ऐसे अनुप्रयोग हैं जो संदेश प्रणाली के रूप में अच्छी तरह से कार्यान्वित किए जाते हैं। व्यापक अर्थों में, संदेश कुछ भी हो सकते हैं - डेटा ब्लॉक जो "सिग्नल" को नियंत्रित करते हैं, आदि। तर्क में नोड्स होते हैं जो संदेशों को संसाधित करते हैं, और उनके बीच कनेक्शन। इस तरह की संरचना को स्वाभाविक रूप से एक ग्राफ द्वारा दर्शाया जाता है जिसके किनारों को नोड्स में संसाधित संदेश "प्रवाह" करते हैं। इस तरह के एक मॉडल के लिए सबसे प्रसिद्ध नाम एक कम्प्यूटेशनल ग्राफ है।
एक कम्प्यूटेशनल ग्राफ का उपयोग करके, आप कुछ हद तक कार्यों के बीच निर्भरता स्थापित कर सकते हैं, प्रोग्रामेटिक रूप से "डेटाफ़्लो आर्किटेक्चर" को लागू कर सकते हैं।
इस पोस्ट में मैं
इंटेल थ्रेडिंग बिल्डिंग ब्लॉक्स (इंटेल टीबीबी) लाइब्रेरी का उपयोग करके सी ++ में इस तरह के एक मॉडल को लागू करने का वर्णन करूंगा, अर्थात् tbb :: flow :: graph वर्ग।
Intel TBB और tbb :: flow :: graph वर्ग क्या है
इंटेल थ्रेडिंग बिल्डिंग ब्लॉक्स - समानांतर प्रोग्रामिंग के लिए सी ++ टेम्पलेट लाइब्रेरी। यह एक मुक्त स्रोत कार्यान्वयन में नि: शुल्क वितरित किया जाता है, लेकिन एक व्यावसायिक संस्करण भी है। विंडोज *, लिनक्स * और ओएस एक्स * के लिए बाइनरी फॉर्म में उपलब्ध है।
टीबीबी में कई तैयार एल्गोरिदम, निर्माण और डेटा संरचनाएं हैं जो समानांतर कंप्यूटिंग में उपयोग के लिए अनुरूप हैं। सहित, ऐसे निर्माण हैं जो एक कम्प्यूटेशनल ग्राफ को लागू करने की अनुमति देते हैं, जिस पर चर्चा की जाएगी।
ग्राफ, जैसा कि आप जानते हैं, कोने (नोड्स) और किनारों से मिलकर बने होते हैं। कम्प्यूटेशनल ग्राफ tbb :: flow :: ग्राफ में नोड्स, एक किनारे और पूरे ग्राफ का एक ऑब्जेक्ट भी होता है।
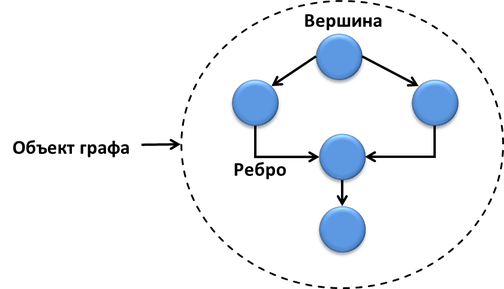
ग्राफ़ के नोड्स में प्रेषक और रिसीवर के इंटरफेस होते हैं, संदेश प्रबंधित करते हैं या कुछ फ़ंक्शन करते हैं। किनारों को ग्राफ के नोड्स से जोड़ा जाता है और संदेश पारित होने के "चैनल" हैं।
प्रत्येक नोड के शरीर को टीबीबी कार्य द्वारा दर्शाया जाता है और दूसरों के साथ समानांतर में निष्पादित किया जा सकता है यदि उनके बीच कोई निर्भरता नहीं है। टीबीबी में, कई समानांतर एल्गोरिदम (या सभी) कार्यों पर निर्मित होते हैं - छोटे कार्य आइटम (निर्देश) जो वर्कफ़्लो द्वारा निष्पादित होते हैं। कार्यों के बीच निर्भरता हो सकती है, उन्हें धागे के बीच गतिशील रूप से पुनर्वितरित किया जा सकता है। कार्यों के उपयोग के लिए धन्यवाद, सीपीयू पर इष्टतम ग्रैन्युलैरिटी और भार संतुलन को प्राप्त करना संभव है, साथ ही उनके आधार पर उच्च-स्तरीय समानांतर संरचनाओं का निर्माण करना - जैसे कि tbb :: flow :: graph।
सबसे सरल निर्भरता ग्राफ
एक किनारे से जुड़े दो सिरों वाला एक ग्राफ, जिसमें से एक "हेलो", और दूसरा "वर्ल्ड" प्रिंट करता है, को योजनाबद्ध रूप से निम्नानुसार दर्शाया जा सकता है:
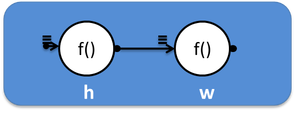
और कोड में यह इस तरह दिखेगा:
#include <iostream> #include <tbb/flow_graph.h> int main(int argc, char *argv[]) { tbb::flow::graph g; tbb::flow::continue_node< tbb::flow::continue_msg > h( g, []( const tbb::flow::continue_msg & ) { std::cout << "Hello "; } ); tbb::flow::continue_node< tbb::flow::continue_msg > w( g, []( const tbb::flow::continue_msg & ) { std::cout << "World\n"; } ); tbb::flow::make_edge( h, w ); h.try_put(tbb::flow::continue_msg()); g.wait_for_all(); return 0; }
यह ग्राफ जी की एक वस्तु बनाता है और दो प्रकार के होते हैं Continue_node - h और w। ये नोड्स जारी रखते हैं और एक प्रकार का संदेश जारी रखते हैं - आंतरिक नियंत्रण संदेश। वे निर्भरता ग्राफ बनाने के लिए उपयोग किए जाते हैं जब नोड बॉडी को उसके पूर्ववर्ती से एक संदेश प्राप्त होने के बाद ही निष्पादित किया जाता है।
Continue_node में से प्रत्येक कुछ सशर्त रूप से उपयोगी कोड निष्पादित करता है - "Hello" और "World" प्रिंट करें। Make_edge विधि का उपयोग करके नोड्स को एक किनारे से जोड़ा जाता है। सब कुछ, कम्प्यूटेशनल ग्राफ की संरचना तैयार है - आप इसे try_put विधि के साथ एक संदेश सबमिट करके निष्पादन के लिए चला सकते हैं। अगला, ग्राफ़ काम करता है, और यह सुनिश्चित करने के लिए कि इसके सभी कार्य पूरे हो गए हैं, हम प्रतीक्षा_फोर्मल विधि का उपयोग करके प्रतीक्षा करते हैं।
सरल मैसेजिंग ग्राफ
कल्पना करें कि हमारे कार्यक्रम को एक्स 1 से 10 तक एक्स के लिए एक्स
2 + एक्स
3 की गणना करनी चाहिए। यह सबसे कठिन कम्प्यूटेशनल कार्य नहीं है, लेकिन यह प्रदर्शन के लिए काफी उपयुक्त है।
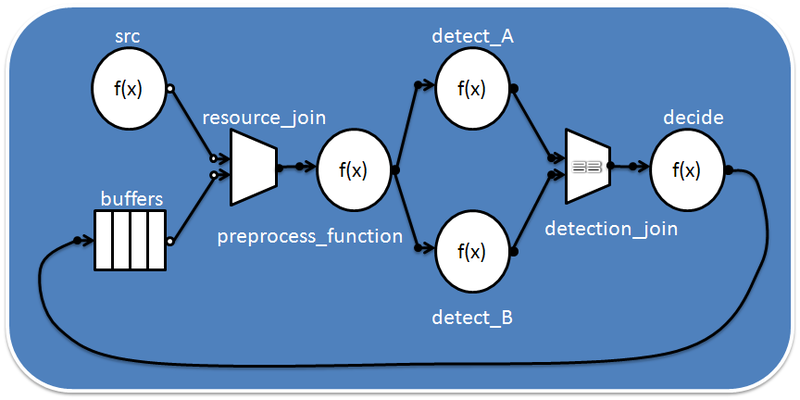
आइए अभिव्यक्ति की गिनती को एक ग्राफ के रूप में प्रस्तुत करने का प्रयास करें। पहला नोड आने वाले डेटा स्ट्रीम से x मान लेगा और इसे उन नोड्स में भेज देगा जो घन और वर्ग हैं। घातांक संचालन एक दूसरे से स्वतंत्र हैं और समानांतर में निष्पादित किए जा सकते हैं। संभव असंतुलन को सुचारू करने के लिए, वे अपने परिणाम को बफर नोड्स में स्थानांतरित करते हैं। इसके बाद यूनीफाइड नोड आता है, जो समन नोड की शक्ति को बढ़ाने के परिणामों की आपूर्ति करता है, जिस पर गणना समाप्त होती है:
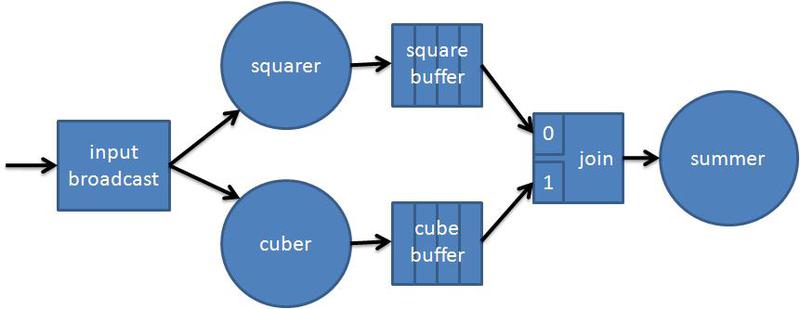
ऐसे ग्राफ के लिए कोड:
#include <tbb/flow_graph.h> #include <windows.h> using namespace tbb::flow; struct square { int operator()(int v) { printf("squaring %d\n", v); Sleep(1000); return v*v; } }; struct cube { int operator()(int v) { printf("cubing %d\n", v); Sleep(1000); return v*v*v; } }; class sum { int &my_sum; public: sum( int &s ) : my_sum(s) {} int operator()( std::tuple<int,int> v ) { printf("adding %d and %d to %d\n", std::get<0>(v), std::get<1>(v), my_sum); my_sum += std::get<0>(v) + std::get<1>(v); return my_sum; } }; int main(int argc, char *argv[]) { int result = 0; graph g; broadcast_node<int> input (g); function_node<int,int> squarer( g, unlimited, square() ); function_node<int,int> cuber( g, unlimited, cube() ); buffer_node<int> square_buffer(g); buffer_node<int> cube_buffer(g); join_node< std::tuple<int,int>, queueing > join(g); function_node<std::tuple<int,int>,int> summer( g, serial, sum(result) ); make_edge( input, squarer ); make_edge( input, cuber ); make_edge( squarer, square_buffer ); make_edge( squarer, input_port<0>(join) ); make_edge( cuber, cube_buffer ); make_edge( cuber, input_port<1>(join) ); make_edge( join, summer ); for (int i = 1; i <= 10; ++i) input.try_put(i); g.wait_for_all(); printf("Final result is %d\n", result); return 0; }
स्लीप (1000) फ़ंक्शन को प्रक्रिया की कल्पना करने के लिए जोड़ा गया है (उदाहरण विंडोज पर संकलित किया गया था, अन्य प्लेटफार्मों पर समकक्ष कॉल का उपयोग करें)। फिर सब कुछ पहले उदाहरण में है - हम नोड बनाते हैं, उन्हें किनारों के साथ जोड़ते हैं और उन्हें निष्पादन के लिए चलाते हैं। Function_node (अनलिमिटेड या सीरियल) में दूसरा पैरामीटर यह निर्धारित करता है कि नोड बॉडी के कितने उदाहरण समानांतर में निष्पादित किए जा सकते हैं। Type join_node का एक नोड प्रत्येक इनपुट पर इनपुट डेटा / संदेशों की तत्परता को निर्धारित करता है, और जब दोनों तैयार होते हैं, तो यह उन्हें std :: tuple के रूप में अगले नोड में भेज देता है।
Tbb :: flow :: graph का उपयोग करके रात के खाने के दार्शनिकों की समस्या का समाधान
विकिपीडिया से :
इन समस्याओं को हल करने के लिए समानांतर एल्गोरिदम और तकनीकों के डिजाइन में तुल्यकालन समस्याओं का वर्णन करने के लिए कंप्यूटर विज्ञान में उपयोग किया जाने वाला "दार्शनिकों की समस्या" एक उत्कृष्ट उदाहरण है।कार्य में, कई दार्शनिक मेज पर बैठे हैं, और या तो खा सकते हैं या सोच सकते हैं, लेकिन एक ही समय में नहीं। हमारे संस्करण में, दार्शनिक नूडल्स को चॉपस्टिक से खाते हैं - खाने के लिए आपको दो छड़ियों की आवश्यकता होती है, लेकिन हर एक उपलब्ध है:
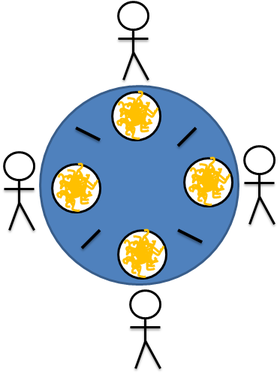
ऐसी स्थिति में, एक गतिरोध (गतिरोध) उत्पन्न हो सकता है, उदाहरण के लिए, प्रत्येक दार्शनिक अपने बाईं ओर एक छड़ी पकड़ता है, इसलिए रात्रिभोज के बीच क्रियाओं का सिंक्रनाइज़ेशन आवश्यक है।
आइए tbb :: flow :: graph के रूप में दार्शनिकों के साथ एक तालिका प्रस्तुत करने का प्रयास करें। प्रत्येक दार्शनिक को दो नोड्स द्वारा दर्शाया जाएगा: join_node को "खाने" और "विचार" कार्यों को पूरा करने के लिए लाठी और function_node के लिए। टेबल पर स्टिक के लिए जगह queue_node के माध्यम से लागू की गई है। Queue_node कतार में एक से अधिक छड़ी नहीं हो सकती है, और यदि यह वहां है, तो यह कैप्चर के लिए उपलब्ध है। ग्राफ इस तरह दिखेगा:
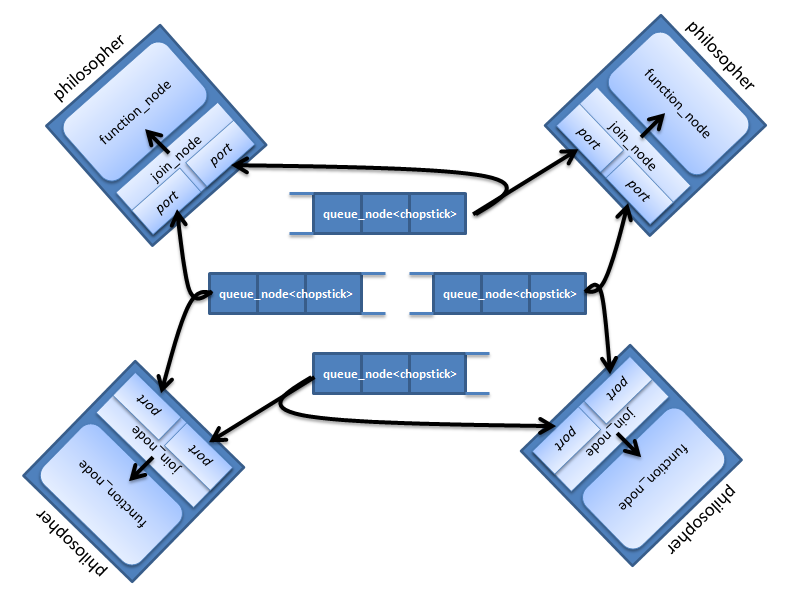
कुछ स्थिरांक और हेडर फ़ाइलों के साथ मुख्य कार्य:
#include <windows.h> #include <tbb/flow_graph.h> #include <tbb/task_scheduler_init.h> using namespace tbb::flow; const char *names[] = { "Archimedes", "Aristotle", "Democritus", "Epicurus", "Euclid", "Heraclitus", "Plato", "Pythagoras", "Socrates", "Thales" }; …. int main(int argc, char *argv[]) { int num_threads = 0; int num_philosophers = 10; if ( argc > 1 ) num_threads = atoi(argv[1]); if ( argc > 2 ) num_philosophers = atoi(argv[2]); if ( num_threads < 1 || num_philosophers < 1 || num_philosophers > 10 ) exit(1); tbb::task_scheduler_init init(num_threads); graph g; printf("\n%d philosophers with %d threads\n\n", num_philosophers, num_threads); std::vector< queue_node<chopstick> * > places; for ( int i = 0; i < num_philosophers; ++i ) { queue_node<chopstick> *qn_ptr = new queue_node<chopstick>(g); qn_ptr->try_put(chopstick()); places.push_back( qn_ptr ); } std::vector< philosopher > philosophers; for ( int i = 0; i < num_philosophers; ++i ) { philosophers.push_back( philosopher( names[i], g, places[i], places[(i+1)%num_philosophers] ) ); g.run( philosophers[i] ); } g.wait_for_all(); for ( int i = 0; i < num_philosophers; ++i ) philosophers[i].check(); return 0; }
कमांड लाइन के मापदंडों को संसाधित करने के बाद, लाइब्रेरी को टाइप tbb :: task_scheduler_init का ऑब्जेक्ट बनाकर आरम्भ किया जाता है। यह आपको आरंभीकरण के समय को नियंत्रित करने और मैन्युअल रूप से थ्रेड-हैंडलर की संख्या निर्धारित करने की अनुमति देता है। इसके बिना, प्रारंभ स्वचालित रूप से होगा। इसके बाद, ग्राफ जी का एक ऑब्जेक्ट बनाया जाता है। "छड़ी स्थान" कतार_नोड को std :: वेक्टर में रखा जाता है, और प्रत्येक छड़ी को एक छड़ी पर रखा जाता है।
आगे दार्शनिकों को एक समान तरीके से बनाया गया है - एसटीडी :: वेक्टर में रखा गया है। प्रत्येक दार्शनिक का उद्देश्य ग्राफ़ ऑब्जेक्ट के रन फ़ंक्शन को दिया जाता है। दार्शनिक वर्ग में ऑपरेटर () होगा, और रन फ़ंक्शन आपको इस फ़ंक्टर को एक कार्य में निष्पादित करने की अनुमति देता है जो ग्राफ़ जी ऑब्जेक्ट के मूल कार्य का एक बच्चा है। इसलिए हम इंतजार कर सकते हैं जब तक कि g.wait_for_all () को कॉल के दौरान ये कार्य पूरा नहीं हो जाता।
दार्शनिक वर्ग:
const int think_time = 1000; const int eat_time = 1000; const int num_times = 10; class chopstick {}; class philosopher { public: typedef queue_node< chopstick > chopstick_buffer; typedef join_node< std::tuple<chopstick,chopstick> > join_type; philosopher( const char *name, graph &the_graph, chopstick_buffer *left, chopstick_buffer *right ) : my_name(name), my_graph(&the_graph), my_left_chopstick(left), my_right_chopstick(right), my_join(new join_type(the_graph)), my_function_node(NULL), my_count(new int(num_times)) {} void operator()(); void check(); private: const char *my_name; graph *my_graph; chopstick_buffer *my_left_chopstick; chopstick_buffer *my_right_chopstick; join_type *my_join; function_node< join_type::output_type, continue_msg > *my_function_node; int *my_count; friend class node_body; void eat_and_think( ); void eat( ); void think( ); void make_my_node(); };
प्रत्येक दार्शनिक का एक नाम होता है, ग्राफ़ ऑब्जेक्ट को इंगित करता है और बाईं और दाईं ओर लाठी, join_node नोड, function_node फ़ंक्शन नोड और my_count काउंटर, जो गिनता है कि दार्शनिक ने कितनी बार सोचा और खाया।
ऑपरेटर () (), ग्राफ रन फ़ंक्शन द्वारा बुलाया जाता है, इसे लागू किया जाता है ताकि दार्शनिक पहले सोचता है और फिर ग्राफ में खुद को जोड़ता है।
void philosopher::operator()() { think(); make_my_node(); } think eat : void philosopher::think() { printf("%s thinking\n", my_name ); Sleep(think_time); printf("%s done thinking\n", my_name ); } void philosopher::eat() { printf("%s eating\n", my_name ); Sleep(eat_time); printf("%s done eating\n", my_name ); }
मेक_मी_नोड विधि एक फ़ंक्शन नोड बनाती है, और इसे दोनों को जोड़ती है और बाकी ग्राफ के साथ join_node:
void philosopher::make_my_node() { my_left_chopstick->register_successor( input_port<0>(*my_join) ); my_right_chopstick->register_successor( input_port<1>(*my_join) ); my_function_node = new function_node< join_type::output_type, continue_msg >( *my_graph, serial, node_body( *this ) ); make_edge( *my_join, *my_function_node ); }
ध्यान दें कि ग्राफ गतिशील रूप से बनाया गया है - बढ़त register_successor विधि द्वारा बनाई गई है। पहले ग्राफ संरचना को पूरी तरह से बनाना आवश्यक नहीं है, और फिर इसे निष्पादन के लिए चलाएं। टीबीबी में इस संरचना को मक्खी पर बदलने की क्षमता है, भले ही ग्राफ पहले से चल रहा हो - हटाएं और नए नोड जोड़ें। यह एक कम्प्यूटेशनल ग्राफ की अवधारणा के लिए और भी अधिक लचीलापन जोड़ता है।
नोड_बॉडी वर्ग एक सरल फ़नकार है जो दार्शनिक को बुलाता है :: eat_and_think () विधि:
class node_body { philosopher &my_philosopher; public: node_body( philosopher &p ) : my_philosopher(p) { } void operator()( philosopher::join_type::output_type ) { my_philosopher.eat_and_think(); } };
खाने_और_लिंक विधि खाने () फ़ंक्शन को कॉल करती है और काउंटर को घटाती है। तब दार्शनिक अपने वैंड्स को टेबल पर रखता है और सोचता है। और यदि उसने खाया और सही संख्या में बार सोचा, तो वह टेबल से उठ जाता है - अपने join_node के कनेक्शन को हटाने के साथ ग्राफ के साथ निकालता है। यहां फिर से, ग्राफ की गतिशील संरचना दिखाई देती है - नोड्स का हिस्सा हटा दिया जाता है जबकि बाकी काम करना जारी रखते हैं।
void philosopher::eat_and_think( ) { eat(); --(*my_count); if (*my_count > 0) { my_left_chopstick->try_put( chopstick() ); my_right_chopstick->try_put( chopstick() ); think(); } else { my_left_chopstick->remove_successor( input_port<0>(*my_join) ); my_right_chopstick->remove_successor( input_port<1>(*my_join) ); my_left_chopstick->try_put( chopstick() ); my_right_chopstick->try_put( chopstick() ); } }
हमारे ग्राफ में दार्शनिक के लिए कतार (एक छड़ी के लिए एक जगह) से एक छोर है, अधिक सटीक रूप से, इसके join_node। लेकिन विपरीत दिशा में, नहीं। हालाँकि, खाने_और_थिंक विधि try_put कॉल कर सकते हैं ताकि कतार को वापस कतार में रखा जा सके।
प्रत्येक दार्शनिक के लिए मुख्य () फ़ंक्शन के अंत में, चेक विधि कहा जाता है, जो यह सुनिश्चित करता है कि दार्शनिक ने कई बार सही संख्या में खाया और सोचा है और आवश्यक "सफाई" करता है:
void philosopher::check() { if ( *my_count != 0 ) { printf("ERROR: philosopher %s still had to run %d more times\n", my_name, *my_count); exit(1); } else { printf("%s done.\n", my_name); } delete my_function_node; delete my_join; delete my_count; }
इस उदाहरण में डेडलॉक join_node के उपयोग के कारण नहीं होता है। इस प्रकार के नोड्स दोनों इनपुटों से प्राप्त वस्तुओं से std :: tuple बनाते हैं। इस मामले में, रसीद पर तुरंत इनपुट डेटा का उपभोग नहीं किया जाता है। join_node पहले प्रतीक्षा करता है जब तक कि डेटा दोनों इनपुट पर प्रकट न हो जाए, फिर बदले में उन्हें आरक्षित करने का प्रयास करता है। यदि यह ऑपरेशन सफल होता है - केवल तभी वे "भस्म" होते हैं और एसटीडी :: ट्यूपल उनसे बनाया जाता है। यदि कम से कम एक इनपुट "चैनल" का आरक्षण नहीं करता है, तो जो पहले से आरक्षित हैं, वे जारी किए जाते हैं। यानी यदि दार्शनिक एक छड़ी पर कब्जा कर सकता है, लेकिन दूसरा व्यस्त है, तो वह पड़ोसियों को व्यर्थ जाने के बिना, पहले जाने और इंतजार करने देगा।
यह भोजन दार्शनिक उदाहरण टीबीबी ग्राफ की कई विशेषताओं को प्रदर्शित करता है:
- संसाधन पहुँच सिंक्रनाइज़ेशन सुनिश्चित करने के लिए join_node का उपयोग करना
- गतिशील ग्राफ निर्माण - नोड्स को ऑपरेशन के दौरान जोड़ा और हटाया जा सकता है
- एकल प्रविष्टि और निकास बिंदुओं की कमी, ग्राफ़ में लूप हो सकते हैं
- ग्राफ रन फ़ंक्शन का उपयोग करना
नोड्स के प्रकार
tbb :: flow :: graph नोड विकल्पों की एक विस्तृत श्रृंखला प्रदान करता है। उन्हें चार समूहों में विभाजित किया जा सकता है: कार्यात्मक, बफरिंग, संयोजन और अलग करना, और अन्य। पौराणिक कथा के साथ नोड प्रकारों की सूची:
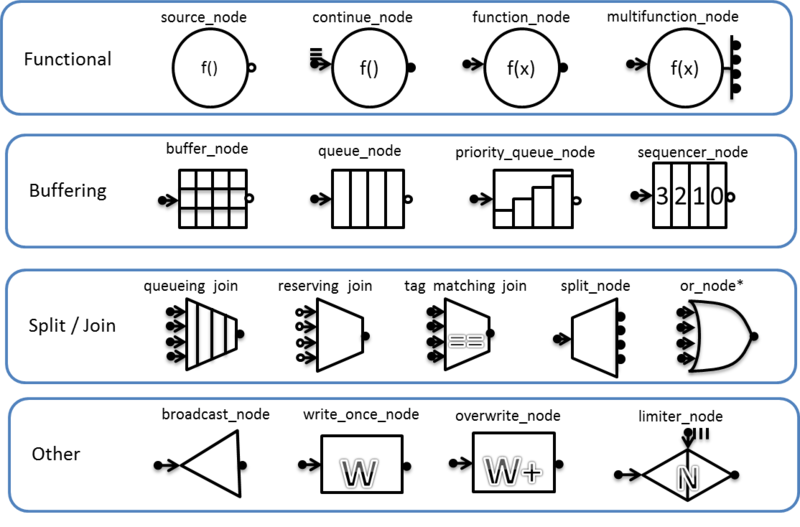
निष्कर्ष
इंटेल टीबीबी में लागू ग्राफ का उपयोग करके, आप एक समानांतर कार्यक्रम के लिए जटिल और दिलचस्प तर्क बना सकते हैं, जिसे कभी-कभी "असंरचित समानता" कहा जाता है। कम्प्यूटेशनल ग्राफ़ आपको संदेशों और घटनाओं के प्रसारण के आधार पर कार्यों के बीच निर्भरता को व्यवस्थित करने, अनुप्रयोगों के निर्माण की अनुमति देता है।
ग्राफ संरचना या तो स्थिर या गतिशील हो सकती है - नोड्स और किनारों को मक्खी पर जोड़ा और हटाया जा सकता है। आप अलग-अलग सबग्राफ को एक बड़े ग्राफ़ में जोड़ सकते हैं।
अधिकांश सामग्री मेरे विदेशी सहयोगियों के अंग्रेजी प्रकाशनों पर आधारित है।
जो लोग रुचि रखते हैं, उनके लिए प्रयास करें:
डाउनलोड इंटेल थ्रेडिंग बिल्डिंग ब्लॉक्स लाइब्रेरी (ओपन सोर्स संस्करण):
http://threadingbuildingblocks.orgइंटेल टीबीबी का व्यावसायिक संस्करण (कार्यात्मक रूप से अलग नहीं):
http://software.intel.com/en-us/intel-tbbTbb :: flow :: graph के बारे में अंग्रेजी ब्लॉग
http://software.intel.com/en-us/tags/17218http://software.intel.com/en-us/tags/17455