नमस्कार।
तंत्रिका नेटवर्क पर पाठ्यक्रम समाप्त हो गया है। अच्छा कोर्स, लेकिन ज्यादा अभ्यास नहीं। तो इस पोस्ट में हम एक
सीमित बोल्ट्जमान मशीन - एक
तंत्रिका नेटवर्क के एक
स्टोकेस्टिक ,
जनरेटिव मॉडल को देखेंगे, लिखेंगे और परीक्षण करेंगे। हम प्रोफेसर
जेफरी हिंटन द्वारा विकसित
कॉन्ट्रैस्टिव डाइवर्जेंस (सीडी-के) एल्गोरिथ्म का उपयोग करके उसे प्रशिक्षित करेंगे, जो उस पाठ्यक्रम का संचालन करता है। हम मुद्रित अंग्रेजी अक्षरों के एक सेट पर परीक्षण करेंगे। अगली पोस्ट में, हम त्रुटि बैक-प्रॉपेगोरिथम एल्गोरिथम की कमियों और बोल्ट्जमैन मशीन का उपयोग करके वज़न को कम करने की विधि पर विचार करेंगे। फार्मूले और पाठ की शीट से कौन डरता नहीं है, कृपया, बिल्ली के नीचे।
एक बहुत ही संक्षिप्त इतिहास
मैं विशेष रूप से सीमित बोल्ट्ज़मन मशीन (आरबीएम) की उत्पत्ति के इतिहास पर ध्यान केंद्रित नहीं करूंगा, मैं केवल यह उल्लेख करूंगा कि यह सभी
आवर्तक तंत्रिका नेटवर्क के साथ शुरू हुआ, जो कि प्रतिक्रिया नेटवर्क हैं जो कि प्रशिक्षित करना बहुत मुश्किल है। सीखने में इस मामूली कठिनाई के कारण, लोगों ने अधिक
सीमित पुनरावृत्ति मॉडल का आविष्कार करना शुरू किया, जिसके लिए सरल शिक्षण एल्गोरिदम लागू किया जा सकता था। इनमें से एक मॉडल
होपफील्ड न्यूरल नेटवर्क था , और उन्होंने
थर्मोरोग्यूलेशन के साथ तंत्रिका नेटवर्क की गतिशीलता की तुलना करके नेटवर्क ऊर्जा की अवधारणा पेश की:
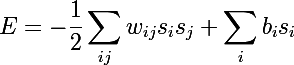
- डब्ल्यू - न्यूरॉन्स के बीच वजन
- बी - न्यूरॉन विस्थापन
- s न्यूरॉन की स्थिति है
आरबीएम के रास्ते में अगला कदम साधारण
बोल्ट्जमन मशीनें थीं , वे हॉपफील्ड नेटवर्क से अलग हैं कि वे
प्रकृति में स्टोकेस्टिक हैं , और न्यूरॉन्स को दो समूहों में विभाजित किया गया है, जो अवलोकन योग्य और छिपे हुए राज्यों का वर्णन करते हैं (
मार्कोव मॉडल के साथ सादृश्य द्वारा, जिस तरह से, हिंटन व्याख्यान में स्वीकार करते हैं वहाँ से उसने "छिपा हुआ" शब्द उधार लिया)। बोल्ट्जमैन मशीनों में ऊर्जा निम्नानुसार व्यक्त की जाती है:
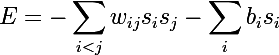
बोल्ट्जमैन मशीन एक पूरी तरह से जुड़ा हुआ अप्रत्यक्ष ग्राफ है, और इस प्रकार, एक ही समूह के किसी भी दो कोने एक दूसरे पर निर्भर करते हैं।

लेकिन अगर हम
द्विदलीय ग्राफ प्राप्त करने के लिए समूह के भीतर बंधों को हटाते हैं, तो हमें आरबीएम मॉडल की संरचना मिलती है।

इस मॉडल की ख़ासियत यह है कि एक समूह में न्यूरॉन्स की एक निश्चित अवस्था में, दूसरे समूह में न्यूरॉन्स की स्थिति एक दूसरे से स्वतंत्र होगी। अब हम एक सिद्धांत पर आगे बढ़ सकते हैं जहां यह संपत्ति एक महत्वपूर्ण भूमिका निभाती है।
व्याख्या और उद्देश्य
आरबीएम को मार्कोव के छिपे हुए मॉडल के समान समझा जाता है। हमारे पास कई राज्य हैं जो हम देख सकते हैं (दृश्यमान न्यूरॉन्स जो बाहरी वातावरण के साथ संवाद करने के लिए एक इंटरफ़ेस प्रदान करते हैं) और कई राज्य छिपे हुए हैं, और हम सीधे उनके राज्य (छिपे हुए न्यूरॉन्स) नहीं देख सकते हैं। लेकिन हम अव्यक्त राज्यों के बारे में एक संभाव्य निष्कर्ष निकाल सकते हैं, उन राज्यों के आधार पर जिन्हें हम देख सकते हैं। इस तरह के एक मॉडल को प्रशिक्षित करने के बाद, हमें छिपे हुए राज्यों के बारे में निष्कर्ष निकालने का अवसर भी मिलता है, छिपे हुए लोगों को जानने का (किसी ने
बेयस का प्रमेय = रद्द नहीं किया है), और इस तरह संभावना वितरण से डेटा उत्पन्न होता है जिस पर मॉडल प्रशिक्षित होता है।
इस प्रकार, हम मॉडल प्रशिक्षण के लक्ष्य को तैयार कर सकते हैं: मॉडल मापदंडों को समायोजित करना आवश्यक है ताकि प्रारंभिक अवस्था से पुनर्निर्मित वेक्टर मूल के सबसे करीब हो। पुनर्गठित को छिपा राज्यों से संभाव्य निष्कर्ष द्वारा प्राप्त वेक्टर को संदर्भित करता है, जो बदले में अवलोकन किए गए राज्यों से संभाव्य निष्कर्ष द्वारा प्राप्त किया जाता है, अर्थात्। मूल वेक्टर से।
सिद्धांत
हम निम्नलिखित संकेतन प्रस्तुत करते हैं:
- w_ij - i-th न्यूरॉन के बीच वजन
- a_i - दृश्यमान न्यूरॉन का विस्थापन
- b_j - छिपे हुए न्यूरॉन का विस्थापन
- v_i - दृश्यमान न्यूरॉन की स्थिति
- h_j - छिपे हुए न्यूरॉन की स्थिति
हम बाइनरी वैक्टर से मिलकर एक प्रशिक्षण सेट पर विचार करेंगे, लेकिन यह आसानी से वास्तविक संख्या के वैक्टर के लिए सामान्यीकृत किया जा सकता है। मान लीजिए कि हमारे पास दृश्यमान न्यूरॉन्स और मीटर छिपे हुए हैं। हम RBM के लिए ऊर्जा की अवधारणा का परिचय देते हैं:
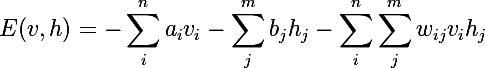
तंत्रिका नेटवर्क सभी प्रकार के जोड़े
v और
h की संयुक्त संभावना की गणना इस प्रकार करेगा:

जहां
Z निम्नलिखित फॉर्म का विभाजन फ़ंक्शन योग या सामान्य है (मान लें कि हमारे पास केवल एन छवियां हैं, और एम छवियां एच):

जाहिर है, वेक्टर
v की कुल संभावना की गणना सभी
एच से अधिक के योग द्वारा की जाएगी:

इस संभावना पर विचार करें कि किसी दिए गए
v में से किसी एक में छिपा हुआ
h_k = 1 है । ऐसा करने के लिए, एक न्यूरॉन की कल्पना करें, फिर 1 पर सिस्टम की ऊर्जा ई 1 होगी, और 0 पर यह ई 0 होगा, और संभावना 1 वर्तमान न्यूरॉन के रैखिक संयोजन के सिग्मॉइड फ़ंक्शन के बराबर होगी जिसमें परत के राज्य वेक्टर के साथ ऑफसेट की जांच की जाएगी:
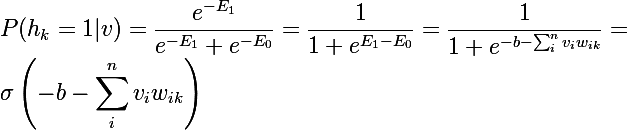
और चूंकि दिए गए
v के लिए सभी
h_k एक दूसरे से स्वतंत्र हैं, तो:

किसी दिए गए
h के लिए प्रायिकता
v के समान निष्कर्ष निकाला जाता है।
जैसा कि हम याद करते हैं, प्रशिक्षण का लक्ष्य पुनर्निर्मित वेक्टर को मूल के सबसे करीब बनाना है, या, दूसरे शब्दों में, संभावना
p (v) को अधिकतम करना है। इसके लिए, मॉडल मापदंडों के संबंध में संभाव्यता के आंशिक डेरिवेटिव की गणना करना आवश्यक है। आइए, मॉडल मापदंडों के अनुसार ऊर्जा के विभेदन के साथ शुरुआत करें:
हमें नकारात्मक ऊर्जा के प्रतिपादक के व्युत्पन्न की भी आवश्यकता होगी:
हम विभाजन फ़ंक्शन को अलग करते हैं:
हम लगभग वहाँ हैं -) भार के संबंध में संभाव्यता
v के आंशिक व्युत्पन्न पर विचार करें:
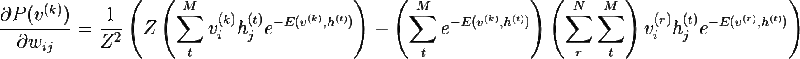
जाहिर है, प्रायिकता को अधिकतम करना संभाव्यता के लघुगणक को अधिकतम करने के समान है, यह ट्रिक आपको एक सुंदर समाधान में आने में मदद करेगी। वजन द्वारा प्राकृतिक लघुगणक के व्युत्पन्न पर विचार करें:
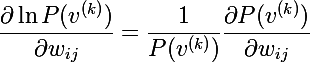
अंतिम दो सूत्रों को मिलाकर, हम निम्नलिखित अभिव्यक्ति प्राप्त करते हैं:
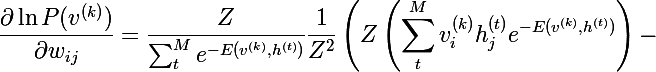
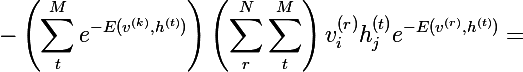

प्रत्येक शब्द के अंश और हर को
Z से गुणा करना और इसे संभावनाओं तक सरल करना, हम निम्नलिखित अभिव्यक्ति प्राप्त करते हैं:

और
गणितीय अपेक्षा की परिभाषा से
, हम अंतिम अभिव्यक्ति प्राप्त करते हैं (वर्ग ब्रैकेट के सामने एम अपेक्षा का संकेत है):
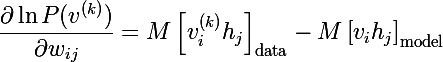
न्यूरॉन्स के विस्थापन के संबंध में डेरिवेटिव समान रूप से व्युत्पन्न हैं:
और अंत में, मॉडल मापदंडों को अपडेट करने के लिए तीन नियम हैं, जहां
यह सीखने की गति है:
इंडेक्स में पीएस फ्राई गलत हो सकता है, एक हब पर कोई अंतर्निहित नहीं है  संपादक =)
संपादक =)लर्निंग एल्गोरिथम कॉन्ट्रास्टिव डाइवर्जेंस
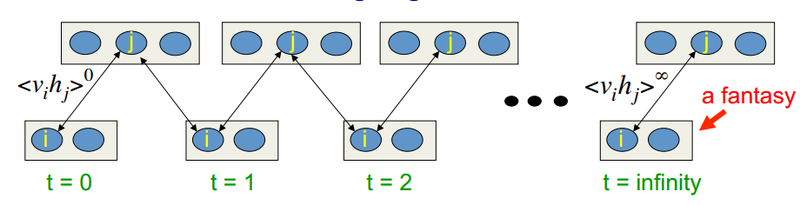
यह एल्गोरिथ्म 2002 में प्रोफेसर हिंटन द्वारा आविष्कार किया गया था, और यह इसकी सादगी के लिए उल्लेखनीय है। मुख्य विचार यह है कि गणितीय उम्मीदों को अच्छी तरह से परिभाषित मूल्यों से बदल दिया जाता है। नमूना प्रक्रिया की अवधारणा पेश की गई है (गिब्स नमूना, आप एसोसिएशन को देखने के लिए
यहां देख सकते हैं)। सीडी-के प्रक्रिया इस प्रकार है:
- दृश्यमान न्यूरॉन्स की स्थिति इनपुट छवि के बराबर होती है
- छिपी हुई राज्य सम्भावनाएँ व्युत्पन्न हैं
- छिपी हुई परत के प्रत्येक न्यूरॉन को "1" की एक स्थिति सौंपी जाती है, जिसमें इसकी वर्तमान स्थिति के बराबर संभावना होती है
- छिपी हुई परत की संभावनाएं छिपे के आधार पर निकाली गई हैं
- यदि वर्तमान पुनरावृत्ति k से कम है, तो चरण 2 पर लौटें
- छिपी हुई राज्य सम्भावनाएँ व्युत्पन्न हैं
हिंटन के व्याख्यानों में, ऐसा दिखता है:
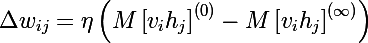
यानी हम जितनी देर तक सैंपलिंग करेंगे, हमारी ग्रेडियंट उतनी ही सटीक होगी। इसी समय, प्रोफेसर का दावा है कि सीडी -1 (नमूनाकरण का सिर्फ एक पुनरावृत्ति) के लिए भी, काफी अच्छा परिणाम पहले से ही प्राप्त हुआ है। पहले शब्द को
सकारात्मक चरण कहा जाता है, और दूसरे को ऋण चिन्ह के साथ
ऋणात्मक चरण कहा जाता है।
बात सस्ती है। मुझे कोड दिखाओ।
के रूप में
backpropagation एल्गोरिथ्म के
कार्यान्वयन में , मैं लगभग एक ही इंटरफेस का उपयोग करें। तो, चलो तुरंत एक तंत्रिका नेटवर्क के प्रशिक्षण के कार्य पर विचार करें। हम जड़ता के क्षण का उपयोग करके प्रशिक्षण को लागू करेंगे।
public void Train(IMultilayerNeuralNetwork network, IList<DataItem> data)
, . , .
LearningAlgorithmConfig config = new LearningAlgorithmConfig() { BatchSize = 10, // MaxEpoches = 1000, // GibbsSamplingChainLength = 30, // k CD-k LearningRate = 0.01, // CostFunctionRecalculationStep = 1, // Momentum = 0.9, // MinError = 0, // MinErrorChange = 0, // UseBiases = true // };
.
ILayer visibleLayer = network.Layers[0]; // RBM , ILayer hiddenLayer = network.Layers[1]; // if (!_config.UseBiases) // { for (int i = 0; i < visibleLayer.Neurons.Length; i++) { visibleLayer.Neurons[i].Bias = 0d; } for (int i = 0; i < hiddenLayer.Neurons.Length; i++) { hiddenLayer.Neurons[i].Bias = 0d; } } //init momentum // double[,] momentumSpeedWeights = new double[visibleLayer.Neurons.Length, hiddenLayer.Neurons.Length]; double[] momentumSpeedVisibleBiases = new double[visibleLayer.Neurons.Length]; double[] momentumSpeedHiddenBiases = new double[hiddenLayer.Neurons.Length]; //init stop factors bool stopFlag = false; double lastError = Double.MaxValue; // , double lastErrorChange = double.MaxValue; double learningRate = _config.LearningRate; int currentEpoche = 0; BatchEnumerator<DataItem<double>> batchEnumerator = new BatchEnumerator<DataItem<double>>(data, _config.BatchSize, true);
BatchEnumerator' , .
:
do { DateTime dtStart = DateTime.Now; //start batch processing foreach (IList<DataItem<double>> batch in batchEnumerator) { //batch gradient // , / double[,] nablaWeights = new double[visibleLayer.Neurons.Length, hiddenLayer.Neurons.Length]; double[] nablaHiddenBiases = new double[hiddenLayer.Neurons.Length]; double[] nablaVisibleBiases = new double[visibleLayer.Neurons.Length]; #region iterate through batch //... #endregion #region compute mean of wights nabla, and update them //... #endregion } #region Logging and error calculation //... #endregion // currentEpoche++; if (currentEpoche >= _config.MaxEpoches) { stopFlag = true; Logger.Instance.Log("Stop: currentEpoche:" + currentEpoche + " >= _config.MaxEpoches:" + _config.MaxEpoches); } else if (_config.MinError >= lastError) { stopFlag = true; Logger.Instance.Log("Stop: _config.MinError:" + _config.MinError + " >= lastError:" + lastError); } else if (_config.MinErrorChange >= lastErrorChange) { stopFlag = true; Logger.Instance.Log("Stop: _config.MinErrorChange:" + _config.MinErrorChange + " >= lastErrorChange:" + lastErrorChange); } } while (!stopFlag);
, Gibbs sampling, .
#region iterate through batch // foreach (DataItem<double> dataItem in batch) { //init visible layer states // / for (int i = 0; i < dataItem.Input.Length; i++) { visibleLayer.Neurons[i].LastState = dataItem.Input[i]; } #region Gibbs sampling for (int k = 0; k <= _config.GibbsSamplingChainLength; k++) { //calculate hidden states probabilities // , hiddenLayer.Compute(); #region accumulate negative phase // - , if (k == _config.GibbsSamplingChainLength) { for (int i = 0; i < visibleLayer.Neurons.Length; i++) { for (int j = 0; j < hiddenLayer.Neurons.Length; j++) { // nablaWeights[i, j] -= visibleLayer.Neurons[i].LastState * hiddenLayer.Neurons[j].LastState; } } if (_config.UseBiases) { for (int i = 0; i < hiddenLayer.Neurons.Length; i++) { nablaHiddenBiases[i] -= hiddenLayer.Neurons[i].LastState; } for (int i = 0; i < visibleLayer.Neurons.Length; i++) { nablaVisibleBiases[i] -= visibleLayer.Neurons[i].LastState; } } break; } #endregion //sample hidden states // , , , Gibbs sampling for (int i = 0; i < hiddenLayer.Neurons.Length; i++) { hiddenLayer.Neurons[i].LastState = _r.NextDouble() <= hiddenLayer.Neurons[i].LastState ? 1d : 0d; } #region accumulate positive phase // , if (k == 0) { for (int i = 0; i < visibleLayer.Neurons.Length; i++) { for (int j = 0; j < hiddenLayer.Neurons.Length; j++) { nablaWeights[i, j] += visibleLayer.Neurons[i].LastState* hiddenLayer.Neurons[j].LastState; } } if (_config.UseBiases) { for (int i = 0; i < hiddenLayer.Neurons.Length; i++) { nablaHiddenBiases[i] += hiddenLayer.Neurons[i].LastState; } for (int i = 0; i < visibleLayer.Neurons.Length; i++) { nablaVisibleBiases[i] += visibleLayer.Neurons[i].LastState; } } } #endregion //calculate visible probs // visibleLayer.Compute(); // , , , . ; //todo: may be not do sampling, like in 3.2 of http://www.cs.toronto.edu/~hinton/absps/guideTR.pdf //sample visible //for (int i = 0; i < visibleLayer.Neurons.Length; i++) //{ // visibleLayer.Neurons[i].LastState = _r.NextDouble() <= visibleLayer.Neurons[i].LastState ? 1d : 0d; //} } #endregion }
, . : ( ) . .

#region compute mean of wights nabla, and update them for (int i = 0; i < visibleLayer.Neurons.Length; i++) { for (int j = 0; j < hiddenLayer.Neurons.Length; j++) { // , momentumSpeedWeights[i, j] = _config.Momentum*momentumSpeedWeights[i, j] + nablaWeights[i, j]/batch.Count; // visibleLayer.Neurons[i].Weights[j] += learningRate * momentumSpeedWeights[i, j]; hiddenLayer.Neurons[j].Weights[i] = visibleLayer.Neurons[i].Weights[j]; } } if (_config.UseBiases) { for (int i = 0; i < hiddenLayer.Neurons.Length; i++) { momentumSpeedHiddenBiases[i] = _config.Momentum*momentumSpeedHiddenBiases[i] + nablaHiddenBiases[i]/batch.Count; hiddenLayer.Neurons[i].Bias += learningRate * momentumSpeedHiddenBiases[i]; } for (int i = 0; i < visibleLayer.Neurons.Length; i++) { momentumSpeedVisibleBiases[i] = _config.Momentum*momentumSpeedVisibleBiases[i] + nablaVisibleBiases[i]/batch.Count; visibleLayer.Neurons[i].Bias += learningRate * momentumSpeedVisibleBiases[i]; } }
- . , , / , , , . : . , , , . .
#region Logging and error calculation string msg = "Epoche #" + currentEpoche; #region calculate error if (currentEpoche % _config.CostFunctionRecalculationStep == 0) { #region calculating squared error with reconstruction IMetrics<double> sed = MetricsCreator.SquareEuclideanDistance(); double d = 0; foreach (DataItem<double> dataItem in data) { d += sed.Calculate(dataItem.Input, network.ComputeOutput(dataItem.Input)); } msg += "; SqDist is " + d; lastErrorChange = Math.Abs(lastError - d); lastError = d; #endregion } #endregion msg += "; Time: " + (DateTime.Now - dtStart).Duration().ToString(); Logger.Instance.Log(msg);
.
RBM
. , , , ( 260 29 29 ): .
:
LearningAlgorithmConfig:
LearningRate = 0.01
BatchSize = 10
RegularizationFactor = 0
MaxEpoches = 1000
MinError = 0
MinErrorChange = 0
CostFunctionRecalculationStep = 1
ErrorFunction =
Momentum = 0.9
NeuronLocalGainLimit: not setted
GibbsSamplingChainLength = 30
UseBiases = True
, 1000 . .. 10, 26 , 26000 . .
, (26 ) 13128, 76.
( , ):

:

, ( RBM).
, - , . , . 841 (29*29) . , 841 29 29 , , . , , , . :

MNIST : http://deeplearning.net/tutorial/_images/filters_at_epoch_14.png . , =)
RBM , , .
https://class.coursera.org/neuralnets-2012-001/ http://www.cs.toronto.edu/~hinton/absps/guideTR.pdf http://deeplearning.net/tutorial/rbm.html#contrastive-divergence-cd-k http://www.iro.umontreal.ca/~lisa/twiki/bin/view.cgi/Public/DBNEquations http://www.cs.toronto.edu/~kriz/learning-features-2009-TR.pdf
PS ambikontur !
UPD :


public void Train(IMultilayerNeuralNetwork network, IList<DataItem> data)
, . , .
LearningAlgorithmConfig config = new LearningAlgorithmConfig() { BatchSize = 10, // MaxEpoches = 1000, // GibbsSamplingChainLength = 30, // k CD-k LearningRate = 0.01, // CostFunctionRecalculationStep = 1, // Momentum = 0.9, // MinError = 0, // MinErrorChange = 0, // UseBiases = true // };
.
ILayer visibleLayer = network.Layers[0]; // RBM , ILayer hiddenLayer = network.Layers[1]; // if (!_config.UseBiases) // { for (int i = 0; i < visibleLayer.Neurons.Length; i++) { visibleLayer.Neurons[i].Bias = 0d; } for (int i = 0; i < hiddenLayer.Neurons.Length; i++) { hiddenLayer.Neurons[i].Bias = 0d; } } //init momentum // double[,] momentumSpeedWeights = new double[visibleLayer.Neurons.Length, hiddenLayer.Neurons.Length]; double[] momentumSpeedVisibleBiases = new double[visibleLayer.Neurons.Length]; double[] momentumSpeedHiddenBiases = new double[hiddenLayer.Neurons.Length]; //init stop factors bool stopFlag = false; double lastError = Double.MaxValue; // , double lastErrorChange = double.MaxValue; double learningRate = _config.LearningRate; int currentEpoche = 0; BatchEnumerator<DataItem<double>> batchEnumerator = new BatchEnumerator<DataItem<double>>(data, _config.BatchSize, true);
BatchEnumerator' , .
:
do { DateTime dtStart = DateTime.Now; //start batch processing foreach (IList<DataItem<double>> batch in batchEnumerator) { //batch gradient // , / double[,] nablaWeights = new double[visibleLayer.Neurons.Length, hiddenLayer.Neurons.Length]; double[] nablaHiddenBiases = new double[hiddenLayer.Neurons.Length]; double[] nablaVisibleBiases = new double[visibleLayer.Neurons.Length]; #region iterate through batch //... #endregion #region compute mean of wights nabla, and update them //... #endregion } #region Logging and error calculation //... #endregion // currentEpoche++; if (currentEpoche >= _config.MaxEpoches) { stopFlag = true; Logger.Instance.Log("Stop: currentEpoche:" + currentEpoche + " >= _config.MaxEpoches:" + _config.MaxEpoches); } else if (_config.MinError >= lastError) { stopFlag = true; Logger.Instance.Log("Stop: _config.MinError:" + _config.MinError + " >= lastError:" + lastError); } else if (_config.MinErrorChange >= lastErrorChange) { stopFlag = true; Logger.Instance.Log("Stop: _config.MinErrorChange:" + _config.MinErrorChange + " >= lastErrorChange:" + lastErrorChange); } } while (!stopFlag);
, Gibbs sampling, .
#region iterate through batch // foreach (DataItem<double> dataItem in batch) { //init visible layer states // / for (int i = 0; i < dataItem.Input.Length; i++) { visibleLayer.Neurons[i].LastState = dataItem.Input[i]; } #region Gibbs sampling for (int k = 0; k <= _config.GibbsSamplingChainLength; k++) { //calculate hidden states probabilities // , hiddenLayer.Compute(); #region accumulate negative phase // - , if (k == _config.GibbsSamplingChainLength) { for (int i = 0; i < visibleLayer.Neurons.Length; i++) { for (int j = 0; j < hiddenLayer.Neurons.Length; j++) { // nablaWeights[i, j] -= visibleLayer.Neurons[i].LastState * hiddenLayer.Neurons[j].LastState; } } if (_config.UseBiases) { for (int i = 0; i < hiddenLayer.Neurons.Length; i++) { nablaHiddenBiases[i] -= hiddenLayer.Neurons[i].LastState; } for (int i = 0; i < visibleLayer.Neurons.Length; i++) { nablaVisibleBiases[i] -= visibleLayer.Neurons[i].LastState; } } break; } #endregion //sample hidden states // , , , Gibbs sampling for (int i = 0; i < hiddenLayer.Neurons.Length; i++) { hiddenLayer.Neurons[i].LastState = _r.NextDouble() <= hiddenLayer.Neurons[i].LastState ? 1d : 0d; } #region accumulate positive phase // , if (k == 0) { for (int i = 0; i < visibleLayer.Neurons.Length; i++) { for (int j = 0; j < hiddenLayer.Neurons.Length; j++) { nablaWeights[i, j] += visibleLayer.Neurons[i].LastState* hiddenLayer.Neurons[j].LastState; } } if (_config.UseBiases) { for (int i = 0; i < hiddenLayer.Neurons.Length; i++) { nablaHiddenBiases[i] += hiddenLayer.Neurons[i].LastState; } for (int i = 0; i < visibleLayer.Neurons.Length; i++) { nablaVisibleBiases[i] += visibleLayer.Neurons[i].LastState; } } } #endregion //calculate visible probs // visibleLayer.Compute(); // , , , . ; //todo: may be not do sampling, like in 3.2 of http://www.cs.toronto.edu/~hinton/absps/guideTR.pdf //sample visible //for (int i = 0; i < visibleLayer.Neurons.Length; i++) //{ // visibleLayer.Neurons[i].LastState = _r.NextDouble() <= visibleLayer.Neurons[i].LastState ? 1d : 0d; //} } #endregion }
, . : ( ) . .
#region compute mean of wights nabla, and update them for (int i = 0; i < visibleLayer.Neurons.Length; i++) { for (int j = 0; j < hiddenLayer.Neurons.Length; j++) { // , momentumSpeedWeights[i, j] = _config.Momentum*momentumSpeedWeights[i, j] + nablaWeights[i, j]/batch.Count; // visibleLayer.Neurons[i].Weights[j] += learningRate * momentumSpeedWeights[i, j]; hiddenLayer.Neurons[j].Weights[i] = visibleLayer.Neurons[i].Weights[j]; } } if (_config.UseBiases) { for (int i = 0; i < hiddenLayer.Neurons.Length; i++) { momentumSpeedHiddenBiases[i] = _config.Momentum*momentumSpeedHiddenBiases[i] + nablaHiddenBiases[i]/batch.Count; hiddenLayer.Neurons[i].Bias += learningRate * momentumSpeedHiddenBiases[i]; } for (int i = 0; i < visibleLayer.Neurons.Length; i++) { momentumSpeedVisibleBiases[i] = _config.Momentum*momentumSpeedVisibleBiases[i] + nablaVisibleBiases[i]/batch.Count; visibleLayer.Neurons[i].Bias += learningRate * momentumSpeedVisibleBiases[i]; } }
- . , , / , , , . : . , , , . .
#region Logging and error calculation string msg = "Epoche #" + currentEpoche; #region calculate error if (currentEpoche % _config.CostFunctionRecalculationStep == 0) { #region calculating squared error with reconstruction IMetrics<double> sed = MetricsCreator.SquareEuclideanDistance(); double d = 0; foreach (DataItem<double> dataItem in data) { d += sed.Calculate(dataItem.Input, network.ComputeOutput(dataItem.Input)); } msg += "; SqDist is " + d; lastErrorChange = Math.Abs(lastError - d); lastError = d; #endregion } #endregion msg += "; Time: " + (DateTime.Now - dtStart).Duration().ToString(); Logger.Instance.Log(msg);
.
RBM
. , , , ( 260 29 29 ): .
:
LearningAlgorithmConfig:
LearningRate = 0.01
BatchSize = 10
RegularizationFactor = 0
MaxEpoches = 1000
MinError = 0
MinErrorChange = 0
CostFunctionRecalculationStep = 1
ErrorFunction =
Momentum = 0.9
NeuronLocalGainLimit: not setted
GibbsSamplingChainLength = 30
UseBiases = True
, 1000 . .. 10, 26 , 26000 . .
, (26 ) 13128, 76.
( , ):
:
, ( RBM).
, - , . , . 841 (29*29) . , 841 29 29 , , . , , , . :
MNIST : http://deeplearning.net/tutorial/_images/filters_at_epoch_14.png . , =)
RBM , , .
https://class.coursera.org/neuralnets-2012-001/ http://www.cs.toronto.edu/~hinton/absps/guideTR.pdf http://deeplearning.net/tutorial/rbm.html#contrastive-divergence-cd-k http://www.iro.umontreal.ca/~lisa/twiki/bin/view.cgi/Public/DBNEquations http://www.cs.toronto.edu/~kriz/learning-features-2009-TR.pdf
PS ambikontur !
UPD :
public void Train(IMultilayerNeuralNetwork network, IList<DataItem> data)
, . , .
LearningAlgorithmConfig config = new LearningAlgorithmConfig() { BatchSize = 10, // MaxEpoches = 1000, // GibbsSamplingChainLength = 30, // k CD-k LearningRate = 0.01, // CostFunctionRecalculationStep = 1, // Momentum = 0.9, // MinError = 0, // MinErrorChange = 0, // UseBiases = true // };
.
ILayer visibleLayer = network.Layers[0]; // RBM , ILayer hiddenLayer = network.Layers[1]; // if (!_config.UseBiases) // { for (int i = 0; i < visibleLayer.Neurons.Length; i++) { visibleLayer.Neurons[i].Bias = 0d; } for (int i = 0; i < hiddenLayer.Neurons.Length; i++) { hiddenLayer.Neurons[i].Bias = 0d; } } //init momentum // double[,] momentumSpeedWeights = new double[visibleLayer.Neurons.Length, hiddenLayer.Neurons.Length]; double[] momentumSpeedVisibleBiases = new double[visibleLayer.Neurons.Length]; double[] momentumSpeedHiddenBiases = new double[hiddenLayer.Neurons.Length]; //init stop factors bool stopFlag = false; double lastError = Double.MaxValue; // , double lastErrorChange = double.MaxValue; double learningRate = _config.LearningRate; int currentEpoche = 0; BatchEnumerator<DataItem<double>> batchEnumerator = new BatchEnumerator<DataItem<double>>(data, _config.BatchSize, true);
BatchEnumerator' , .
:
do { DateTime dtStart = DateTime.Now; //start batch processing foreach (IList<DataItem<double>> batch in batchEnumerator) { //batch gradient // , / double[,] nablaWeights = new double[visibleLayer.Neurons.Length, hiddenLayer.Neurons.Length]; double[] nablaHiddenBiases = new double[hiddenLayer.Neurons.Length]; double[] nablaVisibleBiases = new double[visibleLayer.Neurons.Length]; #region iterate through batch //... #endregion #region compute mean of wights nabla, and update them //... #endregion } #region Logging and error calculation //... #endregion // currentEpoche++; if (currentEpoche >= _config.MaxEpoches) { stopFlag = true; Logger.Instance.Log("Stop: currentEpoche:" + currentEpoche + " >= _config.MaxEpoches:" + _config.MaxEpoches); } else if (_config.MinError >= lastError) { stopFlag = true; Logger.Instance.Log("Stop: _config.MinError:" + _config.MinError + " >= lastError:" + lastError); } else if (_config.MinErrorChange >= lastErrorChange) { stopFlag = true; Logger.Instance.Log("Stop: _config.MinErrorChange:" + _config.MinErrorChange + " >= lastErrorChange:" + lastErrorChange); } } while (!stopFlag);
, Gibbs sampling, .
#region iterate through batch // foreach (DataItem<double> dataItem in batch) { //init visible layer states // / for (int i = 0; i < dataItem.Input.Length; i++) { visibleLayer.Neurons[i].LastState = dataItem.Input[i]; } #region Gibbs sampling for (int k = 0; k <= _config.GibbsSamplingChainLength; k++) { //calculate hidden states probabilities // , hiddenLayer.Compute(); #region accumulate negative phase // - , if (k == _config.GibbsSamplingChainLength) { for (int i = 0; i < visibleLayer.Neurons.Length; i++) { for (int j = 0; j < hiddenLayer.Neurons.Length; j++) { // nablaWeights[i, j] -= visibleLayer.Neurons[i].LastState * hiddenLayer.Neurons[j].LastState; } } if (_config.UseBiases) { for (int i = 0; i < hiddenLayer.Neurons.Length; i++) { nablaHiddenBiases[i] -= hiddenLayer.Neurons[i].LastState; } for (int i = 0; i < visibleLayer.Neurons.Length; i++) { nablaVisibleBiases[i] -= visibleLayer.Neurons[i].LastState; } } break; } #endregion //sample hidden states // , , , Gibbs sampling for (int i = 0; i < hiddenLayer.Neurons.Length; i++) { hiddenLayer.Neurons[i].LastState = _r.NextDouble() <= hiddenLayer.Neurons[i].LastState ? 1d : 0d; } #region accumulate positive phase // , if (k == 0) { for (int i = 0; i < visibleLayer.Neurons.Length; i++) { for (int j = 0; j < hiddenLayer.Neurons.Length; j++) { nablaWeights[i, j] += visibleLayer.Neurons[i].LastState* hiddenLayer.Neurons[j].LastState; } } if (_config.UseBiases) { for (int i = 0; i < hiddenLayer.Neurons.Length; i++) { nablaHiddenBiases[i] += hiddenLayer.Neurons[i].LastState; } for (int i = 0; i < visibleLayer.Neurons.Length; i++) { nablaVisibleBiases[i] += visibleLayer.Neurons[i].LastState; } } } #endregion //calculate visible probs // visibleLayer.Compute(); // , , , . ; //todo: may be not do sampling, like in 3.2 of http://www.cs.toronto.edu/~hinton/absps/guideTR.pdf //sample visible //for (int i = 0; i < visibleLayer.Neurons.Length; i++) //{ // visibleLayer.Neurons[i].LastState = _r.NextDouble() <= visibleLayer.Neurons[i].LastState ? 1d : 0d; //} } #endregion }
, . : ( ) . .
#region compute mean of wights nabla, and update them for (int i = 0; i < visibleLayer.Neurons.Length; i++) { for (int j = 0; j < hiddenLayer.Neurons.Length; j++) { // , momentumSpeedWeights[i, j] = _config.Momentum*momentumSpeedWeights[i, j] + nablaWeights[i, j]/batch.Count; // visibleLayer.Neurons[i].Weights[j] += learningRate * momentumSpeedWeights[i, j]; hiddenLayer.Neurons[j].Weights[i] = visibleLayer.Neurons[i].Weights[j]; } } if (_config.UseBiases) { for (int i = 0; i < hiddenLayer.Neurons.Length; i++) { momentumSpeedHiddenBiases[i] = _config.Momentum*momentumSpeedHiddenBiases[i] + nablaHiddenBiases[i]/batch.Count; hiddenLayer.Neurons[i].Bias += learningRate * momentumSpeedHiddenBiases[i]; } for (int i = 0; i < visibleLayer.Neurons.Length; i++) { momentumSpeedVisibleBiases[i] = _config.Momentum*momentumSpeedVisibleBiases[i] + nablaVisibleBiases[i]/batch.Count; visibleLayer.Neurons[i].Bias += learningRate * momentumSpeedVisibleBiases[i]; } }
- . , , / , , , . : . , , , . .
#region Logging and error calculation string msg = "Epoche #" + currentEpoche; #region calculate error if (currentEpoche % _config.CostFunctionRecalculationStep == 0) { #region calculating squared error with reconstruction IMetrics<double> sed = MetricsCreator.SquareEuclideanDistance(); double d = 0; foreach (DataItem<double> dataItem in data) { d += sed.Calculate(dataItem.Input, network.ComputeOutput(dataItem.Input)); } msg += "; SqDist is " + d; lastErrorChange = Math.Abs(lastError - d); lastError = d; #endregion } #endregion msg += "; Time: " + (DateTime.Now - dtStart).Duration().ToString(); Logger.Instance.Log(msg);
.
RBM
. , , , ( 260 29 29 ): .
:
LearningAlgorithmConfig:
LearningRate = 0.01
BatchSize = 10
RegularizationFactor = 0
MaxEpoches = 1000
MinError = 0
MinErrorChange = 0
CostFunctionRecalculationStep = 1
ErrorFunction =
Momentum = 0.9
NeuronLocalGainLimit: not setted
GibbsSamplingChainLength = 30
UseBiases = True
, 1000 . .. 10, 26 , 26000 . .
, (26 ) 13128, 76.
( , ):
:
, ( RBM).
, - , . , . 841 (29*29) . , 841 29 29 , , . , , , . :
MNIST : http://deeplearning.net/tutorial/_images/filters_at_epoch_14.png . , =)
RBM , , .
https://class.coursera.org/neuralnets-2012-001/ http://www.cs.toronto.edu/~hinton/absps/guideTR.pdf http://deeplearning.net/tutorial/rbm.html#contrastive-divergence-cd-k http://www.iro.umontreal.ca/~lisa/twiki/bin/view.cgi/Public/DBNEquations http://www.cs.toronto.edu/~kriz/learning-features-2009-TR.pdf
PS ambikontur !
UPD :
public void Train(IMultilayerNeuralNetwork network, IList<DataItem> data)
, . , .
LearningAlgorithmConfig config = new LearningAlgorithmConfig() { BatchSize = 10, // MaxEpoches = 1000, // GibbsSamplingChainLength = 30, // k CD-k LearningRate = 0.01, // CostFunctionRecalculationStep = 1, // Momentum = 0.9, // MinError = 0, // MinErrorChange = 0, // UseBiases = true // };
.
ILayer visibleLayer = network.Layers[0]; // RBM , ILayer hiddenLayer = network.Layers[1]; // if (!_config.UseBiases) // { for (int i = 0; i < visibleLayer.Neurons.Length; i++) { visibleLayer.Neurons[i].Bias = 0d; } for (int i = 0; i < hiddenLayer.Neurons.Length; i++) { hiddenLayer.Neurons[i].Bias = 0d; } } //init momentum // double[,] momentumSpeedWeights = new double[visibleLayer.Neurons.Length, hiddenLayer.Neurons.Length]; double[] momentumSpeedVisibleBiases = new double[visibleLayer.Neurons.Length]; double[] momentumSpeedHiddenBiases = new double[hiddenLayer.Neurons.Length]; //init stop factors bool stopFlag = false; double lastError = Double.MaxValue; // , double lastErrorChange = double.MaxValue; double learningRate = _config.LearningRate; int currentEpoche = 0; BatchEnumerator<DataItem<double>> batchEnumerator = new BatchEnumerator<DataItem<double>>(data, _config.BatchSize, true);
BatchEnumerator' , .
:
do { DateTime dtStart = DateTime.Now; //start batch processing foreach (IList<DataItem<double>> batch in batchEnumerator) { //batch gradient // , / double[,] nablaWeights = new double[visibleLayer.Neurons.Length, hiddenLayer.Neurons.Length]; double[] nablaHiddenBiases = new double[hiddenLayer.Neurons.Length]; double[] nablaVisibleBiases = new double[visibleLayer.Neurons.Length]; #region iterate through batch //... #endregion #region compute mean of wights nabla, and update them //... #endregion } #region Logging and error calculation //... #endregion // currentEpoche++; if (currentEpoche >= _config.MaxEpoches) { stopFlag = true; Logger.Instance.Log("Stop: currentEpoche:" + currentEpoche + " >= _config.MaxEpoches:" + _config.MaxEpoches); } else if (_config.MinError >= lastError) { stopFlag = true; Logger.Instance.Log("Stop: _config.MinError:" + _config.MinError + " >= lastError:" + lastError); } else if (_config.MinErrorChange >= lastErrorChange) { stopFlag = true; Logger.Instance.Log("Stop: _config.MinErrorChange:" + _config.MinErrorChange + " >= lastErrorChange:" + lastErrorChange); } } while (!stopFlag);
, Gibbs sampling, .
#region iterate through batch // foreach (DataItem<double> dataItem in batch) { //init visible layer states // / for (int i = 0; i < dataItem.Input.Length; i++) { visibleLayer.Neurons[i].LastState = dataItem.Input[i]; } #region Gibbs sampling for (int k = 0; k <= _config.GibbsSamplingChainLength; k++) { //calculate hidden states probabilities // , hiddenLayer.Compute(); #region accumulate negative phase // - , if (k == _config.GibbsSamplingChainLength) { for (int i = 0; i < visibleLayer.Neurons.Length; i++) { for (int j = 0; j < hiddenLayer.Neurons.Length; j++) { // nablaWeights[i, j] -= visibleLayer.Neurons[i].LastState * hiddenLayer.Neurons[j].LastState; } } if (_config.UseBiases) { for (int i = 0; i < hiddenLayer.Neurons.Length; i++) { nablaHiddenBiases[i] -= hiddenLayer.Neurons[i].LastState; } for (int i = 0; i < visibleLayer.Neurons.Length; i++) { nablaVisibleBiases[i] -= visibleLayer.Neurons[i].LastState; } } break; } #endregion //sample hidden states // , , , Gibbs sampling for (int i = 0; i < hiddenLayer.Neurons.Length; i++) { hiddenLayer.Neurons[i].LastState = _r.NextDouble() <= hiddenLayer.Neurons[i].LastState ? 1d : 0d; } #region accumulate positive phase // , if (k == 0) { for (int i = 0; i < visibleLayer.Neurons.Length; i++) { for (int j = 0; j < hiddenLayer.Neurons.Length; j++) { nablaWeights[i, j] += visibleLayer.Neurons[i].LastState* hiddenLayer.Neurons[j].LastState; } } if (_config.UseBiases) { for (int i = 0; i < hiddenLayer.Neurons.Length; i++) { nablaHiddenBiases[i] += hiddenLayer.Neurons[i].LastState; } for (int i = 0; i < visibleLayer.Neurons.Length; i++) { nablaVisibleBiases[i] += visibleLayer.Neurons[i].LastState; } } } #endregion //calculate visible probs // visibleLayer.Compute(); // , , , . ; //todo: may be not do sampling, like in 3.2 of http://www.cs.toronto.edu/~hinton/absps/guideTR.pdf //sample visible //for (int i = 0; i < visibleLayer.Neurons.Length; i++) //{ // visibleLayer.Neurons[i].LastState = _r.NextDouble() <= visibleLayer.Neurons[i].LastState ? 1d : 0d; //} } #endregion }
, . : ( ) . .
#region compute mean of wights nabla, and update them for (int i = 0; i < visibleLayer.Neurons.Length; i++) { for (int j = 0; j < hiddenLayer.Neurons.Length; j++) { // , momentumSpeedWeights[i, j] = _config.Momentum*momentumSpeedWeights[i, j] + nablaWeights[i, j]/batch.Count; // visibleLayer.Neurons[i].Weights[j] += learningRate * momentumSpeedWeights[i, j]; hiddenLayer.Neurons[j].Weights[i] = visibleLayer.Neurons[i].Weights[j]; } } if (_config.UseBiases) { for (int i = 0; i < hiddenLayer.Neurons.Length; i++) { momentumSpeedHiddenBiases[i] = _config.Momentum*momentumSpeedHiddenBiases[i] + nablaHiddenBiases[i]/batch.Count; hiddenLayer.Neurons[i].Bias += learningRate * momentumSpeedHiddenBiases[i]; } for (int i = 0; i < visibleLayer.Neurons.Length; i++) { momentumSpeedVisibleBiases[i] = _config.Momentum*momentumSpeedVisibleBiases[i] + nablaVisibleBiases[i]/batch.Count; visibleLayer.Neurons[i].Bias += learningRate * momentumSpeedVisibleBiases[i]; } }
- . , , / , , , . : . , , , . .
#region Logging and error calculation string msg = "Epoche #" + currentEpoche; #region calculate error if (currentEpoche % _config.CostFunctionRecalculationStep == 0) { #region calculating squared error with reconstruction IMetrics<double> sed = MetricsCreator.SquareEuclideanDistance(); double d = 0; foreach (DataItem<double> dataItem in data) { d += sed.Calculate(dataItem.Input, network.ComputeOutput(dataItem.Input)); } msg += "; SqDist is " + d; lastErrorChange = Math.Abs(lastError - d); lastError = d; #endregion } #endregion msg += "; Time: " + (DateTime.Now - dtStart).Duration().ToString(); Logger.Instance.Log(msg);
.
RBM
. , , , ( 260 29 29 ): .
:
LearningAlgorithmConfig:
LearningRate = 0.01
BatchSize = 10
RegularizationFactor = 0
MaxEpoches = 1000
MinError = 0
MinErrorChange = 0
CostFunctionRecalculationStep = 1
ErrorFunction =
Momentum = 0.9
NeuronLocalGainLimit: not setted
GibbsSamplingChainLength = 30
UseBiases = True
, 1000 . .. 10, 26 , 26000 . .
, (26 ) 13128, 76.
( , ):
:
, ( RBM).
, - , . , . 841 (29*29) . , 841 29 29 , , . , , , . :
MNIST : http://deeplearning.net/tutorial/_images/filters_at_epoch_14.png . , =)
RBM , , .
https://class.coursera.org/neuralnets-2012-001/ http://www.cs.toronto.edu/~hinton/absps/guideTR.pdf http://deeplearning.net/tutorial/rbm.html#contrastive-divergence-cd-k http://www.iro.umontreal.ca/~lisa/twiki/bin/view.cgi/Public/DBNEquations http://www.cs.toronto.edu/~kriz/learning-features-2009-TR.pdf
PS ambikontur !
UPD :
public void Train(IMultilayerNeuralNetwork network, IList<DataItem> data)
, . , .
LearningAlgorithmConfig config = new LearningAlgorithmConfig() { BatchSize = 10, // MaxEpoches = 1000, // GibbsSamplingChainLength = 30, // k CD-k LearningRate = 0.01, // CostFunctionRecalculationStep = 1, // Momentum = 0.9, // MinError = 0, // MinErrorChange = 0, // UseBiases = true // };
.
ILayer visibleLayer = network.Layers[0]; // RBM , ILayer hiddenLayer = network.Layers[1]; // if (!_config.UseBiases) // { for (int i = 0; i < visibleLayer.Neurons.Length; i++) { visibleLayer.Neurons[i].Bias = 0d; } for (int i = 0; i < hiddenLayer.Neurons.Length; i++) { hiddenLayer.Neurons[i].Bias = 0d; } } //init momentum // double[,] momentumSpeedWeights = new double[visibleLayer.Neurons.Length, hiddenLayer.Neurons.Length]; double[] momentumSpeedVisibleBiases = new double[visibleLayer.Neurons.Length]; double[] momentumSpeedHiddenBiases = new double[hiddenLayer.Neurons.Length]; //init stop factors bool stopFlag = false; double lastError = Double.MaxValue; // , double lastErrorChange = double.MaxValue; double learningRate = _config.LearningRate; int currentEpoche = 0; BatchEnumerator<DataItem<double>> batchEnumerator = new BatchEnumerator<DataItem<double>>(data, _config.BatchSize, true);
BatchEnumerator' , .
:
do { DateTime dtStart = DateTime.Now; //start batch processing foreach (IList<DataItem<double>> batch in batchEnumerator) { //batch gradient // , / double[,] nablaWeights = new double[visibleLayer.Neurons.Length, hiddenLayer.Neurons.Length]; double[] nablaHiddenBiases = new double[hiddenLayer.Neurons.Length]; double[] nablaVisibleBiases = new double[visibleLayer.Neurons.Length]; #region iterate through batch //... #endregion #region compute mean of wights nabla, and update them //... #endregion } #region Logging and error calculation //... #endregion // currentEpoche++; if (currentEpoche >= _config.MaxEpoches) { stopFlag = true; Logger.Instance.Log("Stop: currentEpoche:" + currentEpoche + " >= _config.MaxEpoches:" + _config.MaxEpoches); } else if (_config.MinError >= lastError) { stopFlag = true; Logger.Instance.Log("Stop: _config.MinError:" + _config.MinError + " >= lastError:" + lastError); } else if (_config.MinErrorChange >= lastErrorChange) { stopFlag = true; Logger.Instance.Log("Stop: _config.MinErrorChange:" + _config.MinErrorChange + " >= lastErrorChange:" + lastErrorChange); } } while (!stopFlag);
, Gibbs sampling, .
#region iterate through batch // foreach (DataItem<double> dataItem in batch) { //init visible layer states // / for (int i = 0; i < dataItem.Input.Length; i++) { visibleLayer.Neurons[i].LastState = dataItem.Input[i]; } #region Gibbs sampling for (int k = 0; k <= _config.GibbsSamplingChainLength; k++) { //calculate hidden states probabilities // , hiddenLayer.Compute(); #region accumulate negative phase // - , if (k == _config.GibbsSamplingChainLength) { for (int i = 0; i < visibleLayer.Neurons.Length; i++) { for (int j = 0; j < hiddenLayer.Neurons.Length; j++) { // nablaWeights[i, j] -= visibleLayer.Neurons[i].LastState * hiddenLayer.Neurons[j].LastState; } } if (_config.UseBiases) { for (int i = 0; i < hiddenLayer.Neurons.Length; i++) { nablaHiddenBiases[i] -= hiddenLayer.Neurons[i].LastState; } for (int i = 0; i < visibleLayer.Neurons.Length; i++) { nablaVisibleBiases[i] -= visibleLayer.Neurons[i].LastState; } } break; } #endregion //sample hidden states // , , , Gibbs sampling for (int i = 0; i < hiddenLayer.Neurons.Length; i++) { hiddenLayer.Neurons[i].LastState = _r.NextDouble() <= hiddenLayer.Neurons[i].LastState ? 1d : 0d; } #region accumulate positive phase // , if (k == 0) { for (int i = 0; i < visibleLayer.Neurons.Length; i++) { for (int j = 0; j < hiddenLayer.Neurons.Length; j++) { nablaWeights[i, j] += visibleLayer.Neurons[i].LastState* hiddenLayer.Neurons[j].LastState; } } if (_config.UseBiases) { for (int i = 0; i < hiddenLayer.Neurons.Length; i++) { nablaHiddenBiases[i] += hiddenLayer.Neurons[i].LastState; } for (int i = 0; i < visibleLayer.Neurons.Length; i++) { nablaVisibleBiases[i] += visibleLayer.Neurons[i].LastState; } } } #endregion //calculate visible probs // visibleLayer.Compute(); // , , , . ; //todo: may be not do sampling, like in 3.2 of http://www.cs.toronto.edu/~hinton/absps/guideTR.pdf //sample visible //for (int i = 0; i < visibleLayer.Neurons.Length; i++) //{ // visibleLayer.Neurons[i].LastState = _r.NextDouble() <= visibleLayer.Neurons[i].LastState ? 1d : 0d; //} } #endregion }
, . : ( ) . .
#region compute mean of wights nabla, and update them for (int i = 0; i < visibleLayer.Neurons.Length; i++) { for (int j = 0; j < hiddenLayer.Neurons.Length; j++) { // , momentumSpeedWeights[i, j] = _config.Momentum*momentumSpeedWeights[i, j] + nablaWeights[i, j]/batch.Count; // visibleLayer.Neurons[i].Weights[j] += learningRate * momentumSpeedWeights[i, j]; hiddenLayer.Neurons[j].Weights[i] = visibleLayer.Neurons[i].Weights[j]; } } if (_config.UseBiases) { for (int i = 0; i < hiddenLayer.Neurons.Length; i++) { momentumSpeedHiddenBiases[i] = _config.Momentum*momentumSpeedHiddenBiases[i] + nablaHiddenBiases[i]/batch.Count; hiddenLayer.Neurons[i].Bias += learningRate * momentumSpeedHiddenBiases[i]; } for (int i = 0; i < visibleLayer.Neurons.Length; i++) { momentumSpeedVisibleBiases[i] = _config.Momentum*momentumSpeedVisibleBiases[i] + nablaVisibleBiases[i]/batch.Count; visibleLayer.Neurons[i].Bias += learningRate * momentumSpeedVisibleBiases[i]; } }
- . , , / , , , . : . , , , . .
#region Logging and error calculation string msg = "Epoche #" + currentEpoche; #region calculate error if (currentEpoche % _config.CostFunctionRecalculationStep == 0) { #region calculating squared error with reconstruction IMetrics<double> sed = MetricsCreator.SquareEuclideanDistance(); double d = 0; foreach (DataItem<double> dataItem in data) { d += sed.Calculate(dataItem.Input, network.ComputeOutput(dataItem.Input)); } msg += "; SqDist is " + d; lastErrorChange = Math.Abs(lastError - d); lastError = d; #endregion } #endregion msg += "; Time: " + (DateTime.Now - dtStart).Duration().ToString(); Logger.Instance.Log(msg);
.
RBM
. , , , ( 260 29 29 ): .
:
LearningAlgorithmConfig:
LearningRate = 0.01
BatchSize = 10
RegularizationFactor = 0
MaxEpoches = 1000
MinError = 0
MinErrorChange = 0
CostFunctionRecalculationStep = 1
ErrorFunction =
Momentum = 0.9
NeuronLocalGainLimit: not setted
GibbsSamplingChainLength = 30
UseBiases = True
, 1000 . .. 10, 26 , 26000 . .
, (26 ) 13128, 76.
( , ):
:
, ( RBM).
, - , . , . 841 (29*29) . , 841 29 29 , , . , , , . :
MNIST : http://deeplearning.net/tutorial/_images/filters_at_epoch_14.png . , =)
RBM , , .
https://class.coursera.org/neuralnets-2012-001/ http://www.cs.toronto.edu/~hinton/absps/guideTR.pdf http://deeplearning.net/tutorial/rbm.html#contrastive-divergence-cd-k http://www.iro.umontreal.ca/~lisa/twiki/bin/view.cgi/Public/DBNEquations http://www.cs.toronto.edu/~kriz/learning-features-2009-TR.pdf
PS ambikontur !
UPD :
public void Train(IMultilayerNeuralNetwork network, IList<DataItem> data)
, . , .
LearningAlgorithmConfig config = new LearningAlgorithmConfig() { BatchSize = 10, // MaxEpoches = 1000, // GibbsSamplingChainLength = 30, // k CD-k LearningRate = 0.01, // CostFunctionRecalculationStep = 1, // Momentum = 0.9, // MinError = 0, // MinErrorChange = 0, // UseBiases = true // };
.
ILayer visibleLayer = network.Layers[0]; // RBM , ILayer hiddenLayer = network.Layers[1]; // if (!_config.UseBiases) // { for (int i = 0; i < visibleLayer.Neurons.Length; i++) { visibleLayer.Neurons[i].Bias = 0d; } for (int i = 0; i < hiddenLayer.Neurons.Length; i++) { hiddenLayer.Neurons[i].Bias = 0d; } } //init momentum // double[,] momentumSpeedWeights = new double[visibleLayer.Neurons.Length, hiddenLayer.Neurons.Length]; double[] momentumSpeedVisibleBiases = new double[visibleLayer.Neurons.Length]; double[] momentumSpeedHiddenBiases = new double[hiddenLayer.Neurons.Length]; //init stop factors bool stopFlag = false; double lastError = Double.MaxValue; // , double lastErrorChange = double.MaxValue; double learningRate = _config.LearningRate; int currentEpoche = 0; BatchEnumerator<DataItem<double>> batchEnumerator = new BatchEnumerator<DataItem<double>>(data, _config.BatchSize, true);
BatchEnumerator' , .
:
do { DateTime dtStart = DateTime.Now; //start batch processing foreach (IList<DataItem<double>> batch in batchEnumerator) { //batch gradient // , / double[,] nablaWeights = new double[visibleLayer.Neurons.Length, hiddenLayer.Neurons.Length]; double[] nablaHiddenBiases = new double[hiddenLayer.Neurons.Length]; double[] nablaVisibleBiases = new double[visibleLayer.Neurons.Length]; #region iterate through batch //... #endregion #region compute mean of wights nabla, and update them //... #endregion } #region Logging and error calculation //... #endregion // currentEpoche++; if (currentEpoche >= _config.MaxEpoches) { stopFlag = true; Logger.Instance.Log("Stop: currentEpoche:" + currentEpoche + " >= _config.MaxEpoches:" + _config.MaxEpoches); } else if (_config.MinError >= lastError) { stopFlag = true; Logger.Instance.Log("Stop: _config.MinError:" + _config.MinError + " >= lastError:" + lastError); } else if (_config.MinErrorChange >= lastErrorChange) { stopFlag = true; Logger.Instance.Log("Stop: _config.MinErrorChange:" + _config.MinErrorChange + " >= lastErrorChange:" + lastErrorChange); } } while (!stopFlag);
, Gibbs sampling, .
#region iterate through batch // foreach (DataItem<double> dataItem in batch) { //init visible layer states // / for (int i = 0; i < dataItem.Input.Length; i++) { visibleLayer.Neurons[i].LastState = dataItem.Input[i]; } #region Gibbs sampling for (int k = 0; k <= _config.GibbsSamplingChainLength; k++) { //calculate hidden states probabilities // , hiddenLayer.Compute(); #region accumulate negative phase // - , if (k == _config.GibbsSamplingChainLength) { for (int i = 0; i < visibleLayer.Neurons.Length; i++) { for (int j = 0; j < hiddenLayer.Neurons.Length; j++) { // nablaWeights[i, j] -= visibleLayer.Neurons[i].LastState * hiddenLayer.Neurons[j].LastState; } } if (_config.UseBiases) { for (int i = 0; i < hiddenLayer.Neurons.Length; i++) { nablaHiddenBiases[i] -= hiddenLayer.Neurons[i].LastState; } for (int i = 0; i < visibleLayer.Neurons.Length; i++) { nablaVisibleBiases[i] -= visibleLayer.Neurons[i].LastState; } } break; } #endregion //sample hidden states // , , , Gibbs sampling for (int i = 0; i < hiddenLayer.Neurons.Length; i++) { hiddenLayer.Neurons[i].LastState = _r.NextDouble() <= hiddenLayer.Neurons[i].LastState ? 1d : 0d; } #region accumulate positive phase // , if (k == 0) { for (int i = 0; i < visibleLayer.Neurons.Length; i++) { for (int j = 0; j < hiddenLayer.Neurons.Length; j++) { nablaWeights[i, j] += visibleLayer.Neurons[i].LastState* hiddenLayer.Neurons[j].LastState; } } if (_config.UseBiases) { for (int i = 0; i < hiddenLayer.Neurons.Length; i++) { nablaHiddenBiases[i] += hiddenLayer.Neurons[i].LastState; } for (int i = 0; i < visibleLayer.Neurons.Length; i++) { nablaVisibleBiases[i] += visibleLayer.Neurons[i].LastState; } } } #endregion //calculate visible probs // visibleLayer.Compute(); // , , , . ; //todo: may be not do sampling, like in 3.2 of http://www.cs.toronto.edu/~hinton/absps/guideTR.pdf //sample visible //for (int i = 0; i < visibleLayer.Neurons.Length; i++) //{ // visibleLayer.Neurons[i].LastState = _r.NextDouble() <= visibleLayer.Neurons[i].LastState ? 1d : 0d; //} } #endregion }
, . : ( ) . .
#region compute mean of wights nabla, and update them for (int i = 0; i < visibleLayer.Neurons.Length; i++) { for (int j = 0; j < hiddenLayer.Neurons.Length; j++) { // , momentumSpeedWeights[i, j] = _config.Momentum*momentumSpeedWeights[i, j] + nablaWeights[i, j]/batch.Count; // visibleLayer.Neurons[i].Weights[j] += learningRate * momentumSpeedWeights[i, j]; hiddenLayer.Neurons[j].Weights[i] = visibleLayer.Neurons[i].Weights[j]; } } if (_config.UseBiases) { for (int i = 0; i < hiddenLayer.Neurons.Length; i++) { momentumSpeedHiddenBiases[i] = _config.Momentum*momentumSpeedHiddenBiases[i] + nablaHiddenBiases[i]/batch.Count; hiddenLayer.Neurons[i].Bias += learningRate * momentumSpeedHiddenBiases[i]; } for (int i = 0; i < visibleLayer.Neurons.Length; i++) { momentumSpeedVisibleBiases[i] = _config.Momentum*momentumSpeedVisibleBiases[i] + nablaVisibleBiases[i]/batch.Count; visibleLayer.Neurons[i].Bias += learningRate * momentumSpeedVisibleBiases[i]; } }
- . , , / , , , . : . , , , . .
#region Logging and error calculation string msg = "Epoche #" + currentEpoche; #region calculate error if (currentEpoche % _config.CostFunctionRecalculationStep == 0) { #region calculating squared error with reconstruction IMetrics<double> sed = MetricsCreator.SquareEuclideanDistance(); double d = 0; foreach (DataItem<double> dataItem in data) { d += sed.Calculate(dataItem.Input, network.ComputeOutput(dataItem.Input)); } msg += "; SqDist is " + d; lastErrorChange = Math.Abs(lastError - d); lastError = d; #endregion } #endregion msg += "; Time: " + (DateTime.Now - dtStart).Duration().ToString(); Logger.Instance.Log(msg);
.
RBM
. , , , ( 260 29 29 ): .
:
LearningAlgorithmConfig:
LearningRate = 0.01
BatchSize = 10
RegularizationFactor = 0
MaxEpoches = 1000
MinError = 0
MinErrorChange = 0
CostFunctionRecalculationStep = 1
ErrorFunction =
Momentum = 0.9
NeuronLocalGainLimit: not setted
GibbsSamplingChainLength = 30
UseBiases = True
, 1000 . .. 10, 26 , 26000 . .
, (26 ) 13128, 76.
( , ):
:
, ( RBM).
, - , . , . 841 (29*29) . , 841 29 29 , , . , , , . :
MNIST : http://deeplearning.net/tutorial/_images/filters_at_epoch_14.png . , =)
RBM , , .
https://class.coursera.org/neuralnets-2012-001/ http://www.cs.toronto.edu/~hinton/absps/guideTR.pdf http://deeplearning.net/tutorial/rbm.html#contrastive-divergence-cd-k http://www.iro.umontreal.ca/~lisa/twiki/bin/view.cgi/Public/DBNEquations http://www.cs.toronto.edu/~kriz/learning-features-2009-TR.pdf
PS ambikontur !
UPD :
public void Train(IMultilayerNeuralNetwork network, IList<DataItem> data)
, . , .
LearningAlgorithmConfig config = new LearningAlgorithmConfig() { BatchSize = 10, // MaxEpoches = 1000, // GibbsSamplingChainLength = 30, // k CD-k LearningRate = 0.01, // CostFunctionRecalculationStep = 1, // Momentum = 0.9, // MinError = 0, // MinErrorChange = 0, // UseBiases = true // };
.
ILayer visibleLayer = network.Layers[0]; // RBM , ILayer hiddenLayer = network.Layers[1]; // if (!_config.UseBiases) // { for (int i = 0; i < visibleLayer.Neurons.Length; i++) { visibleLayer.Neurons[i].Bias = 0d; } for (int i = 0; i < hiddenLayer.Neurons.Length; i++) { hiddenLayer.Neurons[i].Bias = 0d; } } //init momentum // double[,] momentumSpeedWeights = new double[visibleLayer.Neurons.Length, hiddenLayer.Neurons.Length]; double[] momentumSpeedVisibleBiases = new double[visibleLayer.Neurons.Length]; double[] momentumSpeedHiddenBiases = new double[hiddenLayer.Neurons.Length]; //init stop factors bool stopFlag = false; double lastError = Double.MaxValue; // , double lastErrorChange = double.MaxValue; double learningRate = _config.LearningRate; int currentEpoche = 0; BatchEnumerator<DataItem<double>> batchEnumerator = new BatchEnumerator<DataItem<double>>(data, _config.BatchSize, true);
BatchEnumerator' , .
:
do { DateTime dtStart = DateTime.Now; //start batch processing foreach (IList<DataItem<double>> batch in batchEnumerator) { //batch gradient // , / double[,] nablaWeights = new double[visibleLayer.Neurons.Length, hiddenLayer.Neurons.Length]; double[] nablaHiddenBiases = new double[hiddenLayer.Neurons.Length]; double[] nablaVisibleBiases = new double[visibleLayer.Neurons.Length]; #region iterate through batch //... #endregion #region compute mean of wights nabla, and update them //... #endregion } #region Logging and error calculation //... #endregion // currentEpoche++; if (currentEpoche >= _config.MaxEpoches) { stopFlag = true; Logger.Instance.Log("Stop: currentEpoche:" + currentEpoche + " >= _config.MaxEpoches:" + _config.MaxEpoches); } else if (_config.MinError >= lastError) { stopFlag = true; Logger.Instance.Log("Stop: _config.MinError:" + _config.MinError + " >= lastError:" + lastError); } else if (_config.MinErrorChange >= lastErrorChange) { stopFlag = true; Logger.Instance.Log("Stop: _config.MinErrorChange:" + _config.MinErrorChange + " >= lastErrorChange:" + lastErrorChange); } } while (!stopFlag);
, Gibbs sampling, .
#region iterate through batch // foreach (DataItem<double> dataItem in batch) { //init visible layer states // / for (int i = 0; i < dataItem.Input.Length; i++) { visibleLayer.Neurons[i].LastState = dataItem.Input[i]; } #region Gibbs sampling for (int k = 0; k <= _config.GibbsSamplingChainLength; k++) { //calculate hidden states probabilities // , hiddenLayer.Compute(); #region accumulate negative phase // - , if (k == _config.GibbsSamplingChainLength) { for (int i = 0; i < visibleLayer.Neurons.Length; i++) { for (int j = 0; j < hiddenLayer.Neurons.Length; j++) { // nablaWeights[i, j] -= visibleLayer.Neurons[i].LastState * hiddenLayer.Neurons[j].LastState; } } if (_config.UseBiases) { for (int i = 0; i < hiddenLayer.Neurons.Length; i++) { nablaHiddenBiases[i] -= hiddenLayer.Neurons[i].LastState; } for (int i = 0; i < visibleLayer.Neurons.Length; i++) { nablaVisibleBiases[i] -= visibleLayer.Neurons[i].LastState; } } break; } #endregion //sample hidden states // , , , Gibbs sampling for (int i = 0; i < hiddenLayer.Neurons.Length; i++) { hiddenLayer.Neurons[i].LastState = _r.NextDouble() <= hiddenLayer.Neurons[i].LastState ? 1d : 0d; } #region accumulate positive phase // , if (k == 0) { for (int i = 0; i < visibleLayer.Neurons.Length; i++) { for (int j = 0; j < hiddenLayer.Neurons.Length; j++) { nablaWeights[i, j] += visibleLayer.Neurons[i].LastState* hiddenLayer.Neurons[j].LastState; } } if (_config.UseBiases) { for (int i = 0; i < hiddenLayer.Neurons.Length; i++) { nablaHiddenBiases[i] += hiddenLayer.Neurons[i].LastState; } for (int i = 0; i < visibleLayer.Neurons.Length; i++) { nablaVisibleBiases[i] += visibleLayer.Neurons[i].LastState; } } } #endregion //calculate visible probs // visibleLayer.Compute(); // , , , . ; //todo: may be not do sampling, like in 3.2 of http://www.cs.toronto.edu/~hinton/absps/guideTR.pdf //sample visible //for (int i = 0; i < visibleLayer.Neurons.Length; i++) //{ // visibleLayer.Neurons[i].LastState = _r.NextDouble() <= visibleLayer.Neurons[i].LastState ? 1d : 0d; //} } #endregion }
, . : ( ) . .
#region compute mean of wights nabla, and update them for (int i = 0; i < visibleLayer.Neurons.Length; i++) { for (int j = 0; j < hiddenLayer.Neurons.Length; j++) { // , momentumSpeedWeights[i, j] = _config.Momentum*momentumSpeedWeights[i, j] + nablaWeights[i, j]/batch.Count; // visibleLayer.Neurons[i].Weights[j] += learningRate * momentumSpeedWeights[i, j]; hiddenLayer.Neurons[j].Weights[i] = visibleLayer.Neurons[i].Weights[j]; } } if (_config.UseBiases) { for (int i = 0; i < hiddenLayer.Neurons.Length; i++) { momentumSpeedHiddenBiases[i] = _config.Momentum*momentumSpeedHiddenBiases[i] + nablaHiddenBiases[i]/batch.Count; hiddenLayer.Neurons[i].Bias += learningRate * momentumSpeedHiddenBiases[i]; } for (int i = 0; i < visibleLayer.Neurons.Length; i++) { momentumSpeedVisibleBiases[i] = _config.Momentum*momentumSpeedVisibleBiases[i] + nablaVisibleBiases[i]/batch.Count; visibleLayer.Neurons[i].Bias += learningRate * momentumSpeedVisibleBiases[i]; } }
- . , , / , , , . : . , , , . .
#region Logging and error calculation string msg = "Epoche #" + currentEpoche; #region calculate error if (currentEpoche % _config.CostFunctionRecalculationStep == 0) { #region calculating squared error with reconstruction IMetrics<double> sed = MetricsCreator.SquareEuclideanDistance(); double d = 0; foreach (DataItem<double> dataItem in data) { d += sed.Calculate(dataItem.Input, network.ComputeOutput(dataItem.Input)); } msg += "; SqDist is " + d; lastErrorChange = Math.Abs(lastError - d); lastError = d; #endregion } #endregion msg += "; Time: " + (DateTime.Now - dtStart).Duration().ToString(); Logger.Instance.Log(msg);
.
RBM
. , , , ( 260 29 29 ): .
:
LearningAlgorithmConfig:
LearningRate = 0.01
BatchSize = 10
RegularizationFactor = 0
MaxEpoches = 1000
MinError = 0
MinErrorChange = 0
CostFunctionRecalculationStep = 1
ErrorFunction =
Momentum = 0.9
NeuronLocalGainLimit: not setted
GibbsSamplingChainLength = 30
UseBiases = True
, 1000 . .. 10, 26 , 26000 . .
, (26 ) 13128, 76.
( , ):
:
, ( RBM).
, - , . , . 841 (29*29) . , 841 29 29 , , . , , , . :
MNIST : http://deeplearning.net/tutorial/_images/filters_at_epoch_14.png . , =)
RBM , , .
https://class.coursera.org/neuralnets-2012-001/ http://www.cs.toronto.edu/~hinton/absps/guideTR.pdf http://deeplearning.net/tutorial/rbm.html#contrastive-divergence-cd-k http://www.iro.umontreal.ca/~lisa/twiki/bin/view.cgi/Public/DBNEquations http://www.cs.toronto.edu/~kriz/learning-features-2009-TR.pdf
PS ambikontur !
UPD :
public void Train(IMultilayerNeuralNetwork network, IList<DataItem> data)
, . , .
LearningAlgorithmConfig config = new LearningAlgorithmConfig() { BatchSize = 10, // MaxEpoches = 1000, // GibbsSamplingChainLength = 30, // k CD-k LearningRate = 0.01, // CostFunctionRecalculationStep = 1, // Momentum = 0.9, // MinError = 0, // MinErrorChange = 0, // UseBiases = true // };
.
ILayer visibleLayer = network.Layers[0]; // RBM , ILayer hiddenLayer = network.Layers[1]; // if (!_config.UseBiases) // { for (int i = 0; i < visibleLayer.Neurons.Length; i++) { visibleLayer.Neurons[i].Bias = 0d; } for (int i = 0; i < hiddenLayer.Neurons.Length; i++) { hiddenLayer.Neurons[i].Bias = 0d; } } //init momentum // double[,] momentumSpeedWeights = new double[visibleLayer.Neurons.Length, hiddenLayer.Neurons.Length]; double[] momentumSpeedVisibleBiases = new double[visibleLayer.Neurons.Length]; double[] momentumSpeedHiddenBiases = new double[hiddenLayer.Neurons.Length]; //init stop factors bool stopFlag = false; double lastError = Double.MaxValue; // , double lastErrorChange = double.MaxValue; double learningRate = _config.LearningRate; int currentEpoche = 0; BatchEnumerator<DataItem<double>> batchEnumerator = new BatchEnumerator<DataItem<double>>(data, _config.BatchSize, true);
BatchEnumerator' , .
:
do { DateTime dtStart = DateTime.Now; //start batch processing foreach (IList<DataItem<double>> batch in batchEnumerator) { //batch gradient // , / double[,] nablaWeights = new double[visibleLayer.Neurons.Length, hiddenLayer.Neurons.Length]; double[] nablaHiddenBiases = new double[hiddenLayer.Neurons.Length]; double[] nablaVisibleBiases = new double[visibleLayer.Neurons.Length]; #region iterate through batch //... #endregion #region compute mean of wights nabla, and update them //... #endregion } #region Logging and error calculation //... #endregion // currentEpoche++; if (currentEpoche >= _config.MaxEpoches) { stopFlag = true; Logger.Instance.Log("Stop: currentEpoche:" + currentEpoche + " >= _config.MaxEpoches:" + _config.MaxEpoches); } else if (_config.MinError >= lastError) { stopFlag = true; Logger.Instance.Log("Stop: _config.MinError:" + _config.MinError + " >= lastError:" + lastError); } else if (_config.MinErrorChange >= lastErrorChange) { stopFlag = true; Logger.Instance.Log("Stop: _config.MinErrorChange:" + _config.MinErrorChange + " >= lastErrorChange:" + lastErrorChange); } } while (!stopFlag);
, Gibbs sampling, .
#region iterate through batch // foreach (DataItem<double> dataItem in batch) { //init visible layer states // / for (int i = 0; i < dataItem.Input.Length; i++) { visibleLayer.Neurons[i].LastState = dataItem.Input[i]; } #region Gibbs sampling for (int k = 0; k <= _config.GibbsSamplingChainLength; k++) { //calculate hidden states probabilities // , hiddenLayer.Compute(); #region accumulate negative phase // - , if (k == _config.GibbsSamplingChainLength) { for (int i = 0; i < visibleLayer.Neurons.Length; i++) { for (int j = 0; j < hiddenLayer.Neurons.Length; j++) { // nablaWeights[i, j] -= visibleLayer.Neurons[i].LastState * hiddenLayer.Neurons[j].LastState; } } if (_config.UseBiases) { for (int i = 0; i < hiddenLayer.Neurons.Length; i++) { nablaHiddenBiases[i] -= hiddenLayer.Neurons[i].LastState; } for (int i = 0; i < visibleLayer.Neurons.Length; i++) { nablaVisibleBiases[i] -= visibleLayer.Neurons[i].LastState; } } break; } #endregion //sample hidden states // , , , Gibbs sampling for (int i = 0; i < hiddenLayer.Neurons.Length; i++) { hiddenLayer.Neurons[i].LastState = _r.NextDouble() <= hiddenLayer.Neurons[i].LastState ? 1d : 0d; } #region accumulate positive phase // , if (k == 0) { for (int i = 0; i < visibleLayer.Neurons.Length; i++) { for (int j = 0; j < hiddenLayer.Neurons.Length; j++) { nablaWeights[i, j] += visibleLayer.Neurons[i].LastState* hiddenLayer.Neurons[j].LastState; } } if (_config.UseBiases) { for (int i = 0; i < hiddenLayer.Neurons.Length; i++) { nablaHiddenBiases[i] += hiddenLayer.Neurons[i].LastState; } for (int i = 0; i < visibleLayer.Neurons.Length; i++) { nablaVisibleBiases[i] += visibleLayer.Neurons[i].LastState; } } } #endregion //calculate visible probs // visibleLayer.Compute(); // , , , . ; //todo: may be not do sampling, like in 3.2 of http://www.cs.toronto.edu/~hinton/absps/guideTR.pdf //sample visible //for (int i = 0; i < visibleLayer.Neurons.Length; i++) //{ // visibleLayer.Neurons[i].LastState = _r.NextDouble() <= visibleLayer.Neurons[i].LastState ? 1d : 0d; //} } #endregion }
, . : ( ) . .
#region compute mean of wights nabla, and update them for (int i = 0; i < visibleLayer.Neurons.Length; i++) { for (int j = 0; j < hiddenLayer.Neurons.Length; j++) { // , momentumSpeedWeights[i, j] = _config.Momentum*momentumSpeedWeights[i, j] + nablaWeights[i, j]/batch.Count; // visibleLayer.Neurons[i].Weights[j] += learningRate * momentumSpeedWeights[i, j]; hiddenLayer.Neurons[j].Weights[i] = visibleLayer.Neurons[i].Weights[j]; } } if (_config.UseBiases) { for (int i = 0; i < hiddenLayer.Neurons.Length; i++) { momentumSpeedHiddenBiases[i] = _config.Momentum*momentumSpeedHiddenBiases[i] + nablaHiddenBiases[i]/batch.Count; hiddenLayer.Neurons[i].Bias += learningRate * momentumSpeedHiddenBiases[i]; } for (int i = 0; i < visibleLayer.Neurons.Length; i++) { momentumSpeedVisibleBiases[i] = _config.Momentum*momentumSpeedVisibleBiases[i] + nablaVisibleBiases[i]/batch.Count; visibleLayer.Neurons[i].Bias += learningRate * momentumSpeedVisibleBiases[i]; } }
- . , , / , , , . : . , , , . .
#region Logging and error calculation string msg = "Epoche #" + currentEpoche; #region calculate error if (currentEpoche % _config.CostFunctionRecalculationStep == 0) { #region calculating squared error with reconstruction IMetrics<double> sed = MetricsCreator.SquareEuclideanDistance(); double d = 0; foreach (DataItem<double> dataItem in data) { d += sed.Calculate(dataItem.Input, network.ComputeOutput(dataItem.Input)); } msg += "; SqDist is " + d; lastErrorChange = Math.Abs(lastError - d); lastError = d; #endregion } #endregion msg += "; Time: " + (DateTime.Now - dtStart).Duration().ToString(); Logger.Instance.Log(msg);
.
RBM
. , , , ( 260 29 29 ): .
:
LearningAlgorithmConfig:
LearningRate = 0.01
BatchSize = 10
RegularizationFactor = 0
MaxEpoches = 1000
MinError = 0
MinErrorChange = 0
CostFunctionRecalculationStep = 1
ErrorFunction =
Momentum = 0.9
NeuronLocalGainLimit: not setted
GibbsSamplingChainLength = 30
UseBiases = True
, 1000 . .. 10, 26 , 26000 . .
, (26 ) 13128, 76.
( , ):
:
, ( RBM).
, - , . , . 841 (29*29) . , 841 29 29 , , . , , , . :
MNIST : http://deeplearning.net/tutorial/_images/filters_at_epoch_14.png . , =)
RBM , , .
https://class.coursera.org/neuralnets-2012-001/ http://www.cs.toronto.edu/~hinton/absps/guideTR.pdf http://deeplearning.net/tutorial/rbm.html#contrastive-divergence-cd-k http://www.iro.umontreal.ca/~lisa/twiki/bin/view.cgi/Public/DBNEquations http://www.cs.toronto.edu/~kriz/learning-features-2009-TR.pdf
PS ambikontur !
UPD :
public void Train(IMultilayerNeuralNetwork network, IList<DataItem> data)
, . , .
LearningAlgorithmConfig config = new LearningAlgorithmConfig() { BatchSize = 10, // MaxEpoches = 1000, // GibbsSamplingChainLength = 30, // k CD-k LearningRate = 0.01, // CostFunctionRecalculationStep = 1, // Momentum = 0.9, // MinError = 0, // MinErrorChange = 0, // UseBiases = true // };
.
ILayer visibleLayer = network.Layers[0]; // RBM , ILayer hiddenLayer = network.Layers[1]; // if (!_config.UseBiases) // { for (int i = 0; i < visibleLayer.Neurons.Length; i++) { visibleLayer.Neurons[i].Bias = 0d; } for (int i = 0; i < hiddenLayer.Neurons.Length; i++) { hiddenLayer.Neurons[i].Bias = 0d; } } //init momentum // double[,] momentumSpeedWeights = new double[visibleLayer.Neurons.Length, hiddenLayer.Neurons.Length]; double[] momentumSpeedVisibleBiases = new double[visibleLayer.Neurons.Length]; double[] momentumSpeedHiddenBiases = new double[hiddenLayer.Neurons.Length]; //init stop factors bool stopFlag = false; double lastError = Double.MaxValue; // , double lastErrorChange = double.MaxValue; double learningRate = _config.LearningRate; int currentEpoche = 0; BatchEnumerator<DataItem<double>> batchEnumerator = new BatchEnumerator<DataItem<double>>(data, _config.BatchSize, true);
BatchEnumerator' , .
:
do { DateTime dtStart = DateTime.Now; //start batch processing foreach (IList<DataItem<double>> batch in batchEnumerator) { //batch gradient // , / double[,] nablaWeights = new double[visibleLayer.Neurons.Length, hiddenLayer.Neurons.Length]; double[] nablaHiddenBiases = new double[hiddenLayer.Neurons.Length]; double[] nablaVisibleBiases = new double[visibleLayer.Neurons.Length]; #region iterate through batch //... #endregion #region compute mean of wights nabla, and update them //... #endregion } #region Logging and error calculation //... #endregion // currentEpoche++; if (currentEpoche >= _config.MaxEpoches) { stopFlag = true; Logger.Instance.Log("Stop: currentEpoche:" + currentEpoche + " >= _config.MaxEpoches:" + _config.MaxEpoches); } else if (_config.MinError >= lastError) { stopFlag = true; Logger.Instance.Log("Stop: _config.MinError:" + _config.MinError + " >= lastError:" + lastError); } else if (_config.MinErrorChange >= lastErrorChange) { stopFlag = true; Logger.Instance.Log("Stop: _config.MinErrorChange:" + _config.MinErrorChange + " >= lastErrorChange:" + lastErrorChange); } } while (!stopFlag);
, Gibbs sampling, .
#region iterate through batch // foreach (DataItem<double> dataItem in batch) { //init visible layer states // / for (int i = 0; i < dataItem.Input.Length; i++) { visibleLayer.Neurons[i].LastState = dataItem.Input[i]; } #region Gibbs sampling for (int k = 0; k <= _config.GibbsSamplingChainLength; k++) { //calculate hidden states probabilities // , hiddenLayer.Compute(); #region accumulate negative phase // - , if (k == _config.GibbsSamplingChainLength) { for (int i = 0; i < visibleLayer.Neurons.Length; i++) { for (int j = 0; j < hiddenLayer.Neurons.Length; j++) { // nablaWeights[i, j] -= visibleLayer.Neurons[i].LastState * hiddenLayer.Neurons[j].LastState; } } if (_config.UseBiases) { for (int i = 0; i < hiddenLayer.Neurons.Length; i++) { nablaHiddenBiases[i] -= hiddenLayer.Neurons[i].LastState; } for (int i = 0; i < visibleLayer.Neurons.Length; i++) { nablaVisibleBiases[i] -= visibleLayer.Neurons[i].LastState; } } break; } #endregion //sample hidden states // , , , Gibbs sampling for (int i = 0; i < hiddenLayer.Neurons.Length; i++) { hiddenLayer.Neurons[i].LastState = _r.NextDouble() <= hiddenLayer.Neurons[i].LastState ? 1d : 0d; } #region accumulate positive phase // , if (k == 0) { for (int i = 0; i < visibleLayer.Neurons.Length; i++) { for (int j = 0; j < hiddenLayer.Neurons.Length; j++) { nablaWeights[i, j] += visibleLayer.Neurons[i].LastState* hiddenLayer.Neurons[j].LastState; } } if (_config.UseBiases) { for (int i = 0; i < hiddenLayer.Neurons.Length; i++) { nablaHiddenBiases[i] += hiddenLayer.Neurons[i].LastState; } for (int i = 0; i < visibleLayer.Neurons.Length; i++) { nablaVisibleBiases[i] += visibleLayer.Neurons[i].LastState; } } } #endregion //calculate visible probs // visibleLayer.Compute(); // , , , . ; //todo: may be not do sampling, like in 3.2 of http://www.cs.toronto.edu/~hinton/absps/guideTR.pdf //sample visible //for (int i = 0; i < visibleLayer.Neurons.Length; i++) //{ // visibleLayer.Neurons[i].LastState = _r.NextDouble() <= visibleLayer.Neurons[i].LastState ? 1d : 0d; //} } #endregion }
, . : ( ) . .
#region compute mean of wights nabla, and update them for (int i = 0; i < visibleLayer.Neurons.Length; i++) { for (int j = 0; j < hiddenLayer.Neurons.Length; j++) { // , momentumSpeedWeights[i, j] = _config.Momentum*momentumSpeedWeights[i, j] + nablaWeights[i, j]/batch.Count; // visibleLayer.Neurons[i].Weights[j] += learningRate * momentumSpeedWeights[i, j]; hiddenLayer.Neurons[j].Weights[i] = visibleLayer.Neurons[i].Weights[j]; } } if (_config.UseBiases) { for (int i = 0; i < hiddenLayer.Neurons.Length; i++) { momentumSpeedHiddenBiases[i] = _config.Momentum*momentumSpeedHiddenBiases[i] + nablaHiddenBiases[i]/batch.Count; hiddenLayer.Neurons[i].Bias += learningRate * momentumSpeedHiddenBiases[i]; } for (int i = 0; i < visibleLayer.Neurons.Length; i++) { momentumSpeedVisibleBiases[i] = _config.Momentum*momentumSpeedVisibleBiases[i] + nablaVisibleBiases[i]/batch.Count; visibleLayer.Neurons[i].Bias += learningRate * momentumSpeedVisibleBiases[i]; } }
- . , , / , , , . : . , , , . .
#region Logging and error calculation string msg = "Epoche #" + currentEpoche; #region calculate error if (currentEpoche % _config.CostFunctionRecalculationStep == 0) { #region calculating squared error with reconstruction IMetrics<double> sed = MetricsCreator.SquareEuclideanDistance(); double d = 0; foreach (DataItem<double> dataItem in data) { d += sed.Calculate(dataItem.Input, network.ComputeOutput(dataItem.Input)); } msg += "; SqDist is " + d; lastErrorChange = Math.Abs(lastError - d); lastError = d; #endregion } #endregion msg += "; Time: " + (DateTime.Now - dtStart).Duration().ToString(); Logger.Instance.Log(msg);
.
RBM
. , , , ( 260 29 29 ): .
:
LearningAlgorithmConfig:
LearningRate = 0.01
BatchSize = 10
RegularizationFactor = 0
MaxEpoches = 1000
MinError = 0
MinErrorChange = 0
CostFunctionRecalculationStep = 1
ErrorFunction =
Momentum = 0.9
NeuronLocalGainLimit: not setted
GibbsSamplingChainLength = 30
UseBiases = True
, 1000 . .. 10, 26 , 26000 . .
, (26 ) 13128, 76.
( , ):
:
, ( RBM).
, - , . , . 841 (29*29) . , 841 29 29 , , . , , , . :
MNIST : http://deeplearning.net/tutorial/_images/filters_at_epoch_14.png . , =)
RBM , , .
https://class.coursera.org/neuralnets-2012-001/ http://www.cs.toronto.edu/~hinton/absps/guideTR.pdf http://deeplearning.net/tutorial/rbm.html#contrastive-divergence-cd-k http://www.iro.umontreal.ca/~lisa/twiki/bin/view.cgi/Public/DBNEquations http://www.cs.toronto.edu/~kriz/learning-features-2009-TR.pdf
PS ambikontur !
UPD :
public void Train(IMultilayerNeuralNetwork network, IList<DataItem> data)
, . , .
LearningAlgorithmConfig config = new LearningAlgorithmConfig() { BatchSize = 10, // MaxEpoches = 1000, // GibbsSamplingChainLength = 30, // k CD-k LearningRate = 0.01, // CostFunctionRecalculationStep = 1, // Momentum = 0.9, // MinError = 0, // MinErrorChange = 0, // UseBiases = true // };
.
ILayer visibleLayer = network.Layers[0]; // RBM , ILayer hiddenLayer = network.Layers[1]; // if (!_config.UseBiases) // { for (int i = 0; i < visibleLayer.Neurons.Length; i++) { visibleLayer.Neurons[i].Bias = 0d; } for (int i = 0; i < hiddenLayer.Neurons.Length; i++) { hiddenLayer.Neurons[i].Bias = 0d; } } //init momentum // double[,] momentumSpeedWeights = new double[visibleLayer.Neurons.Length, hiddenLayer.Neurons.Length]; double[] momentumSpeedVisibleBiases = new double[visibleLayer.Neurons.Length]; double[] momentumSpeedHiddenBiases = new double[hiddenLayer.Neurons.Length]; //init stop factors bool stopFlag = false; double lastError = Double.MaxValue; // , double lastErrorChange = double.MaxValue; double learningRate = _config.LearningRate; int currentEpoche = 0; BatchEnumerator<DataItem<double>> batchEnumerator = new BatchEnumerator<DataItem<double>>(data, _config.BatchSize, true);
BatchEnumerator' , .
:
do { DateTime dtStart = DateTime.Now; //start batch processing foreach (IList<DataItem<double>> batch in batchEnumerator) { //batch gradient // , / double[,] nablaWeights = new double[visibleLayer.Neurons.Length, hiddenLayer.Neurons.Length]; double[] nablaHiddenBiases = new double[hiddenLayer.Neurons.Length]; double[] nablaVisibleBiases = new double[visibleLayer.Neurons.Length]; #region iterate through batch //... #endregion #region compute mean of wights nabla, and update them //... #endregion } #region Logging and error calculation //... #endregion // currentEpoche++; if (currentEpoche >= _config.MaxEpoches) { stopFlag = true; Logger.Instance.Log("Stop: currentEpoche:" + currentEpoche + " >= _config.MaxEpoches:" + _config.MaxEpoches); } else if (_config.MinError >= lastError) { stopFlag = true; Logger.Instance.Log("Stop: _config.MinError:" + _config.MinError + " >= lastError:" + lastError); } else if (_config.MinErrorChange >= lastErrorChange) { stopFlag = true; Logger.Instance.Log("Stop: _config.MinErrorChange:" + _config.MinErrorChange + " >= lastErrorChange:" + lastErrorChange); } } while (!stopFlag);
, Gibbs sampling, .
#region iterate through batch // foreach (DataItem<double> dataItem in batch) { //init visible layer states // / for (int i = 0; i < dataItem.Input.Length; i++) { visibleLayer.Neurons[i].LastState = dataItem.Input[i]; } #region Gibbs sampling for (int k = 0; k <= _config.GibbsSamplingChainLength; k++) { //calculate hidden states probabilities // , hiddenLayer.Compute(); #region accumulate negative phase // - , if (k == _config.GibbsSamplingChainLength) { for (int i = 0; i < visibleLayer.Neurons.Length; i++) { for (int j = 0; j < hiddenLayer.Neurons.Length; j++) { // nablaWeights[i, j] -= visibleLayer.Neurons[i].LastState * hiddenLayer.Neurons[j].LastState; } } if (_config.UseBiases) { for (int i = 0; i < hiddenLayer.Neurons.Length; i++) { nablaHiddenBiases[i] -= hiddenLayer.Neurons[i].LastState; } for (int i = 0; i < visibleLayer.Neurons.Length; i++) { nablaVisibleBiases[i] -= visibleLayer.Neurons[i].LastState; } } break; } #endregion //sample hidden states // , , , Gibbs sampling for (int i = 0; i < hiddenLayer.Neurons.Length; i++) { hiddenLayer.Neurons[i].LastState = _r.NextDouble() <= hiddenLayer.Neurons[i].LastState ? 1d : 0d; } #region accumulate positive phase // , if (k == 0) { for (int i = 0; i < visibleLayer.Neurons.Length; i++) { for (int j = 0; j < hiddenLayer.Neurons.Length; j++) { nablaWeights[i, j] += visibleLayer.Neurons[i].LastState* hiddenLayer.Neurons[j].LastState; } } if (_config.UseBiases) { for (int i = 0; i < hiddenLayer.Neurons.Length; i++) { nablaHiddenBiases[i] += hiddenLayer.Neurons[i].LastState; } for (int i = 0; i < visibleLayer.Neurons.Length; i++) { nablaVisibleBiases[i] += visibleLayer.Neurons[i].LastState; } } } #endregion //calculate visible probs // visibleLayer.Compute(); // , , , . ; //todo: may be not do sampling, like in 3.2 of http://www.cs.toronto.edu/~hinton/absps/guideTR.pdf //sample visible //for (int i = 0; i < visibleLayer.Neurons.Length; i++) //{ // visibleLayer.Neurons[i].LastState = _r.NextDouble() <= visibleLayer.Neurons[i].LastState ? 1d : 0d; //} } #endregion }
, . : ( ) . .
#region compute mean of wights nabla, and update them for (int i = 0; i < visibleLayer.Neurons.Length; i++) { for (int j = 0; j < hiddenLayer.Neurons.Length; j++) { // , momentumSpeedWeights[i, j] = _config.Momentum*momentumSpeedWeights[i, j] + nablaWeights[i, j]/batch.Count; // visibleLayer.Neurons[i].Weights[j] += learningRate * momentumSpeedWeights[i, j]; hiddenLayer.Neurons[j].Weights[i] = visibleLayer.Neurons[i].Weights[j]; } } if (_config.UseBiases) { for (int i = 0; i < hiddenLayer.Neurons.Length; i++) { momentumSpeedHiddenBiases[i] = _config.Momentum*momentumSpeedHiddenBiases[i] + nablaHiddenBiases[i]/batch.Count; hiddenLayer.Neurons[i].Bias += learningRate * momentumSpeedHiddenBiases[i]; } for (int i = 0; i < visibleLayer.Neurons.Length; i++) { momentumSpeedVisibleBiases[i] = _config.Momentum*momentumSpeedVisibleBiases[i] + nablaVisibleBiases[i]/batch.Count; visibleLayer.Neurons[i].Bias += learningRate * momentumSpeedVisibleBiases[i]; } }
- . , , / , , , . : . , , , . .
#region Logging and error calculation string msg = "Epoche #" + currentEpoche; #region calculate error if (currentEpoche % _config.CostFunctionRecalculationStep == 0) { #region calculating squared error with reconstruction IMetrics<double> sed = MetricsCreator.SquareEuclideanDistance(); double d = 0; foreach (DataItem<double> dataItem in data) { d += sed.Calculate(dataItem.Input, network.ComputeOutput(dataItem.Input)); } msg += "; SqDist is " + d; lastErrorChange = Math.Abs(lastError - d); lastError = d; #endregion } #endregion msg += "; Time: " + (DateTime.Now - dtStart).Duration().ToString(); Logger.Instance.Log(msg);
.
RBM
. , , , ( 260 29 29 ): .
:
LearningAlgorithmConfig:
LearningRate = 0.01
BatchSize = 10
RegularizationFactor = 0
MaxEpoches = 1000
MinError = 0
MinErrorChange = 0
CostFunctionRecalculationStep = 1
ErrorFunction =
Momentum = 0.9
NeuronLocalGainLimit: not setted
GibbsSamplingChainLength = 30
UseBiases = True
, 1000 . .. 10, 26 , 26000 . .
, (26 ) 13128, 76.
( , ):
:
, ( RBM).
, - , . , . 841 (29*29) . , 841 29 29 , , . , , , . :
MNIST : http://deeplearning.net/tutorial/_images/filters_at_epoch_14.png . , =)
RBM , , .
https://class.coursera.org/neuralnets-2012-001/ http://www.cs.toronto.edu/~hinton/absps/guideTR.pdf http://deeplearning.net/tutorial/rbm.html#contrastive-divergence-cd-k http://www.iro.umontreal.ca/~lisa/twiki/bin/view.cgi/Public/DBNEquations http://www.cs.toronto.edu/~kriz/learning-features-2009-TR.pdf
PS ambikontur !
UPD :
public void Train(IMultilayerNeuralNetwork network, IList<DataItem> data)
, . , .
LearningAlgorithmConfig config = new LearningAlgorithmConfig() { BatchSize = 10, // MaxEpoches = 1000, // GibbsSamplingChainLength = 30, // k CD-k LearningRate = 0.01, // CostFunctionRecalculationStep = 1, // Momentum = 0.9, // MinError = 0, // MinErrorChange = 0, // UseBiases = true // };
.
ILayer visibleLayer = network.Layers[0]; // RBM , ILayer hiddenLayer = network.Layers[1]; // if (!_config.UseBiases) // { for (int i = 0; i < visibleLayer.Neurons.Length; i++) { visibleLayer.Neurons[i].Bias = 0d; } for (int i = 0; i < hiddenLayer.Neurons.Length; i++) { hiddenLayer.Neurons[i].Bias = 0d; } } //init momentum // double[,] momentumSpeedWeights = new double[visibleLayer.Neurons.Length, hiddenLayer.Neurons.Length]; double[] momentumSpeedVisibleBiases = new double[visibleLayer.Neurons.Length]; double[] momentumSpeedHiddenBiases = new double[hiddenLayer.Neurons.Length]; //init stop factors bool stopFlag = false; double lastError = Double.MaxValue; // , double lastErrorChange = double.MaxValue; double learningRate = _config.LearningRate; int currentEpoche = 0; BatchEnumerator<DataItem<double>> batchEnumerator = new BatchEnumerator<DataItem<double>>(data, _config.BatchSize, true);
BatchEnumerator' , .
:
do { DateTime dtStart = DateTime.Now; //start batch processing foreach (IList<DataItem<double>> batch in batchEnumerator) { //batch gradient // , / double[,] nablaWeights = new double[visibleLayer.Neurons.Length, hiddenLayer.Neurons.Length]; double[] nablaHiddenBiases = new double[hiddenLayer.Neurons.Length]; double[] nablaVisibleBiases = new double[visibleLayer.Neurons.Length]; #region iterate through batch //... #endregion #region compute mean of wights nabla, and update them //... #endregion } #region Logging and error calculation //... #endregion // currentEpoche++; if (currentEpoche >= _config.MaxEpoches) { stopFlag = true; Logger.Instance.Log("Stop: currentEpoche:" + currentEpoche + " >= _config.MaxEpoches:" + _config.MaxEpoches); } else if (_config.MinError >= lastError) { stopFlag = true; Logger.Instance.Log("Stop: _config.MinError:" + _config.MinError + " >= lastError:" + lastError); } else if (_config.MinErrorChange >= lastErrorChange) { stopFlag = true; Logger.Instance.Log("Stop: _config.MinErrorChange:" + _config.MinErrorChange + " >= lastErrorChange:" + lastErrorChange); } } while (!stopFlag);
, Gibbs sampling, .
#region iterate through batch // foreach (DataItem<double> dataItem in batch) { //init visible layer states // / for (int i = 0; i < dataItem.Input.Length; i++) { visibleLayer.Neurons[i].LastState = dataItem.Input[i]; } #region Gibbs sampling for (int k = 0; k <= _config.GibbsSamplingChainLength; k++) { //calculate hidden states probabilities // , hiddenLayer.Compute(); #region accumulate negative phase // - , if (k == _config.GibbsSamplingChainLength) { for (int i = 0; i < visibleLayer.Neurons.Length; i++) { for (int j = 0; j < hiddenLayer.Neurons.Length; j++) { // nablaWeights[i, j] -= visibleLayer.Neurons[i].LastState * hiddenLayer.Neurons[j].LastState; } } if (_config.UseBiases) { for (int i = 0; i < hiddenLayer.Neurons.Length; i++) { nablaHiddenBiases[i] -= hiddenLayer.Neurons[i].LastState; } for (int i = 0; i < visibleLayer.Neurons.Length; i++) { nablaVisibleBiases[i] -= visibleLayer.Neurons[i].LastState; } } break; } #endregion //sample hidden states // , , , Gibbs sampling for (int i = 0; i < hiddenLayer.Neurons.Length; i++) { hiddenLayer.Neurons[i].LastState = _r.NextDouble() <= hiddenLayer.Neurons[i].LastState ? 1d : 0d; } #region accumulate positive phase // , if (k == 0) { for (int i = 0; i < visibleLayer.Neurons.Length; i++) { for (int j = 0; j < hiddenLayer.Neurons.Length; j++) { nablaWeights[i, j] += visibleLayer.Neurons[i].LastState* hiddenLayer.Neurons[j].LastState; } } if (_config.UseBiases) { for (int i = 0; i < hiddenLayer.Neurons.Length; i++) { nablaHiddenBiases[i] += hiddenLayer.Neurons[i].LastState; } for (int i = 0; i < visibleLayer.Neurons.Length; i++) { nablaVisibleBiases[i] += visibleLayer.Neurons[i].LastState; } } } #endregion //calculate visible probs // visibleLayer.Compute(); // , , , . ; //todo: may be not do sampling, like in 3.2 of http://www.cs.toronto.edu/~hinton/absps/guideTR.pdf //sample visible //for (int i = 0; i < visibleLayer.Neurons.Length; i++) //{ // visibleLayer.Neurons[i].LastState = _r.NextDouble() <= visibleLayer.Neurons[i].LastState ? 1d : 0d; //} } #endregion }
, . : ( ) . .
#region compute mean of wights nabla, and update them for (int i = 0; i < visibleLayer.Neurons.Length; i++) { for (int j = 0; j < hiddenLayer.Neurons.Length; j++) { // , momentumSpeedWeights[i, j] = _config.Momentum*momentumSpeedWeights[i, j] + nablaWeights[i, j]/batch.Count; // visibleLayer.Neurons[i].Weights[j] += learningRate * momentumSpeedWeights[i, j]; hiddenLayer.Neurons[j].Weights[i] = visibleLayer.Neurons[i].Weights[j]; } } if (_config.UseBiases) { for (int i = 0; i < hiddenLayer.Neurons.Length; i++) { momentumSpeedHiddenBiases[i] = _config.Momentum*momentumSpeedHiddenBiases[i] + nablaHiddenBiases[i]/batch.Count; hiddenLayer.Neurons[i].Bias += learningRate * momentumSpeedHiddenBiases[i]; } for (int i = 0; i < visibleLayer.Neurons.Length; i++) { momentumSpeedVisibleBiases[i] = _config.Momentum*momentumSpeedVisibleBiases[i] + nablaVisibleBiases[i]/batch.Count; visibleLayer.Neurons[i].Bias += learningRate * momentumSpeedVisibleBiases[i]; } }
- . , , / , , , . : . , , , . .
#region Logging and error calculation string msg = "Epoche #" + currentEpoche; #region calculate error if (currentEpoche % _config.CostFunctionRecalculationStep == 0) { #region calculating squared error with reconstruction IMetrics<double> sed = MetricsCreator.SquareEuclideanDistance(); double d = 0; foreach (DataItem<double> dataItem in data) { d += sed.Calculate(dataItem.Input, network.ComputeOutput(dataItem.Input)); } msg += "; SqDist is " + d; lastErrorChange = Math.Abs(lastError - d); lastError = d; #endregion } #endregion msg += "; Time: " + (DateTime.Now - dtStart).Duration().ToString(); Logger.Instance.Log(msg);
.
RBM
. , , , ( 260 29 29 ): .
:
LearningAlgorithmConfig:
LearningRate = 0.01
BatchSize = 10
RegularizationFactor = 0
MaxEpoches = 1000
MinError = 0
MinErrorChange = 0
CostFunctionRecalculationStep = 1
ErrorFunction =
Momentum = 0.9
NeuronLocalGainLimit: not setted
GibbsSamplingChainLength = 30
UseBiases = True
, 1000 . .. 10, 26 , 26000 . .
, (26 ) 13128, 76.
( , ):
:
, ( RBM).
, - , . , . 841 (29*29) . , 841 29 29 , , . , , , . :
MNIST : http://deeplearning.net/tutorial/_images/filters_at_epoch_14.png . , =)
RBM , , .
https://class.coursera.org/neuralnets-2012-001/ http://www.cs.toronto.edu/~hinton/absps/guideTR.pdf http://deeplearning.net/tutorial/rbm.html#contrastive-divergence-cd-k http://www.iro.umontreal.ca/~lisa/twiki/bin/view.cgi/Public/DBNEquations http://www.cs.toronto.edu/~kriz/learning-features-2009-TR.pdf
PS ambikontur !
UPD :
public void Train(IMultilayerNeuralNetwork network, IList<DataItem> data)
, . , .
LearningAlgorithmConfig config = new LearningAlgorithmConfig() { BatchSize = 10, // MaxEpoches = 1000, // GibbsSamplingChainLength = 30, // k CD-k LearningRate = 0.01, // CostFunctionRecalculationStep = 1, // Momentum = 0.9, // MinError = 0, // MinErrorChange = 0, // UseBiases = true // };
.
ILayer visibleLayer = network.Layers[0]; // RBM , ILayer hiddenLayer = network.Layers[1]; // if (!_config.UseBiases) // { for (int i = 0; i < visibleLayer.Neurons.Length; i++) { visibleLayer.Neurons[i].Bias = 0d; } for (int i = 0; i < hiddenLayer.Neurons.Length; i++) { hiddenLayer.Neurons[i].Bias = 0d; } } //init momentum // double[,] momentumSpeedWeights = new double[visibleLayer.Neurons.Length, hiddenLayer.Neurons.Length]; double[] momentumSpeedVisibleBiases = new double[visibleLayer.Neurons.Length]; double[] momentumSpeedHiddenBiases = new double[hiddenLayer.Neurons.Length]; //init stop factors bool stopFlag = false; double lastError = Double.MaxValue; // , double lastErrorChange = double.MaxValue; double learningRate = _config.LearningRate; int currentEpoche = 0; BatchEnumerator<DataItem<double>> batchEnumerator = new BatchEnumerator<DataItem<double>>(data, _config.BatchSize, true);
BatchEnumerator' , .
:
do { DateTime dtStart = DateTime.Now; //start batch processing foreach (IList<DataItem<double>> batch in batchEnumerator) { //batch gradient // , / double[,] nablaWeights = new double[visibleLayer.Neurons.Length, hiddenLayer.Neurons.Length]; double[] nablaHiddenBiases = new double[hiddenLayer.Neurons.Length]; double[] nablaVisibleBiases = new double[visibleLayer.Neurons.Length]; #region iterate through batch //... #endregion #region compute mean of wights nabla, and update them //... #endregion } #region Logging and error calculation //... #endregion // currentEpoche++; if (currentEpoche >= _config.MaxEpoches) { stopFlag = true; Logger.Instance.Log("Stop: currentEpoche:" + currentEpoche + " >= _config.MaxEpoches:" + _config.MaxEpoches); } else if (_config.MinError >= lastError) { stopFlag = true; Logger.Instance.Log("Stop: _config.MinError:" + _config.MinError + " >= lastError:" + lastError); } else if (_config.MinErrorChange >= lastErrorChange) { stopFlag = true; Logger.Instance.Log("Stop: _config.MinErrorChange:" + _config.MinErrorChange + " >= lastErrorChange:" + lastErrorChange); } } while (!stopFlag);
, Gibbs sampling, .
#region iterate through batch // foreach (DataItem<double> dataItem in batch) { //init visible layer states // / for (int i = 0; i < dataItem.Input.Length; i++) { visibleLayer.Neurons[i].LastState = dataItem.Input[i]; } #region Gibbs sampling for (int k = 0; k <= _config.GibbsSamplingChainLength; k++) { //calculate hidden states probabilities // , hiddenLayer.Compute(); #region accumulate negative phase // - , if (k == _config.GibbsSamplingChainLength) { for (int i = 0; i < visibleLayer.Neurons.Length; i++) { for (int j = 0; j < hiddenLayer.Neurons.Length; j++) { // nablaWeights[i, j] -= visibleLayer.Neurons[i].LastState * hiddenLayer.Neurons[j].LastState; } } if (_config.UseBiases) { for (int i = 0; i < hiddenLayer.Neurons.Length; i++) { nablaHiddenBiases[i] -= hiddenLayer.Neurons[i].LastState; } for (int i = 0; i < visibleLayer.Neurons.Length; i++) { nablaVisibleBiases[i] -= visibleLayer.Neurons[i].LastState; } } break; } #endregion //sample hidden states // , , , Gibbs sampling for (int i = 0; i < hiddenLayer.Neurons.Length; i++) { hiddenLayer.Neurons[i].LastState = _r.NextDouble() <= hiddenLayer.Neurons[i].LastState ? 1d : 0d; } #region accumulate positive phase // , if (k == 0) { for (int i = 0; i < visibleLayer.Neurons.Length; i++) { for (int j = 0; j < hiddenLayer.Neurons.Length; j++) { nablaWeights[i, j] += visibleLayer.Neurons[i].LastState* hiddenLayer.Neurons[j].LastState; } } if (_config.UseBiases) { for (int i = 0; i < hiddenLayer.Neurons.Length; i++) { nablaHiddenBiases[i] += hiddenLayer.Neurons[i].LastState; } for (int i = 0; i < visibleLayer.Neurons.Length; i++) { nablaVisibleBiases[i] += visibleLayer.Neurons[i].LastState; } } } #endregion //calculate visible probs // visibleLayer.Compute(); // , , , . ; //todo: may be not do sampling, like in 3.2 of http://www.cs.toronto.edu/~hinton/absps/guideTR.pdf //sample visible //for (int i = 0; i < visibleLayer.Neurons.Length; i++) //{ // visibleLayer.Neurons[i].LastState = _r.NextDouble() <= visibleLayer.Neurons[i].LastState ? 1d : 0d; //} } #endregion }
, . : ( ) . .
#region compute mean of wights nabla, and update them for (int i = 0; i < visibleLayer.Neurons.Length; i++) { for (int j = 0; j < hiddenLayer.Neurons.Length; j++) { // , momentumSpeedWeights[i, j] = _config.Momentum*momentumSpeedWeights[i, j] + nablaWeights[i, j]/batch.Count; // visibleLayer.Neurons[i].Weights[j] += learningRate * momentumSpeedWeights[i, j]; hiddenLayer.Neurons[j].Weights[i] = visibleLayer.Neurons[i].Weights[j]; } } if (_config.UseBiases) { for (int i = 0; i < hiddenLayer.Neurons.Length; i++) { momentumSpeedHiddenBiases[i] = _config.Momentum*momentumSpeedHiddenBiases[i] + nablaHiddenBiases[i]/batch.Count; hiddenLayer.Neurons[i].Bias += learningRate * momentumSpeedHiddenBiases[i]; } for (int i = 0; i < visibleLayer.Neurons.Length; i++) { momentumSpeedVisibleBiases[i] = _config.Momentum*momentumSpeedVisibleBiases[i] + nablaVisibleBiases[i]/batch.Count; visibleLayer.Neurons[i].Bias += learningRate * momentumSpeedVisibleBiases[i]; } }
- . , , / , , , . : . , , , . .
#region Logging and error calculation string msg = "Epoche #" + currentEpoche; #region calculate error if (currentEpoche % _config.CostFunctionRecalculationStep == 0) { #region calculating squared error with reconstruction IMetrics<double> sed = MetricsCreator.SquareEuclideanDistance(); double d = 0; foreach (DataItem<double> dataItem in data) { d += sed.Calculate(dataItem.Input, network.ComputeOutput(dataItem.Input)); } msg += "; SqDist is " + d; lastErrorChange = Math.Abs(lastError - d); lastError = d; #endregion } #endregion msg += "; Time: " + (DateTime.Now - dtStart).Duration().ToString(); Logger.Instance.Log(msg);
.
RBM
. , , , ( 260 29 29 ): .
:
LearningAlgorithmConfig:
LearningRate = 0.01
BatchSize = 10
RegularizationFactor = 0
MaxEpoches = 1000
MinError = 0
MinErrorChange = 0
CostFunctionRecalculationStep = 1
ErrorFunction =
Momentum = 0.9
NeuronLocalGainLimit: not setted
GibbsSamplingChainLength = 30
UseBiases = True
, 1000 . .. 10, 26 , 26000 . .
, (26 ) 13128, 76.
( , ):
:
, ( RBM).
, - , . , . 841 (29*29) . , 841 29 29 , , . , , , . :
MNIST : http://deeplearning.net/tutorial/_images/filters_at_epoch_14.png . , =)
RBM , , .
https://class.coursera.org/neuralnets-2012-001/ http://www.cs.toronto.edu/~hinton/absps/guideTR.pdf http://deeplearning.net/tutorial/rbm.html#contrastive-divergence-cd-k http://www.iro.umontreal.ca/~lisa/twiki/bin/view.cgi/Public/DBNEquations http://www.cs.toronto.edu/~kriz/learning-features-2009-TR.pdf
PS ambikontur !
UPD :
public void Train(IMultilayerNeuralNetwork network, IList<DataItem> data)
, . , .
LearningAlgorithmConfig config = new LearningAlgorithmConfig() { BatchSize = 10, // MaxEpoches = 1000, // GibbsSamplingChainLength = 30, // k CD-k LearningRate = 0.01, // CostFunctionRecalculationStep = 1, // Momentum = 0.9, // MinError = 0, // MinErrorChange = 0, // UseBiases = true // };
.
ILayer visibleLayer = network.Layers[0]; // RBM , ILayer hiddenLayer = network.Layers[1]; // if (!_config.UseBiases) // { for (int i = 0; i < visibleLayer.Neurons.Length; i++) { visibleLayer.Neurons[i].Bias = 0d; } for (int i = 0; i < hiddenLayer.Neurons.Length; i++) { hiddenLayer.Neurons[i].Bias = 0d; } } //init momentum // double[,] momentumSpeedWeights = new double[visibleLayer.Neurons.Length, hiddenLayer.Neurons.Length]; double[] momentumSpeedVisibleBiases = new double[visibleLayer.Neurons.Length]; double[] momentumSpeedHiddenBiases = new double[hiddenLayer.Neurons.Length]; //init stop factors bool stopFlag = false; double lastError = Double.MaxValue; // , double lastErrorChange = double.MaxValue; double learningRate = _config.LearningRate; int currentEpoche = 0; BatchEnumerator<DataItem<double>> batchEnumerator = new BatchEnumerator<DataItem<double>>(data, _config.BatchSize, true);
BatchEnumerator' , .
:
do { DateTime dtStart = DateTime.Now; //start batch processing foreach (IList<DataItem<double>> batch in batchEnumerator) { //batch gradient // , / double[,] nablaWeights = new double[visibleLayer.Neurons.Length, hiddenLayer.Neurons.Length]; double[] nablaHiddenBiases = new double[hiddenLayer.Neurons.Length]; double[] nablaVisibleBiases = new double[visibleLayer.Neurons.Length]; #region iterate through batch //... #endregion #region compute mean of wights nabla, and update them //... #endregion } #region Logging and error calculation //... #endregion // currentEpoche++; if (currentEpoche >= _config.MaxEpoches) { stopFlag = true; Logger.Instance.Log("Stop: currentEpoche:" + currentEpoche + " >= _config.MaxEpoches:" + _config.MaxEpoches); } else if (_config.MinError >= lastError) { stopFlag = true; Logger.Instance.Log("Stop: _config.MinError:" + _config.MinError + " >= lastError:" + lastError); } else if (_config.MinErrorChange >= lastErrorChange) { stopFlag = true; Logger.Instance.Log("Stop: _config.MinErrorChange:" + _config.MinErrorChange + " >= lastErrorChange:" + lastErrorChange); } } while (!stopFlag);
, Gibbs sampling, .
#region iterate through batch // foreach (DataItem<double> dataItem in batch) { //init visible layer states // / for (int i = 0; i < dataItem.Input.Length; i++) { visibleLayer.Neurons[i].LastState = dataItem.Input[i]; } #region Gibbs sampling for (int k = 0; k <= _config.GibbsSamplingChainLength; k++) { //calculate hidden states probabilities // , hiddenLayer.Compute(); #region accumulate negative phase // - , if (k == _config.GibbsSamplingChainLength) { for (int i = 0; i < visibleLayer.Neurons.Length; i++) { for (int j = 0; j < hiddenLayer.Neurons.Length; j++) { // nablaWeights[i, j] -= visibleLayer.Neurons[i].LastState * hiddenLayer.Neurons[j].LastState; } } if (_config.UseBiases) { for (int i = 0; i < hiddenLayer.Neurons.Length; i++) { nablaHiddenBiases[i] -= hiddenLayer.Neurons[i].LastState; } for (int i = 0; i < visibleLayer.Neurons.Length; i++) { nablaVisibleBiases[i] -= visibleLayer.Neurons[i].LastState; } } break; } #endregion //sample hidden states // , , , Gibbs sampling for (int i = 0; i < hiddenLayer.Neurons.Length; i++) { hiddenLayer.Neurons[i].LastState = _r.NextDouble() <= hiddenLayer.Neurons[i].LastState ? 1d : 0d; } #region accumulate positive phase // , if (k == 0) { for (int i = 0; i < visibleLayer.Neurons.Length; i++) { for (int j = 0; j < hiddenLayer.Neurons.Length; j++) { nablaWeights[i, j] += visibleLayer.Neurons[i].LastState* hiddenLayer.Neurons[j].LastState; } } if (_config.UseBiases) { for (int i = 0; i < hiddenLayer.Neurons.Length; i++) { nablaHiddenBiases[i] += hiddenLayer.Neurons[i].LastState; } for (int i = 0; i < visibleLayer.Neurons.Length; i++) { nablaVisibleBiases[i] += visibleLayer.Neurons[i].LastState; } } } #endregion //calculate visible probs // visibleLayer.Compute(); // , , , . ; //todo: may be not do sampling, like in 3.2 of http://www.cs.toronto.edu/~hinton/absps/guideTR.pdf //sample visible //for (int i = 0; i < visibleLayer.Neurons.Length; i++) //{ // visibleLayer.Neurons[i].LastState = _r.NextDouble() <= visibleLayer.Neurons[i].LastState ? 1d : 0d; //} } #endregion }
, . : ( ) . .
#region compute mean of wights nabla, and update them for (int i = 0; i < visibleLayer.Neurons.Length; i++) { for (int j = 0; j < hiddenLayer.Neurons.Length; j++) { // , momentumSpeedWeights[i, j] = _config.Momentum*momentumSpeedWeights[i, j] + nablaWeights[i, j]/batch.Count; // visibleLayer.Neurons[i].Weights[j] += learningRate * momentumSpeedWeights[i, j]; hiddenLayer.Neurons[j].Weights[i] = visibleLayer.Neurons[i].Weights[j]; } } if (_config.UseBiases) { for (int i = 0; i < hiddenLayer.Neurons.Length; i++) { momentumSpeedHiddenBiases[i] = _config.Momentum*momentumSpeedHiddenBiases[i] + nablaHiddenBiases[i]/batch.Count; hiddenLayer.Neurons[i].Bias += learningRate * momentumSpeedHiddenBiases[i]; } for (int i = 0; i < visibleLayer.Neurons.Length; i++) { momentumSpeedVisibleBiases[i] = _config.Momentum*momentumSpeedVisibleBiases[i] + nablaVisibleBiases[i]/batch.Count; visibleLayer.Neurons[i].Bias += learningRate * momentumSpeedVisibleBiases[i]; } }
- . , , / , , , . : . , , , . .
#region Logging and error calculation string msg = "Epoche #" + currentEpoche; #region calculate error if (currentEpoche % _config.CostFunctionRecalculationStep == 0) { #region calculating squared error with reconstruction IMetrics<double> sed = MetricsCreator.SquareEuclideanDistance(); double d = 0; foreach (DataItem<double> dataItem in data) { d += sed.Calculate(dataItem.Input, network.ComputeOutput(dataItem.Input)); } msg += "; SqDist is " + d; lastErrorChange = Math.Abs(lastError - d); lastError = d; #endregion } #endregion msg += "; Time: " + (DateTime.Now - dtStart).Duration().ToString(); Logger.Instance.Log(msg);
.
RBM
. , , , ( 260 29 29 ): .
:
LearningAlgorithmConfig:
LearningRate = 0.01
BatchSize = 10
RegularizationFactor = 0
MaxEpoches = 1000
MinError = 0
MinErrorChange = 0
CostFunctionRecalculationStep = 1
ErrorFunction =
Momentum = 0.9
NeuronLocalGainLimit: not setted
GibbsSamplingChainLength = 30
UseBiases = True
, 1000 . .. 10, 26 , 26000 . .
, (26 ) 13128, 76.
( , ):
:
, ( RBM).
, - , . , . 841 (29*29) . , 841 29 29 , , . , , , . :
MNIST : http://deeplearning.net/tutorial/_images/filters_at_epoch_14.png . , =)
RBM , , .
https://class.coursera.org/neuralnets-2012-001/ http://www.cs.toronto.edu/~hinton/absps/guideTR.pdf http://deeplearning.net/tutorial/rbm.html#contrastive-divergence-cd-k http://www.iro.umontreal.ca/~lisa/twiki/bin/view.cgi/Public/DBNEquations http://www.cs.toronto.edu/~kriz/learning-features-2009-TR.pdf
PS ambikontur !
UPD :
public void Train(IMultilayerNeuralNetwork network, IList<DataItem> data)
, . , .
LearningAlgorithmConfig config = new LearningAlgorithmConfig() { BatchSize = 10, // MaxEpoches = 1000, // GibbsSamplingChainLength = 30, // k CD-k LearningRate = 0.01, // CostFunctionRecalculationStep = 1, // Momentum = 0.9, // MinError = 0, // MinErrorChange = 0, // UseBiases = true // };
.
ILayer visibleLayer = network.Layers[0]; // RBM , ILayer hiddenLayer = network.Layers[1]; // if (!_config.UseBiases) // { for (int i = 0; i < visibleLayer.Neurons.Length; i++) { visibleLayer.Neurons[i].Bias = 0d; } for (int i = 0; i < hiddenLayer.Neurons.Length; i++) { hiddenLayer.Neurons[i].Bias = 0d; } } //init momentum // double[,] momentumSpeedWeights = new double[visibleLayer.Neurons.Length, hiddenLayer.Neurons.Length]; double[] momentumSpeedVisibleBiases = new double[visibleLayer.Neurons.Length]; double[] momentumSpeedHiddenBiases = new double[hiddenLayer.Neurons.Length]; //init stop factors bool stopFlag = false; double lastError = Double.MaxValue; // , double lastErrorChange = double.MaxValue; double learningRate = _config.LearningRate; int currentEpoche = 0; BatchEnumerator<DataItem<double>> batchEnumerator = new BatchEnumerator<DataItem<double>>(data, _config.BatchSize, true);
BatchEnumerator' , .
:
do { DateTime dtStart = DateTime.Now; //start batch processing foreach (IList<DataItem<double>> batch in batchEnumerator) { //batch gradient // , / double[,] nablaWeights = new double[visibleLayer.Neurons.Length, hiddenLayer.Neurons.Length]; double[] nablaHiddenBiases = new double[hiddenLayer.Neurons.Length]; double[] nablaVisibleBiases = new double[visibleLayer.Neurons.Length]; #region iterate through batch //... #endregion #region compute mean of wights nabla, and update them //... #endregion } #region Logging and error calculation //... #endregion // currentEpoche++; if (currentEpoche >= _config.MaxEpoches) { stopFlag = true; Logger.Instance.Log("Stop: currentEpoche:" + currentEpoche + " >= _config.MaxEpoches:" + _config.MaxEpoches); } else if (_config.MinError >= lastError) { stopFlag = true; Logger.Instance.Log("Stop: _config.MinError:" + _config.MinError + " >= lastError:" + lastError); } else if (_config.MinErrorChange >= lastErrorChange) { stopFlag = true; Logger.Instance.Log("Stop: _config.MinErrorChange:" + _config.MinErrorChange + " >= lastErrorChange:" + lastErrorChange); } } while (!stopFlag);
, Gibbs sampling, .
#region iterate through batch // foreach (DataItem<double> dataItem in batch) { //init visible layer states // / for (int i = 0; i < dataItem.Input.Length; i++) { visibleLayer.Neurons[i].LastState = dataItem.Input[i]; } #region Gibbs sampling for (int k = 0; k <= _config.GibbsSamplingChainLength; k++) { //calculate hidden states probabilities // , hiddenLayer.Compute(); #region accumulate negative phase // - , if (k == _config.GibbsSamplingChainLength) { for (int i = 0; i < visibleLayer.Neurons.Length; i++) { for (int j = 0; j < hiddenLayer.Neurons.Length; j++) { // nablaWeights[i, j] -= visibleLayer.Neurons[i].LastState * hiddenLayer.Neurons[j].LastState; } } if (_config.UseBiases) { for (int i = 0; i < hiddenLayer.Neurons.Length; i++) { nablaHiddenBiases[i] -= hiddenLayer.Neurons[i].LastState; } for (int i = 0; i < visibleLayer.Neurons.Length; i++) { nablaVisibleBiases[i] -= visibleLayer.Neurons[i].LastState; } } break; } #endregion //sample hidden states // , , , Gibbs sampling for (int i = 0; i < hiddenLayer.Neurons.Length; i++) { hiddenLayer.Neurons[i].LastState = _r.NextDouble() <= hiddenLayer.Neurons[i].LastState ? 1d : 0d; } #region accumulate positive phase // , if (k == 0) { for (int i = 0; i < visibleLayer.Neurons.Length; i++) { for (int j = 0; j < hiddenLayer.Neurons.Length; j++) { nablaWeights[i, j] += visibleLayer.Neurons[i].LastState* hiddenLayer.Neurons[j].LastState; } } if (_config.UseBiases) { for (int i = 0; i < hiddenLayer.Neurons.Length; i++) { nablaHiddenBiases[i] += hiddenLayer.Neurons[i].LastState; } for (int i = 0; i < visibleLayer.Neurons.Length; i++) { nablaVisibleBiases[i] += visibleLayer.Neurons[i].LastState; } } } #endregion //calculate visible probs // visibleLayer.Compute(); // , , , . ; //todo: may be not do sampling, like in 3.2 of http://www.cs.toronto.edu/~hinton/absps/guideTR.pdf //sample visible //for (int i = 0; i < visibleLayer.Neurons.Length; i++) //{ // visibleLayer.Neurons[i].LastState = _r.NextDouble() <= visibleLayer.Neurons[i].LastState ? 1d : 0d; //} } #endregion }
, . : ( ) . .
#region compute mean of wights nabla, and update them for (int i = 0; i < visibleLayer.Neurons.Length; i++) { for (int j = 0; j < hiddenLayer.Neurons.Length; j++) { // , momentumSpeedWeights[i, j] = _config.Momentum*momentumSpeedWeights[i, j] + nablaWeights[i, j]/batch.Count; // visibleLayer.Neurons[i].Weights[j] += learningRate * momentumSpeedWeights[i, j]; hiddenLayer.Neurons[j].Weights[i] = visibleLayer.Neurons[i].Weights[j]; } } if (_config.UseBiases) { for (int i = 0; i < hiddenLayer.Neurons.Length; i++) { momentumSpeedHiddenBiases[i] = _config.Momentum*momentumSpeedHiddenBiases[i] + nablaHiddenBiases[i]/batch.Count; hiddenLayer.Neurons[i].Bias += learningRate * momentumSpeedHiddenBiases[i]; } for (int i = 0; i < visibleLayer.Neurons.Length; i++) { momentumSpeedVisibleBiases[i] = _config.Momentum*momentumSpeedVisibleBiases[i] + nablaVisibleBiases[i]/batch.Count; visibleLayer.Neurons[i].Bias += learningRate * momentumSpeedVisibleBiases[i]; } }
- . , , / , , , . : . , , , . .
#region Logging and error calculation string msg = "Epoche #" + currentEpoche; #region calculate error if (currentEpoche % _config.CostFunctionRecalculationStep == 0) { #region calculating squared error with reconstruction IMetrics<double> sed = MetricsCreator.SquareEuclideanDistance(); double d = 0; foreach (DataItem<double> dataItem in data) { d += sed.Calculate(dataItem.Input, network.ComputeOutput(dataItem.Input)); } msg += "; SqDist is " + d; lastErrorChange = Math.Abs(lastError - d); lastError = d; #endregion } #endregion msg += "; Time: " + (DateTime.Now - dtStart).Duration().ToString(); Logger.Instance.Log(msg);
.
RBM
. , , , ( 260 29 29 ): .
:
LearningAlgorithmConfig:
LearningRate = 0.01
BatchSize = 10
RegularizationFactor = 0
MaxEpoches = 1000
MinError = 0
MinErrorChange = 0
CostFunctionRecalculationStep = 1
ErrorFunction =
Momentum = 0.9
NeuronLocalGainLimit: not setted
GibbsSamplingChainLength = 30
UseBiases = True
, 1000 . .. 10, 26 , 26000 . .
, (26 ) 13128, 76.
( , ):
:
, ( RBM).
, - , . , . 841 (29*29) . , 841 29 29 , , . , , , . :
MNIST : http://deeplearning.net/tutorial/_images/filters_at_epoch_14.png . , =)
RBM , , .
https://class.coursera.org/neuralnets-2012-001/ http://www.cs.toronto.edu/~hinton/absps/guideTR.pdf http://deeplearning.net/tutorial/rbm.html#contrastive-divergence-cd-k http://www.iro.umontreal.ca/~lisa/twiki/bin/view.cgi/Public/DBNEquations http://www.cs.toronto.edu/~kriz/learning-features-2009-TR.pdf
PS ambikontur !
UPD :
public void Train(IMultilayerNeuralNetwork network, IList<DataItem> data)
, . , .
LearningAlgorithmConfig config = new LearningAlgorithmConfig() { BatchSize = 10, // MaxEpoches = 1000, // GibbsSamplingChainLength = 30, // k CD-k LearningRate = 0.01, // CostFunctionRecalculationStep = 1, // Momentum = 0.9, // MinError = 0, // MinErrorChange = 0, // UseBiases = true // };
.
ILayer visibleLayer = network.Layers[0]; // RBM , ILayer hiddenLayer = network.Layers[1]; // if (!_config.UseBiases) // { for (int i = 0; i < visibleLayer.Neurons.Length; i++) { visibleLayer.Neurons[i].Bias = 0d; } for (int i = 0; i < hiddenLayer.Neurons.Length; i++) { hiddenLayer.Neurons[i].Bias = 0d; } } //init momentum // double[,] momentumSpeedWeights = new double[visibleLayer.Neurons.Length, hiddenLayer.Neurons.Length]; double[] momentumSpeedVisibleBiases = new double[visibleLayer.Neurons.Length]; double[] momentumSpeedHiddenBiases = new double[hiddenLayer.Neurons.Length]; //init stop factors bool stopFlag = false; double lastError = Double.MaxValue; // , double lastErrorChange = double.MaxValue; double learningRate = _config.LearningRate; int currentEpoche = 0; BatchEnumerator<DataItem<double>> batchEnumerator = new BatchEnumerator<DataItem<double>>(data, _config.BatchSize, true);
BatchEnumerator' , .
:
do { DateTime dtStart = DateTime.Now; //start batch processing foreach (IList<DataItem<double>> batch in batchEnumerator) { //batch gradient // , / double[,] nablaWeights = new double[visibleLayer.Neurons.Length, hiddenLayer.Neurons.Length]; double[] nablaHiddenBiases = new double[hiddenLayer.Neurons.Length]; double[] nablaVisibleBiases = new double[visibleLayer.Neurons.Length]; #region iterate through batch //... #endregion #region compute mean of wights nabla, and update them //... #endregion } #region Logging and error calculation //... #endregion // currentEpoche++; if (currentEpoche >= _config.MaxEpoches) { stopFlag = true; Logger.Instance.Log("Stop: currentEpoche:" + currentEpoche + " >= _config.MaxEpoches:" + _config.MaxEpoches); } else if (_config.MinError >= lastError) { stopFlag = true; Logger.Instance.Log("Stop: _config.MinError:" + _config.MinError + " >= lastError:" + lastError); } else if (_config.MinErrorChange >= lastErrorChange) { stopFlag = true; Logger.Instance.Log("Stop: _config.MinErrorChange:" + _config.MinErrorChange + " >= lastErrorChange:" + lastErrorChange); } } while (!stopFlag);
, Gibbs sampling, .
#region iterate through batch // foreach (DataItem<double> dataItem in batch) { //init visible layer states // / for (int i = 0; i < dataItem.Input.Length; i++) { visibleLayer.Neurons[i].LastState = dataItem.Input[i]; } #region Gibbs sampling for (int k = 0; k <= _config.GibbsSamplingChainLength; k++) { //calculate hidden states probabilities // , hiddenLayer.Compute(); #region accumulate negative phase // - , if (k == _config.GibbsSamplingChainLength) { for (int i = 0; i < visibleLayer.Neurons.Length; i++) { for (int j = 0; j < hiddenLayer.Neurons.Length; j++) { // nablaWeights[i, j] -= visibleLayer.Neurons[i].LastState * hiddenLayer.Neurons[j].LastState; } } if (_config.UseBiases) { for (int i = 0; i < hiddenLayer.Neurons.Length; i++) { nablaHiddenBiases[i] -= hiddenLayer.Neurons[i].LastState; } for (int i = 0; i < visibleLayer.Neurons.Length; i++) { nablaVisibleBiases[i] -= visibleLayer.Neurons[i].LastState; } } break; } #endregion //sample hidden states // , , , Gibbs sampling for (int i = 0; i < hiddenLayer.Neurons.Length; i++) { hiddenLayer.Neurons[i].LastState = _r.NextDouble() <= hiddenLayer.Neurons[i].LastState ? 1d : 0d; } #region accumulate positive phase // , if (k == 0) { for (int i = 0; i < visibleLayer.Neurons.Length; i++) { for (int j = 0; j < hiddenLayer.Neurons.Length; j++) { nablaWeights[i, j] += visibleLayer.Neurons[i].LastState* hiddenLayer.Neurons[j].LastState; } } if (_config.UseBiases) { for (int i = 0; i < hiddenLayer.Neurons.Length; i++) { nablaHiddenBiases[i] += hiddenLayer.Neurons[i].LastState; } for (int i = 0; i < visibleLayer.Neurons.Length; i++) { nablaVisibleBiases[i] += visibleLayer.Neurons[i].LastState; } } } #endregion //calculate visible probs // visibleLayer.Compute(); // , , , . ; //todo: may be not do sampling, like in 3.2 of http://www.cs.toronto.edu/~hinton/absps/guideTR.pdf //sample visible //for (int i = 0; i < visibleLayer.Neurons.Length; i++) //{ // visibleLayer.Neurons[i].LastState = _r.NextDouble() <= visibleLayer.Neurons[i].LastState ? 1d : 0d; //} } #endregion }
, . : ( ) . .
#region compute mean of wights nabla, and update them for (int i = 0; i < visibleLayer.Neurons.Length; i++) { for (int j = 0; j < hiddenLayer.Neurons.Length; j++) { // , momentumSpeedWeights[i, j] = _config.Momentum*momentumSpeedWeights[i, j] + nablaWeights[i, j]/batch.Count; // visibleLayer.Neurons[i].Weights[j] += learningRate * momentumSpeedWeights[i, j]; hiddenLayer.Neurons[j].Weights[i] = visibleLayer.Neurons[i].Weights[j]; } } if (_config.UseBiases) { for (int i = 0; i < hiddenLayer.Neurons.Length; i++) { momentumSpeedHiddenBiases[i] = _config.Momentum*momentumSpeedHiddenBiases[i] + nablaHiddenBiases[i]/batch.Count; hiddenLayer.Neurons[i].Bias += learningRate * momentumSpeedHiddenBiases[i]; } for (int i = 0; i < visibleLayer.Neurons.Length; i++) { momentumSpeedVisibleBiases[i] = _config.Momentum*momentumSpeedVisibleBiases[i] + nablaVisibleBiases[i]/batch.Count; visibleLayer.Neurons[i].Bias += learningRate * momentumSpeedVisibleBiases[i]; } }
- . , , / , , , . : . , , , . .
#region Logging and error calculation string msg = "Epoche #" + currentEpoche; #region calculate error if (currentEpoche % _config.CostFunctionRecalculationStep == 0) { #region calculating squared error with reconstruction IMetrics<double> sed = MetricsCreator.SquareEuclideanDistance(); double d = 0; foreach (DataItem<double> dataItem in data) { d += sed.Calculate(dataItem.Input, network.ComputeOutput(dataItem.Input)); } msg += "; SqDist is " + d; lastErrorChange = Math.Abs(lastError - d); lastError = d; #endregion } #endregion msg += "; Time: " + (DateTime.Now - dtStart).Duration().ToString(); Logger.Instance.Log(msg);
.
RBM
. , , , ( 260 29 29 ): .
:
LearningAlgorithmConfig:
LearningRate = 0.01
BatchSize = 10
RegularizationFactor = 0
MaxEpoches = 1000
MinError = 0
MinErrorChange = 0
CostFunctionRecalculationStep = 1
ErrorFunction =
Momentum = 0.9
NeuronLocalGainLimit: not setted
GibbsSamplingChainLength = 30
UseBiases = True
, 1000 . .. 10, 26 , 26000 . .
, (26 ) 13128, 76.
( , ):
:
, ( RBM).
, - , . , . 841 (29*29) . , 841 29 29 , , . , , , . :
MNIST : http://deeplearning.net/tutorial/_images/filters_at_epoch_14.png . , =)
RBM , , .
https://class.coursera.org/neuralnets-2012-001/ http://www.cs.toronto.edu/~hinton/absps/guideTR.pdf http://deeplearning.net/tutorial/rbm.html#contrastive-divergence-cd-k http://www.iro.umontreal.ca/~lisa/twiki/bin/view.cgi/Public/DBNEquations http://www.cs.toronto.edu/~kriz/learning-features-2009-TR.pdf
PS ambikontur !
UPD :
public void Train(IMultilayerNeuralNetwork network, IList<DataItem> data)
, . , .
LearningAlgorithmConfig config = new LearningAlgorithmConfig() { BatchSize = 10, // MaxEpoches = 1000, // GibbsSamplingChainLength = 30, // k CD-k LearningRate = 0.01, // CostFunctionRecalculationStep = 1, // Momentum = 0.9, // MinError = 0, // MinErrorChange = 0, // UseBiases = true // };
.
ILayer visibleLayer = network.Layers[0]; // RBM , ILayer hiddenLayer = network.Layers[1]; // if (!_config.UseBiases) // { for (int i = 0; i < visibleLayer.Neurons.Length; i++) { visibleLayer.Neurons[i].Bias = 0d; } for (int i = 0; i < hiddenLayer.Neurons.Length; i++) { hiddenLayer.Neurons[i].Bias = 0d; } } //init momentum // double[,] momentumSpeedWeights = new double[visibleLayer.Neurons.Length, hiddenLayer.Neurons.Length]; double[] momentumSpeedVisibleBiases = new double[visibleLayer.Neurons.Length]; double[] momentumSpeedHiddenBiases = new double[hiddenLayer.Neurons.Length]; //init stop factors bool stopFlag = false; double lastError = Double.MaxValue; // , double lastErrorChange = double.MaxValue; double learningRate = _config.LearningRate; int currentEpoche = 0; BatchEnumerator<DataItem<double>> batchEnumerator = new BatchEnumerator<DataItem<double>>(data, _config.BatchSize, true);
BatchEnumerator' , .
:
do { DateTime dtStart = DateTime.Now; //start batch processing foreach (IList<DataItem<double>> batch in batchEnumerator) { //batch gradient // , / double[,] nablaWeights = new double[visibleLayer.Neurons.Length, hiddenLayer.Neurons.Length]; double[] nablaHiddenBiases = new double[hiddenLayer.Neurons.Length]; double[] nablaVisibleBiases = new double[visibleLayer.Neurons.Length]; #region iterate through batch //... #endregion #region compute mean of wights nabla, and update them //... #endregion } #region Logging and error calculation //... #endregion // currentEpoche++; if (currentEpoche >= _config.MaxEpoches) { stopFlag = true; Logger.Instance.Log("Stop: currentEpoche:" + currentEpoche + " >= _config.MaxEpoches:" + _config.MaxEpoches); } else if (_config.MinError >= lastError) { stopFlag = true; Logger.Instance.Log("Stop: _config.MinError:" + _config.MinError + " >= lastError:" + lastError); } else if (_config.MinErrorChange >= lastErrorChange) { stopFlag = true; Logger.Instance.Log("Stop: _config.MinErrorChange:" + _config.MinErrorChange + " >= lastErrorChange:" + lastErrorChange); } } while (!stopFlag);
, Gibbs sampling, .
#region iterate through batch // foreach (DataItem<double> dataItem in batch) { //init visible layer states // / for (int i = 0; i < dataItem.Input.Length; i++) { visibleLayer.Neurons[i].LastState = dataItem.Input[i]; } #region Gibbs sampling for (int k = 0; k <= _config.GibbsSamplingChainLength; k++) { //calculate hidden states probabilities // , hiddenLayer.Compute(); #region accumulate negative phase // - , if (k == _config.GibbsSamplingChainLength) { for (int i = 0; i < visibleLayer.Neurons.Length; i++) { for (int j = 0; j < hiddenLayer.Neurons.Length; j++) { // nablaWeights[i, j] -= visibleLayer.Neurons[i].LastState * hiddenLayer.Neurons[j].LastState; } } if (_config.UseBiases) { for (int i = 0; i < hiddenLayer.Neurons.Length; i++) { nablaHiddenBiases[i] -= hiddenLayer.Neurons[i].LastState; } for (int i = 0; i < visibleLayer.Neurons.Length; i++) { nablaVisibleBiases[i] -= visibleLayer.Neurons[i].LastState; } } break; } #endregion //sample hidden states // , , , Gibbs sampling for (int i = 0; i < hiddenLayer.Neurons.Length; i++) { hiddenLayer.Neurons[i].LastState = _r.NextDouble() <= hiddenLayer.Neurons[i].LastState ? 1d : 0d; } #region accumulate positive phase // , if (k == 0) { for (int i = 0; i < visibleLayer.Neurons.Length; i++) { for (int j = 0; j < hiddenLayer.Neurons.Length; j++) { nablaWeights[i, j] += visibleLayer.Neurons[i].LastState* hiddenLayer.Neurons[j].LastState; } } if (_config.UseBiases) { for (int i = 0; i < hiddenLayer.Neurons.Length; i++) { nablaHiddenBiases[i] += hiddenLayer.Neurons[i].LastState; } for (int i = 0; i < visibleLayer.Neurons.Length; i++) { nablaVisibleBiases[i] += visibleLayer.Neurons[i].LastState; } } } #endregion //calculate visible probs // visibleLayer.Compute(); // , , , . ; //todo: may be not do sampling, like in 3.2 of http://www.cs.toronto.edu/~hinton/absps/guideTR.pdf //sample visible //for (int i = 0; i < visibleLayer.Neurons.Length; i++) //{ // visibleLayer.Neurons[i].LastState = _r.NextDouble() <= visibleLayer.Neurons[i].LastState ? 1d : 0d; //} } #endregion }
, . : ( ) . .
#region compute mean of wights nabla, and update them for (int i = 0; i < visibleLayer.Neurons.Length; i++) { for (int j = 0; j < hiddenLayer.Neurons.Length; j++) { // , momentumSpeedWeights[i, j] = _config.Momentum*momentumSpeedWeights[i, j] + nablaWeights[i, j]/batch.Count; // visibleLayer.Neurons[i].Weights[j] += learningRate * momentumSpeedWeights[i, j]; hiddenLayer.Neurons[j].Weights[i] = visibleLayer.Neurons[i].Weights[j]; } } if (_config.UseBiases) { for (int i = 0; i < hiddenLayer.Neurons.Length; i++) { momentumSpeedHiddenBiases[i] = _config.Momentum*momentumSpeedHiddenBiases[i] + nablaHiddenBiases[i]/batch.Count; hiddenLayer.Neurons[i].Bias += learningRate * momentumSpeedHiddenBiases[i]; } for (int i = 0; i < visibleLayer.Neurons.Length; i++) { momentumSpeedVisibleBiases[i] = _config.Momentum*momentumSpeedVisibleBiases[i] + nablaVisibleBiases[i]/batch.Count; visibleLayer.Neurons[i].Bias += learningRate * momentumSpeedVisibleBiases[i]; } }
- . , , / , , , . : . , , , . .
#region Logging and error calculation string msg = "Epoche #" + currentEpoche; #region calculate error if (currentEpoche % _config.CostFunctionRecalculationStep == 0) { #region calculating squared error with reconstruction IMetrics<double> sed = MetricsCreator.SquareEuclideanDistance(); double d = 0; foreach (DataItem<double> dataItem in data) { d += sed.Calculate(dataItem.Input, network.ComputeOutput(dataItem.Input)); } msg += "; SqDist is " + d; lastErrorChange = Math.Abs(lastError - d); lastError = d; #endregion } #endregion msg += "; Time: " + (DateTime.Now - dtStart).Duration().ToString(); Logger.Instance.Log(msg);
.
RBM
. , , , ( 260 29 29 ): .
:
LearningAlgorithmConfig:
LearningRate = 0.01
BatchSize = 10
RegularizationFactor = 0
MaxEpoches = 1000
MinError = 0
MinErrorChange = 0
CostFunctionRecalculationStep = 1
ErrorFunction =
Momentum = 0.9
NeuronLocalGainLimit: not setted
GibbsSamplingChainLength = 30
UseBiases = True
, 1000 . .. 10, 26 , 26000 . .
, (26 ) 13128, 76.
( , ):
:
, ( RBM).
, - , . , . 841 (29*29) . , 841 29 29 , , . , , , . :
MNIST : http://deeplearning.net/tutorial/_images/filters_at_epoch_14.png . , =)
RBM , , .
https://class.coursera.org/neuralnets-2012-001/ http://www.cs.toronto.edu/~hinton/absps/guideTR.pdf http://deeplearning.net/tutorial/rbm.html#contrastive-divergence-cd-k http://www.iro.umontreal.ca/~lisa/twiki/bin/view.cgi/Public/DBNEquations http://www.cs.toronto.edu/~kriz/learning-features-2009-TR.pdf
PS ambikontur !
UPD :
public void Train(IMultilayerNeuralNetwork network, IList<DataItem> data)
, . , .
LearningAlgorithmConfig config = new LearningAlgorithmConfig() { BatchSize = 10, // MaxEpoches = 1000, // GibbsSamplingChainLength = 30, // k CD-k LearningRate = 0.01, // CostFunctionRecalculationStep = 1, // Momentum = 0.9, // MinError = 0, // MinErrorChange = 0, // UseBiases = true // };
.
ILayer visibleLayer = network.Layers[0]; // RBM , ILayer hiddenLayer = network.Layers[1]; // if (!_config.UseBiases) // { for (int i = 0; i < visibleLayer.Neurons.Length; i++) { visibleLayer.Neurons[i].Bias = 0d; } for (int i = 0; i < hiddenLayer.Neurons.Length; i++) { hiddenLayer.Neurons[i].Bias = 0d; } } //init momentum // double[,] momentumSpeedWeights = new double[visibleLayer.Neurons.Length, hiddenLayer.Neurons.Length]; double[] momentumSpeedVisibleBiases = new double[visibleLayer.Neurons.Length]; double[] momentumSpeedHiddenBiases = new double[hiddenLayer.Neurons.Length]; //init stop factors bool stopFlag = false; double lastError = Double.MaxValue; // , double lastErrorChange = double.MaxValue; double learningRate = _config.LearningRate; int currentEpoche = 0; BatchEnumerator<DataItem<double>> batchEnumerator = new BatchEnumerator<DataItem<double>>(data, _config.BatchSize, true);
BatchEnumerator' , .
:
do { DateTime dtStart = DateTime.Now; //start batch processing foreach (IList<DataItem<double>> batch in batchEnumerator) { //batch gradient // , / double[,] nablaWeights = new double[visibleLayer.Neurons.Length, hiddenLayer.Neurons.Length]; double[] nablaHiddenBiases = new double[hiddenLayer.Neurons.Length]; double[] nablaVisibleBiases = new double[visibleLayer.Neurons.Length]; #region iterate through batch //... #endregion #region compute mean of wights nabla, and update them //... #endregion } #region Logging and error calculation //... #endregion // currentEpoche++; if (currentEpoche >= _config.MaxEpoches) { stopFlag = true; Logger.Instance.Log("Stop: currentEpoche:" + currentEpoche + " >= _config.MaxEpoches:" + _config.MaxEpoches); } else if (_config.MinError >= lastError) { stopFlag = true; Logger.Instance.Log("Stop: _config.MinError:" + _config.MinError + " >= lastError:" + lastError); } else if (_config.MinErrorChange >= lastErrorChange) { stopFlag = true; Logger.Instance.Log("Stop: _config.MinErrorChange:" + _config.MinErrorChange + " >= lastErrorChange:" + lastErrorChange); } } while (!stopFlag);
, Gibbs sampling, .
#region iterate through batch // foreach (DataItem<double> dataItem in batch) { //init visible layer states // / for (int i = 0; i < dataItem.Input.Length; i++) { visibleLayer.Neurons[i].LastState = dataItem.Input[i]; } #region Gibbs sampling for (int k = 0; k <= _config.GibbsSamplingChainLength; k++) { //calculate hidden states probabilities // , hiddenLayer.Compute(); #region accumulate negative phase // - , if (k == _config.GibbsSamplingChainLength) { for (int i = 0; i < visibleLayer.Neurons.Length; i++) { for (int j = 0; j < hiddenLayer.Neurons.Length; j++) { // nablaWeights[i, j] -= visibleLayer.Neurons[i].LastState * hiddenLayer.Neurons[j].LastState; } } if (_config.UseBiases) { for (int i = 0; i < hiddenLayer.Neurons.Length; i++) { nablaHiddenBiases[i] -= hiddenLayer.Neurons[i].LastState; } for (int i = 0; i < visibleLayer.Neurons.Length; i++) { nablaVisibleBiases[i] -= visibleLayer.Neurons[i].LastState; } } break; } #endregion //sample hidden states // , , , Gibbs sampling for (int i = 0; i < hiddenLayer.Neurons.Length; i++) { hiddenLayer.Neurons[i].LastState = _r.NextDouble() <= hiddenLayer.Neurons[i].LastState ? 1d : 0d; } #region accumulate positive phase // , if (k == 0) { for (int i = 0; i < visibleLayer.Neurons.Length; i++) { for (int j = 0; j < hiddenLayer.Neurons.Length; j++) { nablaWeights[i, j] += visibleLayer.Neurons[i].LastState* hiddenLayer.Neurons[j].LastState; } } if (_config.UseBiases) { for (int i = 0; i < hiddenLayer.Neurons.Length; i++) { nablaHiddenBiases[i] += hiddenLayer.Neurons[i].LastState; } for (int i = 0; i < visibleLayer.Neurons.Length; i++) { nablaVisibleBiases[i] += visibleLayer.Neurons[i].LastState; } } } #endregion //calculate visible probs // visibleLayer.Compute(); // , , , . ; //todo: may be not do sampling, like in 3.2 of http://www.cs.toronto.edu/~hinton/absps/guideTR.pdf //sample visible //for (int i = 0; i < visibleLayer.Neurons.Length; i++) //{ // visibleLayer.Neurons[i].LastState = _r.NextDouble() <= visibleLayer.Neurons[i].LastState ? 1d : 0d; //} } #endregion }
, . : ( ) . .
#region compute mean of wights nabla, and update them for (int i = 0; i < visibleLayer.Neurons.Length; i++) { for (int j = 0; j < hiddenLayer.Neurons.Length; j++) { // , momentumSpeedWeights[i, j] = _config.Momentum*momentumSpeedWeights[i, j] + nablaWeights[i, j]/batch.Count; // visibleLayer.Neurons[i].Weights[j] += learningRate * momentumSpeedWeights[i, j]; hiddenLayer.Neurons[j].Weights[i] = visibleLayer.Neurons[i].Weights[j]; } } if (_config.UseBiases) { for (int i = 0; i < hiddenLayer.Neurons.Length; i++) { momentumSpeedHiddenBiases[i] = _config.Momentum*momentumSpeedHiddenBiases[i] + nablaHiddenBiases[i]/batch.Count; hiddenLayer.Neurons[i].Bias += learningRate * momentumSpeedHiddenBiases[i]; } for (int i = 0; i < visibleLayer.Neurons.Length; i++) { momentumSpeedVisibleBiases[i] = _config.Momentum*momentumSpeedVisibleBiases[i] + nablaVisibleBiases[i]/batch.Count; visibleLayer.Neurons[i].Bias += learningRate * momentumSpeedVisibleBiases[i]; } }
- . , , / , , , . : . , , , . .
#region Logging and error calculation string msg = "Epoche #" + currentEpoche; #region calculate error if (currentEpoche % _config.CostFunctionRecalculationStep == 0) { #region calculating squared error with reconstruction IMetrics<double> sed = MetricsCreator.SquareEuclideanDistance(); double d = 0; foreach (DataItem<double> dataItem in data) { d += sed.Calculate(dataItem.Input, network.ComputeOutput(dataItem.Input)); } msg += "; SqDist is " + d; lastErrorChange = Math.Abs(lastError - d); lastError = d; #endregion } #endregion msg += "; Time: " + (DateTime.Now - dtStart).Duration().ToString(); Logger.Instance.Log(msg);
.
RBM
. , , , ( 260 29 29 ): .
:
LearningAlgorithmConfig:
LearningRate = 0.01
BatchSize = 10
RegularizationFactor = 0
MaxEpoches = 1000
MinError = 0
MinErrorChange = 0
CostFunctionRecalculationStep = 1
ErrorFunction =
Momentum = 0.9
NeuronLocalGainLimit: not setted
GibbsSamplingChainLength = 30
UseBiases = True
, 1000 . .. 10, 26 , 26000 . .
, (26 ) 13128, 76.
( , ):
:
, ( RBM).
, - , . , . 841 (29*29) . , 841 29 29 , , . , , , . :
MNIST : http://deeplearning.net/tutorial/_images/filters_at_epoch_14.png . , =)
RBM , , .
https://class.coursera.org/neuralnets-2012-001/ http://www.cs.toronto.edu/~hinton/absps/guideTR.pdf http://deeplearning.net/tutorial/rbm.html#contrastive-divergence-cd-k http://www.iro.umontreal.ca/~lisa/twiki/bin/view.cgi/Public/DBNEquations http://www.cs.toronto.edu/~kriz/learning-features-2009-TR.pdf
PS ambikontur !
UPD :
public void Train(IMultilayerNeuralNetwork network, IList<DataItem> data)
, . , .
LearningAlgorithmConfig config = new LearningAlgorithmConfig() { BatchSize = 10, // MaxEpoches = 1000, // GibbsSamplingChainLength = 30, // k CD-k LearningRate = 0.01, // CostFunctionRecalculationStep = 1, // Momentum = 0.9, // MinError = 0, // MinErrorChange = 0, // UseBiases = true // };
.
ILayer visibleLayer = network.Layers[0]; // RBM , ILayer hiddenLayer = network.Layers[1]; // if (!_config.UseBiases) // { for (int i = 0; i < visibleLayer.Neurons.Length; i++) { visibleLayer.Neurons[i].Bias = 0d; } for (int i = 0; i < hiddenLayer.Neurons.Length; i++) { hiddenLayer.Neurons[i].Bias = 0d; } } //init momentum // double[,] momentumSpeedWeights = new double[visibleLayer.Neurons.Length, hiddenLayer.Neurons.Length]; double[] momentumSpeedVisibleBiases = new double[visibleLayer.Neurons.Length]; double[] momentumSpeedHiddenBiases = new double[hiddenLayer.Neurons.Length]; //init stop factors bool stopFlag = false; double lastError = Double.MaxValue; // , double lastErrorChange = double.MaxValue; double learningRate = _config.LearningRate; int currentEpoche = 0; BatchEnumerator<DataItem<double>> batchEnumerator = new BatchEnumerator<DataItem<double>>(data, _config.BatchSize, true);
BatchEnumerator' , .
:
do { DateTime dtStart = DateTime.Now; //start batch processing foreach (IList<DataItem<double>> batch in batchEnumerator) { //batch gradient // , / double[,] nablaWeights = new double[visibleLayer.Neurons.Length, hiddenLayer.Neurons.Length]; double[] nablaHiddenBiases = new double[hiddenLayer.Neurons.Length]; double[] nablaVisibleBiases = new double[visibleLayer.Neurons.Length]; #region iterate through batch //... #endregion #region compute mean of wights nabla, and update them //... #endregion } #region Logging and error calculation //... #endregion // currentEpoche++; if (currentEpoche >= _config.MaxEpoches) { stopFlag = true; Logger.Instance.Log("Stop: currentEpoche:" + currentEpoche + " >= _config.MaxEpoches:" + _config.MaxEpoches); } else if (_config.MinError >= lastError) { stopFlag = true; Logger.Instance.Log("Stop: _config.MinError:" + _config.MinError + " >= lastError:" + lastError); } else if (_config.MinErrorChange >= lastErrorChange) { stopFlag = true; Logger.Instance.Log("Stop: _config.MinErrorChange:" + _config.MinErrorChange + " >= lastErrorChange:" + lastErrorChange); } } while (!stopFlag);
, Gibbs sampling, .
#region iterate through batch // foreach (DataItem<double> dataItem in batch) { //init visible layer states // / for (int i = 0; i < dataItem.Input.Length; i++) { visibleLayer.Neurons[i].LastState = dataItem.Input[i]; } #region Gibbs sampling for (int k = 0; k <= _config.GibbsSamplingChainLength; k++) { //calculate hidden states probabilities // , hiddenLayer.Compute(); #region accumulate negative phase // - , if (k == _config.GibbsSamplingChainLength) { for (int i = 0; i < visibleLayer.Neurons.Length; i++) { for (int j = 0; j < hiddenLayer.Neurons.Length; j++) { // nablaWeights[i, j] -= visibleLayer.Neurons[i].LastState * hiddenLayer.Neurons[j].LastState; } } if (_config.UseBiases) { for (int i = 0; i < hiddenLayer.Neurons.Length; i++) { nablaHiddenBiases[i] -= hiddenLayer.Neurons[i].LastState; } for (int i = 0; i < visibleLayer.Neurons.Length; i++) { nablaVisibleBiases[i] -= visibleLayer.Neurons[i].LastState; } } break; } #endregion //sample hidden states // , , , Gibbs sampling for (int i = 0; i < hiddenLayer.Neurons.Length; i++) { hiddenLayer.Neurons[i].LastState = _r.NextDouble() <= hiddenLayer.Neurons[i].LastState ? 1d : 0d; } #region accumulate positive phase // , if (k == 0) { for (int i = 0; i < visibleLayer.Neurons.Length; i++) { for (int j = 0; j < hiddenLayer.Neurons.Length; j++) { nablaWeights[i, j] += visibleLayer.Neurons[i].LastState* hiddenLayer.Neurons[j].LastState; } } if (_config.UseBiases) { for (int i = 0; i < hiddenLayer.Neurons.Length; i++) { nablaHiddenBiases[i] += hiddenLayer.Neurons[i].LastState; } for (int i = 0; i < visibleLayer.Neurons.Length; i++) { nablaVisibleBiases[i] += visibleLayer.Neurons[i].LastState; } } } #endregion //calculate visible probs // visibleLayer.Compute(); // , , , . ; //todo: may be not do sampling, like in 3.2 of http://www.cs.toronto.edu/~hinton/absps/guideTR.pdf //sample visible //for (int i = 0; i < visibleLayer.Neurons.Length; i++) //{ // visibleLayer.Neurons[i].LastState = _r.NextDouble() <= visibleLayer.Neurons[i].LastState ? 1d : 0d; //} } #endregion }
, . : ( ) . .
#region compute mean of wights nabla, and update them for (int i = 0; i < visibleLayer.Neurons.Length; i++) { for (int j = 0; j < hiddenLayer.Neurons.Length; j++) { // , momentumSpeedWeights[i, j] = _config.Momentum*momentumSpeedWeights[i, j] + nablaWeights[i, j]/batch.Count; // visibleLayer.Neurons[i].Weights[j] += learningRate * momentumSpeedWeights[i, j]; hiddenLayer.Neurons[j].Weights[i] = visibleLayer.Neurons[i].Weights[j]; } } if (_config.UseBiases) { for (int i = 0; i < hiddenLayer.Neurons.Length; i++) { momentumSpeedHiddenBiases[i] = _config.Momentum*momentumSpeedHiddenBiases[i] + nablaHiddenBiases[i]/batch.Count; hiddenLayer.Neurons[i].Bias += learningRate * momentumSpeedHiddenBiases[i]; } for (int i = 0; i < visibleLayer.Neurons.Length; i++) { momentumSpeedVisibleBiases[i] = _config.Momentum*momentumSpeedVisibleBiases[i] + nablaVisibleBiases[i]/batch.Count; visibleLayer.Neurons[i].Bias += learningRate * momentumSpeedVisibleBiases[i]; } }
- . , , / , , , . : . , , , . .
#region Logging and error calculation string msg = "Epoche #" + currentEpoche; #region calculate error if (currentEpoche % _config.CostFunctionRecalculationStep == 0) { #region calculating squared error with reconstruction IMetrics<double> sed = MetricsCreator.SquareEuclideanDistance(); double d = 0; foreach (DataItem<double> dataItem in data) { d += sed.Calculate(dataItem.Input, network.ComputeOutput(dataItem.Input)); } msg += "; SqDist is " + d; lastErrorChange = Math.Abs(lastError - d); lastError = d; #endregion } #endregion msg += "; Time: " + (DateTime.Now - dtStart).Duration().ToString(); Logger.Instance.Log(msg);
.
RBM
. , , , ( 260 29 29 ): .
:
LearningAlgorithmConfig:
LearningRate = 0.01
BatchSize = 10
RegularizationFactor = 0
MaxEpoches = 1000
MinError = 0
MinErrorChange = 0
CostFunctionRecalculationStep = 1
ErrorFunction =
Momentum = 0.9
NeuronLocalGainLimit: not setted
GibbsSamplingChainLength = 30
UseBiases = True
, 1000 . .. 10, 26 , 26000 . .
, (26 ) 13128, 76.
( , ):
:
, ( RBM).
, - , . , . 841 (29*29) . , 841 29 29 , , . , , , . :
MNIST : http://deeplearning.net/tutorial/_images/filters_at_epoch_14.png . , =)
RBM , , .
https://class.coursera.org/neuralnets-2012-001/ http://www.cs.toronto.edu/~hinton/absps/guideTR.pdf http://deeplearning.net/tutorial/rbm.html#contrastive-divergence-cd-k http://www.iro.umontreal.ca/~lisa/twiki/bin/view.cgi/Public/DBNEquations http://www.cs.toronto.edu/~kriz/learning-features-2009-TR.pdf
PS ambikontur !
UPD :
public void Train(IMultilayerNeuralNetwork network, IList<DataItem> data)
, . , .
LearningAlgorithmConfig config = new LearningAlgorithmConfig() { BatchSize = 10, // MaxEpoches = 1000, // GibbsSamplingChainLength = 30, // k CD-k LearningRate = 0.01, // CostFunctionRecalculationStep = 1, // Momentum = 0.9, // MinError = 0, // MinErrorChange = 0, // UseBiases = true // };
.
ILayer visibleLayer = network.Layers[0]; // RBM , ILayer hiddenLayer = network.Layers[1]; // if (!_config.UseBiases) // { for (int i = 0; i < visibleLayer.Neurons.Length; i++) { visibleLayer.Neurons[i].Bias = 0d; } for (int i = 0; i < hiddenLayer.Neurons.Length; i++) { hiddenLayer.Neurons[i].Bias = 0d; } } //init momentum // double[,] momentumSpeedWeights = new double[visibleLayer.Neurons.Length, hiddenLayer.Neurons.Length]; double[] momentumSpeedVisibleBiases = new double[visibleLayer.Neurons.Length]; double[] momentumSpeedHiddenBiases = new double[hiddenLayer.Neurons.Length]; //init stop factors bool stopFlag = false; double lastError = Double.MaxValue; // , double lastErrorChange = double.MaxValue; double learningRate = _config.LearningRate; int currentEpoche = 0; BatchEnumerator<DataItem<double>> batchEnumerator = new BatchEnumerator<DataItem<double>>(data, _config.BatchSize, true);
BatchEnumerator' , .
:
do { DateTime dtStart = DateTime.Now; //start batch processing foreach (IList<DataItem<double>> batch in batchEnumerator) { //batch gradient // , / double[,] nablaWeights = new double[visibleLayer.Neurons.Length, hiddenLayer.Neurons.Length]; double[] nablaHiddenBiases = new double[hiddenLayer.Neurons.Length]; double[] nablaVisibleBiases = new double[visibleLayer.Neurons.Length]; #region iterate through batch //... #endregion #region compute mean of wights nabla, and update them //... #endregion } #region Logging and error calculation //... #endregion // currentEpoche++; if (currentEpoche >= _config.MaxEpoches) { stopFlag = true; Logger.Instance.Log("Stop: currentEpoche:" + currentEpoche + " >= _config.MaxEpoches:" + _config.MaxEpoches); } else if (_config.MinError >= lastError) { stopFlag = true; Logger.Instance.Log("Stop: _config.MinError:" + _config.MinError + " >= lastError:" + lastError); } else if (_config.MinErrorChange >= lastErrorChange) { stopFlag = true; Logger.Instance.Log("Stop: _config.MinErrorChange:" + _config.MinErrorChange + " >= lastErrorChange:" + lastErrorChange); } } while (!stopFlag);
, Gibbs sampling, .
#region iterate through batch // foreach (DataItem<double> dataItem in batch) { //init visible layer states // / for (int i = 0; i < dataItem.Input.Length; i++) { visibleLayer.Neurons[i].LastState = dataItem.Input[i]; } #region Gibbs sampling for (int k = 0; k <= _config.GibbsSamplingChainLength; k++) { //calculate hidden states probabilities // , hiddenLayer.Compute(); #region accumulate negative phase // - , if (k == _config.GibbsSamplingChainLength) { for (int i = 0; i < visibleLayer.Neurons.Length; i++) { for (int j = 0; j < hiddenLayer.Neurons.Length; j++) { // nablaWeights[i, j] -= visibleLayer.Neurons[i].LastState * hiddenLayer.Neurons[j].LastState; } } if (_config.UseBiases) { for (int i = 0; i < hiddenLayer.Neurons.Length; i++) { nablaHiddenBiases[i] -= hiddenLayer.Neurons[i].LastState; } for (int i = 0; i < visibleLayer.Neurons.Length; i++) { nablaVisibleBiases[i] -= visibleLayer.Neurons[i].LastState; } } break; } #endregion //sample hidden states // , , , Gibbs sampling for (int i = 0; i < hiddenLayer.Neurons.Length; i++) { hiddenLayer.Neurons[i].LastState = _r.NextDouble() <= hiddenLayer.Neurons[i].LastState ? 1d : 0d; } #region accumulate positive phase // , if (k == 0) { for (int i = 0; i < visibleLayer.Neurons.Length; i++) { for (int j = 0; j < hiddenLayer.Neurons.Length; j++) { nablaWeights[i, j] += visibleLayer.Neurons[i].LastState* hiddenLayer.Neurons[j].LastState; } } if (_config.UseBiases) { for (int i = 0; i < hiddenLayer.Neurons.Length; i++) { nablaHiddenBiases[i] += hiddenLayer.Neurons[i].LastState; } for (int i = 0; i < visibleLayer.Neurons.Length; i++) { nablaVisibleBiases[i] += visibleLayer.Neurons[i].LastState; } } } #endregion //calculate visible probs // visibleLayer.Compute(); // , , , . ; //todo: may be not do sampling, like in 3.2 of http://www.cs.toronto.edu/~hinton/absps/guideTR.pdf //sample visible //for (int i = 0; i < visibleLayer.Neurons.Length; i++) //{ // visibleLayer.Neurons[i].LastState = _r.NextDouble() <= visibleLayer.Neurons[i].LastState ? 1d : 0d; //} } #endregion }
, . : ( ) . .
#region compute mean of wights nabla, and update them for (int i = 0; i < visibleLayer.Neurons.Length; i++) { for (int j = 0; j < hiddenLayer.Neurons.Length; j++) { // , momentumSpeedWeights[i, j] = _config.Momentum*momentumSpeedWeights[i, j] + nablaWeights[i, j]/batch.Count; // visibleLayer.Neurons[i].Weights[j] += learningRate * momentumSpeedWeights[i, j]; hiddenLayer.Neurons[j].Weights[i] = visibleLayer.Neurons[i].Weights[j]; } } if (_config.UseBiases) { for (int i = 0; i < hiddenLayer.Neurons.Length; i++) { momentumSpeedHiddenBiases[i] = _config.Momentum*momentumSpeedHiddenBiases[i] + nablaHiddenBiases[i]/batch.Count; hiddenLayer.Neurons[i].Bias += learningRate * momentumSpeedHiddenBiases[i]; } for (int i = 0; i < visibleLayer.Neurons.Length; i++) { momentumSpeedVisibleBiases[i] = _config.Momentum*momentumSpeedVisibleBiases[i] + nablaVisibleBiases[i]/batch.Count; visibleLayer.Neurons[i].Bias += learningRate * momentumSpeedVisibleBiases[i]; } }
- . , , / , , , . : . , , , . .
#region Logging and error calculation string msg = "Epoche #" + currentEpoche; #region calculate error if (currentEpoche % _config.CostFunctionRecalculationStep == 0) { #region calculating squared error with reconstruction IMetrics<double> sed = MetricsCreator.SquareEuclideanDistance(); double d = 0; foreach (DataItem<double> dataItem in data) { d += sed.Calculate(dataItem.Input, network.ComputeOutput(dataItem.Input)); } msg += "; SqDist is " + d; lastErrorChange = Math.Abs(lastError - d); lastError = d; #endregion } #endregion msg += "; Time: " + (DateTime.Now - dtStart).Duration().ToString(); Logger.Instance.Log(msg);
.
RBM
. , , , ( 260 29 29 ): .
:
LearningAlgorithmConfig:
LearningRate = 0.01
BatchSize = 10
RegularizationFactor = 0
MaxEpoches = 1000
MinError = 0
MinErrorChange = 0
CostFunctionRecalculationStep = 1
ErrorFunction =
Momentum = 0.9
NeuronLocalGainLimit: not setted
GibbsSamplingChainLength = 30
UseBiases = True
, 1000 . .. 10, 26 , 26000 . .
, (26 ) 13128, 76.
( , ):
:
, ( RBM).
, - , . , . 841 (29*29) . , 841 29 29 , , . , , , . :
MNIST : http://deeplearning.net/tutorial/_images/filters_at_epoch_14.png . , =)
RBM , , .
https://class.coursera.org/neuralnets-2012-001/ http://www.cs.toronto.edu/~hinton/absps/guideTR.pdf http://deeplearning.net/tutorial/rbm.html#contrastive-divergence-cd-k http://www.iro.umontreal.ca/~lisa/twiki/bin/view.cgi/Public/DBNEquations http://www.cs.toronto.edu/~kriz/learning-features-2009-TR.pdf
PS ambikontur !
UPD :
public void Train(IMultilayerNeuralNetwork network, IList<DataItem> data)
, . , .
LearningAlgorithmConfig config = new LearningAlgorithmConfig() { BatchSize = 10, // MaxEpoches = 1000, // GibbsSamplingChainLength = 30, // k CD-k LearningRate = 0.01, // CostFunctionRecalculationStep = 1, // Momentum = 0.9, // MinError = 0, // MinErrorChange = 0, // UseBiases = true // };
.
ILayer visibleLayer = network.Layers[0]; // RBM , ILayer hiddenLayer = network.Layers[1]; // if (!_config.UseBiases) // { for (int i = 0; i < visibleLayer.Neurons.Length; i++) { visibleLayer.Neurons[i].Bias = 0d; } for (int i = 0; i < hiddenLayer.Neurons.Length; i++) { hiddenLayer.Neurons[i].Bias = 0d; } } //init momentum // double[,] momentumSpeedWeights = new double[visibleLayer.Neurons.Length, hiddenLayer.Neurons.Length]; double[] momentumSpeedVisibleBiases = new double[visibleLayer.Neurons.Length]; double[] momentumSpeedHiddenBiases = new double[hiddenLayer.Neurons.Length]; //init stop factors bool stopFlag = false; double lastError = Double.MaxValue; // , double lastErrorChange = double.MaxValue; double learningRate = _config.LearningRate; int currentEpoche = 0; BatchEnumerator<DataItem<double>> batchEnumerator = new BatchEnumerator<DataItem<double>>(data, _config.BatchSize, true);
BatchEnumerator' , .
:
do { DateTime dtStart = DateTime.Now; //start batch processing foreach (IList<DataItem<double>> batch in batchEnumerator) { //batch gradient // , / double[,] nablaWeights = new double[visibleLayer.Neurons.Length, hiddenLayer.Neurons.Length]; double[] nablaHiddenBiases = new double[hiddenLayer.Neurons.Length]; double[] nablaVisibleBiases = new double[visibleLayer.Neurons.Length]; #region iterate through batch //... #endregion #region compute mean of wights nabla, and update them //... #endregion } #region Logging and error calculation //... #endregion // currentEpoche++; if (currentEpoche >= _config.MaxEpoches) { stopFlag = true; Logger.Instance.Log("Stop: currentEpoche:" + currentEpoche + " >= _config.MaxEpoches:" + _config.MaxEpoches); } else if (_config.MinError >= lastError) { stopFlag = true; Logger.Instance.Log("Stop: _config.MinError:" + _config.MinError + " >= lastError:" + lastError); } else if (_config.MinErrorChange >= lastErrorChange) { stopFlag = true; Logger.Instance.Log("Stop: _config.MinErrorChange:" + _config.MinErrorChange + " >= lastErrorChange:" + lastErrorChange); } } while (!stopFlag);
, Gibbs sampling, .
#region iterate through batch // foreach (DataItem<double> dataItem in batch) { //init visible layer states // / for (int i = 0; i < dataItem.Input.Length; i++) { visibleLayer.Neurons[i].LastState = dataItem.Input[i]; } #region Gibbs sampling for (int k = 0; k <= _config.GibbsSamplingChainLength; k++) { //calculate hidden states probabilities // , hiddenLayer.Compute(); #region accumulate negative phase // - , if (k == _config.GibbsSamplingChainLength) { for (int i = 0; i < visibleLayer.Neurons.Length; i++) { for (int j = 0; j < hiddenLayer.Neurons.Length; j++) { // nablaWeights[i, j] -= visibleLayer.Neurons[i].LastState * hiddenLayer.Neurons[j].LastState; } } if (_config.UseBiases) { for (int i = 0; i < hiddenLayer.Neurons.Length; i++) { nablaHiddenBiases[i] -= hiddenLayer.Neurons[i].LastState; } for (int i = 0; i < visibleLayer.Neurons.Length; i++) { nablaVisibleBiases[i] -= visibleLayer.Neurons[i].LastState; } } break; } #endregion //sample hidden states // , , , Gibbs sampling for (int i = 0; i < hiddenLayer.Neurons.Length; i++) { hiddenLayer.Neurons[i].LastState = _r.NextDouble() <= hiddenLayer.Neurons[i].LastState ? 1d : 0d; } #region accumulate positive phase // , if (k == 0) { for (int i = 0; i < visibleLayer.Neurons.Length; i++) { for (int j = 0; j < hiddenLayer.Neurons.Length; j++) { nablaWeights[i, j] += visibleLayer.Neurons[i].LastState* hiddenLayer.Neurons[j].LastState; } } if (_config.UseBiases) { for (int i = 0; i < hiddenLayer.Neurons.Length; i++) { nablaHiddenBiases[i] += hiddenLayer.Neurons[i].LastState; } for (int i = 0; i < visibleLayer.Neurons.Length; i++) { nablaVisibleBiases[i] += visibleLayer.Neurons[i].LastState; } } } #endregion //calculate visible probs // visibleLayer.Compute(); // , , , . ; //todo: may be not do sampling, like in 3.2 of http://www.cs.toronto.edu/~hinton/absps/guideTR.pdf //sample visible //for (int i = 0; i < visibleLayer.Neurons.Length; i++) //{ // visibleLayer.Neurons[i].LastState = _r.NextDouble() <= visibleLayer.Neurons[i].LastState ? 1d : 0d; //} } #endregion }
, . : ( ) . .
#region compute mean of wights nabla, and update them for (int i = 0; i < visibleLayer.Neurons.Length; i++) { for (int j = 0; j < hiddenLayer.Neurons.Length; j++) { // , momentumSpeedWeights[i, j] = _config.Momentum*momentumSpeedWeights[i, j] + nablaWeights[i, j]/batch.Count; // visibleLayer.Neurons[i].Weights[j] += learningRate * momentumSpeedWeights[i, j]; hiddenLayer.Neurons[j].Weights[i] = visibleLayer.Neurons[i].Weights[j]; } } if (_config.UseBiases) { for (int i = 0; i < hiddenLayer.Neurons.Length; i++) { momentumSpeedHiddenBiases[i] = _config.Momentum*momentumSpeedHiddenBiases[i] + nablaHiddenBiases[i]/batch.Count; hiddenLayer.Neurons[i].Bias += learningRate * momentumSpeedHiddenBiases[i]; } for (int i = 0; i < visibleLayer.Neurons.Length; i++) { momentumSpeedVisibleBiases[i] = _config.Momentum*momentumSpeedVisibleBiases[i] + nablaVisibleBiases[i]/batch.Count; visibleLayer.Neurons[i].Bias += learningRate * momentumSpeedVisibleBiases[i]; } }
- . , , / , , , . : . , , , . .
#region Logging and error calculation string msg = "Epoche #" + currentEpoche; #region calculate error if (currentEpoche % _config.CostFunctionRecalculationStep == 0) { #region calculating squared error with reconstruction IMetrics<double> sed = MetricsCreator.SquareEuclideanDistance(); double d = 0; foreach (DataItem<double> dataItem in data) { d += sed.Calculate(dataItem.Input, network.ComputeOutput(dataItem.Input)); } msg += "; SqDist is " + d; lastErrorChange = Math.Abs(lastError - d); lastError = d; #endregion } #endregion msg += "; Time: " + (DateTime.Now - dtStart).Duration().ToString(); Logger.Instance.Log(msg);
.
RBM
. , , , ( 260 29 29 ): .
:
LearningAlgorithmConfig:
LearningRate = 0.01
BatchSize = 10
RegularizationFactor = 0
MaxEpoches = 1000
MinError = 0
MinErrorChange = 0
CostFunctionRecalculationStep = 1
ErrorFunction =
Momentum = 0.9
NeuronLocalGainLimit: not setted
GibbsSamplingChainLength = 30
UseBiases = True
, 1000 . .. 10, 26 , 26000 . .
, (26 ) 13128, 76.
( , ):
:
, ( RBM).
, - , . , . 841 (29*29) . , 841 29 29 , , . , , , . :
MNIST : http://deeplearning.net/tutorial/_images/filters_at_epoch_14.png . , =)
RBM , , .
https://class.coursera.org/neuralnets-2012-001/ http://www.cs.toronto.edu/~hinton/absps/guideTR.pdf http://deeplearning.net/tutorial/rbm.html#contrastive-divergence-cd-k http://www.iro.umontreal.ca/~lisa/twiki/bin/view.cgi/Public/DBNEquations http://www.cs.toronto.edu/~kriz/learning-features-2009-TR.pdf
PS ambikontur !
UPD :
public void Train(IMultilayerNeuralNetwork network, IList<DataItem> data)
, . , .
LearningAlgorithmConfig config = new LearningAlgorithmConfig() { BatchSize = 10, // MaxEpoches = 1000, // GibbsSamplingChainLength = 30, // k CD-k LearningRate = 0.01, // CostFunctionRecalculationStep = 1, // Momentum = 0.9, // MinError = 0, // MinErrorChange = 0, // UseBiases = true // };
.
ILayer visibleLayer = network.Layers[0]; // RBM , ILayer hiddenLayer = network.Layers[1]; // if (!_config.UseBiases) // { for (int i = 0; i < visibleLayer.Neurons.Length; i++) { visibleLayer.Neurons[i].Bias = 0d; } for (int i = 0; i < hiddenLayer.Neurons.Length; i++) { hiddenLayer.Neurons[i].Bias = 0d; } } //init momentum // double[,] momentumSpeedWeights = new double[visibleLayer.Neurons.Length, hiddenLayer.Neurons.Length]; double[] momentumSpeedVisibleBiases = new double[visibleLayer.Neurons.Length]; double[] momentumSpeedHiddenBiases = new double[hiddenLayer.Neurons.Length]; //init stop factors bool stopFlag = false; double lastError = Double.MaxValue; // , double lastErrorChange = double.MaxValue; double learningRate = _config.LearningRate; int currentEpoche = 0; BatchEnumerator<DataItem<double>> batchEnumerator = new BatchEnumerator<DataItem<double>>(data, _config.BatchSize, true);
BatchEnumerator' , .
:
do { DateTime dtStart = DateTime.Now; //start batch processing foreach (IList<DataItem<double>> batch in batchEnumerator) { //batch gradient // , / double[,] nablaWeights = new double[visibleLayer.Neurons.Length, hiddenLayer.Neurons.Length]; double[] nablaHiddenBiases = new double[hiddenLayer.Neurons.Length]; double[] nablaVisibleBiases = new double[visibleLayer.Neurons.Length]; #region iterate through batch //... #endregion #region compute mean of wights nabla, and update them //... #endregion } #region Logging and error calculation //... #endregion // currentEpoche++; if (currentEpoche >= _config.MaxEpoches) { stopFlag = true; Logger.Instance.Log("Stop: currentEpoche:" + currentEpoche + " >= _config.MaxEpoches:" + _config.MaxEpoches); } else if (_config.MinError >= lastError) { stopFlag = true; Logger.Instance.Log("Stop: _config.MinError:" + _config.MinError + " >= lastError:" + lastError); } else if (_config.MinErrorChange >= lastErrorChange) { stopFlag = true; Logger.Instance.Log("Stop: _config.MinErrorChange:" + _config.MinErrorChange + " >= lastErrorChange:" + lastErrorChange); } } while (!stopFlag);
, Gibbs sampling, .
#region iterate through batch // foreach (DataItem<double> dataItem in batch) { //init visible layer states // / for (int i = 0; i < dataItem.Input.Length; i++) { visibleLayer.Neurons[i].LastState = dataItem.Input[i]; } #region Gibbs sampling for (int k = 0; k <= _config.GibbsSamplingChainLength; k++) { //calculate hidden states probabilities // , hiddenLayer.Compute(); #region accumulate negative phase // - , if (k == _config.GibbsSamplingChainLength) { for (int i = 0; i < visibleLayer.Neurons.Length; i++) { for (int j = 0; j < hiddenLayer.Neurons.Length; j++) { // nablaWeights[i, j] -= visibleLayer.Neurons[i].LastState * hiddenLayer.Neurons[j].LastState; } } if (_config.UseBiases) { for (int i = 0; i < hiddenLayer.Neurons.Length; i++) { nablaHiddenBiases[i] -= hiddenLayer.Neurons[i].LastState; } for (int i = 0; i < visibleLayer.Neurons.Length; i++) { nablaVisibleBiases[i] -= visibleLayer.Neurons[i].LastState; } } break; } #endregion //sample hidden states // , , , Gibbs sampling for (int i = 0; i < hiddenLayer.Neurons.Length; i++) { hiddenLayer.Neurons[i].LastState = _r.NextDouble() <= hiddenLayer.Neurons[i].LastState ? 1d : 0d; } #region accumulate positive phase // , if (k == 0) { for (int i = 0; i < visibleLayer.Neurons.Length; i++) { for (int j = 0; j < hiddenLayer.Neurons.Length; j++) { nablaWeights[i, j] += visibleLayer.Neurons[i].LastState* hiddenLayer.Neurons[j].LastState; } } if (_config.UseBiases) { for (int i = 0; i < hiddenLayer.Neurons.Length; i++) { nablaHiddenBiases[i] += hiddenLayer.Neurons[i].LastState; } for (int i = 0; i < visibleLayer.Neurons.Length; i++) { nablaVisibleBiases[i] += visibleLayer.Neurons[i].LastState; } } } #endregion //calculate visible probs // visibleLayer.Compute(); // , , , . ; //todo: may be not do sampling, like in 3.2 of http://www.cs.toronto.edu/~hinton/absps/guideTR.pdf //sample visible //for (int i = 0; i < visibleLayer.Neurons.Length; i++) //{ // visibleLayer.Neurons[i].LastState = _r.NextDouble() <= visibleLayer.Neurons[i].LastState ? 1d : 0d; //} } #endregion }
, . : ( ) . .
#region compute mean of wights nabla, and update them for (int i = 0; i < visibleLayer.Neurons.Length; i++) { for (int j = 0; j < hiddenLayer.Neurons.Length; j++) { // , momentumSpeedWeights[i, j] = _config.Momentum*momentumSpeedWeights[i, j] + nablaWeights[i, j]/batch.Count; // visibleLayer.Neurons[i].Weights[j] += learningRate * momentumSpeedWeights[i, j]; hiddenLayer.Neurons[j].Weights[i] = visibleLayer.Neurons[i].Weights[j]; } } if (_config.UseBiases) { for (int i = 0; i < hiddenLayer.Neurons.Length; i++) { momentumSpeedHiddenBiases[i] = _config.Momentum*momentumSpeedHiddenBiases[i] + nablaHiddenBiases[i]/batch.Count; hiddenLayer.Neurons[i].Bias += learningRate * momentumSpeedHiddenBiases[i]; } for (int i = 0; i < visibleLayer.Neurons.Length; i++) { momentumSpeedVisibleBiases[i] = _config.Momentum*momentumSpeedVisibleBiases[i] + nablaVisibleBiases[i]/batch.Count; visibleLayer.Neurons[i].Bias += learningRate * momentumSpeedVisibleBiases[i]; } }
- . , , / , , , . : . , , , . .
#region Logging and error calculation string msg = "Epoche #" + currentEpoche; #region calculate error if (currentEpoche % _config.CostFunctionRecalculationStep == 0) { #region calculating squared error with reconstruction IMetrics<double> sed = MetricsCreator.SquareEuclideanDistance(); double d = 0; foreach (DataItem<double> dataItem in data) { d += sed.Calculate(dataItem.Input, network.ComputeOutput(dataItem.Input)); } msg += "; SqDist is " + d; lastErrorChange = Math.Abs(lastError - d); lastError = d; #endregion } #endregion msg += "; Time: " + (DateTime.Now - dtStart).Duration().ToString(); Logger.Instance.Log(msg);
.
RBM
. , , , ( 260 29 29 ): .
:
LearningAlgorithmConfig:
LearningRate = 0.01
BatchSize = 10
RegularizationFactor = 0
MaxEpoches = 1000
MinError = 0
MinErrorChange = 0
CostFunctionRecalculationStep = 1
ErrorFunction =
Momentum = 0.9
NeuronLocalGainLimit: not setted
GibbsSamplingChainLength = 30
UseBiases = True
, 1000 . .. 10, 26 , 26000 . .
, (26 ) 13128, 76.
( , ):
:
, ( RBM).
, - , . , . 841 (29*29) . , 841 29 29 , , . , , , . :
MNIST : http://deeplearning.net/tutorial/_images/filters_at_epoch_14.png . , =)
RBM , , .
https://class.coursera.org/neuralnets-2012-001/ http://www.cs.toronto.edu/~hinton/absps/guideTR.pdf http://deeplearning.net/tutorial/rbm.html#contrastive-divergence-cd-k http://www.iro.umontreal.ca/~lisa/twiki/bin/view.cgi/Public/DBNEquations http://www.cs.toronto.edu/~kriz/learning-features-2009-TR.pdf
PS ambikontur !
UPD :
public void Train(IMultilayerNeuralNetwork network, IList<DataItem> data)
, . , .
LearningAlgorithmConfig config = new LearningAlgorithmConfig() { BatchSize = 10, // MaxEpoches = 1000, // GibbsSamplingChainLength = 30, // k CD-k LearningRate = 0.01, // CostFunctionRecalculationStep = 1, // Momentum = 0.9, // MinError = 0, // MinErrorChange = 0, // UseBiases = true // };
.
ILayer visibleLayer = network.Layers[0]; // RBM , ILayer hiddenLayer = network.Layers[1]; // if (!_config.UseBiases) // { for (int i = 0; i < visibleLayer.Neurons.Length; i++) { visibleLayer.Neurons[i].Bias = 0d; } for (int i = 0; i < hiddenLayer.Neurons.Length; i++) { hiddenLayer.Neurons[i].Bias = 0d; } } //init momentum // double[,] momentumSpeedWeights = new double[visibleLayer.Neurons.Length, hiddenLayer.Neurons.Length]; double[] momentumSpeedVisibleBiases = new double[visibleLayer.Neurons.Length]; double[] momentumSpeedHiddenBiases = new double[hiddenLayer.Neurons.Length]; //init stop factors bool stopFlag = false; double lastError = Double.MaxValue; // , double lastErrorChange = double.MaxValue; double learningRate = _config.LearningRate; int currentEpoche = 0; BatchEnumerator<DataItem<double>> batchEnumerator = new BatchEnumerator<DataItem<double>>(data, _config.BatchSize, true);
BatchEnumerator' , .
:
do { DateTime dtStart = DateTime.Now; //start batch processing foreach (IList<DataItem<double>> batch in batchEnumerator) { //batch gradient // , / double[,] nablaWeights = new double[visibleLayer.Neurons.Length, hiddenLayer.Neurons.Length]; double[] nablaHiddenBiases = new double[hiddenLayer.Neurons.Length]; double[] nablaVisibleBiases = new double[visibleLayer.Neurons.Length]; #region iterate through batch //... #endregion #region compute mean of wights nabla, and update them //... #endregion } #region Logging and error calculation //... #endregion // currentEpoche++; if (currentEpoche >= _config.MaxEpoches) { stopFlag = true; Logger.Instance.Log("Stop: currentEpoche:" + currentEpoche + " >= _config.MaxEpoches:" + _config.MaxEpoches); } else if (_config.MinError >= lastError) { stopFlag = true; Logger.Instance.Log("Stop: _config.MinError:" + _config.MinError + " >= lastError:" + lastError); } else if (_config.MinErrorChange >= lastErrorChange) { stopFlag = true; Logger.Instance.Log("Stop: _config.MinErrorChange:" + _config.MinErrorChange + " >= lastErrorChange:" + lastErrorChange); } } while (!stopFlag);
, Gibbs sampling, .
#region iterate through batch // foreach (DataItem<double> dataItem in batch) { //init visible layer states // / for (int i = 0; i < dataItem.Input.Length; i++) { visibleLayer.Neurons[i].LastState = dataItem.Input[i]; } #region Gibbs sampling for (int k = 0; k <= _config.GibbsSamplingChainLength; k++) { //calculate hidden states probabilities // , hiddenLayer.Compute(); #region accumulate negative phase // - , if (k == _config.GibbsSamplingChainLength) { for (int i = 0; i < visibleLayer.Neurons.Length; i++) { for (int j = 0; j < hiddenLayer.Neurons.Length; j++) { // nablaWeights[i, j] -= visibleLayer.Neurons[i].LastState * hiddenLayer.Neurons[j].LastState; } } if (_config.UseBiases) { for (int i = 0; i < hiddenLayer.Neurons.Length; i++) { nablaHiddenBiases[i] -= hiddenLayer.Neurons[i].LastState; } for (int i = 0; i < visibleLayer.Neurons.Length; i++) { nablaVisibleBiases[i] -= visibleLayer.Neurons[i].LastState; } } break; } #endregion //sample hidden states // , , , Gibbs sampling for (int i = 0; i < hiddenLayer.Neurons.Length; i++) { hiddenLayer.Neurons[i].LastState = _r.NextDouble() <= hiddenLayer.Neurons[i].LastState ? 1d : 0d; } #region accumulate positive phase // , if (k == 0) { for (int i = 0; i < visibleLayer.Neurons.Length; i++) { for (int j = 0; j < hiddenLayer.Neurons.Length; j++) { nablaWeights[i, j] += visibleLayer.Neurons[i].LastState* hiddenLayer.Neurons[j].LastState; } } if (_config.UseBiases) { for (int i = 0; i < hiddenLayer.Neurons.Length; i++) { nablaHiddenBiases[i] += hiddenLayer.Neurons[i].LastState; } for (int i = 0; i < visibleLayer.Neurons.Length; i++) { nablaVisibleBiases[i] += visibleLayer.Neurons[i].LastState; } } } #endregion //calculate visible probs // visibleLayer.Compute(); // , , , . ; //todo: may be not do sampling, like in 3.2 of http://www.cs.toronto.edu/~hinton/absps/guideTR.pdf //sample visible //for (int i = 0; i < visibleLayer.Neurons.Length; i++) //{ // visibleLayer.Neurons[i].LastState = _r.NextDouble() <= visibleLayer.Neurons[i].LastState ? 1d : 0d; //} } #endregion }
, . : ( ) . .
#region compute mean of wights nabla, and update them for (int i = 0; i < visibleLayer.Neurons.Length; i++) { for (int j = 0; j < hiddenLayer.Neurons.Length; j++) { // , momentumSpeedWeights[i, j] = _config.Momentum*momentumSpeedWeights[i, j] + nablaWeights[i, j]/batch.Count; // visibleLayer.Neurons[i].Weights[j] += learningRate * momentumSpeedWeights[i, j]; hiddenLayer.Neurons[j].Weights[i] = visibleLayer.Neurons[i].Weights[j]; } } if (_config.UseBiases) { for (int i = 0; i < hiddenLayer.Neurons.Length; i++) { momentumSpeedHiddenBiases[i] = _config.Momentum*momentumSpeedHiddenBiases[i] + nablaHiddenBiases[i]/batch.Count; hiddenLayer.Neurons[i].Bias += learningRate * momentumSpeedHiddenBiases[i]; } for (int i = 0; i < visibleLayer.Neurons.Length; i++) { momentumSpeedVisibleBiases[i] = _config.Momentum*momentumSpeedVisibleBiases[i] + nablaVisibleBiases[i]/batch.Count; visibleLayer.Neurons[i].Bias += learningRate * momentumSpeedVisibleBiases[i]; } }
- . , , / , , , . : . , , , . .
#region Logging and error calculation string msg = "Epoche #" + currentEpoche; #region calculate error if (currentEpoche % _config.CostFunctionRecalculationStep == 0) { #region calculating squared error with reconstruction IMetrics<double> sed = MetricsCreator.SquareEuclideanDistance(); double d = 0; foreach (DataItem<double> dataItem in data) { d += sed.Calculate(dataItem.Input, network.ComputeOutput(dataItem.Input)); } msg += "; SqDist is " + d; lastErrorChange = Math.Abs(lastError - d); lastError = d; #endregion } #endregion msg += "; Time: " + (DateTime.Now - dtStart).Duration().ToString(); Logger.Instance.Log(msg);
.
RBM
. , , , ( 260 29 29 ): .
:
LearningAlgorithmConfig:
LearningRate = 0.01
BatchSize = 10
RegularizationFactor = 0
MaxEpoches = 1000
MinError = 0
MinErrorChange = 0
CostFunctionRecalculationStep = 1
ErrorFunction =
Momentum = 0.9
NeuronLocalGainLimit: not setted
GibbsSamplingChainLength = 30
UseBiases = True
, 1000 . .. 10, 26 , 26000 . .
, (26 ) 13128, 76.
( , ):
:
, ( RBM).
, - , . , . 841 (29*29) . , 841 29 29 , , . , , , . :
MNIST : http://deeplearning.net/tutorial/_images/filters_at_epoch_14.png . , =)
RBM , , .
https://class.coursera.org/neuralnets-2012-001/ http://www.cs.toronto.edu/~hinton/absps/guideTR.pdf http://deeplearning.net/tutorial/rbm.html#contrastive-divergence-cd-k http://www.iro.umontreal.ca/~lisa/twiki/bin/view.cgi/Public/DBNEquations http://www.cs.toronto.edu/~kriz/learning-features-2009-TR.pdf
PS ambikontur !
UPD :
public void Train(IMultilayerNeuralNetwork network, IList<DataItem> data)
, . , .
LearningAlgorithmConfig config = new LearningAlgorithmConfig() { BatchSize = 10, // MaxEpoches = 1000, // GibbsSamplingChainLength = 30, // k CD-k LearningRate = 0.01, // CostFunctionRecalculationStep = 1, // Momentum = 0.9, // MinError = 0, // MinErrorChange = 0, // UseBiases = true // };
.
ILayer visibleLayer = network.Layers[0]; // RBM , ILayer hiddenLayer = network.Layers[1]; // if (!_config.UseBiases) // { for (int i = 0; i < visibleLayer.Neurons.Length; i++) { visibleLayer.Neurons[i].Bias = 0d; } for (int i = 0; i < hiddenLayer.Neurons.Length; i++) { hiddenLayer.Neurons[i].Bias = 0d; } } //init momentum // double[,] momentumSpeedWeights = new double[visibleLayer.Neurons.Length, hiddenLayer.Neurons.Length]; double[] momentumSpeedVisibleBiases = new double[visibleLayer.Neurons.Length]; double[] momentumSpeedHiddenBiases = new double[hiddenLayer.Neurons.Length]; //init stop factors bool stopFlag = false; double lastError = Double.MaxValue; // , double lastErrorChange = double.MaxValue; double learningRate = _config.LearningRate; int currentEpoche = 0; BatchEnumerator<DataItem<double>> batchEnumerator = new BatchEnumerator<DataItem<double>>(data, _config.BatchSize, true);
BatchEnumerator' , .
:
do { DateTime dtStart = DateTime.Now; //start batch processing foreach (IList<DataItem<double>> batch in batchEnumerator) { //batch gradient // , / double[,] nablaWeights = new double[visibleLayer.Neurons.Length, hiddenLayer.Neurons.Length]; double[] nablaHiddenBiases = new double[hiddenLayer.Neurons.Length]; double[] nablaVisibleBiases = new double[visibleLayer.Neurons.Length]; #region iterate through batch //... #endregion #region compute mean of wights nabla, and update them //... #endregion } #region Logging and error calculation //... #endregion // currentEpoche++; if (currentEpoche >= _config.MaxEpoches) { stopFlag = true; Logger.Instance.Log("Stop: currentEpoche:" + currentEpoche + " >= _config.MaxEpoches:" + _config.MaxEpoches); } else if (_config.MinError >= lastError) { stopFlag = true; Logger.Instance.Log("Stop: _config.MinError:" + _config.MinError + " >= lastError:" + lastError); } else if (_config.MinErrorChange >= lastErrorChange) { stopFlag = true; Logger.Instance.Log("Stop: _config.MinErrorChange:" + _config.MinErrorChange + " >= lastErrorChange:" + lastErrorChange); } } while (!stopFlag);
, Gibbs sampling, .
#region iterate through batch // foreach (DataItem<double> dataItem in batch) { //init visible layer states // / for (int i = 0; i < dataItem.Input.Length; i++) { visibleLayer.Neurons[i].LastState = dataItem.Input[i]; } #region Gibbs sampling for (int k = 0; k <= _config.GibbsSamplingChainLength; k++) { //calculate hidden states probabilities // , hiddenLayer.Compute(); #region accumulate negative phase // - , if (k == _config.GibbsSamplingChainLength) { for (int i = 0; i < visibleLayer.Neurons.Length; i++) { for (int j = 0; j < hiddenLayer.Neurons.Length; j++) { // nablaWeights[i, j] -= visibleLayer.Neurons[i].LastState * hiddenLayer.Neurons[j].LastState; } } if (_config.UseBiases) { for (int i = 0; i < hiddenLayer.Neurons.Length; i++) { nablaHiddenBiases[i] -= hiddenLayer.Neurons[i].LastState; } for (int i = 0; i < visibleLayer.Neurons.Length; i++) { nablaVisibleBiases[i] -= visibleLayer.Neurons[i].LastState; } } break; } #endregion //sample hidden states // , , , Gibbs sampling for (int i = 0; i < hiddenLayer.Neurons.Length; i++) { hiddenLayer.Neurons[i].LastState = _r.NextDouble() <= hiddenLayer.Neurons[i].LastState ? 1d : 0d; } #region accumulate positive phase // , if (k == 0) { for (int i = 0; i < visibleLayer.Neurons.Length; i++) { for (int j = 0; j < hiddenLayer.Neurons.Length; j++) { nablaWeights[i, j] += visibleLayer.Neurons[i].LastState* hiddenLayer.Neurons[j].LastState; } } if (_config.UseBiases) { for (int i = 0; i < hiddenLayer.Neurons.Length; i++) { nablaHiddenBiases[i] += hiddenLayer.Neurons[i].LastState; } for (int i = 0; i < visibleLayer.Neurons.Length; i++) { nablaVisibleBiases[i] += visibleLayer.Neurons[i].LastState; } } } #endregion //calculate visible probs // visibleLayer.Compute(); // , , , . ; //todo: may be not do sampling, like in 3.2 of http://www.cs.toronto.edu/~hinton/absps/guideTR.pdf //sample visible //for (int i = 0; i < visibleLayer.Neurons.Length; i++) //{ // visibleLayer.Neurons[i].LastState = _r.NextDouble() <= visibleLayer.Neurons[i].LastState ? 1d : 0d; //} } #endregion }
, . : ( ) . .
#region compute mean of wights nabla, and update them for (int i = 0; i < visibleLayer.Neurons.Length; i++) { for (int j = 0; j < hiddenLayer.Neurons.Length; j++) { // , momentumSpeedWeights[i, j] = _config.Momentum*momentumSpeedWeights[i, j] + nablaWeights[i, j]/batch.Count; // visibleLayer.Neurons[i].Weights[j] += learningRate * momentumSpeedWeights[i, j]; hiddenLayer.Neurons[j].Weights[i] = visibleLayer.Neurons[i].Weights[j]; } } if (_config.UseBiases) { for (int i = 0; i < hiddenLayer.Neurons.Length; i++) { momentumSpeedHiddenBiases[i] = _config.Momentum*momentumSpeedHiddenBiases[i] + nablaHiddenBiases[i]/batch.Count; hiddenLayer.Neurons[i].Bias += learningRate * momentumSpeedHiddenBiases[i]; } for (int i = 0; i < visibleLayer.Neurons.Length; i++) { momentumSpeedVisibleBiases[i] = _config.Momentum*momentumSpeedVisibleBiases[i] + nablaVisibleBiases[i]/batch.Count; visibleLayer.Neurons[i].Bias += learningRate * momentumSpeedVisibleBiases[i]; } }
- . , , / , , , . : . , , , . .
#region Logging and error calculation string msg = "Epoche #" + currentEpoche; #region calculate error if (currentEpoche % _config.CostFunctionRecalculationStep == 0) { #region calculating squared error with reconstruction IMetrics<double> sed = MetricsCreator.SquareEuclideanDistance(); double d = 0; foreach (DataItem<double> dataItem in data) { d += sed.Calculate(dataItem.Input, network.ComputeOutput(dataItem.Input)); } msg += "; SqDist is " + d; lastErrorChange = Math.Abs(lastError - d); lastError = d; #endregion } #endregion msg += "; Time: " + (DateTime.Now - dtStart).Duration().ToString(); Logger.Instance.Log(msg);
.
RBM
. , , , ( 260 29 29 ): .
:
LearningAlgorithmConfig:
LearningRate = 0.01
BatchSize = 10
RegularizationFactor = 0
MaxEpoches = 1000
MinError = 0
MinErrorChange = 0
CostFunctionRecalculationStep = 1
ErrorFunction =
Momentum = 0.9
NeuronLocalGainLimit: not setted
GibbsSamplingChainLength = 30
UseBiases = True
, 1000 . .. 10, 26 , 26000 . .
, (26 ) 13128, 76.
( , ):
:
, ( RBM).
, - , . , . 841 (29*29) . , 841 29 29 , , . , , , . :
MNIST : http://deeplearning.net/tutorial/_images/filters_at_epoch_14.png . , =)
RBM , , .
https://class.coursera.org/neuralnets-2012-001/ http://www.cs.toronto.edu/~hinton/absps/guideTR.pdf http://deeplearning.net/tutorial/rbm.html#contrastive-divergence-cd-k http://www.iro.umontreal.ca/~lisa/twiki/bin/view.cgi/Public/DBNEquations http://www.cs.toronto.edu/~kriz/learning-features-2009-TR.pdf
PS ambikontur !
UPD :
public void Train(IMultilayerNeuralNetwork network, IList<DataItem> data)
, . , .
LearningAlgorithmConfig config = new LearningAlgorithmConfig() { BatchSize = 10, // MaxEpoches = 1000, // GibbsSamplingChainLength = 30, // k CD-k LearningRate = 0.01, // CostFunctionRecalculationStep = 1, // Momentum = 0.9, // MinError = 0, // MinErrorChange = 0, // UseBiases = true // };
.
ILayer visibleLayer = network.Layers[0]; // RBM , ILayer hiddenLayer = network.Layers[1]; // if (!_config.UseBiases) // { for (int i = 0; i < visibleLayer.Neurons.Length; i++) { visibleLayer.Neurons[i].Bias = 0d; } for (int i = 0; i < hiddenLayer.Neurons.Length; i++) { hiddenLayer.Neurons[i].Bias = 0d; } } //init momentum // double[,] momentumSpeedWeights = new double[visibleLayer.Neurons.Length, hiddenLayer.Neurons.Length]; double[] momentumSpeedVisibleBiases = new double[visibleLayer.Neurons.Length]; double[] momentumSpeedHiddenBiases = new double[hiddenLayer.Neurons.Length]; //init stop factors bool stopFlag = false; double lastError = Double.MaxValue; // , double lastErrorChange = double.MaxValue; double learningRate = _config.LearningRate; int currentEpoche = 0; BatchEnumerator<DataItem<double>> batchEnumerator = new BatchEnumerator<DataItem<double>>(data, _config.BatchSize, true);
BatchEnumerator' , .
:
do { DateTime dtStart = DateTime.Now; //start batch processing foreach (IList<DataItem<double>> batch in batchEnumerator) { //batch gradient // , / double[,] nablaWeights = new double[visibleLayer.Neurons.Length, hiddenLayer.Neurons.Length]; double[] nablaHiddenBiases = new double[hiddenLayer.Neurons.Length]; double[] nablaVisibleBiases = new double[visibleLayer.Neurons.Length]; #region iterate through batch //... #endregion #region compute mean of wights nabla, and update them //... #endregion } #region Logging and error calculation //... #endregion // currentEpoche++; if (currentEpoche >= _config.MaxEpoches) { stopFlag = true; Logger.Instance.Log("Stop: currentEpoche:" + currentEpoche + " >= _config.MaxEpoches:" + _config.MaxEpoches); } else if (_config.MinError >= lastError) { stopFlag = true; Logger.Instance.Log("Stop: _config.MinError:" + _config.MinError + " >= lastError:" + lastError); } else if (_config.MinErrorChange >= lastErrorChange) { stopFlag = true; Logger.Instance.Log("Stop: _config.MinErrorChange:" + _config.MinErrorChange + " >= lastErrorChange:" + lastErrorChange); } } while (!stopFlag);
, Gibbs sampling, .
#region iterate through batch // foreach (DataItem<double> dataItem in batch) { //init visible layer states // / for (int i = 0; i < dataItem.Input.Length; i++) { visibleLayer.Neurons[i].LastState = dataItem.Input[i]; } #region Gibbs sampling for (int k = 0; k <= _config.GibbsSamplingChainLength; k++) { //calculate hidden states probabilities // , hiddenLayer.Compute(); #region accumulate negative phase // - , if (k == _config.GibbsSamplingChainLength) { for (int i = 0; i < visibleLayer.Neurons.Length; i++) { for (int j = 0; j < hiddenLayer.Neurons.Length; j++) { // nablaWeights[i, j] -= visibleLayer.Neurons[i].LastState * hiddenLayer.Neurons[j].LastState; } } if (_config.UseBiases) { for (int i = 0; i < hiddenLayer.Neurons.Length; i++) { nablaHiddenBiases[i] -= hiddenLayer.Neurons[i].LastState; } for (int i = 0; i < visibleLayer.Neurons.Length; i++) { nablaVisibleBiases[i] -= visibleLayer.Neurons[i].LastState; } } break; } #endregion //sample hidden states // , , , Gibbs sampling for (int i = 0; i < hiddenLayer.Neurons.Length; i++) { hiddenLayer.Neurons[i].LastState = _r.NextDouble() <= hiddenLayer.Neurons[i].LastState ? 1d : 0d; } #region accumulate positive phase // , if (k == 0) { for (int i = 0; i < visibleLayer.Neurons.Length; i++) { for (int j = 0; j < hiddenLayer.Neurons.Length; j++) { nablaWeights[i, j] += visibleLayer.Neurons[i].LastState* hiddenLayer.Neurons[j].LastState; } } if (_config.UseBiases) { for (int i = 0; i < hiddenLayer.Neurons.Length; i++) { nablaHiddenBiases[i] += hiddenLayer.Neurons[i].LastState; } for (int i = 0; i < visibleLayer.Neurons.Length; i++) { nablaVisibleBiases[i] += visibleLayer.Neurons[i].LastState; } } } #endregion //calculate visible probs // visibleLayer.Compute(); // , , , . ; //todo: may be not do sampling, like in 3.2 of http://www.cs.toronto.edu/~hinton/absps/guideTR.pdf //sample visible //for (int i = 0; i < visibleLayer.Neurons.Length; i++) //{ // visibleLayer.Neurons[i].LastState = _r.NextDouble() <= visibleLayer.Neurons[i].LastState ? 1d : 0d; //} } #endregion }
, . : ( ) . .
#region compute mean of wights nabla, and update them for (int i = 0; i < visibleLayer.Neurons.Length; i++) { for (int j = 0; j < hiddenLayer.Neurons.Length; j++) { // , momentumSpeedWeights[i, j] = _config.Momentum*momentumSpeedWeights[i, j] + nablaWeights[i, j]/batch.Count; // visibleLayer.Neurons[i].Weights[j] += learningRate * momentumSpeedWeights[i, j]; hiddenLayer.Neurons[j].Weights[i] = visibleLayer.Neurons[i].Weights[j]; } } if (_config.UseBiases) { for (int i = 0; i < hiddenLayer.Neurons.Length; i++) { momentumSpeedHiddenBiases[i] = _config.Momentum*momentumSpeedHiddenBiases[i] + nablaHiddenBiases[i]/batch.Count; hiddenLayer.Neurons[i].Bias += learningRate * momentumSpeedHiddenBiases[i]; } for (int i = 0; i < visibleLayer.Neurons.Length; i++) { momentumSpeedVisibleBiases[i] = _config.Momentum*momentumSpeedVisibleBiases[i] + nablaVisibleBiases[i]/batch.Count; visibleLayer.Neurons[i].Bias += learningRate * momentumSpeedVisibleBiases[i]; } }
- . , , / , , , . : . , , , . .
#region Logging and error calculation string msg = "Epoche #" + currentEpoche; #region calculate error if (currentEpoche % _config.CostFunctionRecalculationStep == 0) { #region calculating squared error with reconstruction IMetrics<double> sed = MetricsCreator.SquareEuclideanDistance(); double d = 0; foreach (DataItem<double> dataItem in data) { d += sed.Calculate(dataItem.Input, network.ComputeOutput(dataItem.Input)); } msg += "; SqDist is " + d; lastErrorChange = Math.Abs(lastError - d); lastError = d; #endregion } #endregion msg += "; Time: " + (DateTime.Now - dtStart).Duration().ToString(); Logger.Instance.Log(msg);
.
RBM
. , , , ( 260 29 29 ): .
:
LearningAlgorithmConfig:
LearningRate = 0.01
BatchSize = 10
RegularizationFactor = 0
MaxEpoches = 1000
MinError = 0
MinErrorChange = 0
CostFunctionRecalculationStep = 1
ErrorFunction =
Momentum = 0.9
NeuronLocalGainLimit: not setted
GibbsSamplingChainLength = 30
UseBiases = True
, 1000 . .. 10, 26 , 26000 . .
, (26 ) 13128, 76.
( , ):
:
, ( RBM).
, - , . , . 841 (29*29) . , 841 29 29 , , . , , , . :
MNIST : http://deeplearning.net/tutorial/_images/filters_at_epoch_14.png . , =)
RBM , , .
https://class.coursera.org/neuralnets-2012-001/ http://www.cs.toronto.edu/~hinton/absps/guideTR.pdf http://deeplearning.net/tutorial/rbm.html#contrastive-divergence-cd-k http://www.iro.umontreal.ca/~lisa/twiki/bin/view.cgi/Public/DBNEquations http://www.cs.toronto.edu/~kriz/learning-features-2009-TR.pdf
PS ambikontur !
UPD :
public void Train(IMultilayerNeuralNetwork network, IList<DataItem> data)
, . , .
LearningAlgorithmConfig config = new LearningAlgorithmConfig() { BatchSize = 10, // MaxEpoches = 1000, // GibbsSamplingChainLength = 30, // k CD-k LearningRate = 0.01, // CostFunctionRecalculationStep = 1, // Momentum = 0.9, // MinError = 0, // MinErrorChange = 0, // UseBiases = true // };
.
ILayer visibleLayer = network.Layers[0]; // RBM , ILayer hiddenLayer = network.Layers[1]; // if (!_config.UseBiases) // { for (int i = 0; i < visibleLayer.Neurons.Length; i++) { visibleLayer.Neurons[i].Bias = 0d; } for (int i = 0; i < hiddenLayer.Neurons.Length; i++) { hiddenLayer.Neurons[i].Bias = 0d; } } //init momentum // double[,] momentumSpeedWeights = new double[visibleLayer.Neurons.Length, hiddenLayer.Neurons.Length]; double[] momentumSpeedVisibleBiases = new double[visibleLayer.Neurons.Length]; double[] momentumSpeedHiddenBiases = new double[hiddenLayer.Neurons.Length]; //init stop factors bool stopFlag = false; double lastError = Double.MaxValue; // , double lastErrorChange = double.MaxValue; double learningRate = _config.LearningRate; int currentEpoche = 0; BatchEnumerator<DataItem<double>> batchEnumerator = new BatchEnumerator<DataItem<double>>(data, _config.BatchSize, true);
BatchEnumerator' , .
:
do { DateTime dtStart = DateTime.Now; //start batch processing foreach (IList<DataItem<double>> batch in batchEnumerator) { //batch gradient // , / double[,] nablaWeights = new double[visibleLayer.Neurons.Length, hiddenLayer.Neurons.Length]; double[] nablaHiddenBiases = new double[hiddenLayer.Neurons.Length]; double[] nablaVisibleBiases = new double[visibleLayer.Neurons.Length]; #region iterate through batch //... #endregion #region compute mean of wights nabla, and update them //... #endregion } #region Logging and error calculation //... #endregion // currentEpoche++; if (currentEpoche >= _config.MaxEpoches) { stopFlag = true; Logger.Instance.Log("Stop: currentEpoche:" + currentEpoche + " >= _config.MaxEpoches:" + _config.MaxEpoches); } else if (_config.MinError >= lastError) { stopFlag = true; Logger.Instance.Log("Stop: _config.MinError:" + _config.MinError + " >= lastError:" + lastError); } else if (_config.MinErrorChange >= lastErrorChange) { stopFlag = true; Logger.Instance.Log("Stop: _config.MinErrorChange:" + _config.MinErrorChange + " >= lastErrorChange:" + lastErrorChange); } } while (!stopFlag);
, Gibbs sampling, .
#region iterate through batch // foreach (DataItem<double> dataItem in batch) { //init visible layer states // / for (int i = 0; i < dataItem.Input.Length; i++) { visibleLayer.Neurons[i].LastState = dataItem.Input[i]; } #region Gibbs sampling for (int k = 0; k <= _config.GibbsSamplingChainLength; k++) { //calculate hidden states probabilities // , hiddenLayer.Compute(); #region accumulate negative phase // - , if (k == _config.GibbsSamplingChainLength) { for (int i = 0; i < visibleLayer.Neurons.Length; i++) { for (int j = 0; j < hiddenLayer.Neurons.Length; j++) { // nablaWeights[i, j] -= visibleLayer.Neurons[i].LastState * hiddenLayer.Neurons[j].LastState; } } if (_config.UseBiases) { for (int i = 0; i < hiddenLayer.Neurons.Length; i++) { nablaHiddenBiases[i] -= hiddenLayer.Neurons[i].LastState; } for (int i = 0; i < visibleLayer.Neurons.Length; i++) { nablaVisibleBiases[i] -= visibleLayer.Neurons[i].LastState; } } break; } #endregion //sample hidden states // , , , Gibbs sampling for (int i = 0; i < hiddenLayer.Neurons.Length; i++) { hiddenLayer.Neurons[i].LastState = _r.NextDouble() <= hiddenLayer.Neurons[i].LastState ? 1d : 0d; } #region accumulate positive phase // , if (k == 0) { for (int i = 0; i < visibleLayer.Neurons.Length; i++) { for (int j = 0; j < hiddenLayer.Neurons.Length; j++) { nablaWeights[i, j] += visibleLayer.Neurons[i].LastState* hiddenLayer.Neurons[j].LastState; } } if (_config.UseBiases) { for (int i = 0; i < hiddenLayer.Neurons.Length; i++) { nablaHiddenBiases[i] += hiddenLayer.Neurons[i].LastState; } for (int i = 0; i < visibleLayer.Neurons.Length; i++) { nablaVisibleBiases[i] += visibleLayer.Neurons[i].LastState; } } } #endregion //calculate visible probs // visibleLayer.Compute(); // , , , . ; //todo: may be not do sampling, like in 3.2 of http://www.cs.toronto.edu/~hinton/absps/guideTR.pdf //sample visible //for (int i = 0; i < visibleLayer.Neurons.Length; i++) //{ // visibleLayer.Neurons[i].LastState = _r.NextDouble() <= visibleLayer.Neurons[i].LastState ? 1d : 0d; //} } #endregion }
, . : ( ) . .
#region compute mean of wights nabla, and update them for (int i = 0; i < visibleLayer.Neurons.Length; i++) { for (int j = 0; j < hiddenLayer.Neurons.Length; j++) { // , momentumSpeedWeights[i, j] = _config.Momentum*momentumSpeedWeights[i, j] + nablaWeights[i, j]/batch.Count; // visibleLayer.Neurons[i].Weights[j] += learningRate * momentumSpeedWeights[i, j]; hiddenLayer.Neurons[j].Weights[i] = visibleLayer.Neurons[i].Weights[j]; } } if (_config.UseBiases) { for (int i = 0; i < hiddenLayer.Neurons.Length; i++) { momentumSpeedHiddenBiases[i] = _config.Momentum*momentumSpeedHiddenBiases[i] + nablaHiddenBiases[i]/batch.Count; hiddenLayer.Neurons[i].Bias += learningRate * momentumSpeedHiddenBiases[i]; } for (int i = 0; i < visibleLayer.Neurons.Length; i++) { momentumSpeedVisibleBiases[i] = _config.Momentum*momentumSpeedVisibleBiases[i] + nablaVisibleBiases[i]/batch.Count; visibleLayer.Neurons[i].Bias += learningRate * momentumSpeedVisibleBiases[i]; } }
- . , , / , , , . : . , , , . .
#region Logging and error calculation string msg = "Epoche #" + currentEpoche; #region calculate error if (currentEpoche % _config.CostFunctionRecalculationStep == 0) { #region calculating squared error with reconstruction IMetrics<double> sed = MetricsCreator.SquareEuclideanDistance(); double d = 0; foreach (DataItem<double> dataItem in data) { d += sed.Calculate(dataItem.Input, network.ComputeOutput(dataItem.Input)); } msg += "; SqDist is " + d; lastErrorChange = Math.Abs(lastError - d); lastError = d; #endregion } #endregion msg += "; Time: " + (DateTime.Now - dtStart).Duration().ToString(); Logger.Instance.Log(msg);
.
RBM
. , , , ( 260 29 29 ): .
:
LearningAlgorithmConfig:
LearningRate = 0.01
BatchSize = 10
RegularizationFactor = 0
MaxEpoches = 1000
MinError = 0
MinErrorChange = 0
CostFunctionRecalculationStep = 1
ErrorFunction =
Momentum = 0.9
NeuronLocalGainLimit: not setted
GibbsSamplingChainLength = 30
UseBiases = True
, 1000 . .. 10, 26 , 26000 . .
, (26 ) 13128, 76.
( , ):
:
, ( RBM).
, - , . , . 841 (29*29) . , 841 29 29 , , . , , , . :
MNIST : http://deeplearning.net/tutorial/_images/filters_at_epoch_14.png . , =)
RBM , , .
https://class.coursera.org/neuralnets-2012-001/ http://www.cs.toronto.edu/~hinton/absps/guideTR.pdf http://deeplearning.net/tutorial/rbm.html#contrastive-divergence-cd-k http://www.iro.umontreal.ca/~lisa/twiki/bin/view.cgi/Public/DBNEquations http://www.cs.toronto.edu/~kriz/learning-features-2009-TR.pdf
PS ambikontur !
UPD :
public void Train(IMultilayerNeuralNetwork network, IList<DataItem> data)
, . , .
LearningAlgorithmConfig config = new LearningAlgorithmConfig() { BatchSize = 10, // MaxEpoches = 1000, // GibbsSamplingChainLength = 30, // k CD-k LearningRate = 0.01, // CostFunctionRecalculationStep = 1, // Momentum = 0.9, // MinError = 0, // MinErrorChange = 0, // UseBiases = true // };
.
ILayer visibleLayer = network.Layers[0]; // RBM , ILayer hiddenLayer = network.Layers[1]; // if (!_config.UseBiases) // { for (int i = 0; i < visibleLayer.Neurons.Length; i++) { visibleLayer.Neurons[i].Bias = 0d; } for (int i = 0; i < hiddenLayer.Neurons.Length; i++) { hiddenLayer.Neurons[i].Bias = 0d; } } //init momentum // double[,] momentumSpeedWeights = new double[visibleLayer.Neurons.Length, hiddenLayer.Neurons.Length]; double[] momentumSpeedVisibleBiases = new double[visibleLayer.Neurons.Length]; double[] momentumSpeedHiddenBiases = new double[hiddenLayer.Neurons.Length]; //init stop factors bool stopFlag = false; double lastError = Double.MaxValue; // , double lastErrorChange = double.MaxValue; double learningRate = _config.LearningRate; int currentEpoche = 0; BatchEnumerator<DataItem<double>> batchEnumerator = new BatchEnumerator<DataItem<double>>(data, _config.BatchSize, true);
BatchEnumerator' , .
:
do { DateTime dtStart = DateTime.Now; //start batch processing foreach (IList<DataItem<double>> batch in batchEnumerator) { //batch gradient // , / double[,] nablaWeights = new double[visibleLayer.Neurons.Length, hiddenLayer.Neurons.Length]; double[] nablaHiddenBiases = new double[hiddenLayer.Neurons.Length]; double[] nablaVisibleBiases = new double[visibleLayer.Neurons.Length]; #region iterate through batch //... #endregion #region compute mean of wights nabla, and update them //... #endregion } #region Logging and error calculation //... #endregion // currentEpoche++; if (currentEpoche >= _config.MaxEpoches) { stopFlag = true; Logger.Instance.Log("Stop: currentEpoche:" + currentEpoche + " >= _config.MaxEpoches:" + _config.MaxEpoches); } else if (_config.MinError >= lastError) { stopFlag = true; Logger.Instance.Log("Stop: _config.MinError:" + _config.MinError + " >= lastError:" + lastError); } else if (_config.MinErrorChange >= lastErrorChange) { stopFlag = true; Logger.Instance.Log("Stop: _config.MinErrorChange:" + _config.MinErrorChange + " >= lastErrorChange:" + lastErrorChange); } } while (!stopFlag);
, Gibbs sampling, .
#region iterate through batch // foreach (DataItem<double> dataItem in batch) { //init visible layer states // / for (int i = 0; i < dataItem.Input.Length; i++) { visibleLayer.Neurons[i].LastState = dataItem.Input[i]; } #region Gibbs sampling for (int k = 0; k <= _config.GibbsSamplingChainLength; k++) { //calculate hidden states probabilities // , hiddenLayer.Compute(); #region accumulate negative phase // - , if (k == _config.GibbsSamplingChainLength) { for (int i = 0; i < visibleLayer.Neurons.Length; i++) { for (int j = 0; j < hiddenLayer.Neurons.Length; j++) { // nablaWeights[i, j] -= visibleLayer.Neurons[i].LastState * hiddenLayer.Neurons[j].LastState; } } if (_config.UseBiases) { for (int i = 0; i < hiddenLayer.Neurons.Length; i++) { nablaHiddenBiases[i] -= hiddenLayer.Neurons[i].LastState; } for (int i = 0; i < visibleLayer.Neurons.Length; i++) { nablaVisibleBiases[i] -= visibleLayer.Neurons[i].LastState; } } break; } #endregion //sample hidden states // , , , Gibbs sampling for (int i = 0; i < hiddenLayer.Neurons.Length; i++) { hiddenLayer.Neurons[i].LastState = _r.NextDouble() <= hiddenLayer.Neurons[i].LastState ? 1d : 0d; } #region accumulate positive phase // , if (k == 0) { for (int i = 0; i < visibleLayer.Neurons.Length; i++) { for (int j = 0; j < hiddenLayer.Neurons.Length; j++) { nablaWeights[i, j] += visibleLayer.Neurons[i].LastState* hiddenLayer.Neurons[j].LastState; } } if (_config.UseBiases) { for (int i = 0; i < hiddenLayer.Neurons.Length; i++) { nablaHiddenBiases[i] += hiddenLayer.Neurons[i].LastState; } for (int i = 0; i < visibleLayer.Neurons.Length; i++) { nablaVisibleBiases[i] += visibleLayer.Neurons[i].LastState; } } } #endregion //calculate visible probs // visibleLayer.Compute(); // , , , . ; //todo: may be not do sampling, like in 3.2 of http://www.cs.toronto.edu/~hinton/absps/guideTR.pdf //sample visible //for (int i = 0; i < visibleLayer.Neurons.Length; i++) //{ // visibleLayer.Neurons[i].LastState = _r.NextDouble() <= visibleLayer.Neurons[i].LastState ? 1d : 0d; //} } #endregion }
, . : ( ) . .
#region compute mean of wights nabla, and update them for (int i = 0; i < visibleLayer.Neurons.Length; i++) { for (int j = 0; j < hiddenLayer.Neurons.Length; j++) { // , momentumSpeedWeights[i, j] = _config.Momentum*momentumSpeedWeights[i, j] + nablaWeights[i, j]/batch.Count; // visibleLayer.Neurons[i].Weights[j] += learningRate * momentumSpeedWeights[i, j]; hiddenLayer.Neurons[j].Weights[i] = visibleLayer.Neurons[i].Weights[j]; } } if (_config.UseBiases) { for (int i = 0; i < hiddenLayer.Neurons.Length; i++) { momentumSpeedHiddenBiases[i] = _config.Momentum*momentumSpeedHiddenBiases[i] + nablaHiddenBiases[i]/batch.Count; hiddenLayer.Neurons[i].Bias += learningRate * momentumSpeedHiddenBiases[i]; } for (int i = 0; i < visibleLayer.Neurons.Length; i++) { momentumSpeedVisibleBiases[i] = _config.Momentum*momentumSpeedVisibleBiases[i] + nablaVisibleBiases[i]/batch.Count; visibleLayer.Neurons[i].Bias += learningRate * momentumSpeedVisibleBiases[i]; } }
- . , , / , , , . : . , , , . .
#region Logging and error calculation string msg = "Epoche #" + currentEpoche; #region calculate error if (currentEpoche % _config.CostFunctionRecalculationStep == 0) { #region calculating squared error with reconstruction IMetrics<double> sed = MetricsCreator.SquareEuclideanDistance(); double d = 0; foreach (DataItem<double> dataItem in data) { d += sed.Calculate(dataItem.Input, network.ComputeOutput(dataItem.Input)); } msg += "; SqDist is " + d; lastErrorChange = Math.Abs(lastError - d); lastError = d; #endregion } #endregion msg += "; Time: " + (DateTime.Now - dtStart).Duration().ToString(); Logger.Instance.Log(msg);
.
RBM
. , , , ( 260 29 29 ): .
:
LearningAlgorithmConfig:
LearningRate = 0.01
BatchSize = 10
RegularizationFactor = 0
MaxEpoches = 1000
MinError = 0
MinErrorChange = 0
CostFunctionRecalculationStep = 1
ErrorFunction =
Momentum = 0.9
NeuronLocalGainLimit: not setted
GibbsSamplingChainLength = 30
UseBiases = True
, 1000 . .. 10, 26 , 26000 . .
, (26 ) 13128, 76.
( , ):
:
, ( RBM).
, - , . , . 841 (29*29) . , 841 29 29 , , . , , , . :
MNIST : http://deeplearning.net/tutorial/_images/filters_at_epoch_14.png . , =)
RBM , , .
https://class.coursera.org/neuralnets-2012-001/ http://www.cs.toronto.edu/~hinton/absps/guideTR.pdf http://deeplearning.net/tutorial/rbm.html#contrastive-divergence-cd-k http://www.iro.umontreal.ca/~lisa/twiki/bin/view.cgi/Public/DBNEquations http://www.cs.toronto.edu/~kriz/learning-features-2009-TR.pdf
PS ambikontur !
UPD :
public void Train(IMultilayerNeuralNetwork network, IList<DataItem> data)
, . , .
LearningAlgorithmConfig config = new LearningAlgorithmConfig() { BatchSize = 10, // MaxEpoches = 1000, // GibbsSamplingChainLength = 30, // k CD-k LearningRate = 0.01, // CostFunctionRecalculationStep = 1, // Momentum = 0.9, // MinError = 0, // MinErrorChange = 0, // UseBiases = true // };
.
ILayer visibleLayer = network.Layers[0]; // RBM , ILayer hiddenLayer = network.Layers[1]; // if (!_config.UseBiases) // { for (int i = 0; i < visibleLayer.Neurons.Length; i++) { visibleLayer.Neurons[i].Bias = 0d; } for (int i = 0; i < hiddenLayer.Neurons.Length; i++) { hiddenLayer.Neurons[i].Bias = 0d; } } //init momentum // double[,] momentumSpeedWeights = new double[visibleLayer.Neurons.Length, hiddenLayer.Neurons.Length]; double[] momentumSpeedVisibleBiases = new double[visibleLayer.Neurons.Length]; double[] momentumSpeedHiddenBiases = new double[hiddenLayer.Neurons.Length]; //init stop factors bool stopFlag = false; double lastError = Double.MaxValue; // , double lastErrorChange = double.MaxValue; double learningRate = _config.LearningRate; int currentEpoche = 0; BatchEnumerator<DataItem<double>> batchEnumerator = new BatchEnumerator<DataItem<double>>(data, _config.BatchSize, true);
BatchEnumerator' , .
:
do { DateTime dtStart = DateTime.Now; //start batch processing foreach (IList<DataItem<double>> batch in batchEnumerator) { //batch gradient // , / double[,] nablaWeights = new double[visibleLayer.Neurons.Length, hiddenLayer.Neurons.Length]; double[] nablaHiddenBiases = new double[hiddenLayer.Neurons.Length]; double[] nablaVisibleBiases = new double[visibleLayer.Neurons.Length]; #region iterate through batch //... #endregion #region compute mean of wights nabla, and update them //... #endregion } #region Logging and error calculation //... #endregion // currentEpoche++; if (currentEpoche >= _config.MaxEpoches) { stopFlag = true; Logger.Instance.Log("Stop: currentEpoche:" + currentEpoche + " >= _config.MaxEpoches:" + _config.MaxEpoches); } else if (_config.MinError >= lastError) { stopFlag = true; Logger.Instance.Log("Stop: _config.MinError:" + _config.MinError + " >= lastError:" + lastError); } else if (_config.MinErrorChange >= lastErrorChange) { stopFlag = true; Logger.Instance.Log("Stop: _config.MinErrorChange:" + _config.MinErrorChange + " >= lastErrorChange:" + lastErrorChange); } } while (!stopFlag);
, Gibbs sampling, .
#region iterate through batch // foreach (DataItem<double> dataItem in batch) { //init visible layer states // / for (int i = 0; i < dataItem.Input.Length; i++) { visibleLayer.Neurons[i].LastState = dataItem.Input[i]; } #region Gibbs sampling for (int k = 0; k <= _config.GibbsSamplingChainLength; k++) { //calculate hidden states probabilities // , hiddenLayer.Compute(); #region accumulate negative phase // - , if (k == _config.GibbsSamplingChainLength) { for (int i = 0; i < visibleLayer.Neurons.Length; i++) { for (int j = 0; j < hiddenLayer.Neurons.Length; j++) { // nablaWeights[i, j] -= visibleLayer.Neurons[i].LastState * hiddenLayer.Neurons[j].LastState; } } if (_config.UseBiases) { for (int i = 0; i < hiddenLayer.Neurons.Length; i++) { nablaHiddenBiases[i] -= hiddenLayer.Neurons[i].LastState; } for (int i = 0; i < visibleLayer.Neurons.Length; i++) { nablaVisibleBiases[i] -= visibleLayer.Neurons[i].LastState; } } break; } #endregion //sample hidden states // , , , Gibbs sampling for (int i = 0; i < hiddenLayer.Neurons.Length; i++) { hiddenLayer.Neurons[i].LastState = _r.NextDouble() <= hiddenLayer.Neurons[i].LastState ? 1d : 0d; } #region accumulate positive phase // , if (k == 0) { for (int i = 0; i < visibleLayer.Neurons.Length; i++) { for (int j = 0; j < hiddenLayer.Neurons.Length; j++) { nablaWeights[i, j] += visibleLayer.Neurons[i].LastState* hiddenLayer.Neurons[j].LastState; } } if (_config.UseBiases) { for (int i = 0; i < hiddenLayer.Neurons.Length; i++) { nablaHiddenBiases[i] += hiddenLayer.Neurons[i].LastState; } for (int i = 0; i < visibleLayer.Neurons.Length; i++) { nablaVisibleBiases[i] += visibleLayer.Neurons[i].LastState; } } } #endregion //calculate visible probs // visibleLayer.Compute(); // , , , . ; //todo: may be not do sampling, like in 3.2 of http://www.cs.toronto.edu/~hinton/absps/guideTR.pdf //sample visible //for (int i = 0; i < visibleLayer.Neurons.Length; i++) //{ // visibleLayer.Neurons[i].LastState = _r.NextDouble() <= visibleLayer.Neurons[i].LastState ? 1d : 0d; //} } #endregion }
, . : ( ) . .
#region compute mean of wights nabla, and update them for (int i = 0; i < visibleLayer.Neurons.Length; i++) { for (int j = 0; j < hiddenLayer.Neurons.Length; j++) { // , momentumSpeedWeights[i, j] = _config.Momentum*momentumSpeedWeights[i, j] + nablaWeights[i, j]/batch.Count; // visibleLayer.Neurons[i].Weights[j] += learningRate * momentumSpeedWeights[i, j]; hiddenLayer.Neurons[j].Weights[i] = visibleLayer.Neurons[i].Weights[j]; } } if (_config.UseBiases) { for (int i = 0; i < hiddenLayer.Neurons.Length; i++) { momentumSpeedHiddenBiases[i] = _config.Momentum*momentumSpeedHiddenBiases[i] + nablaHiddenBiases[i]/batch.Count; hiddenLayer.Neurons[i].Bias += learningRate * momentumSpeedHiddenBiases[i]; } for (int i = 0; i < visibleLayer.Neurons.Length; i++) { momentumSpeedVisibleBiases[i] = _config.Momentum*momentumSpeedVisibleBiases[i] + nablaVisibleBiases[i]/batch.Count; visibleLayer.Neurons[i].Bias += learningRate * momentumSpeedVisibleBiases[i]; } }
- . , , / , , , . : . , , , . .
#region Logging and error calculation string msg = "Epoche #" + currentEpoche; #region calculate error if (currentEpoche % _config.CostFunctionRecalculationStep == 0) { #region calculating squared error with reconstruction IMetrics<double> sed = MetricsCreator.SquareEuclideanDistance(); double d = 0; foreach (DataItem<double> dataItem in data) { d += sed.Calculate(dataItem.Input, network.ComputeOutput(dataItem.Input)); } msg += "; SqDist is " + d; lastErrorChange = Math.Abs(lastError - d); lastError = d; #endregion } #endregion msg += "; Time: " + (DateTime.Now - dtStart).Duration().ToString(); Logger.Instance.Log(msg);
.
RBM
. , , , ( 260 29 29 ): .
:
LearningAlgorithmConfig:
LearningRate = 0.01
BatchSize = 10
RegularizationFactor = 0
MaxEpoches = 1000
MinError = 0
MinErrorChange = 0
CostFunctionRecalculationStep = 1
ErrorFunction =
Momentum = 0.9
NeuronLocalGainLimit: not setted
GibbsSamplingChainLength = 30
UseBiases = True
, 1000 . .. 10, 26 , 26000 . .
, (26 ) 13128, 76.
( , ):
:
, ( RBM).
, - , . , . 841 (29*29) . , 841 29 29 , , . , , , . :
MNIST : http://deeplearning.net/tutorial/_images/filters_at_epoch_14.png . , =)
RBM , , .
https://class.coursera.org/neuralnets-2012-001/ http://www.cs.toronto.edu/~hinton/absps/guideTR.pdf http://deeplearning.net/tutorial/rbm.html#contrastive-divergence-cd-k http://www.iro.umontreal.ca/~lisa/twiki/bin/view.cgi/Public/DBNEquations http://www.cs.toronto.edu/~kriz/learning-features-2009-TR.pdf
PS ambikontur !
UPD :
public void Train(IMultilayerNeuralNetwork network, IList<DataItem> data)
, . , .
LearningAlgorithmConfig config = new LearningAlgorithmConfig() { BatchSize = 10, // MaxEpoches = 1000, // GibbsSamplingChainLength = 30, // k CD-k LearningRate = 0.01, // CostFunctionRecalculationStep = 1, // Momentum = 0.9, // MinError = 0, // MinErrorChange = 0, // UseBiases = true // };
.
ILayer visibleLayer = network.Layers[0]; // RBM , ILayer hiddenLayer = network.Layers[1]; // if (!_config.UseBiases) // { for (int i = 0; i < visibleLayer.Neurons.Length; i++) { visibleLayer.Neurons[i].Bias = 0d; } for (int i = 0; i < hiddenLayer.Neurons.Length; i++) { hiddenLayer.Neurons[i].Bias = 0d; } } //init momentum // double[,] momentumSpeedWeights = new double[visibleLayer.Neurons.Length, hiddenLayer.Neurons.Length]; double[] momentumSpeedVisibleBiases = new double[visibleLayer.Neurons.Length]; double[] momentumSpeedHiddenBiases = new double[hiddenLayer.Neurons.Length]; //init stop factors bool stopFlag = false; double lastError = Double.MaxValue; // , double lastErrorChange = double.MaxValue; double learningRate = _config.LearningRate; int currentEpoche = 0; BatchEnumerator<DataItem<double>> batchEnumerator = new BatchEnumerator<DataItem<double>>(data, _config.BatchSize, true);
BatchEnumerator' , .
:
do { DateTime dtStart = DateTime.Now; //start batch processing foreach (IList<DataItem<double>> batch in batchEnumerator) { //batch gradient // , / double[,] nablaWeights = new double[visibleLayer.Neurons.Length, hiddenLayer.Neurons.Length]; double[] nablaHiddenBiases = new double[hiddenLayer.Neurons.Length]; double[] nablaVisibleBiases = new double[visibleLayer.Neurons.Length]; #region iterate through batch //... #endregion #region compute mean of wights nabla, and update them //... #endregion } #region Logging and error calculation //... #endregion // currentEpoche++; if (currentEpoche >= _config.MaxEpoches) { stopFlag = true; Logger.Instance.Log("Stop: currentEpoche:" + currentEpoche + " >= _config.MaxEpoches:" + _config.MaxEpoches); } else if (_config.MinError >= lastError) { stopFlag = true; Logger.Instance.Log("Stop: _config.MinError:" + _config.MinError + " >= lastError:" + lastError); } else if (_config.MinErrorChange >= lastErrorChange) { stopFlag = true; Logger.Instance.Log("Stop: _config.MinErrorChange:" + _config.MinErrorChange + " >= lastErrorChange:" + lastErrorChange); } } while (!stopFlag);
, Gibbs sampling, .
#region iterate through batch // foreach (DataItem<double> dataItem in batch) { //init visible layer states // / for (int i = 0; i < dataItem.Input.Length; i++) { visibleLayer.Neurons[i].LastState = dataItem.Input[i]; } #region Gibbs sampling for (int k = 0; k <= _config.GibbsSamplingChainLength; k++) { //calculate hidden states probabilities // , hiddenLayer.Compute(); #region accumulate negative phase // - , if (k == _config.GibbsSamplingChainLength) { for (int i = 0; i < visibleLayer.Neurons.Length; i++) { for (int j = 0; j < hiddenLayer.Neurons.Length; j++) { // nablaWeights[i, j] -= visibleLayer.Neurons[i].LastState * hiddenLayer.Neurons[j].LastState; } } if (_config.UseBiases) { for (int i = 0; i < hiddenLayer.Neurons.Length; i++) { nablaHiddenBiases[i] -= hiddenLayer.Neurons[i].LastState; } for (int i = 0; i < visibleLayer.Neurons.Length; i++) { nablaVisibleBiases[i] -= visibleLayer.Neurons[i].LastState; } } break; } #endregion //sample hidden states // , , , Gibbs sampling for (int i = 0; i < hiddenLayer.Neurons.Length; i++) { hiddenLayer.Neurons[i].LastState = _r.NextDouble() <= hiddenLayer.Neurons[i].LastState ? 1d : 0d; } #region accumulate positive phase // , if (k == 0) { for (int i = 0; i < visibleLayer.Neurons.Length; i++) { for (int j = 0; j < hiddenLayer.Neurons.Length; j++) { nablaWeights[i, j] += visibleLayer.Neurons[i].LastState* hiddenLayer.Neurons[j].LastState; } } if (_config.UseBiases) { for (int i = 0; i < hiddenLayer.Neurons.Length; i++) { nablaHiddenBiases[i] += hiddenLayer.Neurons[i].LastState; } for (int i = 0; i < visibleLayer.Neurons.Length; i++) { nablaVisibleBiases[i] += visibleLayer.Neurons[i].LastState; } } } #endregion //calculate visible probs // visibleLayer.Compute(); // , , , . ; //todo: may be not do sampling, like in 3.2 of http://www.cs.toronto.edu/~hinton/absps/guideTR.pdf //sample visible //for (int i = 0; i < visibleLayer.Neurons.Length; i++) //{ // visibleLayer.Neurons[i].LastState = _r.NextDouble() <= visibleLayer.Neurons[i].LastState ? 1d : 0d; //} } #endregion }
, . : ( ) . .
#region compute mean of wights nabla, and update them for (int i = 0; i < visibleLayer.Neurons.Length; i++) { for (int j = 0; j < hiddenLayer.Neurons.Length; j++) { // , momentumSpeedWeights[i, j] = _config.Momentum*momentumSpeedWeights[i, j] + nablaWeights[i, j]/batch.Count; // visibleLayer.Neurons[i].Weights[j] += learningRate * momentumSpeedWeights[i, j]; hiddenLayer.Neurons[j].Weights[i] = visibleLayer.Neurons[i].Weights[j]; } } if (_config.UseBiases) { for (int i = 0; i < hiddenLayer.Neurons.Length; i++) { momentumSpeedHiddenBiases[i] = _config.Momentum*momentumSpeedHiddenBiases[i] + nablaHiddenBiases[i]/batch.Count; hiddenLayer.Neurons[i].Bias += learningRate * momentumSpeedHiddenBiases[i]; } for (int i = 0; i < visibleLayer.Neurons.Length; i++) { momentumSpeedVisibleBiases[i] = _config.Momentum*momentumSpeedVisibleBiases[i] + nablaVisibleBiases[i]/batch.Count; visibleLayer.Neurons[i].Bias += learningRate * momentumSpeedVisibleBiases[i]; } }
- . , , / , , , . : . , , , . .
#region Logging and error calculation string msg = "Epoche #" + currentEpoche; #region calculate error if (currentEpoche % _config.CostFunctionRecalculationStep == 0) { #region calculating squared error with reconstruction IMetrics<double> sed = MetricsCreator.SquareEuclideanDistance(); double d = 0; foreach (DataItem<double> dataItem in data) { d += sed.Calculate(dataItem.Input, network.ComputeOutput(dataItem.Input)); } msg += "; SqDist is " + d; lastErrorChange = Math.Abs(lastError - d); lastError = d; #endregion } #endregion msg += "; Time: " + (DateTime.Now - dtStart).Duration().ToString(); Logger.Instance.Log(msg);
.
RBM
. , , , ( 260 29 29 ): .
:
LearningAlgorithmConfig:
LearningRate = 0.01
BatchSize = 10
RegularizationFactor = 0
MaxEpoches = 1000
MinError = 0
MinErrorChange = 0
CostFunctionRecalculationStep = 1
ErrorFunction =
Momentum = 0.9
NeuronLocalGainLimit: not setted
GibbsSamplingChainLength = 30
UseBiases = True
, 1000 . .. 10, 26 , 26000 . .
, (26 ) 13128, 76.
( , ):
:
, ( RBM).
, - , . , . 841 (29*29) . , 841 29 29 , , . , , , . :
MNIST : http://deeplearning.net/tutorial/_images/filters_at_epoch_14.png . , =)
RBM , , .
https://class.coursera.org/neuralnets-2012-001/ http://www.cs.toronto.edu/~hinton/absps/guideTR.pdf http://deeplearning.net/tutorial/rbm.html#contrastive-divergence-cd-k http://www.iro.umontreal.ca/~lisa/twiki/bin/view.cgi/Public/DBNEquations http://www.cs.toronto.edu/~kriz/learning-features-2009-TR.pdf
PS ambikontur !
UPD :
public void Train(IMultilayerNeuralNetwork network, IList<DataItem> data)
, . , .
LearningAlgorithmConfig config = new LearningAlgorithmConfig() { BatchSize = 10, // MaxEpoches = 1000, // GibbsSamplingChainLength = 30, // k CD-k LearningRate = 0.01, // CostFunctionRecalculationStep = 1, // Momentum = 0.9, // MinError = 0, // MinErrorChange = 0, // UseBiases = true // };
.
ILayer visibleLayer = network.Layers[0]; // RBM , ILayer hiddenLayer = network.Layers[1]; // if (!_config.UseBiases) // { for (int i = 0; i < visibleLayer.Neurons.Length; i++) { visibleLayer.Neurons[i].Bias = 0d; } for (int i = 0; i < hiddenLayer.Neurons.Length; i++) { hiddenLayer.Neurons[i].Bias = 0d; } } //init momentum // double[,] momentumSpeedWeights = new double[visibleLayer.Neurons.Length, hiddenLayer.Neurons.Length]; double[] momentumSpeedVisibleBiases = new double[visibleLayer.Neurons.Length]; double[] momentumSpeedHiddenBiases = new double[hiddenLayer.Neurons.Length]; //init stop factors bool stopFlag = false; double lastError = Double.MaxValue; // , double lastErrorChange = double.MaxValue; double learningRate = _config.LearningRate; int currentEpoche = 0; BatchEnumerator<DataItem<double>> batchEnumerator = new BatchEnumerator<DataItem<double>>(data, _config.BatchSize, true);
BatchEnumerator' , .
:
do { DateTime dtStart = DateTime.Now; //start batch processing foreach (IList<DataItem<double>> batch in batchEnumerator) { //batch gradient // , / double[,] nablaWeights = new double[visibleLayer.Neurons.Length, hiddenLayer.Neurons.Length]; double[] nablaHiddenBiases = new double[hiddenLayer.Neurons.Length]; double[] nablaVisibleBiases = new double[visibleLayer.Neurons.Length]; #region iterate through batch //... #endregion #region compute mean of wights nabla, and update them //... #endregion } #region Logging and error calculation //... #endregion // currentEpoche++; if (currentEpoche >= _config.MaxEpoches) { stopFlag = true; Logger.Instance.Log("Stop: currentEpoche:" + currentEpoche + " >= _config.MaxEpoches:" + _config.MaxEpoches); } else if (_config.MinError >= lastError) { stopFlag = true; Logger.Instance.Log("Stop: _config.MinError:" + _config.MinError + " >= lastError:" + lastError); } else if (_config.MinErrorChange >= lastErrorChange) { stopFlag = true; Logger.Instance.Log("Stop: _config.MinErrorChange:" + _config.MinErrorChange + " >= lastErrorChange:" + lastErrorChange); } } while (!stopFlag);
, Gibbs sampling, .
#region iterate through batch // foreach (DataItem<double> dataItem in batch) { //init visible layer states // / for (int i = 0; i < dataItem.Input.Length; i++) { visibleLayer.Neurons[i].LastState = dataItem.Input[i]; } #region Gibbs sampling for (int k = 0; k <= _config.GibbsSamplingChainLength; k++) { //calculate hidden states probabilities // , hiddenLayer.Compute(); #region accumulate negative phase // - , if (k == _config.GibbsSamplingChainLength) { for (int i = 0; i < visibleLayer.Neurons.Length; i++) { for (int j = 0; j < hiddenLayer.Neurons.Length; j++) { // nablaWeights[i, j] -= visibleLayer.Neurons[i].LastState * hiddenLayer.Neurons[j].LastState; } } if (_config.UseBiases) { for (int i = 0; i < hiddenLayer.Neurons.Length; i++) { nablaHiddenBiases[i] -= hiddenLayer.Neurons[i].LastState; } for (int i = 0; i < visibleLayer.Neurons.Length; i++) { nablaVisibleBiases[i] -= visibleLayer.Neurons[i].LastState; } } break; } #endregion //sample hidden states // , , , Gibbs sampling for (int i = 0; i < hiddenLayer.Neurons.Length; i++) { hiddenLayer.Neurons[i].LastState = _r.NextDouble() <= hiddenLayer.Neurons[i].LastState ? 1d : 0d; } #region accumulate positive phase // , if (k == 0) { for (int i = 0; i < visibleLayer.Neurons.Length; i++) { for (int j = 0; j < hiddenLayer.Neurons.Length; j++) { nablaWeights[i, j] += visibleLayer.Neurons[i].LastState* hiddenLayer.Neurons[j].LastState; } } if (_config.UseBiases) { for (int i = 0; i < hiddenLayer.Neurons.Length; i++) { nablaHiddenBiases[i] += hiddenLayer.Neurons[i].LastState; } for (int i = 0; i < visibleLayer.Neurons.Length; i++) { nablaVisibleBiases[i] += visibleLayer.Neurons[i].LastState; } } } #endregion //calculate visible probs // visibleLayer.Compute(); // , , , . ; //todo: may be not do sampling, like in 3.2 of http://www.cs.toronto.edu/~hinton/absps/guideTR.pdf //sample visible //for (int i = 0; i < visibleLayer.Neurons.Length; i++) //{ // visibleLayer.Neurons[i].LastState = _r.NextDouble() <= visibleLayer.Neurons[i].LastState ? 1d : 0d; //} } #endregion }
, . : ( ) . .
#region compute mean of wights nabla, and update them for (int i = 0; i < visibleLayer.Neurons.Length; i++) { for (int j = 0; j < hiddenLayer.Neurons.Length; j++) { // , momentumSpeedWeights[i, j] = _config.Momentum*momentumSpeedWeights[i, j] + nablaWeights[i, j]/batch.Count; // visibleLayer.Neurons[i].Weights[j] += learningRate * momentumSpeedWeights[i, j]; hiddenLayer.Neurons[j].Weights[i] = visibleLayer.Neurons[i].Weights[j]; } } if (_config.UseBiases) { for (int i = 0; i < hiddenLayer.Neurons.Length; i++) { momentumSpeedHiddenBiases[i] = _config.Momentum*momentumSpeedHiddenBiases[i] + nablaHiddenBiases[i]/batch.Count; hiddenLayer.Neurons[i].Bias += learningRate * momentumSpeedHiddenBiases[i]; } for (int i = 0; i < visibleLayer.Neurons.Length; i++) { momentumSpeedVisibleBiases[i] = _config.Momentum*momentumSpeedVisibleBiases[i] + nablaVisibleBiases[i]/batch.Count; visibleLayer.Neurons[i].Bias += learningRate * momentumSpeedVisibleBiases[i]; } }
- . , , / , , , . : . , , , . .
#region Logging and error calculation string msg = "Epoche #" + currentEpoche; #region calculate error if (currentEpoche % _config.CostFunctionRecalculationStep == 0) { #region calculating squared error with reconstruction IMetrics<double> sed = MetricsCreator.SquareEuclideanDistance(); double d = 0; foreach (DataItem<double> dataItem in data) { d += sed.Calculate(dataItem.Input, network.ComputeOutput(dataItem.Input)); } msg += "; SqDist is " + d; lastErrorChange = Math.Abs(lastError - d); lastError = d; #endregion } #endregion msg += "; Time: " + (DateTime.Now - dtStart).Duration().ToString(); Logger.Instance.Log(msg);
.
RBM
. , , , ( 260 29 29 ): .
:
LearningAlgorithmConfig:
LearningRate = 0.01
BatchSize = 10
RegularizationFactor = 0
MaxEpoches = 1000
MinError = 0
MinErrorChange = 0
CostFunctionRecalculationStep = 1
ErrorFunction =
Momentum = 0.9
NeuronLocalGainLimit: not setted
GibbsSamplingChainLength = 30
UseBiases = True
, 1000 . .. 10, 26 , 26000 . .
, (26 ) 13128, 76.
( , ):
:
, ( RBM).
, - , . , . 841 (29*29) . , 841 29 29 , , . , , , . :
MNIST : http://deeplearning.net/tutorial/_images/filters_at_epoch_14.png . , =)
RBM , , .
https://class.coursera.org/neuralnets-2012-001/ http://www.cs.toronto.edu/~hinton/absps/guideTR.pdf http://deeplearning.net/tutorial/rbm.html#contrastive-divergence-cd-k http://www.iro.umontreal.ca/~lisa/twiki/bin/view.cgi/Public/DBNEquations http://www.cs.toronto.edu/~kriz/learning-features-2009-TR.pdf
PS ambikontur !
UPD :
public void Train(IMultilayerNeuralNetwork network, IList<DataItem> data)
, . , .
LearningAlgorithmConfig config = new LearningAlgorithmConfig() { BatchSize = 10, // MaxEpoches = 1000, // GibbsSamplingChainLength = 30, // k CD-k LearningRate = 0.01, // CostFunctionRecalculationStep = 1, // Momentum = 0.9, // MinError = 0, // MinErrorChange = 0, // UseBiases = true // };
.
ILayer visibleLayer = network.Layers[0]; // RBM , ILayer hiddenLayer = network.Layers[1]; // if (!_config.UseBiases) // { for (int i = 0; i < visibleLayer.Neurons.Length; i++) { visibleLayer.Neurons[i].Bias = 0d; } for (int i = 0; i < hiddenLayer.Neurons.Length; i++) { hiddenLayer.Neurons[i].Bias = 0d; } } //init momentum // double[,] momentumSpeedWeights = new double[visibleLayer.Neurons.Length, hiddenLayer.Neurons.Length]; double[] momentumSpeedVisibleBiases = new double[visibleLayer.Neurons.Length]; double[] momentumSpeedHiddenBiases = new double[hiddenLayer.Neurons.Length]; //init stop factors bool stopFlag = false; double lastError = Double.MaxValue; // , double lastErrorChange = double.MaxValue; double learningRate = _config.LearningRate; int currentEpoche = 0; BatchEnumerator<DataItem<double>> batchEnumerator = new BatchEnumerator<DataItem<double>>(data, _config.BatchSize, true);
BatchEnumerator' , .
:
do { DateTime dtStart = DateTime.Now; //start batch processing foreach (IList<DataItem<double>> batch in batchEnumerator) { //batch gradient // , / double[,] nablaWeights = new double[visibleLayer.Neurons.Length, hiddenLayer.Neurons.Length]; double[] nablaHiddenBiases = new double[hiddenLayer.Neurons.Length]; double[] nablaVisibleBiases = new double[visibleLayer.Neurons.Length]; #region iterate through batch //... #endregion #region compute mean of wights nabla, and update them //... #endregion } #region Logging and error calculation //... #endregion // currentEpoche++; if (currentEpoche >= _config.MaxEpoches) { stopFlag = true; Logger.Instance.Log("Stop: currentEpoche:" + currentEpoche + " >= _config.MaxEpoches:" + _config.MaxEpoches); } else if (_config.MinError >= lastError) { stopFlag = true; Logger.Instance.Log("Stop: _config.MinError:" + _config.MinError + " >= lastError:" + lastError); } else if (_config.MinErrorChange >= lastErrorChange) { stopFlag = true; Logger.Instance.Log("Stop: _config.MinErrorChange:" + _config.MinErrorChange + " >= lastErrorChange:" + lastErrorChange); } } while (!stopFlag);
, Gibbs sampling, .
#region iterate through batch // foreach (DataItem<double> dataItem in batch) { //init visible layer states // / for (int i = 0; i < dataItem.Input.Length; i++) { visibleLayer.Neurons[i].LastState = dataItem.Input[i]; } #region Gibbs sampling for (int k = 0; k <= _config.GibbsSamplingChainLength; k++) { //calculate hidden states probabilities // , hiddenLayer.Compute(); #region accumulate negative phase // - , if (k == _config.GibbsSamplingChainLength) { for (int i = 0; i < visibleLayer.Neurons.Length; i++) { for (int j = 0; j < hiddenLayer.Neurons.Length; j++) { // nablaWeights[i, j] -= visibleLayer.Neurons[i].LastState * hiddenLayer.Neurons[j].LastState; } } if (_config.UseBiases) { for (int i = 0; i < hiddenLayer.Neurons.Length; i++) { nablaHiddenBiases[i] -= hiddenLayer.Neurons[i].LastState; } for (int i = 0; i < visibleLayer.Neurons.Length; i++) { nablaVisibleBiases[i] -= visibleLayer.Neurons[i].LastState; } } break; } #endregion //sample hidden states // , , , Gibbs sampling for (int i = 0; i < hiddenLayer.Neurons.Length; i++) { hiddenLayer.Neurons[i].LastState = _r.NextDouble() <= hiddenLayer.Neurons[i].LastState ? 1d : 0d; } #region accumulate positive phase // , if (k == 0) { for (int i = 0; i < visibleLayer.Neurons.Length; i++) { for (int j = 0; j < hiddenLayer.Neurons.Length; j++) { nablaWeights[i, j] += visibleLayer.Neurons[i].LastState* hiddenLayer.Neurons[j].LastState; } } if (_config.UseBiases) { for (int i = 0; i < hiddenLayer.Neurons.Length; i++) { nablaHiddenBiases[i] += hiddenLayer.Neurons[i].LastState; } for (int i = 0; i < visibleLayer.Neurons.Length; i++) { nablaVisibleBiases[i] += visibleLayer.Neurons[i].LastState; } } } #endregion //calculate visible probs // visibleLayer.Compute(); // , , , . ; //todo: may be not do sampling, like in 3.2 of http://www.cs.toronto.edu/~hinton/absps/guideTR.pdf //sample visible //for (int i = 0; i < visibleLayer.Neurons.Length; i++) //{ // visibleLayer.Neurons[i].LastState = _r.NextDouble() <= visibleLayer.Neurons[i].LastState ? 1d : 0d; //} } #endregion }
, . : ( ) . .
#region compute mean of wights nabla, and update them for (int i = 0; i < visibleLayer.Neurons.Length; i++) { for (int j = 0; j < hiddenLayer.Neurons.Length; j++) { // , momentumSpeedWeights[i, j] = _config.Momentum*momentumSpeedWeights[i, j] + nablaWeights[i, j]/batch.Count; // visibleLayer.Neurons[i].Weights[j] += learningRate * momentumSpeedWeights[i, j]; hiddenLayer.Neurons[j].Weights[i] = visibleLayer.Neurons[i].Weights[j]; } } if (_config.UseBiases) { for (int i = 0; i < hiddenLayer.Neurons.Length; i++) { momentumSpeedHiddenBiases[i] = _config.Momentum*momentumSpeedHiddenBiases[i] + nablaHiddenBiases[i]/batch.Count; hiddenLayer.Neurons[i].Bias += learningRate * momentumSpeedHiddenBiases[i]; } for (int i = 0; i < visibleLayer.Neurons.Length; i++) { momentumSpeedVisibleBiases[i] = _config.Momentum*momentumSpeedVisibleBiases[i] + nablaVisibleBiases[i]/batch.Count; visibleLayer.Neurons[i].Bias += learningRate * momentumSpeedVisibleBiases[i]; } }
- . , , / , , , . : . , , , . .
#region Logging and error calculation string msg = "Epoche #" + currentEpoche; #region calculate error if (currentEpoche % _config.CostFunctionRecalculationStep == 0) { #region calculating squared error with reconstruction IMetrics<double> sed = MetricsCreator.SquareEuclideanDistance(); double d = 0; foreach (DataItem<double> dataItem in data) { d += sed.Calculate(dataItem.Input, network.ComputeOutput(dataItem.Input)); } msg += "; SqDist is " + d; lastErrorChange = Math.Abs(lastError - d); lastError = d; #endregion } #endregion msg += "; Time: " + (DateTime.Now - dtStart).Duration().ToString(); Logger.Instance.Log(msg);
.
RBM
. , , , ( 260 29 29 ): .
:
LearningAlgorithmConfig:
LearningRate = 0.01
BatchSize = 10
RegularizationFactor = 0
MaxEpoches = 1000
MinError = 0
MinErrorChange = 0
CostFunctionRecalculationStep = 1
ErrorFunction =
Momentum = 0.9
NeuronLocalGainLimit: not setted
GibbsSamplingChainLength = 30
UseBiases = True
, 1000 . .. 10, 26 , 26000 . .
, (26 ) 13128, 76.
( , ):
:
, ( RBM).
, - , . , . 841 (29*29) . , 841 29 29 , , . , , , . :
MNIST : http://deeplearning.net/tutorial/_images/filters_at_epoch_14.png . , =)
RBM , , .
https://class.coursera.org/neuralnets-2012-001/ http://www.cs.toronto.edu/~hinton/absps/guideTR.pdf http://deeplearning.net/tutorial/rbm.html#contrastive-divergence-cd-k http://www.iro.umontreal.ca/~lisa/twiki/bin/view.cgi/Public/DBNEquations http://www.cs.toronto.edu/~kriz/learning-features-2009-TR.pdf
PS ambikontur !
UPD :
public void Train(IMultilayerNeuralNetwork network, IList<DataItem> data)
, . , .
LearningAlgorithmConfig config = new LearningAlgorithmConfig() { BatchSize = 10, // MaxEpoches = 1000, // GibbsSamplingChainLength = 30, // k CD-k LearningRate = 0.01, // CostFunctionRecalculationStep = 1, // Momentum = 0.9, // MinError = 0, // MinErrorChange = 0, // UseBiases = true // };
.
ILayer visibleLayer = network.Layers[0]; // RBM , ILayer hiddenLayer = network.Layers[1]; // if (!_config.UseBiases) // { for (int i = 0; i < visibleLayer.Neurons.Length; i++) { visibleLayer.Neurons[i].Bias = 0d; } for (int i = 0; i < hiddenLayer.Neurons.Length; i++) { hiddenLayer.Neurons[i].Bias = 0d; } } //init momentum // double[,] momentumSpeedWeights = new double[visibleLayer.Neurons.Length, hiddenLayer.Neurons.Length]; double[] momentumSpeedVisibleBiases = new double[visibleLayer.Neurons.Length]; double[] momentumSpeedHiddenBiases = new double[hiddenLayer.Neurons.Length]; //init stop factors bool stopFlag = false; double lastError = Double.MaxValue; // , double lastErrorChange = double.MaxValue; double learningRate = _config.LearningRate; int currentEpoche = 0; BatchEnumerator<DataItem<double>> batchEnumerator = new BatchEnumerator<DataItem<double>>(data, _config.BatchSize, true);
BatchEnumerator' , .
:
do { DateTime dtStart = DateTime.Now; //start batch processing foreach (IList<DataItem<double>> batch in batchEnumerator) { //batch gradient // , / double[,] nablaWeights = new double[visibleLayer.Neurons.Length, hiddenLayer.Neurons.Length]; double[] nablaHiddenBiases = new double[hiddenLayer.Neurons.Length]; double[] nablaVisibleBiases = new double[visibleLayer.Neurons.Length]; #region iterate through batch //... #endregion #region compute mean of wights nabla, and update them //... #endregion } #region Logging and error calculation //... #endregion // currentEpoche++; if (currentEpoche >= _config.MaxEpoches) { stopFlag = true; Logger.Instance.Log("Stop: currentEpoche:" + currentEpoche + " >= _config.MaxEpoches:" + _config.MaxEpoches); } else if (_config.MinError >= lastError) { stopFlag = true; Logger.Instance.Log("Stop: _config.MinError:" + _config.MinError + " >= lastError:" + lastError); } else if (_config.MinErrorChange >= lastErrorChange) { stopFlag = true; Logger.Instance.Log("Stop: _config.MinErrorChange:" + _config.MinErrorChange + " >= lastErrorChange:" + lastErrorChange); } } while (!stopFlag);
, Gibbs sampling, .
#region iterate through batch // foreach (DataItem<double> dataItem in batch) { //init visible layer states // / for (int i = 0; i < dataItem.Input.Length; i++) { visibleLayer.Neurons[i].LastState = dataItem.Input[i]; } #region Gibbs sampling for (int k = 0; k <= _config.GibbsSamplingChainLength; k++) { //calculate hidden states probabilities // , hiddenLayer.Compute(); #region accumulate negative phase // - , if (k == _config.GibbsSamplingChainLength) { for (int i = 0; i < visibleLayer.Neurons.Length; i++) { for (int j = 0; j < hiddenLayer.Neurons.Length; j++) { // nablaWeights[i, j] -= visibleLayer.Neurons[i].LastState * hiddenLayer.Neurons[j].LastState; } } if (_config.UseBiases) { for (int i = 0; i < hiddenLayer.Neurons.Length; i++) { nablaHiddenBiases[i] -= hiddenLayer.Neurons[i].LastState; } for (int i = 0; i < visibleLayer.Neurons.Length; i++) { nablaVisibleBiases[i] -= visibleLayer.Neurons[i].LastState; } } break; } #endregion //sample hidden states // , , , Gibbs sampling for (int i = 0; i < hiddenLayer.Neurons.Length; i++) { hiddenLayer.Neurons[i].LastState = _r.NextDouble() <= hiddenLayer.Neurons[i].LastState ? 1d : 0d; } #region accumulate positive phase // , if (k == 0) { for (int i = 0; i < visibleLayer.Neurons.Length; i++) { for (int j = 0; j < hiddenLayer.Neurons.Length; j++) { nablaWeights[i, j] += visibleLayer.Neurons[i].LastState* hiddenLayer.Neurons[j].LastState; } } if (_config.UseBiases) { for (int i = 0; i < hiddenLayer.Neurons.Length; i++) { nablaHiddenBiases[i] += hiddenLayer.Neurons[i].LastState; } for (int i = 0; i < visibleLayer.Neurons.Length; i++) { nablaVisibleBiases[i] += visibleLayer.Neurons[i].LastState; } } } #endregion //calculate visible probs // visibleLayer.Compute(); // , , , . ; //todo: may be not do sampling, like in 3.2 of http://www.cs.toronto.edu/~hinton/absps/guideTR.pdf //sample visible //for (int i = 0; i < visibleLayer.Neurons.Length; i++) //{ // visibleLayer.Neurons[i].LastState = _r.NextDouble() <= visibleLayer.Neurons[i].LastState ? 1d : 0d; //} } #endregion }
, . : ( ) . .
#region compute mean of wights nabla, and update them for (int i = 0; i < visibleLayer.Neurons.Length; i++) { for (int j = 0; j < hiddenLayer.Neurons.Length; j++) { // , momentumSpeedWeights[i, j] = _config.Momentum*momentumSpeedWeights[i, j] + nablaWeights[i, j]/batch.Count; // visibleLayer.Neurons[i].Weights[j] += learningRate * momentumSpeedWeights[i, j]; hiddenLayer.Neurons[j].Weights[i] = visibleLayer.Neurons[i].Weights[j]; } } if (_config.UseBiases) { for (int i = 0; i < hiddenLayer.Neurons.Length; i++) { momentumSpeedHiddenBiases[i] = _config.Momentum*momentumSpeedHiddenBiases[i] + nablaHiddenBiases[i]/batch.Count; hiddenLayer.Neurons[i].Bias += learningRate * momentumSpeedHiddenBiases[i]; } for (int i = 0; i < visibleLayer.Neurons.Length; i++) { momentumSpeedVisibleBiases[i] = _config.Momentum*momentumSpeedVisibleBiases[i] + nablaVisibleBiases[i]/batch.Count; visibleLayer.Neurons[i].Bias += learningRate * momentumSpeedVisibleBiases[i]; } }
- . , , / , , , . : . , , , . .
#region Logging and error calculation string msg = "Epoche #" + currentEpoche; #region calculate error if (currentEpoche % _config.CostFunctionRecalculationStep == 0) { #region calculating squared error with reconstruction IMetrics<double> sed = MetricsCreator.SquareEuclideanDistance(); double d = 0; foreach (DataItem<double> dataItem in data) { d += sed.Calculate(dataItem.Input, network.ComputeOutput(dataItem.Input)); } msg += "; SqDist is " + d; lastErrorChange = Math.Abs(lastError - d); lastError = d; #endregion } #endregion msg += "; Time: " + (DateTime.Now - dtStart).Duration().ToString(); Logger.Instance.Log(msg);
.
RBM
. , , , ( 260 29 29 ): .
:
LearningAlgorithmConfig:
LearningRate = 0.01
BatchSize = 10
RegularizationFactor = 0
MaxEpoches = 1000
MinError = 0
MinErrorChange = 0
CostFunctionRecalculationStep = 1
ErrorFunction =
Momentum = 0.9
NeuronLocalGainLimit: not setted
GibbsSamplingChainLength = 30
UseBiases = True
, 1000 . .. 10, 26 , 26000 . .
, (26 ) 13128, 76.
( , ):
:
, ( RBM).
, - , . , . 841 (29*29) . , 841 29 29 , , . , , , . :
MNIST : http://deeplearning.net/tutorial/_images/filters_at_epoch_14.png . , =)
RBM , , .
https://class.coursera.org/neuralnets-2012-001/ http://www.cs.toronto.edu/~hinton/absps/guideTR.pdf http://deeplearning.net/tutorial/rbm.html#contrastive-divergence-cd-k http://www.iro.umontreal.ca/~lisa/twiki/bin/view.cgi/Public/DBNEquations http://www.cs.toronto.edu/~kriz/learning-features-2009-TR.pdf
PS ambikontur !
UPD :
public void Train(IMultilayerNeuralNetwork network, IList<DataItem> data)
, . , .
LearningAlgorithmConfig config = new LearningAlgorithmConfig() { BatchSize = 10, // MaxEpoches = 1000, // GibbsSamplingChainLength = 30, // k CD-k LearningRate = 0.01, // CostFunctionRecalculationStep = 1, // Momentum = 0.9, // MinError = 0, // MinErrorChange = 0, // UseBiases = true // };
.
ILayer visibleLayer = network.Layers[0]; // RBM , ILayer hiddenLayer = network.Layers[1]; // if (!_config.UseBiases) // { for (int i = 0; i < visibleLayer.Neurons.Length; i++) { visibleLayer.Neurons[i].Bias = 0d; } for (int i = 0; i < hiddenLayer.Neurons.Length; i++) { hiddenLayer.Neurons[i].Bias = 0d; } } //init momentum // double[,] momentumSpeedWeights = new double[visibleLayer.Neurons.Length, hiddenLayer.Neurons.Length]; double[] momentumSpeedVisibleBiases = new double[visibleLayer.Neurons.Length]; double[] momentumSpeedHiddenBiases = new double[hiddenLayer.Neurons.Length]; //init stop factors bool stopFlag = false; double lastError = Double.MaxValue; // , double lastErrorChange = double.MaxValue; double learningRate = _config.LearningRate; int currentEpoche = 0; BatchEnumerator<DataItem<double>> batchEnumerator = new BatchEnumerator<DataItem<double>>(data, _config.BatchSize, true);
BatchEnumerator' , .
:
do { DateTime dtStart = DateTime.Now; //start batch processing foreach (IList<DataItem<double>> batch in batchEnumerator) { //batch gradient // , / double[,] nablaWeights = new double[visibleLayer.Neurons.Length, hiddenLayer.Neurons.Length]; double[] nablaHiddenBiases = new double[hiddenLayer.Neurons.Length]; double[] nablaVisibleBiases = new double[visibleLayer.Neurons.Length]; #region iterate through batch //... #endregion #region compute mean of wights nabla, and update them //... #endregion } #region Logging and error calculation //... #endregion // currentEpoche++; if (currentEpoche >= _config.MaxEpoches) { stopFlag = true; Logger.Instance.Log("Stop: currentEpoche:" + currentEpoche + " >= _config.MaxEpoches:" + _config.MaxEpoches); } else if (_config.MinError >= lastError) { stopFlag = true; Logger.Instance.Log("Stop: _config.MinError:" + _config.MinError + " >= lastError:" + lastError); } else if (_config.MinErrorChange >= lastErrorChange) { stopFlag = true; Logger.Instance.Log("Stop: _config.MinErrorChange:" + _config.MinErrorChange + " >= lastErrorChange:" + lastErrorChange); } } while (!stopFlag);
, Gibbs sampling, .
#region iterate through batch // foreach (DataItem<double> dataItem in batch) { //init visible layer states // / for (int i = 0; i < dataItem.Input.Length; i++) { visibleLayer.Neurons[i].LastState = dataItem.Input[i]; } #region Gibbs sampling for (int k = 0; k <= _config.GibbsSamplingChainLength; k++) { //calculate hidden states probabilities // , hiddenLayer.Compute(); #region accumulate negative phase // - , if (k == _config.GibbsSamplingChainLength) { for (int i = 0; i < visibleLayer.Neurons.Length; i++) { for (int j = 0; j < hiddenLayer.Neurons.Length; j++) { // nablaWeights[i, j] -= visibleLayer.Neurons[i].LastState * hiddenLayer.Neurons[j].LastState; } } if (_config.UseBiases) { for (int i = 0; i < hiddenLayer.Neurons.Length; i++) { nablaHiddenBiases[i] -= hiddenLayer.Neurons[i].LastState; } for (int i = 0; i < visibleLayer.Neurons.Length; i++) { nablaVisibleBiases[i] -= visibleLayer.Neurons[i].LastState; } } break; } #endregion //sample hidden states // , , , Gibbs sampling for (int i = 0; i < hiddenLayer.Neurons.Length; i++) { hiddenLayer.Neurons[i].LastState = _r.NextDouble() <= hiddenLayer.Neurons[i].LastState ? 1d : 0d; } #region accumulate positive phase // , if (k == 0) { for (int i = 0; i < visibleLayer.Neurons.Length; i++) { for (int j = 0; j < hiddenLayer.Neurons.Length; j++) { nablaWeights[i, j] += visibleLayer.Neurons[i].LastState* hiddenLayer.Neurons[j].LastState; } } if (_config.UseBiases) { for (int i = 0; i < hiddenLayer.Neurons.Length; i++) { nablaHiddenBiases[i] += hiddenLayer.Neurons[i].LastState; } for (int i = 0; i < visibleLayer.Neurons.Length; i++) { nablaVisibleBiases[i] += visibleLayer.Neurons[i].LastState; } } } #endregion //calculate visible probs // visibleLayer.Compute(); // , , , . ; //todo: may be not do sampling, like in 3.2 of http://www.cs.toronto.edu/~hinton/absps/guideTR.pdf //sample visible //for (int i = 0; i < visibleLayer.Neurons.Length; i++) //{ // visibleLayer.Neurons[i].LastState = _r.NextDouble() <= visibleLayer.Neurons[i].LastState ? 1d : 0d; //} } #endregion }
, . : ( ) . .
#region compute mean of wights nabla, and update them for (int i = 0; i < visibleLayer.Neurons.Length; i++) { for (int j = 0; j < hiddenLayer.Neurons.Length; j++) { // , momentumSpeedWeights[i, j] = _config.Momentum*momentumSpeedWeights[i, j] + nablaWeights[i, j]/batch.Count; // visibleLayer.Neurons[i].Weights[j] += learningRate * momentumSpeedWeights[i, j]; hiddenLayer.Neurons[j].Weights[i] = visibleLayer.Neurons[i].Weights[j]; } } if (_config.UseBiases) { for (int i = 0; i < hiddenLayer.Neurons.Length; i++) { momentumSpeedHiddenBiases[i] = _config.Momentum*momentumSpeedHiddenBiases[i] + nablaHiddenBiases[i]/batch.Count; hiddenLayer.Neurons[i].Bias += learningRate * momentumSpeedHiddenBiases[i]; } for (int i = 0; i < visibleLayer.Neurons.Length; i++) { momentumSpeedVisibleBiases[i] = _config.Momentum*momentumSpeedVisibleBiases[i] + nablaVisibleBiases[i]/batch.Count; visibleLayer.Neurons[i].Bias += learningRate * momentumSpeedVisibleBiases[i]; } }
- . , , / , , , . : . , , , . .
#region Logging and error calculation string msg = "Epoche #" + currentEpoche; #region calculate error if (currentEpoche % _config.CostFunctionRecalculationStep == 0) { #region calculating squared error with reconstruction IMetrics<double> sed = MetricsCreator.SquareEuclideanDistance(); double d = 0; foreach (DataItem<double> dataItem in data) { d += sed.Calculate(dataItem.Input, network.ComputeOutput(dataItem.Input)); } msg += "; SqDist is " + d; lastErrorChange = Math.Abs(lastError - d); lastError = d; #endregion } #endregion msg += "; Time: " + (DateTime.Now - dtStart).Duration().ToString(); Logger.Instance.Log(msg);
.
RBM
. , , , ( 260 29 29 ): .
:
LearningAlgorithmConfig:
LearningRate = 0.01
BatchSize = 10
RegularizationFactor = 0
MaxEpoches = 1000
MinError = 0
MinErrorChange = 0
CostFunctionRecalculationStep = 1
ErrorFunction =
Momentum = 0.9
NeuronLocalGainLimit: not setted
GibbsSamplingChainLength = 30
UseBiases = True
, 1000 . .. 10, 26 , 26000 . .
, (26 ) 13128, 76.
( , ):
:
, ( RBM).
, - , . , . 841 (29*29) . , 841 29 29 , , . , , , . :
MNIST : http://deeplearning.net/tutorial/_images/filters_at_epoch_14.png . , =)
RBM , , .
https://class.coursera.org/neuralnets-2012-001/ http://www.cs.toronto.edu/~hinton/absps/guideTR.pdf http://deeplearning.net/tutorial/rbm.html#contrastive-divergence-cd-k http://www.iro.umontreal.ca/~lisa/twiki/bin/view.cgi/Public/DBNEquations http://www.cs.toronto.edu/~kriz/learning-features-2009-TR.pdf
PS ambikontur !
UPD :
public void Train(IMultilayerNeuralNetwork network, IList<DataItem> data)
, . , .
LearningAlgorithmConfig config = new LearningAlgorithmConfig() { BatchSize = 10, // MaxEpoches = 1000, // GibbsSamplingChainLength = 30, // k CD-k LearningRate = 0.01, // CostFunctionRecalculationStep = 1, // Momentum = 0.9, // MinError = 0, // MinErrorChange = 0, // UseBiases = true // };
.
ILayer visibleLayer = network.Layers[0]; // RBM , ILayer hiddenLayer = network.Layers[1]; // if (!_config.UseBiases) // { for (int i = 0; i < visibleLayer.Neurons.Length; i++) { visibleLayer.Neurons[i].Bias = 0d; } for (int i = 0; i < hiddenLayer.Neurons.Length; i++) { hiddenLayer.Neurons[i].Bias = 0d; } } //init momentum // double[,] momentumSpeedWeights = new double[visibleLayer.Neurons.Length, hiddenLayer.Neurons.Length]; double[] momentumSpeedVisibleBiases = new double[visibleLayer.Neurons.Length]; double[] momentumSpeedHiddenBiases = new double[hiddenLayer.Neurons.Length]; //init stop factors bool stopFlag = false; double lastError = Double.MaxValue; // , double lastErrorChange = double.MaxValue; double learningRate = _config.LearningRate; int currentEpoche = 0; BatchEnumerator<DataItem<double>> batchEnumerator = new BatchEnumerator<DataItem<double>>(data, _config.BatchSize, true);
BatchEnumerator' , .
:
do { DateTime dtStart = DateTime.Now; //start batch processing foreach (IList<DataItem<double>> batch in batchEnumerator) { //batch gradient // , / double[,] nablaWeights = new double[visibleLayer.Neurons.Length, hiddenLayer.Neurons.Length]; double[] nablaHiddenBiases = new double[hiddenLayer.Neurons.Length]; double[] nablaVisibleBiases = new double[visibleLayer.Neurons.Length]; #region iterate through batch //... #endregion #region compute mean of wights nabla, and update them //... #endregion } #region Logging and error calculation //... #endregion // currentEpoche++; if (currentEpoche >= _config.MaxEpoches) { stopFlag = true; Logger.Instance.Log("Stop: currentEpoche:" + currentEpoche + " >= _config.MaxEpoches:" + _config.MaxEpoches); } else if (_config.MinError >= lastError) { stopFlag = true; Logger.Instance.Log("Stop: _config.MinError:" + _config.MinError + " >= lastError:" + lastError); } else if (_config.MinErrorChange >= lastErrorChange) { stopFlag = true; Logger.Instance.Log("Stop: _config.MinErrorChange:" + _config.MinErrorChange + " >= lastErrorChange:" + lastErrorChange); } } while (!stopFlag);
, Gibbs sampling, .
#region iterate through batch // foreach (DataItem<double> dataItem in batch) { //init visible layer states // / for (int i = 0; i < dataItem.Input.Length; i++) { visibleLayer.Neurons[i].LastState = dataItem.Input[i]; } #region Gibbs sampling for (int k = 0; k <= _config.GibbsSamplingChainLength; k++) { //calculate hidden states probabilities // , hiddenLayer.Compute(); #region accumulate negative phase // - , if (k == _config.GibbsSamplingChainLength) { for (int i = 0; i < visibleLayer.Neurons.Length; i++) { for (int j = 0; j < hiddenLayer.Neurons.Length; j++) { // nablaWeights[i, j] -= visibleLayer.Neurons[i].LastState * hiddenLayer.Neurons[j].LastState; } } if (_config.UseBiases) { for (int i = 0; i < hiddenLayer.Neurons.Length; i++) { nablaHiddenBiases[i] -= hiddenLayer.Neurons[i].LastState; } for (int i = 0; i < visibleLayer.Neurons.Length; i++) { nablaVisibleBiases[i] -= visibleLayer.Neurons[i].LastState; } } break; } #endregion //sample hidden states // , , , Gibbs sampling for (int i = 0; i < hiddenLayer.Neurons.Length; i++) { hiddenLayer.Neurons[i].LastState = _r.NextDouble() <= hiddenLayer.Neurons[i].LastState ? 1d : 0d; } #region accumulate positive phase // , if (k == 0) { for (int i = 0; i < visibleLayer.Neurons.Length; i++) { for (int j = 0; j < hiddenLayer.Neurons.Length; j++) { nablaWeights[i, j] += visibleLayer.Neurons[i].LastState* hiddenLayer.Neurons[j].LastState; } } if (_config.UseBiases) { for (int i = 0; i < hiddenLayer.Neurons.Length; i++) { nablaHiddenBiases[i] += hiddenLayer.Neurons[i].LastState; } for (int i = 0; i < visibleLayer.Neurons.Length; i++) { nablaVisibleBiases[i] += visibleLayer.Neurons[i].LastState; } } } #endregion //calculate visible probs // visibleLayer.Compute(); // , , , . ; //todo: may be not do sampling, like in 3.2 of http://www.cs.toronto.edu/~hinton/absps/guideTR.pdf //sample visible //for (int i = 0; i < visibleLayer.Neurons.Length; i++) //{ // visibleLayer.Neurons[i].LastState = _r.NextDouble() <= visibleLayer.Neurons[i].LastState ? 1d : 0d; //} } #endregion }
, . : ( ) . .
#region compute mean of wights nabla, and update them for (int i = 0; i < visibleLayer.Neurons.Length; i++) { for (int j = 0; j < hiddenLayer.Neurons.Length; j++) { // , momentumSpeedWeights[i, j] = _config.Momentum*momentumSpeedWeights[i, j] + nablaWeights[i, j]/batch.Count; // visibleLayer.Neurons[i].Weights[j] += learningRate * momentumSpeedWeights[i, j]; hiddenLayer.Neurons[j].Weights[i] = visibleLayer.Neurons[i].Weights[j]; } } if (_config.UseBiases) { for (int i = 0; i < hiddenLayer.Neurons.Length; i++) { momentumSpeedHiddenBiases[i] = _config.Momentum*momentumSpeedHiddenBiases[i] + nablaHiddenBiases[i]/batch.Count; hiddenLayer.Neurons[i].Bias += learningRate * momentumSpeedHiddenBiases[i]; } for (int i = 0; i < visibleLayer.Neurons.Length; i++) { momentumSpeedVisibleBiases[i] = _config.Momentum*momentumSpeedVisibleBiases[i] + nablaVisibleBiases[i]/batch.Count; visibleLayer.Neurons[i].Bias += learningRate * momentumSpeedVisibleBiases[i]; } }
- . , , / , , , . : . , , , . .
#region Logging and error calculation string msg = "Epoche #" + currentEpoche; #region calculate error if (currentEpoche % _config.CostFunctionRecalculationStep == 0) { #region calculating squared error with reconstruction IMetrics<double> sed = MetricsCreator.SquareEuclideanDistance(); double d = 0; foreach (DataItem<double> dataItem in data) { d += sed.Calculate(dataItem.Input, network.ComputeOutput(dataItem.Input)); } msg += "; SqDist is " + d; lastErrorChange = Math.Abs(lastError - d); lastError = d; #endregion } #endregion msg += "; Time: " + (DateTime.Now - dtStart).Duration().ToString(); Logger.Instance.Log(msg);
.
RBM
. , , , ( 260 29 29 ): .
:
LearningAlgorithmConfig:
LearningRate = 0.01
BatchSize = 10
RegularizationFactor = 0
MaxEpoches = 1000
MinError = 0
MinErrorChange = 0
CostFunctionRecalculationStep = 1
ErrorFunction =
Momentum = 0.9
NeuronLocalGainLimit: not setted
GibbsSamplingChainLength = 30
UseBiases = True
, 1000 . .. 10, 26 , 26000 . .
, (26 ) 13128, 76.
( , ):
:
, ( RBM).
, - , . , . 841 (29*29) . , 841 29 29 , , . , , , . :
MNIST : http://deeplearning.net/tutorial/_images/filters_at_epoch_14.png . , =)
RBM , , .
https://class.coursera.org/neuralnets-2012-001/ http://www.cs.toronto.edu/~hinton/absps/guideTR.pdf http://deeplearning.net/tutorial/rbm.html#contrastive-divergence-cd-k http://www.iro.umontreal.ca/~lisa/twiki/bin/view.cgi/Public/DBNEquations http://www.cs.toronto.edu/~kriz/learning-features-2009-TR.pdf
PS ambikontur !
UPD :