
इस विषय में, मैं बात करना चाहता हूं कि
कैसेसेंड्रा की व्यवस्था कैसे
की जाती है - एक विकेन्द्रीकृत, दोष-सहिष्णु और विश्वसनीय कुंजी-मूल्य डेटाबेस। स्टोरेज ही
विफलता के एक बिंदु , सर्वर की विफलता और
क्लस्टर नोड्स के बीच डेटा के वितरण की समस्याओं का ध्यान रखेगा। इसके अलावा, दोनों को एक
डेटा सेंटर (
डेटा सेंटर ) में सर्वर रखने के मामले में, और कई डेटा केंद्रों के साथ कॉन्फ़िगरेशन में, दूरी से अलग किया जाता है और, तदनुसार, नेटवर्क देरी करता है। विश्वसनीयता प्रत्येक अनुरोध
की धुन संगतता सेट करने की क्षमता के साथ डेटा की
अंतिम स्थिरता को संदर्भित करता है।
NoSQL डेटाबेस को
SQL की तुलना में उनकी आंतरिक संरचना की आम तौर पर अधिक समझ की आवश्यकता होती है। यह आलेख मूल संरचना का वर्णन करेगा, और निम्नलिखित लेखों में यह विचार करना संभव होगा: सीक्यूएल और प्रोग्रामिंग इंटरफ़ेस; डिजाइन और अनुकूलन तकनीक; कई डेटा केंद्रों में स्थित समूहों की विशेषताएं।
डेटा मॉडल
कैसेंड्रा की शब्दावली में, एक अनुप्रयोग एक
कुंजी क्षेत्र के साथ काम करता
है , जो एक संबंधपरक मॉडल में
डेटाबेस स्कीमा की अवधारणा
से मेल खाता है। इस प्रमुख स्थान में कई
स्तंभ परिवार हो सकते हैं, जो एक संबंधपरक तालिका की अवधारणा से मेल खाता है। बदले में, कॉलम परिवारों में
कॉलम (
स्तंभ ) होते
हैं , जो
रिकॉर्ड (
पंक्ति ) में
कुंजी (
पंक्ति कुंजी ) का उपयोग करके संयुक्त होते हैं। एक कॉलम में तीन भाग होते हैं:
नाम (
कॉलम नाम ),
टाइमस्टैम्प (
टाइमस्टैम्प ) और
मूल्य (
वैल्यू )। रिकॉर्ड के भीतर कॉलम का आदेश दिया गया है। एक रिलेशनल डेटाबेस के विपरीत, इस तथ्य पर कोई प्रतिबंध नहीं है कि रिकॉर्ड (और एक डेटाबेस के संदर्भ में ये पंक्तियाँ हैं) में अन्य नामों के समान कॉलम हैं - नहीं। कॉलम परिवार कई प्रकार के हो सकते हैं, लेकिन इस लेख में हम इस विवरण को छोड़ देंगे। साथ ही,
कैसेंड्रा के नवीनतम संस्करणों में,
CQL भाषा का उपयोग करके
डेटा परिभाषा और परिवर्तन अनुरोध (
DDL ,
DML ) को निष्पादित
करना संभव हो गया, साथ ही साथ
माध्यमिक सूचकांक भी बनाए गए।
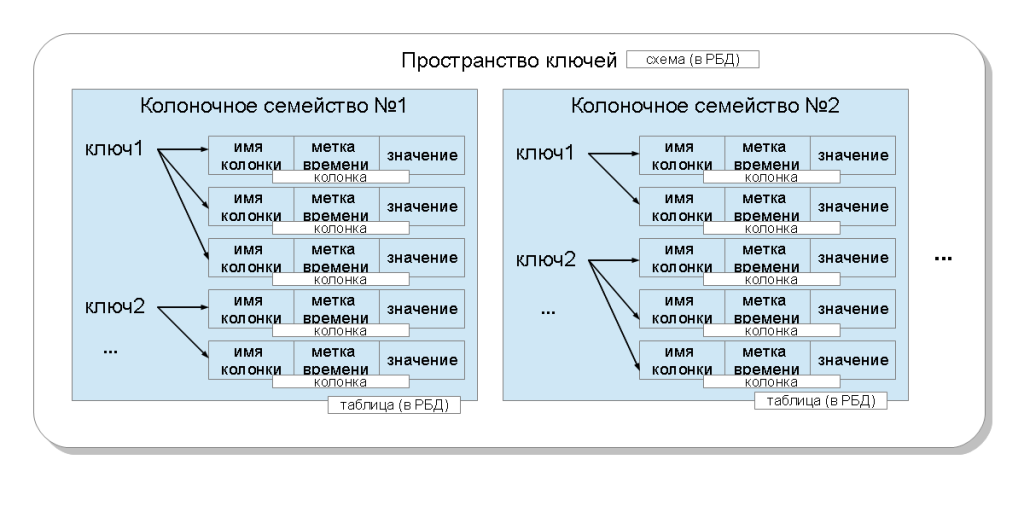
कैसेंड्रा में संग्रहीत विशिष्ट मूल्य की पहचान की जाती है:
- कीस्पेस एक एप्लीकेशन (डोमेन) के लिए एक बाइंडिंग है। एक क्लस्टर पर विभिन्न अनुप्रयोगों के डेटा को रखने की अनुमति देता है;
- स्तंभ परिवार - यह अनुरोध के लिए एक बाध्यकारी है;
- कुंजी क्लस्टर नोड के लिए बाध्यकारी है। यह उस कुंजी पर निर्भर करता है जो सहेजे गए कॉलम को नोड करती है;
- स्तंभ नाम रिकॉर्ड में विशेषता के लिए बाध्यकारी है। एक रिकॉर्ड में कई मूल्यों को संग्रहीत करने की अनुमति देता है।
प्रत्येक मान एक समय टिकट के साथ जुड़ा हुआ है - एक उपयोगकर्ता-परिभाषित संख्या जिसका उपयोग रिकॉर्डिंग के दौरान संघर्ष को हल करने के लिए किया जाता है: बड़ी संख्या, नया स्तंभ और तुलना करते समय, यह पुराने स्तंभों को पीस देगा।
डेटा प्रकार द्वारा: कुंजी स्थान और स्तंभ परिवार तार (नाम) हैं; टाइमस्टैम्प 64-बिट संख्या है; और कुंजी, स्तंभ नाम और स्तंभ मान बाइट्स की एक सरणी है। कैसेंड्रा
में डेटा प्रकारों की अवधारणा भी है। स्तंभ परिवार बनाते समय डेवलपर द्वारा इन प्रकारों को वैकल्पिक रूप से निर्दिष्ट किया जा सकता है। स्तंभ नामों के लिए, इसे एक
तुलनित्र कहा जाता है, मूल्यों और कुंजियों के लिए, इसे एक
सत्यापनकर्ता कहा जाता है। पहला निर्धारित करता है कि कॉलम नामों के लिए बाइट मान क्या मान्य हैं और उन्हें कैसे व्यवस्थित किया जाए। दूसरा वह है जो बाइट मान स्तंभ और प्रमुख मानों के लिए मान्य है। यदि ये डेटा प्रकार निर्दिष्ट नहीं हैं, तो
कैसेंड्रा मूल्यों को संग्रहीत करता है और उनकी तुलना
बाइट स्ट्रिंग्स (
बाइट्स टाइप ) के रूप में करता है, वास्तव में, वे आंतरिक रूप से संग्रहीत होते हैं।
डेटा प्रकार इस प्रकार हैं:
- बाइट टाइप: कोई बाइट स्ट्रिंग्स (सत्यापन के बिना)
- AsciiType: ASCII स्ट्रिंग
- UTF8Type: UTF-8 स्ट्रिंग
- IntegerType: मनमाने आकार की संख्या
- Int32Type: 4-बाइट संख्या
- LongType: 8 बाइट संख्या
- UUIDType: 1 या 4 प्रकार के UUID
- TimeUUIDType: टाइप 1 UUID
- दिनांक प्रकार: 8-बाइट टाइमस्टैम्प मान
- बूलियन टाइप: दो मान: सत्य = १ या असत्य = ०
- फ्लोट टाइप: 4-बाइट फ्लोटिंग पॉइंट नंबर
- DoubleType: 8-बाइट फ़्लोटिंग पॉइंट नंबर
- DecimalType: मनमाना आकार और फ्लोटिंग पॉइंट नंबर
- काउंटरकॉलमंटाइप: 8-बाइट काउंटर
कैसेंड्रा में, सभी डेटा राइटिंग ऑपरेशन हमेशा पुनर्लेखन ऑपरेशन होते हैं, अर्थात, यदि एक ही कुंजी और नाम वाला कॉलम पहले से मौजूद है और एक टाइमस्टैम्प स्तंभ परिवार में सहेजे गए से अधिक है, तो मान ओवरराइट किया जाता है। दर्ज किए गए मान कभी नहीं बदलते हैं, नए मूल्यों के साथ बस नए कॉलम आते हैं।
कैसेंड्रा के लिए लेखन पढ़ने की तुलना में तेजी से काम करता है। यह डिजाइन में उपयोग किए जाने वाले दृष्टिकोण को बदल देता है। यदि हम डेटा मॉडल को डिज़ाइन करने के दृष्टिकोण से कैसंड्रा पर विचार करते हैं, तो स्तंभ परिवार की तालिका के रूप में नहीं, बल्कि
भौतिक दृष्टिकोण के रूप में कल्पना करना आसान है - एक संरचना जो कुछ जटिल क्वेरी के डेटा का प्रतिनिधित्व करती है, लेकिन इसे डिस्क पर संग्रहीत करती है। किसी तरह से प्रश्नों की मदद से डेटा की रचना करने की कोशिश करने के बजाय, अंतिम परिवार में इस क्वेरी के लिए आवश्यक हर चीज को बचाने की कोशिश करना बेहतर है। यही है, संस्थाओं या वस्तुओं के बीच संबंधों के बीच संबंधों के पक्ष से नहीं, बल्कि प्रश्नों के पक्ष से दृष्टिकोण करना आवश्यक है: किन क्षेत्रों को चुनना आवश्यक है; रिकॉर्ड किस क्रम में जाना चाहिए; मुख्य से संबंधित क्या डेटा संयुक्त रूप से अनुरोध किया जाना चाहिए - यह सब पहले से ही कॉलम परिवार में संग्रहीत किया जाना चाहिए। एक रिकॉर्ड में स्तंभों की संख्या सैद्धांतिक रूप से 2 बिलियन तक सीमित है। यह एक संक्षिप्त विषयांतर है, और अधिक विवरण में, डिजाइन और अनुकूलन तकनीकों पर एक लेख में। और अब डेटा को कैसेंड्रा में सहेजने और उसे पढ़ने की प्रक्रिया में तल्लीन करते हैं।
डेटा वितरण
क्लस्टर नोड्स के बीच कुंजी के आधार पर डेटा कैसे वितरित किया जाता है, इस पर विचार करें। कैसंड्रा आपको डेटा वितरण रणनीति को परिभाषित करने की अनुमति देता है। पहली ऐसी रणनीति md5 कुंजी मूल्य के आधार पर डेटा वितरित करती है - एक
यादृच्छिक पार्टीशनर (
यादृच्छिक विभाजन )। दूसरा स्वयं कुंजी के बिट प्रतिनिधित्व को ध्यान में रखता है - एक
ऑर्डिनल मार्कअप (
बाइट-ऑर्डर किए गए विभाजनकर्ता )। अधिकांश भाग के लिए पहली रणनीति, अधिक लाभ देती है, क्योंकि आपको सर्वर और समान समस्याओं के बीच डेटा के समान वितरण के बारे में चिंता करने की आवश्यकता नहीं है। दूसरी रणनीति का उपयोग दुर्लभ मामलों में किया जाता है, उदाहरण के लिए यदि
रेंज स्कैन की आवश्यकता होती है। यह ध्यान रखना महत्वपूर्ण है कि क्लस्टर बनाने से पहले इस रणनीति का चुनाव किया जाता है और वास्तव में, पूर्ण डेटा पुनः लोड किए बिना नहीं बदला जा सकता है।
Cassander डेटा वितरित करने के लिए
सुसंगत हैशिंग के रूप
में ज्ञात एक तकनीक का उपयोग करता है। यह दृष्टिकोण आपको नोड्स के बीच डेटा वितरित करने और इसे बनाने की अनुमति देता है ताकि एक नया नोड जोड़ते और निकालते समय, भेजे गए डेटा की मात्रा कम हो। ऐसा करने के लिए, प्रत्येक नोड को एक
लेबल (
टोकन ) सौंपा गया है, जो सभी md5 कुंजी मानों के सेट को टुकड़ों में तोड़ता है। चूंकि ज्यादातर मामलों में रैंडमपार्टिशनर का उपयोग किया जाता है, इस पर विचार करें। जैसा कि मैंने कहा, रैंडमपार्टिशनर प्रत्येक कुंजी के लिए 128-बिट md5 की गणना करता है। यह निर्धारित करने के लिए कि कौन सा नोड डेटा में संग्रहीत किया जाएगा, नोड्स के सभी लेबल को सबसे छोटे से सबसे बड़े तक सॉर्ट किया जाता है, और जब लेबल मान कुंजी के md5 मान से बड़ा हो जाता है, तो यह नोड कई बाद के नोड्स (लेबल के क्रम में) को भंडारण के लिए चुना जाता है। चयनित नोड्स की कुल संख्या
प्रतिकृति कारक के बराबर होनी चाहिए। प्रतिकृति स्तर प्रत्येक प्रमुख स्थान के लिए सेट किया गया है और आपको
डेटा अतिरेक को समायोजित करने की अनुमति देता है।
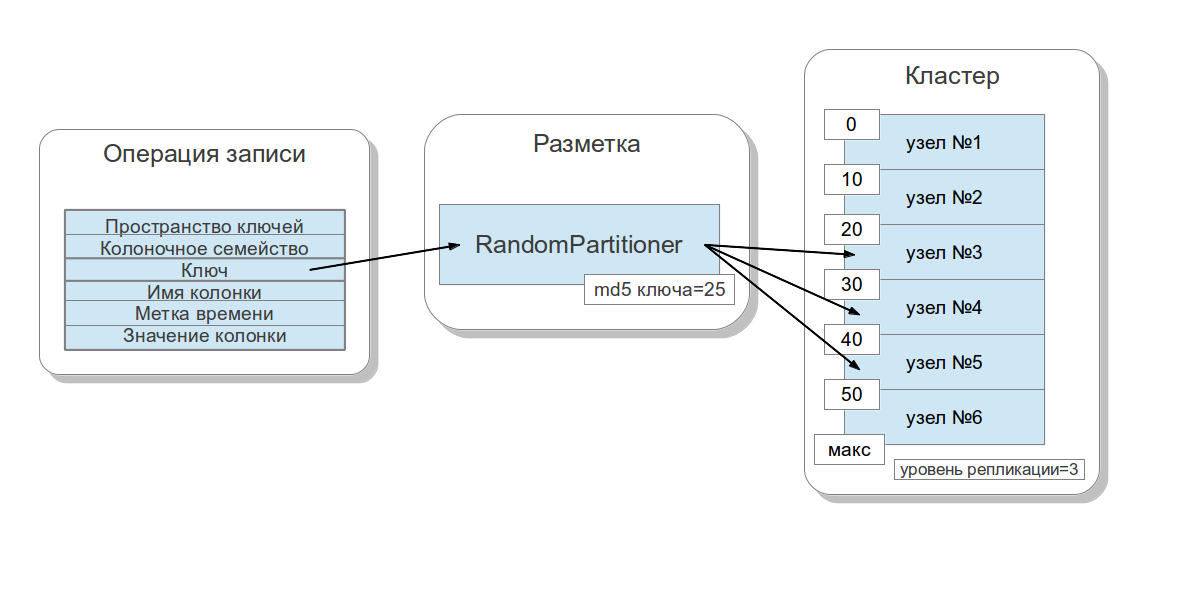
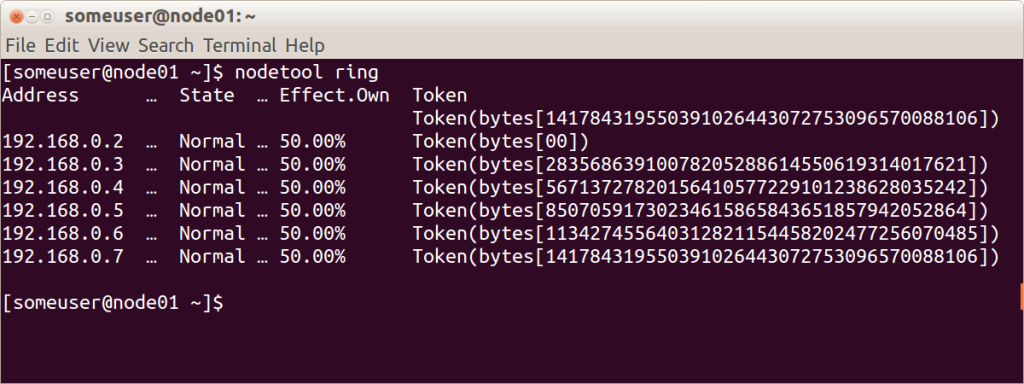
इससे पहले कि आप क्लस्टर में एक नोड जोड़ें, आपको इसके लिए एक लेबल सेट करना होगा। इस लेबल और अगले के बीच की खाई को कवर करने वाली कुंजियों का प्रतिशत नोड पर कितना डेटा संग्रहीत किया जाएगा, इस पर निर्भर करता है। एक क्लस्टर के लिए लेबल के पूरे सेट को
रिंग कहा जाता
है ।
यहाँ एक उदाहरण दिखाया गया है
जिसमें नोडोड उपयोगिता का उपयोग करके समान रूप से वितरित लेबल के साथ 6 नोड्स का एक क्लस्टर रिंग है।
डेटा संगति
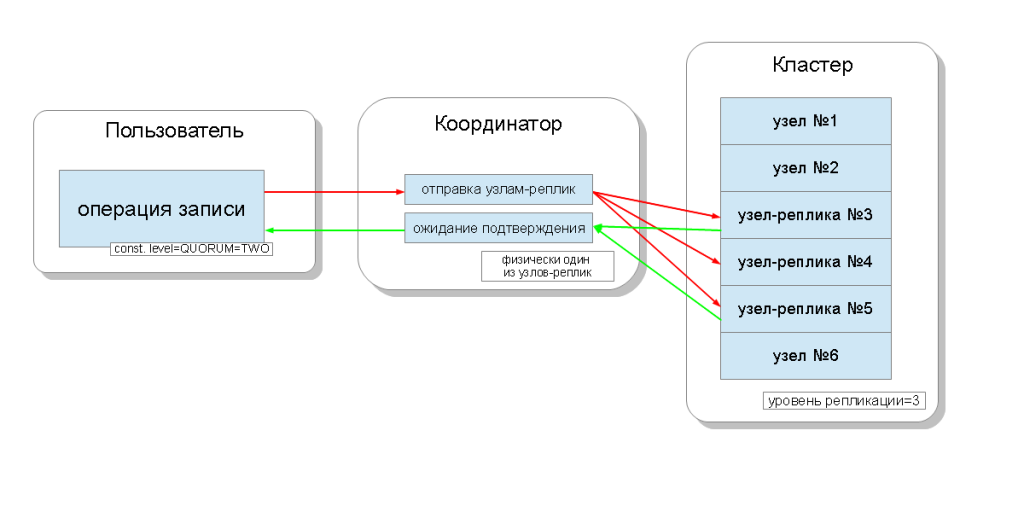
कैसंड्रा क्लस्टर के नोड्स बराबर हैं, और क्लाइंट उनमें से किसी से भी जुड़ सकते हैं, दोनों लिखने और पढ़ने के लिए। अनुरोध समन्वय चरण से गुजरते हैं, जिसके दौरान, एक कुंजी और एक मुंशी की मदद से पता लगाया जाता है कि डेटा किस नोड पर स्थित होना चाहिए, सर्वर इन नोड्स के लिए अनुरोध भेजता है। हम उस नोड को कॉल करेंगे जो समन्वयक समन्वय करता है, और इस कुंजी के साथ रिकॉर्ड को बचाने के लिए चुने गए
नोड्स प्रतिकृति नोड हैं । शारीरिक रूप से, प्रतिकृति नोड्स में से एक समन्वयक हो सकता है - यह केवल कुंजी, मार्कअप और लेबल पर निर्भर करता है।
प्रत्येक अनुरोध के लिए, पढ़ना और लिखना दोनों, डेटा स्थिरता का स्तर निर्धारित करना संभव है।
रिकॉर्डिंग के लिए, यह स्तर प्रतिकृति नोड्स की संख्या को प्रभावित करेगा जिससे उपयोगकर्ता पर नियंत्रण वापस करने से पहले एक सफल संचालन की पुष्टि की जाएगी (डेटा रिकॉर्ड किया गया है)। रिकॉर्डिंग के लिए, इस तरह के स्तर हैं:
- एक - समन्वयक सभी प्रतिकृति नोड्स के लिए अनुरोध भेजता है, लेकिन, पहले नोड से पुष्टि के इंतजार के बाद, उपयोगकर्ता को नियंत्रण लौटाता है;
- TWO समान है, लेकिन नियंत्रण वापस करने से पहले समन्वयक पहले दो नोड्स से पुष्टि की प्रतीक्षा करता है;
- तीन - इसी तरह, लेकिन नियंत्रण वापस करने से पहले समन्वयक पहले तीन नोड्स से पुष्टि की प्रतीक्षा करता है;
- कोरम - एक कोरम एकत्र किया जा रहा है: समन्वयक प्रतिकृति नोड्स के आधे से अधिक से रिकॉर्ड की पुष्टि की प्रतीक्षा कर रहा है, अर्थात् गोल (एन / 2) + 1, जहां एन प्रतिकृति का स्तर है;
- LOCAL_QUORUM - समन्वयक उसी डेटा केंद्र में प्रतिकृति नोड्स के आधे से अधिक से पुष्टि की प्रतीक्षा कर रहा है, जहां समन्वयक स्थित है (संभवतः प्रत्येक अनुरोध के लिए)। आपको अन्य डेटा केंद्रों में डेटा भेजने से जुड़ी देरी से छुटकारा पाने की अनुमति देता है। इस लेख में कई डेटा केंद्रों के साथ काम करने के मुद्दों पर चर्चा की गई है;
- EACH_QUORUM - समन्वयक स्वतंत्र रूप से प्रत्येक डेटा सेंटर में प्रतिकृति नोड्स के आधे से अधिक से पुष्टि की प्रतीक्षा कर रहा है;
- सभी - समन्वयक सभी प्रतिकृति नोड्स से पुष्टि की प्रतीक्षा कर रहा है;
- कोई भी - डेटा को लिखना संभव बनाता है, भले ही सभी प्रतिकृति नोड्स प्रतिक्रिया न दें। समन्वयक किसी भी प्रतिकृति नोड में से पहली प्रतिक्रिया की प्रतीक्षा करता है, या जब समन्वयक पर संकेतित हैंडऑफ़ का उपयोग करके डेटा सहेजा जाता है।
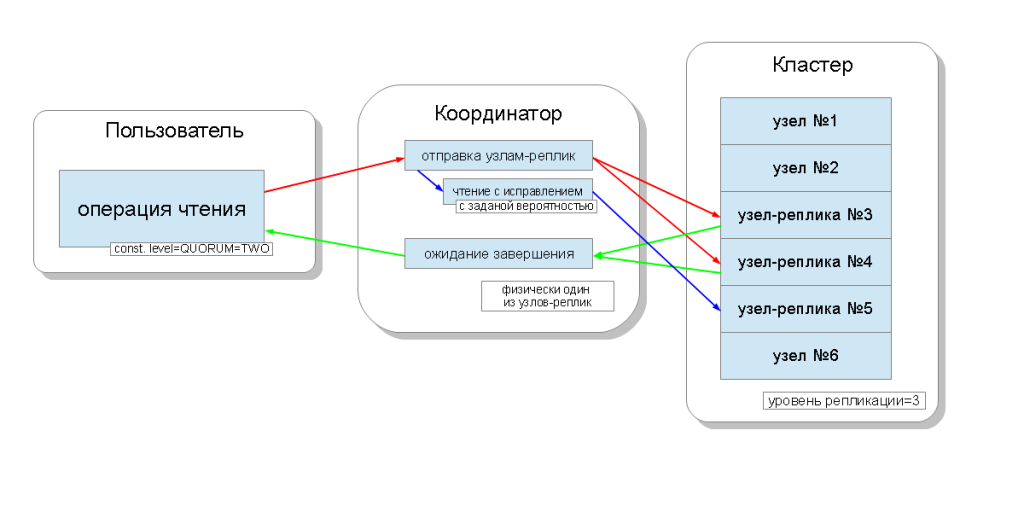
पढ़ने के लिए, स्थिरता का स्तर प्रतिकृति नोड्स की संख्या को प्रभावित करेगा जो इससे पढ़ा जाएगा। पढ़ने के लिए, स्थिरता के ऐसे स्तर हैं:
- एक - समन्वयक निकटतम प्रतिकृति नोड के लिए अनुरोध भेजता है। शेष प्रतिकृतियां भी कैसेंड्रा कॉन्फ़िगरेशन में निर्दिष्ट संभावना के साथ पढ़ने की मरम्मत के लिए पढ़ी जाती हैं ;
- दो समान है, लेकिन समन्वयक दो निकटतम नोड्स के लिए अनुरोध भेजता है। वह मान जिसके पास एक बड़ा टाइमस्टैम्प है, उसका चयन किया जाता है;
- तीन - पिछले विकल्प के समान, लेकिन तीन नोड्स के साथ;
- QUORUM - एक कोरम एकत्र किया जा रहा है, अर्थात, समन्वयक प्रतिकृति नोड्स के आधे से अधिक को अनुरोध भेजता है, अर्थात् गोल (एन / 2) + 1, जहां एन प्रतिकृति का स्तर है;
- LOCAL_QUORUM - डेटा केंद्र में एक कोरम एकत्र किया जाता है जिसमें समन्वय होता है, और अंतिम बार स्टाम्प के साथ डेटा वापस आ जाता है;
- EACH_QUORUM - संयोजक डेटा केंद्रों में से प्रत्येक में कोरम बैठक के बाद डेटा लौटाता है;
- सभी - समन्वयक सभी प्रतिकृति नोड्स से पढ़ने के बाद डेटा लौटाता है।
इस प्रकार, पढ़ने के समय की देरी, संचालन और
धुन की स्थिरता (
ट्यून स्थिरता ), साथ ही प्रत्येक प्रकार के संचालन की
उपलब्धता (
उपलब्धता ) को समायोजित करना संभव है। वास्तव में, पहुंच सीधे पढ़ने और लिखने के संचालन की स्थिरता के स्तर पर निर्भर करती है, क्योंकि यह निर्धारित करता है कि कितने प्रतिकृति नोड विफल हो सकते हैं, और एक ही समय में, इन ऑपरेशनों की पुष्टि अभी भी होगी।
यदि नोड्स की संख्या जिसमें से लिखित पुष्टि प्राप्त होती है, कुल मिलाकर नोड्स की संख्या, जिसमें से रीड बनाए जाते हैं, प्रतिकृति स्तर से अधिक है, तो हमारे पास गारंटी है कि लिखने के बाद नया मान हमेशा पढ़ा जाएगा, और इसे
सख्त स्थिरता (
मजबूत) कहा जाता है
संगति )। सख्त स्थिरता की अनुपस्थिति में, यह संभव है कि एक रीड ऑपरेशन अप्रचलित डेटा वापस कर देगा।
किसी भी स्थिति में, मूल्य अंततः प्रतिकृतियों के बीच फैल जाएगा, लेकिन समन्वय इंतजार खत्म होने के बाद ही। इस वितरण को
अंतिम संगति कहा जाता है। यदि रिकॉर्डिंग के दौरान सभी प्रतिकृति नोड उपलब्ध नहीं हैं, तो जल्दी या बाद में, पुनर्प्राप्ति उपकरण का उपयोग किया जाएगा, जैसे कि रीड-रिपेयर और एंटी-एंट्रॉपी नोड मरम्मत। इसके बारे में बाद में।
इस प्रकार, QUORUM ने निरंतरता के स्तर को पढ़ा और लिखा है, सख्त स्थिरता हमेशा बनी रहेगी, और यह पढ़ने और लिखने के संचालन में देरी के बीच एक प्रकार का संतुलन होगा। ONE लिखते समय ALL लिखते समय, सख्त संगति होगी, और रीड ऑपरेशंस तेज और अधिक सुलभ होंगे, अर्थात, जिस समय तक रीडिंग का प्रदर्शन किया जाएगा, उसमें विफल नोड्स की संख्या QUORUM से अधिक हो सकती है। लिखने के संचालन के लिए, सभी प्रतिकृति काम नोड्स की आवश्यकता होती है। जब सब एक को पढ़ते हैं, तो सभी को पढ़ना, सख्त स्थिरता भी होगी, और लिखने का कार्य तेज हो जाएगा और लेखन क्षमता बड़ी हो जाएगी, क्योंकि यह केवल यह पुष्टि करने के लिए पर्याप्त होगा कि लेखन ऑपरेशन कम से कम एक सर्वर पर पारित हो गया है, और पढ़ना धीमा है और सभी प्रतिकृति नोड्स की आवश्यकता है । यदि एप्लिकेशन को सख्त संगतता की आवश्यकता नहीं है, तो यह पढ़ने और लिखने दोनों कार्यों को गति देने के लिए संभव हो जाता है, साथ ही साथ स्थिरता के निचले स्तर को निर्धारित करके पहुंच में सुधार होता है।
डेटा रिकवरी
कैसेंड्रा तीन डेटा रिकवरी तंत्र का समर्थन करता है:
- रीड रिपेयर - सभी प्रतिकृतियों से डेटा पढ़ने का अनुरोध किया जाता है और समन्वय पूरा होने के बाद तुलना की जाती है। नवीनतम टाइमस्टैम्प वाले कॉलम में नोड्स तक विस्तार होगा जहां लेबल पुराने हैं।
- दिशात्मक भेजने ( संकेतित हैंडऑफ़ ) - आपको इस घटना में समन्वयक पर लिखने के संचालन के बारे में जानकारी सहेजने की अनुमति देता है कि किसी भी नोड पर रिकॉर्डिंग विफल रही। बाद में, जब यह संभव होगा, रिकॉर्डिंग दोहराई जाएगी। आपको क्लस्टर में एक नोड की अल्पकालिक अनुपस्थिति के मामले में डेटा रिकवरी जल्दी करने की अनुमति देता है। इसके अलावा, निरंतरता के स्तर के साथ, कोई भी पूर्ण लिखने की उपलब्धता की अनुमति देता है, जब सभी प्रतिकृति नोड अनुपलब्ध होते हैं, तो लेखन ऑपरेशन की पुष्टि की जाती है, और डेटा समन्वयक नोड पर सहेजा जाता है।
- एंटी- एंट्रॉपी नोड मरम्मत सभी प्रतिकृतियों को पुनर्प्राप्त करने की एक निश्चित प्रक्रिया है, जिसे "नोडोडूल रिपेयर" कमांड का उपयोग करके मैन्युअल रूप से नियमित रूप से शुरू किया जाना चाहिए और आपको उन सभी डेटा की प्रतिकृतियों की संख्या बनाए रखने की अनुमति देता है जो पहले दो तरीकों से बहाल नहीं हुई हों। आवश्यक प्रतिकृति स्तर।
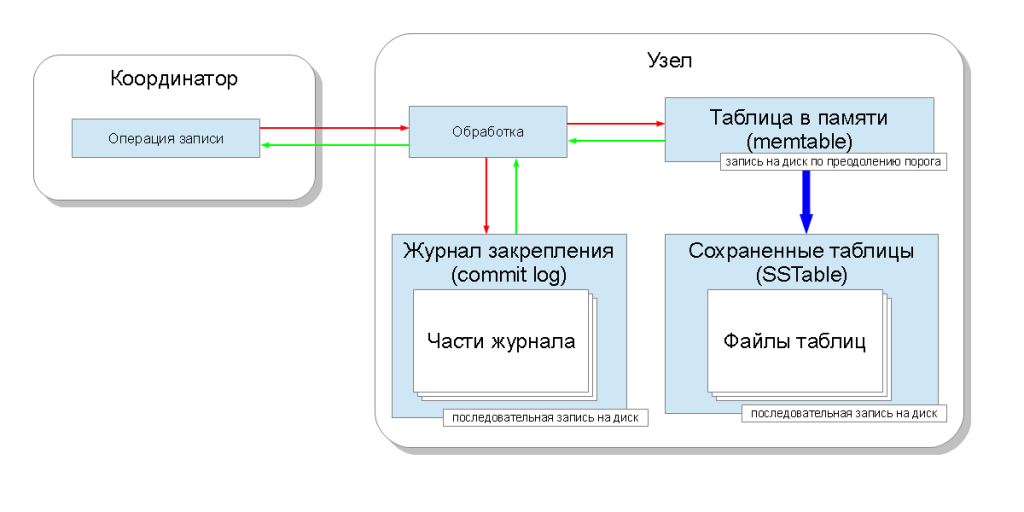
डिस्क को जलन
जब डेटा सीधे लिखने के लिए नोड के समन्वय के बाद आता है, तो यह दो डेटा संरचनाओं में आता है:
मेमोरी में टेबल (
यादगार ) और
कमिट लॉग । प्रत्येक स्तंभ परिवार के लिए एक मेमोरी टेबल मौजूद है और आपको तुरंत मूल्य याद रखने की अनुमति देता है। तकनीकी तौर पर, यह एक
हैशमैप है जिसमें
समवर्ती संरचना है जो डेटा संरचना पर आधारित है जिसे
स्किप सूची कहा जाता है। पिन लॉग पूरे मुख्य स्थान के लिए एक है और डिस्क पर सहेजा गया है। एक पत्रिका संशोधन कार्यों का एक अनुक्रम है। एक निश्चित आकार तक पहुँचने पर यह टुकड़ों में भी टूट जाता है।
ऐसा संगठन आपको अनुक्रमिक लेखन की गति से हार्ड डिस्क तक रिकॉर्डिंग की गति को सीमित करने की अनुमति देता है और उसी समय
डेटा स्थायित्व की गारंटी देता है। एक नोड के आपातकालीन स्टॉप की स्थिति में, पिन लॉग को कैसंड्रा सेवा की शुरुआत में पढ़ा जाता है और मेमोरी में सभी तालिकाओं को पुनर्स्थापित करता है। यह पता चला है कि गति डिस्क पर अनुक्रमिक रिकॉर्डिंग के दौरान टिकी हुई है, और आधुनिक हार्ड ड्राइव के लिए यह लगभग 100 एमबी / एस है। इस कारण से, पिन लॉग को एक अलग डिस्क ड्राइव पर रखने की सलाह दी जाती है।
यह स्पष्ट है कि जितनी जल्दी या बाद में स्मृति भर सकती है। इसलिए, स्मृति में तालिका को डिस्क पर सहेजने की भी आवश्यकता है। बचत के क्षण को निर्धारित करने के लिए,
मेमोरी में कब्जे वाली तालिकाओं के आकार की सीमा होती है (
memtable_total_spacein_mb ), डिफ़ॉल्ट रूप से यह
जावा हीप का अधिकतम आकार (
जावा हीपस्पेस ) है। इस सीमा से अधिक मेमोरी के साथ तालिकाओं को भरने पर,
कैसेंड्रा एक नई तालिका बनाता है और एक
सहेजे गए टेबल (
SSTable ) के रूप में डिस्क में मेमोरी में पुरानी तालिका लिखता है। निर्माण के बाद एक सहेजी गई तालिका कभी भी
संशोधित नहीं होती
है (
अपरिवर्तनीय है )। जब डिस्क पर बचत होती है, तो पिन लॉग के कुछ हिस्सों को मुफ्त में चिह्नित किया जाता है, जिससे पत्रिका द्वारा कब्जा कर लिया गया डिस्क स्थान खाली हो जाता है। यह ध्यान में रखा जाना चाहिए कि कुंजी स्थान में विभिन्न स्तंभ परिवारों के डेटा से लॉग में एक इंटरवॉवन संरचना है, और कुछ हिस्सों को मुक्त नहीं किया जा सकता है, क्योंकि कुछ क्षेत्र स्मृति में तालिकाओं में अभी भी अन्य डेटा के अनुरूप होंगे।
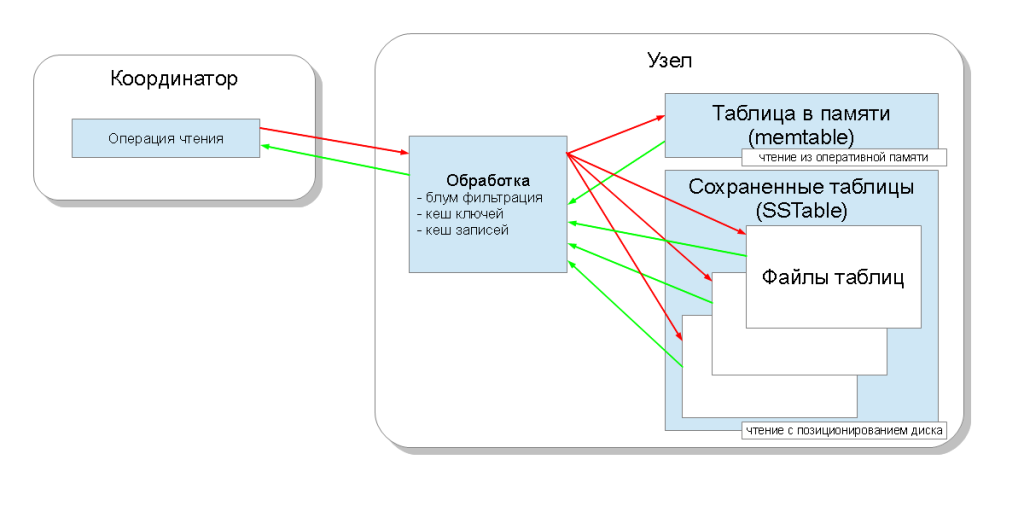
नतीजतन, प्रत्येक स्तंभ परिवार स्मृति में एक तालिका और एक निश्चित संख्या में संग्रहीत तालिकाओं से मेल खाता है। अब जब नोड रीड रिक्वेस्ट को प्रोसेस कर रहा है, तो उसे इन सभी स्ट्रक्चर्स को रिक्वेस्ट करने की जरूरत है और सबसे हाल के टाइमस्टैम्प वैल्यू को चुनना होगा।
: वहाँ प्रक्रिया में तेजी लाने के लिए तीन प्रक्रियाओं हैं ब्लूम फिल्टर ( खिलने फिल्टर ), कुंजी कैश ( कुंजी कैश ) और कैश रिकॉर्ड ( रिकॉर्ड कैश ):- ब्लूम फ़िल्टर एक डेटा संरचना है जो थोड़ी सी जगह लेता है और आपको प्रश्न का उत्तर देने की अनुमति देता है: इसमें निहित तत्व है, और हमारे मामले में यह कुंजी है, सेट में है या नहीं। इसके अलावा, यदि उत्तर "नहीं" है, तो यह 100% है, और यदि उत्तर "हां" है, तो यह संभवतः एक गलत-सकारात्मक उत्तर है। यह आपको संग्रहीत तालिकाओं से रीडिंग की संख्या को कम करने की अनुमति देता है;
- , ( seek operations ) ;
- , .
 एक निश्चित समय में, कॉलम परिवार में डेटा को अधिलेखित कर दिया जाएगा - कॉलम आ जाएगा जिसमें समान नाम और कुंजी होगी। यही है, एक स्थिति उत्पन्न होगी जब पुराने और नए डेटा को पुराने सहेजे गए तालिका और नए में समाहित किया जाएगा। अखंडता की गारंटी के लिए, कैसेंड्रा को इन सभी संग्रहीत तालिकाओं को पढ़ने और नवीनतम टाइमस्टैम्प के साथ डेटा का चयन करने की आवश्यकता होती है। यह पता चला है कि पढ़ने के दौरान हार्ड ड्राइव की स्थिति की संख्या संग्रहीत तालिकाओं की संख्या के आनुपातिक है। इसलिए, अधिलेखित डेटा को मुक्त करने और संग्रहीत तालिकाओं की संख्या को कम करने के लिए, एक संघनन प्रक्रिया ( संघनन) है)। यह कई संग्रहीत तालिकाओं को क्रमिक रूप से पढ़ता है और एक नई सहेजी गई तालिका लिखता है, जो टाइमस्टैम्प द्वारा डेटा को जोड़ती है। जब तालिका पूरी तरह से रिकॉर्ड की जाती है और उपयोग में लाई जाती है, तो कैसेंड्रा स्रोत तालिकाओं (इसे बनाने वाली तालिकाओं द्वारा) को मुक्त कर सकता है। इस प्रकार, यदि तालिकाओं में डेटा ओवरराइट किया जाता है, तो यह अतिरेक समाप्त हो जाता है। यह स्पष्ट है कि इस तरह के ऑपरेशन के दौरान अतिरेक की मात्रा बढ़ जाती है - स्रोत तालिकाओं के साथ डिस्क पर एक नई सहेजी गई तालिका मौजूद है, जिसका अर्थ है कि डिस्क स्थान की मात्रा हमेशा ऐसी होनी चाहिए कि संघनन किया जा सके।
एक निश्चित समय में, कॉलम परिवार में डेटा को अधिलेखित कर दिया जाएगा - कॉलम आ जाएगा जिसमें समान नाम और कुंजी होगी। यही है, एक स्थिति उत्पन्न होगी जब पुराने और नए डेटा को पुराने सहेजे गए तालिका और नए में समाहित किया जाएगा। अखंडता की गारंटी के लिए, कैसेंड्रा को इन सभी संग्रहीत तालिकाओं को पढ़ने और नवीनतम टाइमस्टैम्प के साथ डेटा का चयन करने की आवश्यकता होती है। यह पता चला है कि पढ़ने के दौरान हार्ड ड्राइव की स्थिति की संख्या संग्रहीत तालिकाओं की संख्या के आनुपातिक है। इसलिए, अधिलेखित डेटा को मुक्त करने और संग्रहीत तालिकाओं की संख्या को कम करने के लिए, एक संघनन प्रक्रिया ( संघनन) है)। यह कई संग्रहीत तालिकाओं को क्रमिक रूप से पढ़ता है और एक नई सहेजी गई तालिका लिखता है, जो टाइमस्टैम्प द्वारा डेटा को जोड़ती है। जब तालिका पूरी तरह से रिकॉर्ड की जाती है और उपयोग में लाई जाती है, तो कैसेंड्रा स्रोत तालिकाओं (इसे बनाने वाली तालिकाओं द्वारा) को मुक्त कर सकता है। इस प्रकार, यदि तालिकाओं में डेटा ओवरराइट किया जाता है, तो यह अतिरेक समाप्त हो जाता है। यह स्पष्ट है कि इस तरह के ऑपरेशन के दौरान अतिरेक की मात्रा बढ़ जाती है - स्रोत तालिकाओं के साथ डिस्क पर एक नई सहेजी गई तालिका मौजूद है, जिसका अर्थ है कि डिस्क स्थान की मात्रा हमेशा ऐसी होनी चाहिए कि संघनन किया जा सके। कासांद्रा आपको संघनन के संचालन के लिए दो में से एक रणनीति चुनने की अनुमति देता है:एक लिखने आपरेशन, विशेष अर्थ - - आंतरिक डिवाइस संचालन हटाने कॉलम के दृष्टिकोण से अधिलेखित कर देता है मानों ( समाधि )। जब इस तरह के मूल्य को पढ़ने के परिणामस्वरूप प्राप्त किया जाता है, तो इसे छोड़ दिया जाता है, जैसे कि ऐसा मूल्य कभी अस्तित्व में नहीं था। संघनन के परिणामस्वरूप, ऐसे मूल्य धीरे-धीरे अप्रचलित वास्तविक मूल्यों को विस्थापित कर देते हैं और संभवतः, पूरी तरह से गायब हो जाते हैं। यदि वास्तविक डेटा वाले कॉलम नए टाइमस्टैम्प के साथ भी दिखाई देते हैं, तो वे पीस जाएंगे, अंत में, ये ओवररेटेड मान।
कासांद्रा आपको संघनन के संचालन के लिए दो में से एक रणनीति चुनने की अनुमति देता है:एक लिखने आपरेशन, विशेष अर्थ - - आंतरिक डिवाइस संचालन हटाने कॉलम के दृष्टिकोण से अधिलेखित कर देता है मानों ( समाधि )। जब इस तरह के मूल्य को पढ़ने के परिणामस्वरूप प्राप्त किया जाता है, तो इसे छोड़ दिया जाता है, जैसे कि ऐसा मूल्य कभी अस्तित्व में नहीं था। संघनन के परिणामस्वरूप, ऐसे मूल्य धीरे-धीरे अप्रचलित वास्तविक मूल्यों को विस्थापित कर देते हैं और संभवतः, पूरी तरह से गायब हो जाते हैं। यदि वास्तविक डेटा वाले कॉलम नए टाइमस्टैम्प के साथ भी दिखाई देते हैं, तो वे पीस जाएंगे, अंत में, ये ओवररेटेड मान।लेन-देन संबंधी
कैसेंड्रा एक रिकॉर्ड के स्तर पर लेन-देन का समर्थन करता है, अर्थात्, एक कुंजी के साथ स्तंभों के सेट के लिए। यहाँ चार ACID आवश्यकताओं को कैसे पूरा किया जाता है:- ( atomicity ) — , ;
- ( consistency ) — , , ;
- ( isolation ) — 1.1, , , , , , , ;
- स्थायित्व ( स्थायित्व ) पत्रिका है, जो reproduced किया जाएगा फिक्सिंग द्वारा सुनिश्चित, और किसी भी विफलता की स्थिति में वांछित राज्य के लिए नोड को पुनर्स्थापित करता है।
अंतभाषण
इसलिए, हमने जांच की कि बुनियादी कार्यों को कैसे व्यवस्थित किया जाता है - कैसेंड्रा के मूल्यों को पढ़ना और लिखना।इसके अलावा, मेरी राय में, महत्वपूर्ण लिंक हैं:अनुरोध: व्यक्तिगत संदेश में लेख को बेहतर बनाने के लिए वर्तनी और विचारों पर टिप्पणी व्यक्त करें।