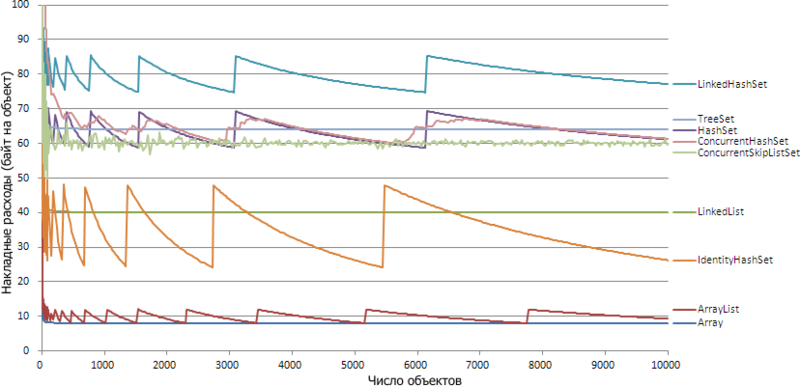
मैं सोच रहा था कि वस्तुओं को संग्रहीत करते समय कितने मेमोरी अतिरिक्त मेमोरी खाते हैं। मैंने लोकप्रिय संग्रह के लिए ओवरहेड मापन किया, जिसमें एक ही प्रकार (यानी, सूची और सेट) के तत्वों का भंडारण शामिल था और परिणामों को एक सामान्य अनुसूची में घटा दिया। यहाँ 64-बिट हॉटस्पॉट JVM (जावा 1.6) के लिए चित्र है:
लेकिन 32-बिट हॉटस्पॉट के लिए:
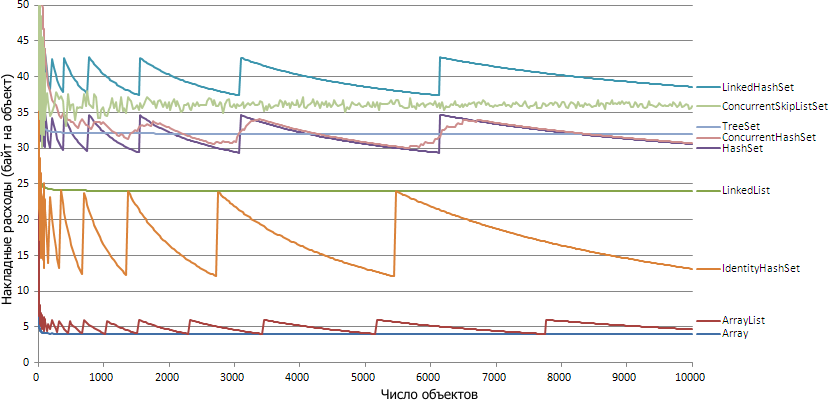
नीचे मैं आपको बताऊंगा कि कैसे माप लिया गया, और फिर यह पता लगाने की कोशिश करें कि चित्र इस तरह क्यों दिखते हैं।
सामग्री और तरीके
Java.util और java.util.concurrent से मानक जावा संग्रह के लिए माप लिया गया था, साथ ही एक नियमित जावा सरणी के लिए भी। IdentityHashSet और ConcurrentHashSet कलेक्शंस कलेक्शंस ।newSetFromMap () पद्धति का उपयोग करके संबंधित मानचित्र से बनाए जाते हैं। सभी संग्रह पहले तत्वों की संख्या को निर्दिष्ट किए बिना डिफ़ॉल्ट रूप से आरंभीकृत किए गए थे (अच्छी तरह से, सरणी के लिए, जिसके लिए यह आवश्यक है, को छोड़कर), और फिर वे ऐड विधि का उपयोग करके परीक्षण ऑब्जेक्ट्स से भर गए थे (और असाइनमेंट केवल सरणी के लिए प्रदर्शन किया गया था)। प्रत्येक प्रकार के लगभग 500 संग्रह 1 से 10,000 तक की एक अलग संख्या के तत्वों के साथ बनाए गए थे। एक तत्व के रूप में, यादृच्छिक अक्षरों से मिलकर यादृच्छिक लंबाई के 10,000 विभिन्न तारों का उपयोग किया गया था। सिद्धांत रूप में, तत्व खुद को केवल समवर्ती हाशसेट प्रभावित करते हैं, और फिर भी थोड़ा, इसलिए रेखांकन किसी भी डेटा के लिए समान दिखाई देगा।
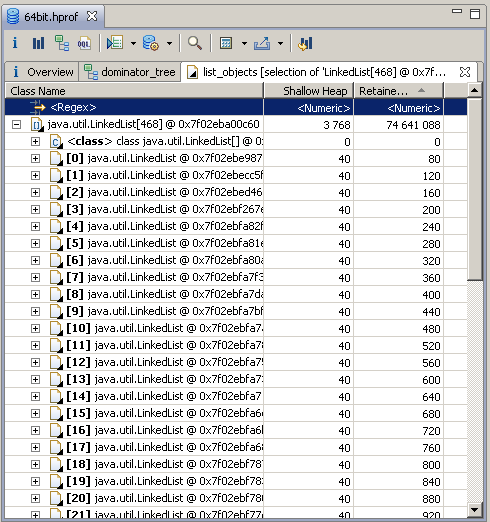
सरणियों में भरने के बाद, एक मेमोरी डंप प्रक्रिया से लिया गया था और एलेक्से मेमोरी मेमोरी एनालाइज़र का उपयोग करके विश्लेषण किया गया था, जो कि प्रत्येक संग्रह के रिटायर्ड सेट की गणना सही ढंग से करता था, न कि वस्तुओं को स्वयं सहित, लेकिन केवल ओवरहेड सहित। उदाहरण के लिए, यह इस तरह दिखता है:
खैर, फिर एक्सेल की नकल करना, सरल गणितीय संचालन और आलेखीय संपादक में थोड़ी अतिरिक्त ड्राइंग के साथ साजिश रचना।
परिणामों की चर्चा
यह देखा जा सकता है कि प्रत्येक संग्रह में ओवरहेड लागत और अधिक तत्वों के लिए एक निचली सीमा होती है, अधिक बार यह इसके करीब होता है। हालाँकि, कुछ संग्रहों के लिए यह नहीं कहा जा सकता है कि ओवरहेड फ़ंक्शन गणितीय अर्थों में इस सीमा में परिवर्तित होता है। उदाहरण के लिए, ArrayList, हालांकि यह तेजी से 8 बाइट्स (64 बिट के लिए) पर निकलता है, लेकिन यह प्रत्येक नए मेमोरी आवंटन के साथ 12 बाइट्स पर कूदता रहता है।
दिलचस्प बात यह है कि 32 बिट और 64 बिट के लिए ग्राफ बहुत समान हैं: अधिकांश संग्रह के लिए, ग्राफ़ दो अपवादों को छोड़कर आधे से भिन्न होता है: समवर्तीSkipListSet और LinkedList। प्रत्येक संग्रह पर व्यक्तिगत रूप से विचार करें और देखें कि ऐसा क्यों है।
सरणी
सबसे सरल विकल्प एक सरणी है जिसके लिए तत्वों की संख्या अग्रिम में ज्ञात है। इसमें, प्रत्येक ऑब्जेक्ट पर एक संदर्भ संग्रहीत किया जाता है: 4 (8) बाइट्स (कोष्ठक में मूल्य 64-बिट जेवीएम के लिए है), इसके अलावा, सरणी की लंबाई int, 4 बाइट्स है, और ऑब्जेक्ट डिस्क्रिप्टर 8 (16) बाइट्स है। इसके अलावा, प्रत्येक ऑब्जेक्ट को 8 बाइट्स द्वारा संरेखित किया जाता है, यही कारण है कि 32 बिट प्रति 4 एलिट खो देता है। परिणाम: 4 (8) बाइट्स प्रति ऑब्जेक्ट और 12 से 24 बाइट्स से एक स्थिर।
एक खाली सरणी 16 (24) बाइट्स में रहती है।
ArrayList
यहां यह मामूली अंतर के साथ लगभग समान है: चूंकि सरणी में तत्वों की संख्या अग्रिम रूप से ज्ञात नहीं है, सरणी को मार्जिन के साथ आवंटित किया गया है (डिफ़ॉल्ट रूप से 10 तत्वों द्वारा) और, यदि आवश्यक हो, तो डेढ़ गुना से थोड़ा अधिक विस्तार होता है:
int newCapacity = (oldCapacity * 3)/2 + 1;
इसलिए, ग्राफ़ 6 (12) बाइट्स पर कूदता है। स्थिरांक भी थोड़ा बड़ा होता है: 40 (64) बाइट्स के बाद से, ऐरे के अलावा एक एरियर लाईट ऑब्जेक्ट भी होता है, जो एरे के संदर्भ, सूची के वास्तविक आकार और संशोधनों की संख्या (एक समवर्ती वर्गीकरण को फेंकने के लिए) को संग्रहीत करता है। फिर भी, यह एक ही प्रकार का डेटा संग्रहीत करने का सबसे किफायती तरीका है, अगर आपको पहले से पता नहीं है कि वहाँ कितना होगा।
बिना तत्वों वाला एक डिफ़ॉल्ट निर्मित ArrayList 80 (144) बाइट लेता है।
LinkedList
एक लिंक की गई सूची के लिए, एक चित्र एक सरणी की तरह है: एक हाइपरबोले के लिए एक asymptote में जाता है। Java.util.LinkedList.Entry प्रकार की एक सेवा ऑब्जेक्ट प्रत्येक सूची आइटम के लिए बनाई गई है। इनमें से प्रत्येक ऑब्जेक्ट में तीन लिंक होते हैं (सूची आइटम के लिए, पिछली और बाद की प्रविष्टि के लिए), और 32 बिट में संरेखण के कारण, 4 बाइट्स खो जाते हैं, इसलिए अंत में प्रत्येक एंट्री के लिए 24 (40) बाइट्स की आवश्यकता होती है। निरंतर में लिंक्डलिस्ट ऑब्जेक्ट का हैंडल, हेड एंट्री और इसके साथ एक लिंक शामिल है, सूची का आकार और संशोधनों की संख्या 48 (80) बाइट्स है। खाली सूची एक ही राशि पर है, क्योंकि, निश्चित रूप से, यहां कोई मेमोरी आवंटित नहीं की गई है।
TreeSet
सामान्य तौर पर, सभी उपयोग किए गए सेट मैप पर आधारित होते हैं। कुछ मामलों में एक अलग कार्यान्वयन कुछ अधिक कॉम्पैक्ट हो सकता है, लेकिन सामान्य कोड, निश्चित रूप से, अधिक महत्वपूर्ण है।
ग्राफ भी एक लिंक्डलिस्ट और एक सरणी की तरह दिखता है। प्रत्येक तत्व के लिए, java.util.TreeMap.Entry ट्री ब्रांच बनाई जाती है, जिसमें पाँच लिंक होते हैं: की, वैल्यू, पेरेंट, लेफ्ट और राइट चाइल्ड। उनके अलावा, एक बूलियन चर संग्रहित होता है जो शाखा के रंग को इंगित करता है, लाल या काला (
लाल-काला पेड़ देखें )। एक एकल बूलियन चर में 4 बाइट्स लगते हैं, इसलिए पूरे रिकॉर्ड में 32 (64) बाइट्स लगते हैं।
TreeMap में निरंतर डेटा है: तुलनित्र का एक संदर्भ, पेड़ की जड़ का एक संदर्भ (लिंक्डलिस्ट में खगोलीय प्रविष्टि के विपरीत, जड़ का उपयोग अपने इच्छित उद्देश्य के लिए किया जाता है - सेट के वास्तविक तत्व को संदर्भित करता है), entrySet, navigableKeySet, descendingMap (इन वस्तुओं की मांग पर बनाया जाता है) के लिए लिंक। आकार और संशोधनों की संख्या। ट्रीपॉपर ऑब्जेक्ट डिस्क्रिप्टर के साथ, 48 (80) बाइट्स प्राप्त होते हैं। ट्रीसेट खुद ही अपने डिस्क्रिप्टर और ट्रीपैप का लिंक जोड़ता है। कुल में, 64 (104) बाइट्स आउटपुट हैं। खाली सेट का वज़न वही होता है। वैसे, मेमोरी की खपत पेड़ के संतुलन की डिग्री पर निर्भर नहीं करती है।
HashSet
HashSet HashMap पर आधारित है, जो TreeMap की तुलना में थोड़ा पेचीदा है। प्रत्येक तत्व के लिए, एक java.util.HashMap.Entry प्रविष्टि बनाई जाती है, जिसमें कुंजी का संदर्भ होता है, वह मान जो प्रविष्टि का अनुसरण करता है (यदि कई प्रविष्टियाँ हैश तालिका के समान सेल में आती हैं), साथ ही हैश मान भी। कुल मिलाकर, एंट्री का वजन 24 (48) बाइट होता है।
एंट्री के अलावा, एंट्री के लिंक के साथ एक हैश टेबल भी है, जिसमें शुरू में 16 तत्व होते हैं और युगल तब होते हैं जब तत्वों की संख्या इसके आकार का 75% से अधिक हो जाती है (75% डिफ़ॉल्ट लोडफ़ैक्टर मूल्य है, इसे कंस्ट्रक्टर में निर्दिष्ट किया जा सकता है)। अर्थात्, डिफ़ॉल्ट रूप से निर्माण करते समय, तालिका बढ़ाई जाती है जब तत्वों की संख्या 12, 24, 48, 96, आदि (2
एन * 3 से अधिक हो जाती है, ग्राफ पर अंतिम फट 6144 तत्व है)। वृद्धि के तुरंत बाद, तालिका 2 / 0.75 = 2.67 तत्वों की संख्या है, अर्थात, कुल खपत लगभग 34.67 (69.33) बाइट्स प्रति तत्व (स्थिर गणना नहीं) है। वृद्धि से ठीक पहले, तालिका केवल 1 / 0.75 = 1.33 तत्वों की संख्या है, और कुल खपत प्रति तत्व 29.33 (58.67) बाइट्स है। ध्यान दें कि मेमोरी का उपयोग पूरी तरह से स्वतंत्र है कि कितनी बार हैश टक्कर होती है।
जो लोग निरंतर घटक की गणना कर सकते हैं, मैं केवल यह कहूंगा कि डिफ़ॉल्ट प्रारंभिक खाली हाशसेट का वजन 136 (240) बाइट्स है।
LinkedHashSet
हशसेट में लगभग वैसा ही। यह java.util.LinkedHashMap.Entry का उपयोग करता है, जो java.util.HashMap.Entry को विरासत में मिलाता है, पिछले और अगले तत्वों के लिए दो लिंक जोड़ता है, इसलिए ग्राफ़ 8 (16) बाइट्स हैशेट से अधिक है, टेबल एक्सटेंशन 37.33 (74.67) तक पहुंचने से पहले। और उसके बाद - एक रिकॉर्ड 42.67 (85.33)। स्थिरांक भी बढ़ गया है, क्योंकि लिंक्डलिस्ट की तरह, हेड एंट्री संग्रहीत की जाती है, जो सेट के एक तत्व को संदर्भित नहीं करता है। हौसले से बनाई गई LinkedHashSet का वजन 176 (320) बाइट्स है।
IdentityHashSet (newSetFromMap के माध्यम से)
IdentityHashMap एक बहुत ही दिलचस्प बात है। यह मानक मैप अनुबंध का उल्लंघन करता है = = की तुलना में कुंजियों की तुलना करके और System.identityHashCode का उपयोग करके। यह दिलचस्प भी है क्योंकि यह एंट्री जैसी वस्तुओं का निर्माण नहीं करता है, लेकिन बस सभी कुंजियों और मूल्यों को एक सरणी में संग्रहीत करता है (समान तत्वों में चाबियाँ, विषम लोगों में मूल्य)। टकराव की स्थिति में, यह एक सूची नहीं बनाता है, लेकिन ऑब्जेक्ट को सरणी के साथ पहली मुक्त सेल में लिखता है। इसके लिए धन्यवाद, सभी सेटों के बीच रिकॉर्ड कम ओवरहेड लागत प्राप्त की जाती है।
IdentityHashMap हर बार सरणी का आकार 2/3 से अधिक पूर्ण होने पर दोहराता है (HashMap के विपरीत, यह गुणांक कॉन्फ़िगर करने योग्य नहीं है)। डिफ़ॉल्ट रूप से, एक सरणी 32 तत्वों के साथ बनाई गई है (अर्थात, सरणी का आकार 64 है)। तदनुसार, विस्तार तब होता है जब 21, 42, 85, 170, आदि ([2
एन / 3], ग्राफ में अंतिम उछाल 5461) से अधिक है। विस्तार से पहले, सरणी में IdentityHashMap में कुंजियों की तुलना में 3 गुना अधिक तत्व होते हैं, और विस्तार के बाद - 6 बार। इस प्रकार, ओवरहेड 12 (24) से 24 (48) बाइट्स प्रति तत्व है। डिफ़ॉल्ट रूप से एक खाली सेट काफी अधिक लेता है - 344 (656) बाइट्स, लेकिन पहले से ही नौ तत्वों के साथ यह सभी अन्य सेटों की तुलना में अधिक किफायती हो जाता है।
समवर्ती HashSet (newSetFromMap के माध्यम से)
ConcurrentHashMap पहला संग्रह है जिसमें चार्ट स्वयं तत्वों पर निर्भर करता है (या उनके हैश कार्यों पर)। मोटे तौर पर, यह एक निश्चित संख्या में सेगमेंट (डिफ़ॉल्ट रूप से 16) का एक सेट है, जिनमें से प्रत्येक हैशपॉप का एक तुल्यकालिक एनालॉग है। एक खंड का चयन करने के लिए संशोधित हैश कोड से बिट्स के हिस्से का उपयोग किया जाता है, विभिन्न खंडों तक पहुंच समानांतर में हो सकती है। सीमा में, ओवरहेड स्वयं हाशप के ओवरहेड के समान है, क्योंकि java.util.concurrent.ConcurrentHashMap.HashEntry java.util.HashMap.Entry के समान ही है। सेगमेंट के आकार में वृद्धि स्वतंत्र रूप से होती है, क्योंकि ग्राफ एक साथ नहीं बढ़ता है: पहला, वे सेगमेंट जिनमें अधिक तत्व बढ़ते हैं।
यह संग्रह प्रारंभिक आकार - 1304 (2328) बाइट्स के मामले में शीर्ष पर बाहर आया, क्योंकि 16 खंड तुरंत शुरू किए गए थे, जिनमें से प्रत्येक में 16 रिकॉर्ड और कई सहायक क्षेत्रों के साथ एक तालिका है। हालांकि, 10,000 तत्वों के लिए, समवर्ती हाशसेट हैसेट से केवल 0.3% बड़ा है।
ConcurrentSkipListSet
समवर्तीSkipListMap के माध्यम से लागू किया गया और, मेरी राय में, वर्णित संग्रह का सबसे जटिल है। एल्गोरिथ्म का विचार
हैबे पर वर्णित किया गया था, इसलिए यहां मैं विवरण में नहीं जाऊंगा। मैं केवल यह ध्यान देता हूं कि परिणामी मेमोरी का आकार डेटा से स्वतंत्र है, लेकिन गैर-नियतात्मक है, क्योंकि संग्रह को छद्म यादृच्छिक संख्या जनरेटर द्वारा शुरू किया गया है। अगले छद्म यादृच्छिक संख्या के आधार पर, एक निर्णय किया जाता है कि सूचकांक प्रविष्टि और कितने स्तरों को जोड़ा जाए। प्रत्येक तत्व के लिए, एक java.util.concurrent.ConcurrentSkipListMap.Node ऑब्जेक्ट आवश्यक रूप से बनाया गया है, जिसमें कुंजी, मान और अगले नोड का संदर्भ होता है, बस एक कनेक्ट की गई सूची बनाते हैं। यह प्रति तत्व 24 (40) बाइट्स देता है। इसके अलावा, लगभग एक सूचकांक प्रविष्टि (java.util.concurrent.ConcurrentSkipListMap.Index) हर दो तत्वों के लिए बनाई गई है (पहले स्तर पर हर चौथे रिकॉर्ड के लिए एक सूचकांक है, हर आठवें पर दूसरा, आदि)। प्रत्येक इंडेक्स एंट्री का वज़न Node जितना होता है (वहाँ भी तीन लिंक होते हैं), इसलिए कुल मिलाकर प्रत्येक तत्व के लिए लगभग 36 (60) बाइट्स की आवश्यकता होती है। प्रत्येक स्तर (हेडइंडेक्स) के लिए हेड रिकॉर्ड हैं, लेकिन उनमें से कुछ (तत्वों की संख्या का लगभग लघुगणक) हैं, इसलिए उन्हें उपेक्षित किया जा सकता है।
एक खाली समवर्तीSkipListSet में, एक HeadIndex और एक खाली नोड बनाए जाते हैं; डिफ़ॉल्ट रूप से निर्माण के बाद, संग्रह 112 (200) बाइट लेता है।
यह सब क्यों?
परिणाम काफी हद तक अप्रत्याशित थे और मेरे सहज विचारों का खंडन किया। इसलिए मैंने सोचा कि प्रतिस्पर्धी संग्रहों को नियमित संग्रहों की तुलना में बहुत अधिक होना चाहिए, और लिंक्डशैसेट को ट्रीसेट और हैशसेट के बीच कहीं स्थित होना चाहिए। यह भी आश्चर्यजनक था कि व्यावहारिक रूप से स्मृति की खपत वस्तुओं पर खुद निर्भर नहीं होती है: पेड़ के संतुलन की डिग्री या हैश तालिकाओं में टकराव की संख्या कुछ भी प्रभावित नहीं करती है और गैर-प्रतिस्पर्धी संग्रहों के लिए आप एक बाइट की सटीकता के साथ ओवरहेड के आकार को पूर्व-निर्धारित कर सकते हैं। विभिन्न संग्रहों की आंतरिक संरचना में तल्लीन करना दिलचस्प था। क्या इस अध्ययन में कोई ठोस व्यावहारिक लाभ है? मैं नहीं जानता, सभी को अपने लिए निर्णय लेने दें।