यह क्या है और किसके लिए (शामिल होने के बजाय)इस लेख में मैं टेक्स्ट माइनिंग के क्षेत्र में अपनी शोध गतिविधियों के छोटे परिणामों के बारे में बात करना चाहूंगा। ये बहुत ही "परिणाम" एक छोटे फ़्रेमवर्क थे, जो अब तक बहुत अच्छे नहीं हैं, लेकिन हम बढ़ रहे हैं =)। यह परियोजना मेरे द्वारा विकसित किए गए कुछ सैद्धांतिक प्रावधानों के कार्यान्वयन में है। इसके परिणामस्वरूप, मैं उन अवसरों को प्रस्तुत करता हूं जो संभवतः सभी विचारों के कार्यान्वयन के अंत में हो सकते हैं। इस रचना को कहा जाता है: "टेक्स्ट माइनिंग फ़्रेमवर्क" (टेक्स्टएमएफ)। चलिए संक्षेप में समीक्षा करते हैं कि TextMF अपने पहले अंतिम संस्करण में क्या अनुमति देगा और अब क्या काम करता है।
अंतिम संस्करण में होना चाहिए :
- सांख्यिकीय पाठ विश्लेषण;
- पाठ में सभी शब्दों और प्रत्येक शब्द के शब्द रूपों की खोज करें;
- पाठ में वजन द्वारा शब्दों की रैंकिंग;
- प्रश्न में पाठ में विषयों की खोज करें;
- पाठ में विषयों के बीच लिंक (प्रत्यक्ष और गैर-प्रत्यक्ष लिंक);
- पाठ अमूर्त;
- पाठ के विषय की परिभाषा;
- भाषा प्रशिक्षण;
- संचार के माध्यम से उपयोगकर्ता के साथ बातचीत का संगठन (चैट)।
पहले से ही लागू (आंशिक रूप से उपलब्ध या परीक्षण से गुजरना) :
- पाठ का सांख्यिकीय विश्लेषण (अब तक बहुत आंशिक रूप से लागू);
- पाठ में सभी शब्दों और शब्द रूपों के लिए खोजें;
- किसी दिए गए पाठ में उनके वजन के अनुसार शब्दों को क्रमबद्ध करें;
- पाठ में व्यक्तियों की खोज करें;
- पाठ के विषय की परिभाषा (सूत्रों का परीक्षण और संरेखण)।
क्यों एक और टेक्स्ट प्रोसेसिंग लाइब्रेरी?तथ्य यह है कि इस परियोजना का लक्ष्य एक ऐसा उपकरण बनाना नहीं है, जिसके उपयोग से आप किसी भी प्रकार के टेक्स्ट प्रोसेसिंग एल्गोरिदम (जैसे
पायथन एनएलटीके और इसी तरह के अन्य) को लागू कर सकते हैं, लेकिन तैयार एल्गोरिदम का उपयोग करना संभव बना सकते हैं। और एक ही समय में व्यवहार में अपने खुद के एल्गोरिथ्म का परीक्षण करने के लिए। यानी यह एक अन्य सांख्यिकीय विश्लेषक या पाठ डेटा के साथ काम करने के लिए अनुकूलित कंटेनरों का एक सेट नहीं है। नहीं! यह हेयूरिस्टिक्स का एक सेट है जो अतिरिक्त ज्ञान की आवश्यकता के बिना बॉक्स से बाहर काम करेगा।
TextMF किस इनपुट डेटा के साथ काम करता है: अब तक केवल पाठ फ़ाइलें। कहने की जरूरत नहीं है, ज्यादा बड़े इनपुट प्रारूपों के लिए आगे समर्थन की योजना है। वेब के साथ एकीकरण करने की भी योजना है, ताकि वेब पेजों का शांतिपूर्वक विश्लेषण करना संभव हो सके।
दिखावे और पासवर्डयह परियोजना
बिटबकेट रिपॉजिटरी के माध्यम से वितरित की गई है।
इसे अपने आप से मोड़ें और अपने प्रोजेक्ट से कनेक्ट करें =) सब कुछ बेहद सरल है। जल्द ही, प्लग-इन जार के रूप में विधानसभाएं उपलब्ध होंगी।
उदाहरण का उपयोग करेंपाठ प्रसंस्करण बहुत बार बहुत समय लेता है, खासकर यदि आप एक पूरी किताब खोलने की कोशिश करते हैं! इसलिए इसे आज़माने के लिए, मैं दृढ़ता से खुद को साइटों से कुछ पृष्ठ के पाठों तक सीमित करने की सलाह देता हूँ। हालांकि, बहुत छोटे ग्रंथ भी बहुत अच्छे परिणाम नहीं दे सकते हैं, उनमें जानकारी की कमी के कारण।
जैसा कि पहले उल्लेख किया गया है, मुख्य विचार हेरास्टिक और एल्गोरिदम के उपयोग और छिपाने की अधिकतम आसानी है। तो सब कुछ ठीक है:
मैं दोहराता हूं, एक विषय प्राप्त करना एक लंबी प्रक्रिया है, इसलिए इस पद्धति को कहते समय सावधान रहें;) विषय प्राप्त करने की अतुल्यकालिक विधि को स्वयं द्वारा लागू किया जाएगा, लेकिन बाद में। यह भी ध्यान रखना महत्वपूर्ण है कि प्रस्तुत पाठ के आकार के आधार पर विधियों के काम की गुणवत्ता बढ़ जाती है। जितनी अधिक जानकारी है, एक नियम के रूप में, एक भाषा सीखने का अवसर उतना ही अधिक होगा। हालाँकि, सामग्री के बढ़ते आकार के साथ, फाइलों का शुरुआती समय काफी बढ़ जाता है।
छोटे यूआई कार्यक्रमकार्यक्रम की कुछ विशेषताओं के बारे में बताने के लिए, आंद्रेई नाम के मेरे सहयोगी ने यूआई के एक छोटे ग्राहक को मार दिया। वर्तमान स्तर पर, यह केवल मार्गदर्शन के लिए है, क्योंकि इसका उपयोग करना कभी-कभी अधिक सुविधाजनक होता है। यह जावा एफएक्स में लिखा गया है, और अभी तक एक अलग जार फ़ाइल के रूप में वितरित नहीं किया गया है। इसे "महसूस" करने के लिए, आपको इसे इकट्ठा करने की आवश्यकता है = (।
कार्यक्रम की मुख्य खिड़की:
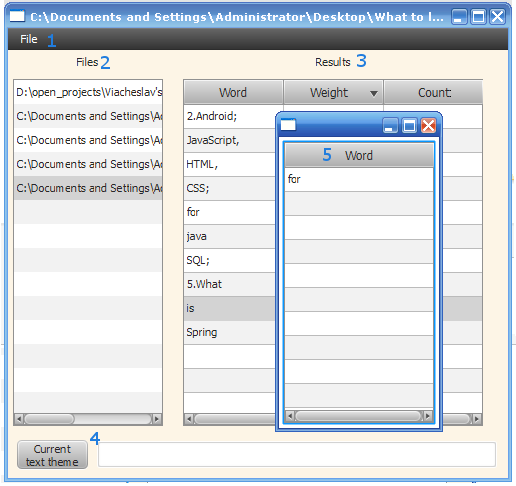
1) संसाधित होने के लिए पाठ का चयन करने के लिए मेनू;
2) चयनित फ़ाइलों की सूची;
3) काम के परिणाम:
क) पाठ में पाया जाने वाला शब्द;
बी) पाठ में शब्द का वजन;
c) पाठ में दोहराव की संख्या
4) एक पाठ विषय प्रदर्शित करने के लिए एक क्षेत्र;
5) शब्द रूपों की सूची।
आइए देखें कि हम इस पाठ के लिए अपने कार्यक्रम का उपयोग करके क्या पता लगा सकते हैं:
वोल्गा और मस्कोवाइट्स के मालिकों को एक और साल दिया जाएगा :
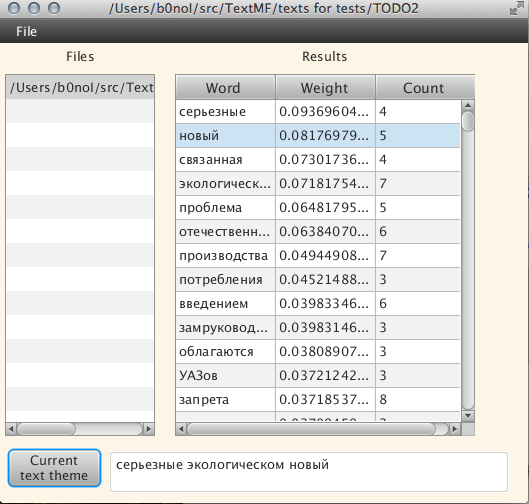
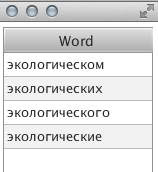
विषय को लगभग एक मिनट तक खोजा गया (लंबा, मैं सहमत हूं)। किसी एक शब्द को चुनते समय, आप उसका शब्द रूप देख सकते हैं:

या यहाँ:
और अब एक और पाठ आज़माते हैं: “
एलियंस ने Ukrainians के एक परिवार का अपहरण कर लिया और पृथ्वी के भविष्य के बारे में बात की! ", संभवतः सबसे" पीले "ग्रंथों में से एक =):
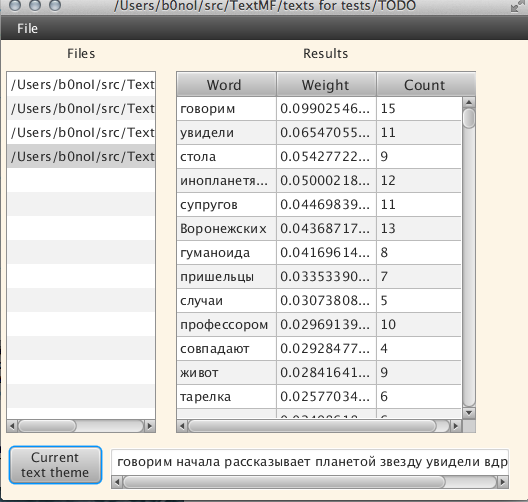
पाठ एक लंबे समय के लिए खोला गया, शायद एक मिनट, मैंने उसी तरह कहीं और विषय की खोज की। बेशक, एक पाठ विषय को शब्दों की एक श्रृंखला के रूप में समझा जाना चाहिए जिसे एल्गोरिथ्म एक पाठ विषय के रूप में मानता है। भविष्य में, एल्गोरिदम एक पठनीय रूप में आउटपुट का उत्पादन करने में सक्षम होगा, लेकिन यह भविष्य है, और अब है
हमें आपकी सहायता की आवश्यकता हैबेशक, हम वास्तव में, वास्तव में आपकी मदद की जरूरत है! बहुत सारे कार्य हैं, लेकिन परियोजना स्वतंत्र है। कार्य सबसे सरल से शुरू होते हैं: एक साइट में संलग्न करने के लिए, सबसे कट्टर के लिए उदाहरण, दस्तावेज़ कोड लिखें: चटाई को अनुकूलित करने में मदद करने के लिए। तंत्र और इसे परिष्कृत करें। अब, उदाहरण के लिए, किसी के लिए अच्छा होगा कि वह इनपुट प्रारूपों के विस्तार के मुद्दे पर ले जाए और केवल एक पाठ फ़ाइल से अधिक कुछ करे। परीक्षण में सहायता भी बहुत महत्वपूर्ण है। परियोजना में एक डोमेन है:
www.textmf.com , हालांकि यह वहां खाली है, और मुझे बहुत खुशी होगी अगर किसी ने इसे ठीक करने में मदद की)))
सहयोग के किसी भी प्रस्ताव के लिए, कृपया यहां संपर्क करें:
Viacheslav@b0noI.comतत्काल योजनानिकट भविष्य में क्या होगा (मुझे लगता है कि एक या दो महीने के भीतर) परियोजना के साथ:
- जार फ़ाइल विधानसभा जोड़ें;
- परियोजना को कोर और UI में विभाजित किया जाएगा, अर्थात एक और भंडार जोड़ा जाएगा;
- दीर्घकालिक स्मृति का कार्यान्वयन शुरू होगा;
- व्यक्तियों के बीच संबंधों का विश्लेषण;
- पाठ को संक्षेप में प्रस्तुत करना संभव होगा;
- UI के साथ स्व-निहित जार बनाना।
दूर की योजनाअब TextMF
www.ukrinnovation.com प्रोजेक्ट का सेमीफाइनलिस्ट बन गया है। इसलिए, एक छोटा सा, लेकिन फिर भी विकास निवेश प्राप्त करने का एक मौका है।
मुझे पता है कि अब तक ये सपने हैं, लेकिन अगर उन्होंने मुझसे पूछा कि मैं अंत में क्या कार्यक्षमता देखता हूं, तो मैं जवाब दूंगा: एक पुस्तकालय जिसका उपयोग करके आप एक चैट बॉट लिख सकते हैं जो ट्यूरिंग टेस्ट पास करेगा। यदि अधिक वास्तविक बोलने के लिए, तो इंटरनेट पर जानकारी के गतिशील ट्रैकिंग के लिए सबसे अधिक संभावना वाले इंजन हैं। लिंक ट्रैक करें और उनके परिवर्तनों की निगरानी करें। बेशक, किसी भी स्थानीय खोज इंजन बनाने के लिए कुछ।
इस विचार में स्वयं बहुत संभावनाएं हैं, यहां स्पैम फिल्टर, खोज इंजन और स्वचालित संदर्भित सिस्टम और कई, कई और चीजें हैं जो इस तरह के ढांचे के आधार पर बनाई जा सकती हैं।
TextMF लेखक:आपका विनम्र सेवक व्याचेस्लाव वी कोवालेवस्की और
UI डेवलपर एंड्रे प्रिसिखा (vinglfm@gmail.com)