प्रस्तावना
फिर से नमस्कार!
चूंकि
पहला भाग अनुकूल
रूप से प्राप्त हुआ था, मैंने पाठ्यक्रम पूरा होने के बाद, अपने सभी छापों के बारे में लिखने का फैसला किया।

पिछली श्रृंखला का सारांश: मैंने ल्युट्ज़ और निक पार्लेंट के बाद एक मौलिक सीएस
पाठ्यक्रम (दुर्भाग्य से, हमेशा अजगर शैली नहीं), आसान
पाठ्यक्रम "सबसे छोटे के लिए पायथन" (पहले से ही पूरा) के लिए, अजगर सीखने का फैसला किया। खैर, उनके बीच कहीं मैं
CS188.1x एआई में शामिल हो गया, अब यह देखते हुए कि मैं अजगर को प्रशिक्षित करता हूं, इसलिए गंभीर चीजों पर।
पिछली समीक्षा में, मैं पाठ्यक्रम के पहले 2 हफ्तों (लगभग 30%) पर विचार करने में कामयाब रहा, वास्तव में 19 नवंबर को मैंने अंतिम परीक्षा के लिए कठिन समय सीमा पार कर ली, और मैं संक्षेप में प्रस्तुत करना चाहता हूं।
हम एआई-जातियों की पेचीदगियों से परिचित होना जारी रखते हैं
प्रोजेक्ट 1 के असफल कार्यान्वयन के बाद, छात्रों को बाधा संतुष्टि समस्याओं (सीएसपी) के बारे में जानकारी की एक परत की प्रतीक्षा थी। संक्षेप में, यह बात है कि तकनीकी रूप से समस्याओं को एक निश्चित संख्या में प्रतिबंधों के साथ कैसे हल किया जाए - सबसे विशिष्ट है, उदाहरण के लिए, विश्वविद्यालय के लिए एक शेड्यूल बनाने के लिए, प्रोफेसरों, कक्षाओं के रोजगार को ध्यान में रखते हुए, उपलब्ध समय की तुलना करना आदि। ऐसा लगता है कि सहज रूप से सब कुछ स्पष्ट है (लेकिन हमेशा सरल नहीं), लेकिन सभी प्रकार की चालें हैं जो राज्य ग्राफ के ट्रैवर्सल को गति देती हैं। जो लोग
इस इंटरैक्टिव html के साथ खेल सकते हैं (यहां आपको रंगों को असाइन करने की आवश्यकता है, पड़ोसी तत्व एक ही रंग नहीं हो सकते। आप स्पष्ट रूप से देख सकते हैं कि समाधान का चयन बिना अनुकूलन के और कुछ ग्राफ़ ट्रैवर्सल अनुकूलन के साथ कैसे भिन्न होता है)। सामान्य तौर पर, यह विषय जटिल नहीं लगता था।
आगे हम गेम ट्री और डिसीजन थ्योरी का इंतजार कर रहे थे। तब प्रोफेसर दुश्मन से विरोध के पक्ष में खेल की समस्याओं के समाधान से परिचित थे (पाक के मामले में यह भूत था)। सिद्धांत रूप में, गेम ट्री पर समान खोज, प्रतिद्वंद्वी के सभी प्रकार के चालों को ध्यान में रखते हुए, या तो इष्टतम नहीं है। अल्फा-बीटा प्रूनिंग अकेले एक तरह से समय की कमी को कम करने के लिए एक बड़े पेड़ को पार करने के लिए अलग-अलग गारंटीकृत अप्रकाशित शाखाओं को काटकर ले जाता है।
प्रोजेक्ट 2 ने मुझे बताया: "यार, फिर से अपने अजगर के यहाँ आओ।" वास्तव में फिर से एक तेज, लेकिन शब्दों से कोड तक अप्रत्याशित संक्रमण नहीं। वही Pacman World बना रहा, केवल दुश्मन एजेंटों को जोड़ा गया था।
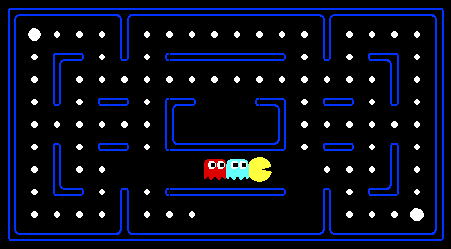
पहले रिफ्लेक्सएजेंट को लागू करना आवश्यक था, जो कुछ भी योजना नहीं करता है, विशेष रूप से वर्तमान खेल की स्थिति से कार्य करता है। अगला - मिनिमैक्सएजेंट, दुश्मन के इष्टतम कार्यों से आगे बढ़ता है और भविष्य में दूर (धीरे-धीरे काम नहीं करता) दिखता है। फिर आप स्पष्ट रूप से समझते हैं कि अल्फ़ा-बीटा का उपयोग करके कुछ आगे बढ़ने पर परिमाण के क्रम से समय कैसे कम होता है। ExpectimaxAgent प्रतिद्वंद्वी की संभावित मूर्खता के आधार पर कार्य करता है, जो कभी-कभी आपको घातक गेम स्थितियों से विजयी होने की अनुमति देता है। खैर, मिठाई के लिए - "आपका चरम भूत-शिकार, पेलेट-नबिंग, फूड-गॉब्लिंग, अनस्टॉपेबल मूल्यांकन फ़ंक्शन।" इसके लिए, मुझे 0/6 मिला, क्योंकि मैंने तर्क लिखा था और इसे ठीक से डिबग करने का प्रबंधन नहीं किया था। निष्कर्ष - डेडलाइन से ठीक पहले प्रोजेक्ट पर मत बैठो, अगर यह रविवार रात को है, और आपको सोमवार को काम करना चाहिए।
सीखने के लिए ऐ सीखना, या अयोग्य "पंजा"
पिछले दो सप्ताह मार्कोव निर्णय प्रक्रिया (एमडीपी) के लिए समर्पित रहे हैं, जो एमडीपी और सुदृढीकरण सीखने (आरएल) के रूप में दुनिया का प्रतिनिधित्व करने का एक प्रकार है, जब हमें हमारे आसपास की दुनिया की स्थितियों के बारे में कुछ भी नहीं पता है, और हम किसी तरह इसे जानते हैं। मुख्य विचार विभिन्न कार्यों के लिए पुरस्कार, सकारात्मक या नकारात्मक पुरस्कार है।
फिर, पहली मुलाकात से, उसने मेरे दिमाग पर कब्जा कर लिया, महान और भयानक पंजा।
उसी समय मजाकिया और डरावना, वह अपने पंजे की एक मूर्खतापूर्ण लहर बनाता है, लेकिन उसे सीखने की ज़रूरत है कि कॉलेज जाने के लिए कैसे चलना है :) मैं व्याख्यान से
वीडियो का एक टुकड़ा संलग्न कर रहा हूं, यह अधिक समझ में आएगा। आगे देखते हुए, मैं कहूंगा कि पिछले प्रोजेक्ट में मैं अपने पालतू जानवरों को चलने के लिए सिखाने में कामयाब रहा।
ऑफटॉपिक और सपनेबस उस समय, हेक्सापॉड के बारे में उत्कृष्ट DIY वीडियो के साथ एक उत्कृष्ट
लेख हैबे पर चला गया। अब उसी को इकट्ठा करने का विचार मुझे सता रहा है (STMF4DISCOVERY एक गायरोस्कोप और एक्सेलेरोमीटर के साथ चारों ओर झूठ बोल रहा है, एक वाईफाई / ब्लूटूथ सीटी जुड़ी हुई है), और उसे सिखाने का प्रयास करें कि कैसे चलना है। बस यह देखने के लिए कि कीट छद्म जीवन कैसे झुलस रहा है। एह, अपने आप को मजबूर करने के लिए ...
ये दो विषय बल्कि जटिल लग रहे थे, उदाहरण के लिए, इष्टतम व्यवहार एक्सप्लोरेशन बनाम एक्सप्लोरेशन के संतुलन को कैसे पाया जाए, इस सवाल का जब कि क्या पर्याप्त सीखना है, तो यह ज्ञान प्राप्त करने के अनुसार कार्य करने का समय है।
प्रोजेक्ट 3 में, हम एक पीले रंग की रोटी के साथ भूलभुलैया से थोड़ा विचलित हो गए, तथाकथित ग्राउडवर्ल्ड की समस्याओं को हल किया।
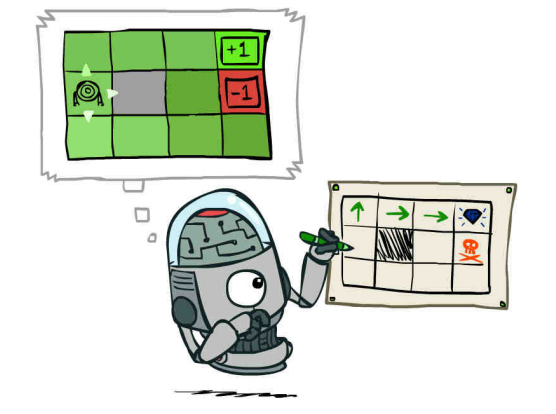
जब हम "उत्तर" और "पूर्व" के लिए एक ही समय पर कदम के साथ कुछ संभावना के साथ कुछ परिस्थितियों में जाने के लिए यह तय करना सबसे अच्छा है कि कैसे तय करें इस दुनिया की खोज की प्रक्रिया में कैसे व्यवहार करें? क्या अच्छा है, क्या बुरा है? कार्यान्वित एल्गोरिदम क्लॉ के लिए भी काम कर रहे हैं। थोड़ा डोपिलिवैनी - पेकमैन भी अध्ययन के लिए तैयार है। यह वापस जाना बहुत दिलचस्प हो गया और तुलना की कि हमारे सहकर्मी-हत्यारे ने भूतों के खिलाफ कई सौ खेलों में कैसे प्रशिक्षित किया। यहाँ यह दृष्टिकोणों का अंतर है, भूलभुलैया में गेम को हल करने के लिए ExpectiMax सर्च लिखें, या पेकमैन को सिखाएं कि कैसे जीतें।
फिनिश लाइन
अंतिम परीक्षा अभ्यास में परियोजना 3 को पूरा करने और खुद के लिए प्रशिक्षण के लिए एक सप्ताह दिया गया था, जिसके लिए ग्रेड को ध्यान में नहीं रखा गया था। अंतिम परीक्षा पास करने के लिए एक और सप्ताह का समय आवंटित किया गया था, 48 घंटे के गलियारे को चुनना संभव था, और उस समय शांत जवाब। यह एक प्लस और एक आरामदायक माइनस दोनों था। एक और क्रूर खोज, अधिकांश सवालों के जवाब देने का एक एकल प्रयास था (54 में से लगभग 40, अन्य ने दो प्रयास दिए)। और अगर ट्रू / फाल्स सीरीज़ के प्रश्नों में यह उचित है, तो कुछ अन्य में 4-6 चेकबॉक्स के साथ - यह परेशान करता है। उत्तर देने के दो प्रयासों के साथ यह सबसे आसान था। प्रश्नों ने पूरे पाठ्यक्रम को काफी कसकर कवर किया। व्याख्याताओं ने 2-5 घंटे पर परीक्षा का मूल्यांकन किया, मैंने 2 दिनों में लगभग 1 + 4 घंटे बिताए (मैंने धीरे से उत्तर दिया, कुछ स्थानों पर व्याख्यान की समीक्षा की), और मैं त्रुटियों के बिना परीक्षा उत्तीर्ण नहीं कर सका, अंतिम परिणाम (176/200)।
अपने इंप्रेशन को समाप्त या समाप्त करने के बजाय
बहुत दिलचस्प! व्याख्यान और परीक्षणों में, अजगर गंध नहीं करता है, लेकिन विशेष पैक्मैन परियोजनाओं में यह बहुत दृढ़ता से बदबू आ रही है। विशिष्ट समस्याओं को हल करने के लिए एक उपकरण के रूप में भाषा का उपयोग करने की पूर्ण भावना - मुझे लगता है कि यह अध्ययन के लिए बहुत अच्छा है। व्याख्याता द्वारा सामग्री की प्रस्तुति उत्कृष्ट है, और मुझे व्यक्तिगत रूप से समस्याओं को हल करने के लिए व्याख्यान में पर्याप्त जानकारी थी, हालांकि कुछ अतिरिक्त। सामग्री पाठ्यक्रम विकी में सूचीबद्ध हैं। मंच कई बार बहुत उपयोगी था। खैर, तकनीकी हिस्सा शीर्ष पर है, सब कुछ सुविधाजनक है, बटन, झंडे, उत्तर। यह ध्यान देने योग्य है कि समय सीमा से पहले रविवार की शाम को, ऑटो-ग्रेडर बहुत धीमा है (यह 20-30 मिनट तक कोड की जांच करता है)। यदि आप इसे सीधे वीडियो / प्रश्न अनुभाग के तहत देखते हैं, तो मंच धीमा हो जाता है, लेकिन यहां मैं अपनी पुरानी नेटबुक पर पाप करता हूं।
दुर्भाग्य से, youtube-dl के साथ खेलने के बाद, मुझे अभी भी समझ नहीं आया कि edx उपशीर्षक के साथ अपने लिए व्याख्यान कैसे प्राप्त करें, और youtube ऑटो-उपशीर्षक नहीं, यदि कोई व्यक्ति इस मुद्दे को हल करता है, तो plz लिखें।
मैंने व्याख्यान और होमवर्क पर सप्ताह में 4 घंटे और 10 घंटे (या शायद अधिक, यह गणना करना मुश्किल है) प्रत्येक परियोजना के लिए (1 बार 2 सप्ताह में) खर्च किया। मैंने अपने नोट खुद नहीं रखे, अब मुझे इसका थोड़ा अफसोस है।
खैर, CS188x टीम के ईस्टर अंडे ने एक विशेष आनंद दिया, जैसे:
if 0 == 1: print 'We are in a world of arithmetic pain'
एक बोनस के रूप में, मैंने व्याख्यान में वीडियो के लिए कई लिंक (समय के साथ) एकत्र किए जो कि रोबो-एआई के विभिन्न वास्तविक-विश्व अनुप्रयोगों को कवर करते हैं:
aibo फ़ुटबॉल ,
Google कार ,
शर्ट-तह रोबोट ,
टर्मिनेटर ,
aibo चलना सीखता है , एक
humanoid रोबोट चलना सीखता है । पाठ्यक्रम के छात्रों के लिए, यह सब कैसे एक ही क्रमादेशित है पर रहस्य का पर्दा थोड़ा खुला है।
पाठ्यक्रम के दूसरे भाग में, आपको वैसे भी साइन अप करना चाहिए!
प्रोफेसर क्लिन में मिलते हैं।