसमें त्रुटियों की सूची, उनका प्रकार, एक समानांतर क्षेत्र जिसमें वे दिखाई देते हैं, शामिल हैं। त्रुटि पर डबल-क्लिक करके, आप स्रोत को देखने के लिए आगे बढ़ सकते हैं, जहां अतिरिक्त जानकारी दिखाई देती है, उदाहरण के लिए, कॉल स्टैक:

हमारे उदाहरण में, एक डेटा रेस की खोज की गई थी - फ़ंक्शन वीडियो में :: अगली_फ्रेम (), वैश्विक चर g_updates में वृद्धि हुई है। हालांकि यह कार्यक्रम के निष्पादन को प्रभावित नहीं करता है, वास्तव में कोड अभी भी एकल-थ्रेडेड है। हालांकि, यह स्पष्ट है कि समस्या को ठीक करने की आवश्यकता होगी, और इससे प्रदर्शन प्रभावित होगा - सिंक्रनाइज़ेशन ऑब्जेक्ट दिखाई दे सकते हैं जो स्केलेबिलिटी को बाधित करते हैं, या इसके विपरीत, चर के स्थानीयकरण का सकारात्मक प्रभाव पड़ेगा।
इसे जांचने के लिए, सलाहकार एक्सई के पास एक अन्य प्रकार का एनोटेशन है - "लॉक एनोटेशन"। उनका उपयोग महत्वपूर्ण वर्गों को अनुकरण करने के लिए किया जाता है। हमारे उदाहरण में, g_updates को वीडियो :: अगले_फ्रेम () फ़ंक्शन में संशोधित किया गया है, जिसे हमारे समानांतर लूप में कहा जाता है। इसलिए, हम इसे सिंक्रनाइज़ेशन एनोटेशन के साथ सुरक्षित कर सकते हैं:
static void parallel_thread (void) { ANNOTATE_SITE_BEGIN(allRows); for (int y = starty; y < stopy; y++) { ANNOTATE_TASK_BEGIN(eachRow); m_storage.serial = 1; m_storage.mboxsize = sizeof(unsigned int)*(max_objectid() + 20); m_storage.local_mbox = (unsigned int *) malloc(m_storage.mboxsize); memset(m_storage.local_mbox,0,m_storage.mboxsize); drawing_area drawing(startx, totaly-y, stopx-startx, 1); for (int x = startx; x < stopx; x++) { color_t c = render_one_pixel (x, y, m_storage.local_mbox, m_storage.serial, startx, stopx, starty, stopy); drawing.put_pixel(c); } ANNOTATE_LOCK_ACQUIRE(0); if(!video->next_frame()) { ANNOTATE_LOCK_RELEASE(0); free(m_storage.local_mbox); return; } ANNOTATE_LOCK_RELEASE(0); free(m_storage.local_mbox); ANNOTATE_TASK_END(eachRow); } ANNOTATE_SITE_END(allRows); }
किए गए परिवर्तनों के बाद, हम कार्यक्रम का पुनर्निर्माण करते हैं और फिर से जांचते हैं। आप शुद्धता की जांच कर सकते हैं - क्या समस्या हल हो गई है, और प्रदर्शन के लिए - एक महत्वपूर्ण खंड की उपस्थिति को ध्यान में रखते हुए, समानांतरकरण का क्या प्रभाव पड़ेगा। हमारे उदाहरण में, एक महत्वपूर्ण अनुभाग की शुरूआत का प्रदर्शन पर लगभग कोई प्रभाव नहीं पड़ा।
स्टेज 5. समानांतरकरण का कार्यान्वयन (समानांतर फ्रेमवर्क जोड़ें)
कोड समानांतरकरण का अंतिम चरण वास्तव में समानांतरकरण है, अर्थात। स्ट्रीमिंग एपीआई, प्रत्यक्ष कोडिंग और डिबगिंग का विकल्प। यह चरण केवल सशर्त XE के "वर्कफ़्लो" में सशर्त रूप से शामिल है, ताकि भूल न जाए, इसलिए बोलने के लिए। "सलाहकार" केवल मॉडलिंग के लिए और डेवलपर को विश्लेषणात्मक जानकारी प्रदान करने के लिए अभिप्रेत है, जिसके आधार पर उसे यह स्पष्ट विचार होगा कि आगे कहाँ जाना है - क्या और कैसे संशोधित किया जाए, क्या प्रभाव की उम्मीद की जाए और क्या समस्याएं उत्पन्न हो सकती हैं। आपको खुद पर कार्रवाई करनी होगी।
लेकिन निराश मत हो - इंटेल समानांतर स्टूडियो एक्सई पैकेज में कई और उपकरण हैं जो अन्य चरणों में मदद करेंगे। आप कई उच्च-स्तरीय "समानांतर फ्रेमवर्क" की मदद से उपरोक्त उदाहरण में मॉडल के अनुसार एक समानांतर चक्र को लागू कर सकते हैं जो आपको थ्रेड्स के स्वतंत्र निर्माण और उनके बीच लोड के वितरण से सार करने की अनुमति देता है। उदाहरण के लिए, आप Intel Cilk Plus का उपयोग करके एक सीरियल चक्र को समानांतर में बदल सकते हैं। आपको इंटेल कंपाइलर का उपयोग करने की आवश्यकता होगी। और सिंक्रनाइज़ेशन आदिम के रूप में, आप इंटेल टीबीबी लाइब्रेरी से tbb :: spin_mutex ले सकते हैं। लूप का कोड (पहले से समानांतर) इस तरह दिखेगा:
static void parallel_thread (void) { volatile bool continue_work = true; cilk_for (int y = starty; y < stopy; y++) { if (continue_work) { storage m_storage; m_storage.serial = 1; m_storage.mboxsize = sizeof(unsigned int)*(max_objectid() + 20); m_storage.local_mbox = (unsigned int *) malloc(m_storage.mboxsize); memset(m_storage.local_mbox,0,m_storage.mboxsize); drawing_area drawing(startx, totaly-y, stopx-startx, 1); for (int x = startx; x < stopx; x++) { color_t c = render_one_pixel (x, y, m_storage.local_mbox, m_storage.serial, startx, stopx, starty, stopy); drawing.put_pixel(c); } { tbb::spin_mutex::scoped_lock lockUntilScopeExit(MyMutex); if(!video->next_frame()) { continue_work = false; } } free (m_storage.local_mbox); } } }
निष्कर्ष
सलाहकार एक्सई उपयोगी होगा जहां पहले से ही काम करने वाला कोड है जिसे आंशिक रूप से समानांतर करने की आवश्यकता है। उदाहरण के लिए, फोरट्रान पर एक पुराना वैज्ञानिक अनुप्रयोग है जिसे एक नए सर्वर या क्लस्टर के लिए अनुकूलित करने की आवश्यकता है। उपकरण का मुख्य लाभ बहु-थ्रेडेड निष्पादन को जल्दी से अनुकरण करने की क्षमता है। कई प्रयोगों का संचालन करने के बाद, आप कोड के उन क्षेत्रों को निर्धारित कर सकते हैं जिन पर प्रयासों को केंद्रित करना है, और यह समझना है कि इससे क्या उम्मीद की जाए - कैसे समानांतर उपयोग उपयोगी हो सकता है, क्या स्केलेबिलिटी हासिल की जा सकती है। धागे बनाकर और कोड को फिर से तैयार करके "असली के लिए" एक ही काम करना बहुत अधिक प्रयास करेगा।
आप उत्पाद वेबसाइट से Intel सलाहकार XE का परीक्षण संस्करण डाउनलोड कर सकते हैं:
http://software.intel.com/en-us/intel-advisor-xe ।
इंटेल समानांतर स्टूडियो XE 2013:
http://software.intel.com/en-us/intel-parallel-studio-xe/इंटेल Cilk प्लस
http://software.intel.com/en-us/intel-cilk-plus-archiveइंटेल थ्रेडिंग बिल्डिंग ब्लॉक
http://software.intel.com/en-us/intel-tbbhttp://threadingbuildingblocks.org/